
基于随机森林和贝叶斯优化的TiO2光催化污染物降解速率预测模型研究
2021-09-10 12:21刘海军刘韵锋刘小玲郭柏帆赵文锋通讯作者
信息记录材料 2021年8期
刘海军,刘韵锋,陈 侨,刘小玲,郭柏帆,赵文锋(通讯作者)
(华南农业大学电子工程学院<华南农业大学人工智能学院> 广东 广州 510642)
1 引言
水污染处理是当今全球性问题,由于水体污染物中包含重金属、有毒有害易长期积累的有机物、放射性污染物等,对用水安全产生了极大地威胁。1972年以来,研究人员开展了大量光催化降解污染物的实验,由于化学反应的发生与结果往往取决于反应物与实验环境,具有高度的不确定性,需要反复地实验,不断地试错以获取期望的结果,显然这种方法在资源消耗与取得成果上不具备优势。
随着数据科学的兴起,各种机器学习模型也被用到化学反应的预测工作。在多种机器学习模型中,人工神经网络(Artificial Neural Network,ANN)对水污染处理效果的预测模型受到越来越多研究人员的关注。张浩等[1]为获取高效的甲醛气体去除率,运用正交实验设计结合反向传播(Back Propagation,BP)神经网络优化TiO2的改性方案,并通过该模型进行预测和优选,得到了最佳的活性炭改性方案。袁军座等[2]以BP神经网络作为模型的主体结构,指数平滑法作为预测模型的输入,利用网络自学习获取模型输入权重,建立Cu-Ce/TiO2光催化性能组合预测模型。
但是,传统ANN算法是基于渐近理论,模型的准确预测建立在大量数据支撑的基础上,同时容易陷入局部最值,以及对样本的依赖性和初始权重的敏感度较高等因素,使得模型的处理精度和速度达不到预期。进而有研究人员开始利用集成学习(Ensemble Learning)方法去搭建预测模型。郑伟达等[3]建立随机森林、岭回归、基于径向基核函数和线性核函数的支持向量回归等4种机器学习算法的预测模型,对钙钛矿材料数据集中的密度、形成能、带隙、晶体体积等4种性能参数进行预测。SUUO J等[4]利用随机森林算法实现了不对称催化氢化反应对映选择性的预测。
在本项工作中,我们提出基于随机森林(Random Forest,RF)与贝叶斯优化的高精度预测模型,阐述了模型的基本原理及实现过程,并与ANN搭建的模型进行对比分析,验证了该模型的可行性和可靠性。
2 材料与方法
2.1 数据准备
数据集包含408个数据点,来自于公开发表的论文报告[5-7]。每个数据点包含6个输入变量,分别是有机污染物类型(OC)、污染物初始浓度(Co)、紫外光强度(I,mWcm-2)、实验温度(T,℃)、TiO2用量(D,gL-1)和溶液初始pH(pH),输出为光降解速率常数(k,min-1),将其转换为以10为底的对数-log(k),以便更好地可视化小数据。
除了有机污染物类型外,其他5个变量和1个响应都是数值数据,对于计算机语言来说是直接可读的。为了使污染物类型对于模型可读,需要使用分子指纹将它们转换成一个二元矢量,如(000101…0)。分子指纹将化合物的化学结构特征编码成只含有0和1的二元载体,0表示化合物中没有一定的化学结构,而1表示其存在,可以作为机器学习模型的输入,能够直接链接到化学特征。向量的长度是可调的,长度越长,就会存储越多的结构特征,因此不同化合物的特征重叠的可能性就越小。这对模型的可靠性有很大的影响,可通过后续的研究内容进行确定。
