
YOLO模型在视频监测中快速识别目标的应用研究
2021-09-10 13:25陈旋
视听 2021年9期
陈 旋
一、研究目的
随着光纤入户和5G网络的普及,人们从视频获取信息的占比越来越高。视频与文字、图片相比,增加了时间维度,信息从二维提高到了三维。在互联网信息监测中,用二维的技术无法满足三维结构的要求,这给新媒体监测提出了新的挑战。根据广播电视监测行业的特点,在每个阶段对新媒体的监测会有不同的目标,且有时会有紧急任务,也就是目标不固定、样本少、时间紧。若单纯使用人工播放并观看的方式进行监测,将严重消耗人力,成为新媒体监测的难点。为了解决这个问题,需要研究当今计算机视觉的最新成果,并结合广播电视行业的特点,找出适合业务要求的监测方法,最终实现机器自动监测,达到解放人力和减少网络信息危害的目的。
二、目标识别方法
本文主要研究在一个视频流中快速发现指定目标的监测过程,例如,在视频流中找到特定的标志、植物等。此过程不同于人脸识别技术,识别目标对象没有一个固定的分类,也没有固定的特征,不同种类的目标具有不同的形状、纹理、色彩、背景等特征。视频流是由一帧一帧的画面组合而成的,在视频流中找到目标也就是要在每一帧画面中找到目标。为了便于区分,目标识别定义为在视频流中找目标,而目标检测定义为在一帧画面中找目标。目标识别是目标检测的集合。目标检测最终会得到两个结果,即目标的定位以及目标的分类。目标的定位是指在画面中预测出目标的位置,也就是目标的坐标值、高和宽;目标的分类是指正确判断出目标的所属类型。
随着计算机视觉科技的发展,目标检测技术先后发展出了两类检测模型。一类称为two-stage模型。这一类模型检测需要两个步骤,先对物体进行定位,然后再对物体做识别。这类模型的经典算法是R-CNN。该模型利用了选择性搜索(Selective Search)算法进行相邻子块的特征相似度评测,对相似图像区域打分以及合并,从而获取出感兴趣区域的候选框。这些候选框被输入到卷积神经网络提取出图像特征,再由支持向量机进行特征向量分类,最后做边框回归,最终完成目标检测及定位。two-stage模型最大的缺点是算法性能较低,不能满足实时要求。这源于需要对每一个生成的候选区域进行特征提取,存在大量的重复运算。虽然在R-CNN基础上做了一些改进,推出了fast R-CNN和faster R-CNN,但还远远满足不了人们对实时性能的要求。另外一种称为one-stage模型。该类模型把两个步骤优化成一个步骤,大大减少了计算量。YOLO模型是该类模型的杰出代表。
YOLO是You Only Look Once的英文缩写,包含着快速检测的意义。经过对比测试,YOLO模型在达到faster R-CNN同等准确率的情况下,表现出更高的识别速度,可以达到实时性的要求。
三、YOLO模型原理
YOLO模型与其他计算机视觉领域的模型一样,也是充分利用卷积神经网络(CNN)的研究成果,并对R-CNN家族算法做了架构上的优化统一。YOLO模型也创新了检测思路,它将目标检测作为回归任务来解决,实现了端对端(end-to-end)的检测,性能上得到了显著提高。
模型进行学习训练时,YOLO模型先将输入的图片分割成S×S的网格,每个网格单元负责检测中心点落在该网格单元内的目标。如图1所示,目标对象为一只小狗,其背景是树木和草地。小狗的中心点位于图像的中间位置,也就是加粗的小方格内,因此该网格单元将完成这个小狗的预测。每个单元格会预测B个边框的坐标值、高和宽,同时也给出边框的置信度值。YOLO模型的网络结构参考了GooLeNet模型,包含了24个卷积层和2个全连接层。
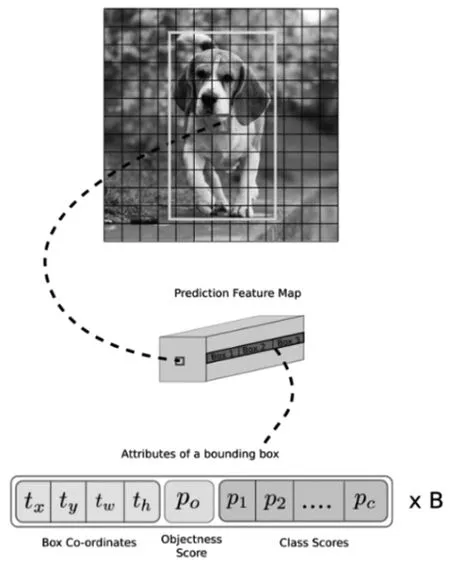
图1 YOLO原理图
模型在进行预测时,每个网格单元格都参与预测。每个网格单元格预测B个边框,因此会有B个边框置信度值,整个画面将产生S×S×B个预测框,且每个预测框给出C个目标类别的概率值。通过阈值选出概率值高的预测框,再通过非极大值抑制算法(non maximum suppression,NMS)筛选出符合度最高的边框。
四、衡量监测效果方法
