
无监督领域自适应调制识别方法
2021-09-09 13:37毛红霞
探测与控制学报 2021年4期
毛红霞
(成都锦城学院计算机与软件学院, 四川 成都 611731)
0 引言
自动调制识别技术能够识别出特定通信信号的调制方式,在民用与军用领域有着较大的应用前景。目前主流的调制识别方法有两种:基于传统特征量的方法和基于深度学习的方法[1]。其中,基于传统特征量的方法通常首先提取接收信号的特征量,再通过一定的分类器进行分类。这些特征量主要包含瞬时特征统计量[2]、高阶统计量[3]、循环累积量、相关谱特征[4]等。该类方法中,所采用的分类器包含基础的门限分类器、决策树(decision tree)、支撑向量机(support vector machine)等机器学习通用分类器[5-6]。这些方法中,人为定义的特征往往受到不同信噪比、不同信道模型、不同参数估计精度(如载频、符号速率等)等因素的较大影响,因此其识别率在实际的应用中受到较大的影响。基于深度学习的调制识别方法中,文献[7]通过设计的卷积神经网络(convolutional nerual network, CNN)对11种调制数据进行分类,综合识别率达到了84%;文献[8]利用了开源的数据,利用循环神经网络(recurrent neural network, RNN)进行了调制识别;文献[9]综合研究了不同的深度神经网络对调制识别正确率的影响,这些网络结构除了CNN、RNN,还包含残差网络(ResNet)[10]、inception网络、卷积长短时网络(convolutional long-short deep neural network, CLDNN)等,发现了采用CLDNN网络在网络复杂度和训练时间有所提升的情况下,其识别率最佳;文献[11]研究了基于分离通道联合卷积网络的调制识别方法,并且证明了其相比于CNN网络和传统特征提取方法识别率有较明显的提高;文献[12]研究了基于VGG-19网络的调制识别方法,其利用试解调后的星座图作为输入,实现了对不同阶数的QAM信号的识别。
现有的方法在实际情况中,遇到变化的信道环境或变化的参数估计精度,可使调制识别的识别率下降。针对上述问题,本文提出无监督领域自适应(domain adaptation, DA)的调制识别方法。
1 信号模型与网络模型基础
1.1 调制识别信号模型
典型的已调信号(已经变换到基带)的离散信号模型可以表示为:
(1)
式(1)中,r(n)表示第三方接收的离散信号,fbias表示下变频时由于载频估计不准带来的频率偏移,T表示信号的码元周期,N表示符号序列的长度,h(n)表示信道的冲击响应函数,ε表示符号采样时间的偏移,w(n)表示加性高斯白噪声。接收信号的随机性主要体现在如下几个方面:
1) 由于载频估计的不准确带来的频偏;
2) 由于符号采样点的不准确带来的偏差;
3) 由于信道的变化带来的随机性;
4) 由于加性白噪声带来的随机性。
因此,本文在通过仿真产生数据集时,充分考虑了上面几种因素带来的不准确性,产生了不同信噪比下的不同调制识别方式的数据,并且为了验证迁移学习的有效性,产生了不同频偏和不同信道模型的数据,产生信号模型结构如图1所示。

图1 调制识别信号样本产生模型Fig.1 The model of the simulated signal for modulation recognition
1.2 调制识别经典神经网络结构
由于篇幅有限,此处仅对调制识别中经典的CNN网络和ResNet网络进行介绍。CNN网络中最重要的是卷积网络层,具有权值共享的特性,大大降低了神经网络的复杂性,并且使网络可以并行运算。文献[13]中利用CNN网络对基带的调制信号进行识别,其结构如图2所示,包含2层卷积层,2层全连接层。
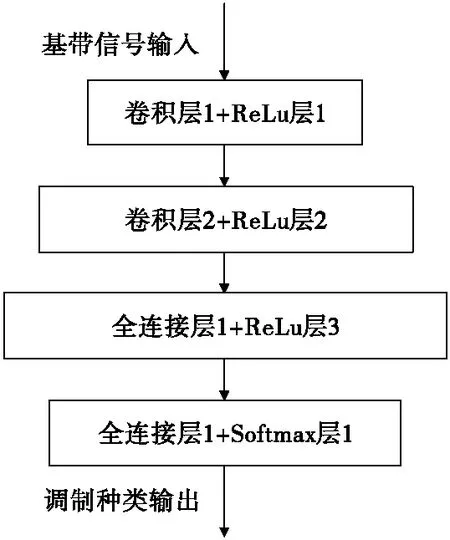
图2 调制识别经典CNN网络模型Fig.2 The classical CNN model for modulation recognition
ResNet网络的提出可以缓解由于CNN网络深度增加带来梯度爆炸或消失等问题,通过引入额外的网络通路,使得神经网络更容易被训练,同时也具有深层网络的丰富的表示特性[14-15]。文献[9]提出了利用ResNet网络进行调制识别的方法,其结构可以表示为图3。