在本工作中,我们将数据集按照4:1的比例随机划分为训练集和测试集,其中训练集样本326份,测试集样本82份。利用均方根误差(RMSE,公式1)和决定系数(R2,公式2)来评估所开发模型的性能。RMSE是残差的标准偏差,即预测值与真实值的误差,其值越低越好。当决定系数(R2)应用于测试集时,其值等于外部解释的方差,可用于判断模型的好坏。一般来说,RMSE越低,R2值越高,说明模型拟合效果越好。
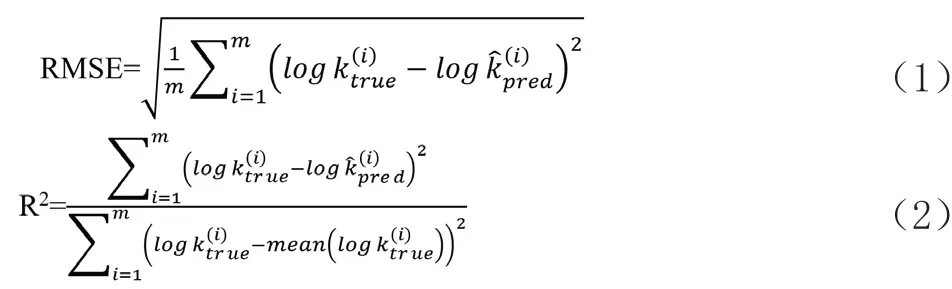
2.2 模型比较
2.2.1 人工神经网络模型(Artificial Neural Network)
ANN是由大量神经元互相连接而形成的复杂网络结构,以类似于人类神经系统的方式学习输入到神经网络的数据,是一种具有分布式并行信息处理的特征抽象数学模型[8]。
典型的神经网络由几到数百万个神经元组成,他们排列在一系列的层中。输入层用于接收外部的数据,输入层的神经元数目正好是我们输入变量的数目,例如本工作中的CO、I、T、D、Co、pH。最后一层为输出层,输出层的神经元数目等于响应的数目,例如本工作中的-logk。在输入层和输出层之间,存在着一系列的隐藏层,通过激活函数连接从输入到输出层的信息,层与层之间的任意两个神经元都通过权重连接起来,这些权重表示这两个神经元之间信息的强度。
过拟合是调试ANN经常遇到的问题,其外部表现为模型在训练集的准确率很高而在测试集的准确率很低,内部表现为模型泛化能力差,参数过多拟合某一个或多个方向。在本项工作中,我们使用Dropout方法防止过拟合,Dropout是一种在正向训练阶段随机让某一个神经元暂时退出或者丢弃,从而降低模型的复杂度,防止训练数据的过匹配的方法,这可能会导致训练时间上升,但能够抑制过拟合的可能性,提高神经网络模型泛化力。
一般认为,ANN模型的质量极大地取决于它的超参数。因此,要获得一个可靠的ANN模型,就必须对网络的超参数进行优化,找到最佳参数,这将在后面的研究内容中提到。
2.2.2 随机森林模型(Random Forest)
随机森林是一种基于分类树的高效集成学习算法,它通过随机选择训练样本和特征的子集来构建众多独立的决策树,然后收集这些决策树的结果。对于新的输入进行预测,需要遍历每颗决策树,将每棵树的结果取平均作为最终结果,这使得模型具有更稳定的预测能力。
该算法的优点体现在学习过程较快,对于大规模数据集,是一种高效的处理算法,且对数据集中的噪声有较强的鲁棒性。与传统的机器学习方法相比,RF不需要顾虑一般回归分析面临的多元共线性的问题,便于非线性数据处理,算法具有预测精度高、收敛速度快、调节参数少以及能有效避免“过拟合”风险等优点,适用于超高维特征向量空间,因此在众多领域中得到了广泛应用。
RF的参数中,n_estimators为决策树的数目,太少容易欠拟合,通常决策树的数目越多,算法效果越好,但是计算时间也会随之增加,当树的数量超过一个临界值,算法的效果并不会显著变好;max_features为最大特征数,即构建决策树最优模型时考虑的最大特征数,是分割节点时考虑特征随机子集的大小,这个值越低,方差减小得越多,但是偏差的增大也越多;min_samples_split为节点可分的最小样本数;max_depth为决策树最大深度。同样地,我们需要对RF的参数进行调优,以便获得最佳参数,这将在后面的研究内容中提到。
2.2.3 贝叶斯优化
针对机器学习超参数进行优化的算法有很多,常用的有网格搜索、随机搜索和贝叶斯优化。相比于网格搜索和随机搜索,贝叶斯优化能够以更少的迭代次数获得更优的结果,快速而准确地寻找超参数的最优解,因此在参数组合寻优问题上被广泛应用。