为了量化目标监测的效果,需要定义相关指标参数。平均准确度均值mAP(mean average precision)是目标检测的常用评价标准,用于衡量识别精度。mAP应用于多类目标的检测,每一个类别存在一个AP值,多个目标时取其加权平均,也就是mAP。AP是查准率(P值,Precision)和查全率(R 值,Recall)综合考虑的值。查准率是指模型判为目标的结果中实际也正确的比率,查全率是指模型判断正确的数量占该类样本总数的比率。比如模型识别出10个目标,经过人工检查,这10个判断结果中正确的判断是8个,那么查准率为80%;但样本中却有16个是正样本,因此查全率是50%。AP在几何上是PR曲线下的曲线面积。准确率与召回率是反相关的关系,也就是增加准确率时会降低召回率,增加召回率意味着会降低准确率。结合广播电视监测行业对视频快速监测的业务要求,通常来说样本数是较少的,往往是几十到一两百个,且在视频中判断出有目标存在即可,因此可以适当牺牲查全率来获得较高的准确率。
五、目标监测步骤
本文假设以球星梅西作为监测对象。以人物目标作为识别对象,一方面是素材容易获得,另外在难度水平上,人物识别的难度高于大部分日常监测目标,可获得推广意义。本文将在windows10平台下训练和测试模型,使用YOLO模型的代码版本为v4。为了加快训练速度且考虑可接受的成本,选用Nivida GeForce GT 730作为GPU设备。其他相关软件版本如下:cuda10.2、cudnn7.6.5、Python3.7、VisualStudio2019、Opencv3.4.0。
(一)数据采集。工作中不能采集到很多且场景多样的样本,也没有足够时间进行标注。根据这个特点,本次研究只从3段录像中提取182张图片。实践证明,有意识地筛选出具有强烈特征区别的样本,可以提高准确度。如清晰反映出梅西的发型、球服、人脸、动作等的样本。数据采集是一件费力的事情,为了减轻工作量,可编写Python脚本。该脚本能够一边低速播放,一边接收键盘输入,按空格键将抓取一帧图片并保存到磁盘目录中。
(二)数据标注。实践证明,YOLO模型只识别一个对象比识别多个对象准确度低,这是由于多个识别对象可以相互作为负样本,正负样本同时存在可提高精度,因此在标注监测目标的同时也多标注一类辅助目标,本文选择足球为辅助目标。LabelImg是常用的目标标注工具,支持多平台。根据8:2的比例生成训练集和测试集,最终整理出训练所需的训练图片列表,测试图片列表,标注文件、文件存放路径。
(三)网络模型训练。本文使用迁移学习的方法进行网络模型训练。迁移学习是把已训练好的模型参数迁移到新的模型中来,起到帮助新模型快速收敛的目的。在样本少的情况下,该方法显得很有帮助。实践也证明,从已有的类似场景中迁移过来,花费时间不仅更少且效果更佳。训练经历了4个小时,loss值降到0.5后结束训练。
(四)网络模型测试与性能。图2是模型测试的效果截图,可以看到识别出梅西球星和足球,也给出了概率值。可直观地认为YOLO模型学习到了梅西的球服、肤色、动作等综合特征,而不是单纯地以白色球服、人体的轮廓来判断。测试显示帧率(FPS)在40左右,可以流畅播放。

图2 视频测试
(五)性能和效果分析。通过运行darknet.exedetector map命令可计算出mAP的值。IoU=0.5时mAP=87%,IoU=0.7时mAP=35%,因此在不要求框得十分完整的情况下,可以较好地查找到目标。
六、结语
通过上述讨论,可以得出YOLO模型应用于广播电视监测行业的视频监测是可行的,所需样本的数量、样本标注的工作量、模型训练的耗时、设备的成本等方面都是可接受的。为了减少误报率,一方面可以提高阈值,另一方面可采集并标注更多的训练样本(如500张以上且尽可能场景多样)。本文的研究过程使用了不同的工具,若能在一个系统中实现所有流程,将可以节约时间。
猜你喜欢
无线互联科技(2022年11期)2022-08-18
数字通信世界(2020年11期)2020-12-04
作文新天地(初中版)(2019年6期)2019-08-15
摄影之友(影像视觉)(2018年1期)2018-03-22
摄影之友(影像视觉)(2017年11期)2017-11-27
北京航空航天大学学报(2017年6期)2017-11-23
物流科技(2017年5期)2017-07-06
小雪花·成长指南(2016年9期)2016-10-12
办公自动化(2016年13期)2016-08-24
浙江大学学报(工学版)(2016年10期)2016-06-05