图3 调制识别经典ResNet网络模型Fig.3 The classical ResNet model for modulation recognition
2 无监督领域自适应调制识别方法
本文提出的无监督领域自适应方法中,对源域与目标域分别进行了定义,如图4所示。源域表示已知调制方式(标签)的训练数据,它们在相同的信道模型中得到;目标域表示在不同的未知信道下获得的样本数据,并且无法得知样本数据的调制方式(即标签)。本文提出的方法能够充分利用源域中带标签的数据和目标域中不带标签的数据进行训练,使得神经网络对样本的来源(源域或目标域)不敏感,从而达到领域自适应的目的。

图4 目标域与源域在本文调制识别背景下的定义Fig.4 The definition of source and target domain for modulation recognition
领域自适应的迁移学习调制识别方法的基本网络结构如图5所示。为了能够进行迁移学习,对传统的神经网络结构进行了改进,改进后的网络呈现三个子网络:特征提取子网络、调制种类预测网络和域分类网络。其中特征提取子网络的主要功能是提取调制信号中的特征。这些特征既能够对不同的调制方式敏感,从而能够有效地进行调制方式的识别;同时也能够对不同的域输入不敏感,使得网络无法区分调制信号是否自适应于相同的信道或相同的频偏,也就是说使得提取的特征在不同域上的分布尽量相同,从而达到领域自适应的目的。调制种类预测网络一般为传统神经网络最后的全连接层和Softmax层,可以利用前面层级提取出的特征进行分类,生成样本属于不同种类的概率。在实际应用中,特征提取子网络与调制种类预测网络可以组成传统的调制识别神经网络,因此在后续的实际应用中,可以直接利用已有的调制识别网络构成特征提取子网络和调制种类预测网络。对于域分类网络,其主要目的是能够对样本来自于源域或目标域进行判别,并且产生反向的梯度,使得特征识别网络无法区分源域或目标域。
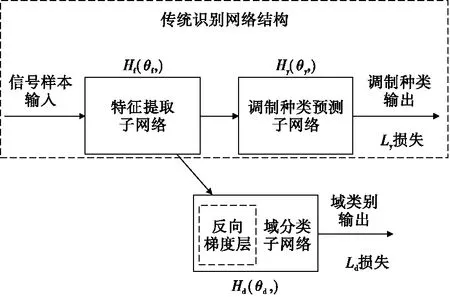
图5 本文领域自适应的调制识别网络节结构Fig.5 The domain adaptation based network for modulation recognition
图5中,特征提取子网络用Hf(·)表示,其参数用θf表示;调制种类预测子网络用Hy(·)表示,其参数用θy表示,其预测分类与真实类别带来的代价函数用Ly()表示;域分类子网络用Hd(·)表示,其参数用θd表示;域分类的代价函数用Ld()表示。该网络整体的训练代价函数可以表示为:

(2)
式(2)中的求和符号表示对所有训练样本求和,xi表示输入的信号样本。在训练的过程中,按照Lall最小化的目标进行优化,也就是使得调制种类预测的损失函数最小(从而达到更好的识别效果),并且使域分类损失函数最大(从而使网络无法区分源域或目标域),达到领域自适应的目的。参数η表示对两种损失函数的加权系数,作为一个超参数将在后续的实验部分进行研究。根据整体的损失函数,在训练时,可以对不同的子网络参数进行更新:
(3)
式(3)中,参数λ表示参数更新的速率。在应用中,为了不改变常见的神经网络训练模型中的梯度下降算法,根据损失函数,对域分类子网络进行改进,重新设计了反向梯度层,该层嵌入到原始的域分类网络与特征提取子网络之间,反向梯度层Greverse(·)可以表示为:

其特点是,在正向传播时,完全对输入进行复制,在反向进行梯度计算时,将原始的梯度乘以负的参数-η,从而达到最大化域分类损失的目的。
3 仿真实验及分析
3.1 数据集产生
本文利用开源的软件无线电软件GUN Radio进行数据集产生。由于该软件完全开源,能够以模块的方式实现通信系统中的组件,这些组件的核心信号处理功能通过C语言实现,具有速度快的优点,并且组件可以通过Python语言进行调用,具有易用的优点,因此本文选择GUN Radio软件产生仿真的数据集。在利用GUN Radio软件产生数据的过程中,参考了文献[16]所用的方法。如1.1节所示,考虑了由于载频估计的不准确带来的频偏,由于符号采样点的不准确带来的偏差,由于信道的变化带来的随机性,由于加性白噪声带来的随机性。产生的数据集包含了0~20 dB,以5 dB为间隔,5种不同的信噪比。调制方式包含模拟调制方式和数字调制方式,分别为AM、FM、GFSK、BPSK、QPSK、8PSK、OQPSK、8QAM、16QAM,9种常见的不同调制方式。图6显示了9种不同调制方式下20 dB的基带IQ路时域采样信号。如图6所示,单个信号样本中,包含IQ两路分别128个时域采样点。该数据集中,源域数据与目标域数据的不同主要体现在两个方面,如表1所示:第一方面,源域的数据无频偏,目标域的数据存在由下变频带来的剩余频偏;另一方面,目标域相比于源域,多加入了瑞利信道后产生的样本。在本文的实验中,利用上述两个方面的目标域和源域进行两次独立训练,从而探讨本文迁移学习的优点。
在实际训练过程中,选取256个样本数据为一个批次(batch),该批次中,包含源域的带标签的样本128个与目标域的不带标签的样本128个,进行训练。

图6 20 dB下不同调制方式的IQ路时域信号Fig.6 The IQ signal samples under 20 dB

表1 源域与目标域
3.2 超参数设置
在训练过程中,根据文献[17—18]中的描述对超参数η进行设置:
(4)
式(4)中,ηp的取值范围在0到1之间,ε为待确定的超参数,p表示训练过程中的识别率。用该方式设置超参数η的优点是;在前期识别率较低,η趋近于0,使得训练网络趋向于单纯的调制识别网络,而不考虑迁移的问题;当p增加时,η也随之而增加,表示训练随着特征提取与调制种类识别子网络的收敛,应当更多地考虑迁移学习的代价。其中ε表征了网络在训练过程中仅考虑识别率和域分类正确性(具有更强的域迁移能力)的转换速度。按照不同的参数ε,对本文方法中的神经网络进行了训练,其网络收敛时间和网络的识别率随着参数ε的变化如图7所示。图7中,左边的纵坐标表示识别率,右边的纵坐标表示训练时间。可以看出,随着参数ε的变化,神经网络的训练时间在ε=15的时候达到最小值,识别率在ε=20时达到最大值。本文中,选取ε=20作为超参数ε的取值。
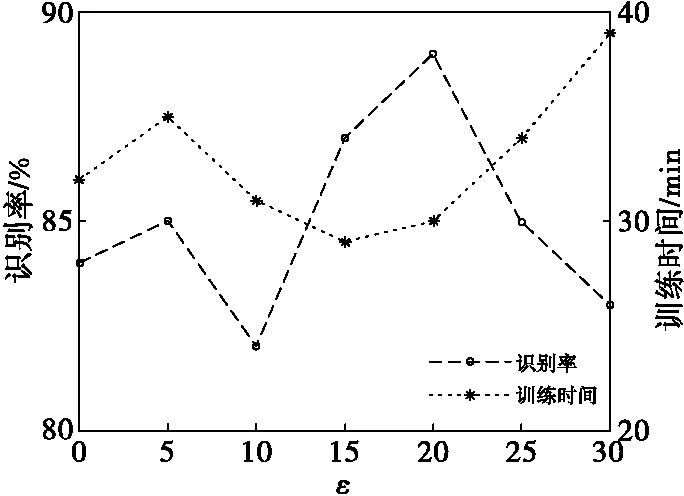
图7 训练所需时间与识别率随超参数ε变化曲线(CNN网络得到)Fig.7 The curves of the training times and the recognition rate due to different ε(with CNN network)
3.3 方法对比
为了充分说明本文提出方法的有效性,在实验中按照传统的CNN网络和ResNet网络进行了改造,按照上文所述方法加入了域分类子网络的内容,并且利用带标签的源域样本和不带标签的目标域样本进行训练。在改造后的网络基础上,分别对无迁移学习方法、有监督方法,以及文献中提出的基于精调迁移学习的调制识别方法[19]进行了对比。实验中用到的测试集都相同,包含了源域和目标域的样本。实验中对比的四种方法所用的训练集不同,其特点如表2所示。其中本文方法,利用带调制种类标签的源域样本和无调制种类标签的目标域样本进行训练;无迁移学习方法表示了仅利用带调制种类标签的源域样本进行训练;有监督方法中训练样本既包含了带标签的源域数据也包含了带标签的目标域的数据;参数精调迁移学习方法[19]表示首先利用带标签的源域数据进行训练,再利用少部分带标签的目标域的数据进行参数精调。表3为以CNN为基础网络的方法和以ResNet网络为基础的方法对比。