使用贝叶斯方法优化ANN的超参数,所使用的激活函数是ReLU,优化器是Adam,每个batch大小为64,周期为500,通过5倍交叉验证的方法对ANN模型进行训练,该方法将数据随机分成5个近似大小相等的子组。每次保留一个数据组用于验证,其他4个数据组用于训练,这个过程重复5次,计算结果可以使用每次的模型评估分数取平均,用RMSE和R2对ANN模型的性能进行评估。
同样地,使用贝叶斯优化RF的超参数,通过5倍交叉验证方法对RF模型进行训练,用RMSE和R2对RF模型的性能进行评估。
3 结果与讨论
3.1 贝叶斯优化人工神经网络
采用贝叶斯优化方法对ANN模型参数进行优化,在本项工作中,ANN模型参数包括隐藏层的数量、每个神经元的数量、Dropout率以及分子指纹的半径和长度。
随着贝叶斯迭代的进行,RMSE就会收敛。优化后的对应模型参数如下,网络层数为8层,其中隐藏层7层,输出层1层,每个隐藏层中的神经元数为512,Dropout率为0.2,分子半径为1.0,分子指纹长度为128,使用贝叶斯优化后的参数作为ANN模型的初始超参数进行训练。此外,我们还使用测试集对模型的性能进行评估,结果为:RMSE为0.21,R2为0.86,预测值和真实值的对比折线图和散点图见图1。
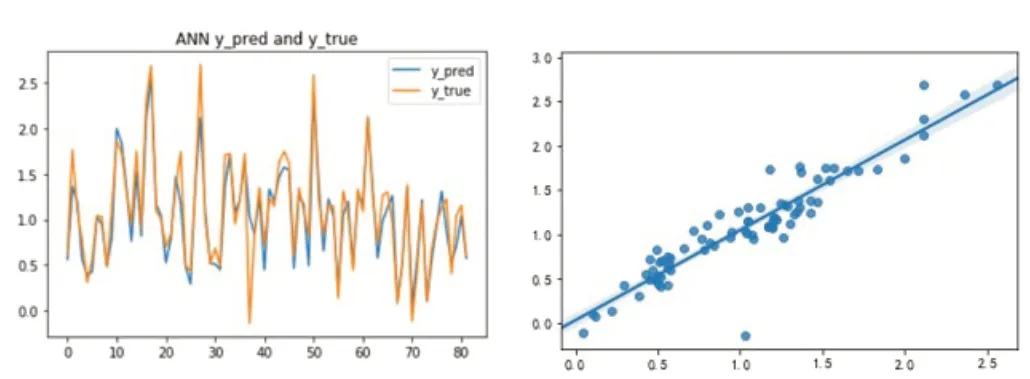
图1 ANN的预测值和真实值对比图
3.2 贝叶斯优化随机森林
采用贝叶斯优化方法进行了RF模型参数的优化,模型参数如下:决策树数目为387,最大特征数为0.703,最小样本数为2,最大深度为84,分子半径为1.0,分子指纹长度为128。使用测试集对模型的性能进行评估,结果为:RMSE为0.16,R2为0.92,预测值和真实值的对比折线图和散点图见图2。

图2 RF的预测值和真实值对比图
3.3 对比分析
通过对比两个模型预测值和真实值对比图(图1和图2),可知RF模型预测值和真实值的折线图重叠程度更高,预测值和真实值的散点更紧密分布于直线的两侧,具有较小的方差和偏差,充分证明了RF模型的准确率更高,可靠性更强,拟合和泛化能力也更强。
ANN模型和RF模型性能指标对比,见表1,使用相同的数据集进行训练和测试,结果表明:RF模型的RMSE更小,R2更高,RF模型性能明显优于ANN模型。

表1 ANN和RF模型性能对比
4 结语
在本项工作中,我们提出了ANN和RF两个模型,用于水污染物光降解速率常数的预测。模型的输入特征基本上涵盖了光催化降解过程的大部分实验条件,输出为光降解速率常数。以均方根误差(RMSE)和决定系数(R2)作为模型的评测指标,结果表明,相比于ANN模型,本工作提出的基于随机森林和贝叶斯优化的光降解速率常数预测的建模方法避免了冗余信息和干扰噪声等因素对模型准确率的不利影响,在具有较高的预测精度和可靠性的同时,增强了模型的泛化能力和鲁棒性。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
现代装饰(2018年5期)2018-05-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电子器件(2015年5期)2015-12-29
电源技术(2015年5期)2015-08-22
中国生化药物杂志(2015年4期)2015-07-07
弹箭与制导学报(2015年1期)2015-03-11