表2 不同方法训练集特点
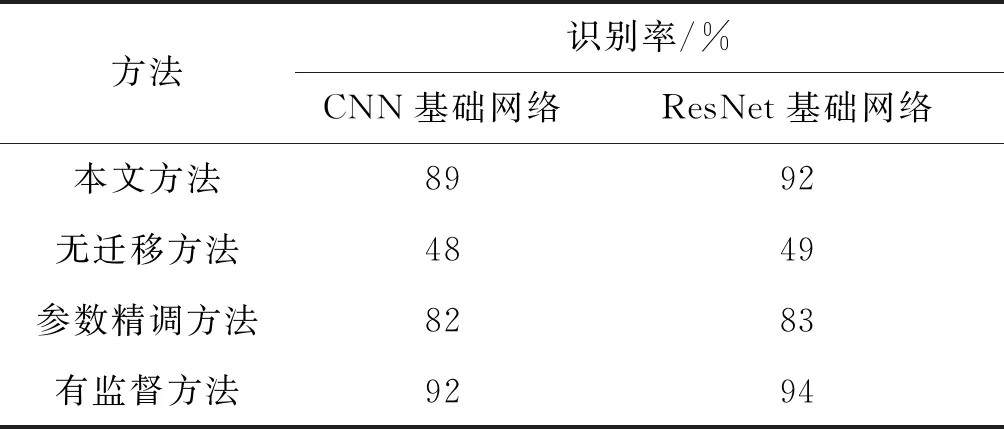
表3 不同方法正确识别率
从表3可以看出, ResNet整体来说相比于CNN网络存在更高的识别率,与前人的结论一致。在CNN为基础的方法中,本文方法相比于无迁移学习方法和参数精调迁移学习方法,识别率分别提高了约41%和7%,说明本文提出的无监督迁移学习(此处指源域数据无标签)方法能够充分利用无标签目标域数据自身的分布特性,对神经网络进行调整,从而使特征提取子网络能够适应不同分布的源域和目标域样本的输入。而基于参数精调的方法由于仅仅依赖少许带标签的目标域的数据,无法充分利用所有的目标域数据,因此其识别率低于本文方法。本文方法相比于有监督的方法识别率仅低3%,说明本文方法几乎达到了识别率的上限(即同时利用带标签的源域和目标域进行训练)。在实际应用中,通常仅能够大量获取无标签的目标域数据,因此本文方法相比于有监督的方法,具有更强的实用性。在以ResNet为基础的方法对比中,本文方法相比于无迁移学习的方法和参数精调迁移学习方法,识别率分别提高了约43%和9%,相比于有监督的方法识别率仅低2%,能够得到类似上述的结论。
4 结论
本文提出了无监督领域自适应的调制识别方法,该方法在传统识别网络中加入域分类子网络,在训练的代价项中加入域分类代价,使得网络能够同时适应目标域和源域。通过开源的GUN Radio软件产生的仿真数据集验证,证明了该方法相比于无迁移学习和基于参数精调的方法,在CNN为基础网络的条件下识别率分别提高了41%和7%,在ResNet为基础网络的条件下识别率分别提高了43%和9%;并且,该方法接近于同时利用目标域和源域数据进行训练后的调制识别率的上限,在CNN和ResNet为基础网络的条件下,仅分别下降了3%和2%。下一步将对更高阶的MQAM信号进行调制识别,研究频偏等因素对高阶信号识别率的影响。
猜你喜欢
计算机技术与发展(2020年11期)2020-12-04
海峡姐妹(2018年3期)2018-05-09
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
青年文学家(2015年29期)2016-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
