
基于How Net义原和W ord2vec词向量表示的多特征融合消歧方法
2021-09-09 08:09:18赵尔平崔志远
计算机应用 2021年8期
王 伟,赵尔平,崔志远,孙 浩
(西藏民族大学信息工程学院,陕西咸阳 712082)
0 引言
近年来,随着自然语言处理(Natural Language Processing,NLP)与人工智能(Artificial Intelligence,AI)的迅速发展与广泛应用,命名实体消歧作为自然语言处理的关键环节,在信息检索、知识库及知识图谱构建等方面发挥着越来越重要的作用。命名实体消歧旨在解决实体指称间的歧义性与多样性,例如“冬虫夏草”的别名分别有“夏草冬虫”“虫草”和“冬虫草”,把这种表达相同实体而有多个指称的词语称之为指称多样性。而“螃蟹甲”一词,它一方面指代藏药的名称,另一方面又指代武汉的一个地名。像“螃蟹甲”这类词称之为多义词,本文旨在研究多义词的歧义消除问题。
至今,命名实体消歧主要采用联合知识、机器学习和深度学习等方法实现,其中大部分方法都是考虑全局信息,却很少考虑局部信息。王瑞等[1]针对消歧任务,充分利用上下文以及词向量特征信息以达到提高准确率的目的。马晓军等[2]将消歧方法融入了局部信息来解决多义词不能被区分的问题,但是词向量的质量和稳定性没有兼顾。杨陟卓[3]提出基于翻译的有监督词义消歧方法,该种方法虽然能大幅度提高准确率,但是需要大量的人工标注语料且伪训练语料需要随着消歧任务的不同而改变。王苗等[4]提出的消歧方法,通过改进的无监督学习并结合图数据结构以达到消歧的目的并取得较高准确率。陈洋等[5]则针对词向量表示的质量问题,使用义原表示词向量,很好地解决了词向量表示不稳定的问题,但是却没有注意到词义混淆问题。范鹏程等[6]使用知识链接的方法达到了目前最好算法的F1值。很显然有监督学习方法虽然人工工作量大,但是消歧效果较为出众。基于机器学习的消歧方法,面临的问题是需要准确且质量较高的语料库支持,需要花费人力标注语料,且需要关注数据稀疏问题。目前,实体消歧任务重点是在上下文信息和特征信息挖掘两个方面,缺乏在不同应用场景下面对不同特征时区分实体能力的差异分析。在低频词方面,使用词向量进行消歧时由于词频低导致训练不充足,使得词向量表示的质量得不到保证。在语义表示方面,缺乏结合上下文语义综合考虑多义词的多方面特征,未能将词语多个语义特征按权重值融合使用。譬如,西藏畜牧业领域有上千种牧草名和几百种动物名,包括大量音译词、合成词、生僻词等类型低频词。例如“雪莲花”一词,在大多数语料库中都属于低频词,该词义项包含两类:一类属歌曲,一类属藏药。多义词方面例如“我今天在阿里吃的饭”这句话中“阿里”一词可能指西藏阿里地区,也有可能指“阿里巴巴”公司。
针对命名实体消歧过程中存在问题,本文提出基于HSWR-W 2c(HowNet-Sememe Word embedding Representation-Word2vec)词向量表示的多特征融合消歧方法。通过两种词向量融合表示来解决单一词向量表示低频词质量差、不稳定和多义词的词义混淆问题。为了体现每一类特征在消歧过程中发挥的不同作用,提出三类不同词向量特征加权融合的消歧方法,以解决消歧过程中因词向量携带信息量少、语义特征单一而导致的准确率不高的问题,并引入主题特征弥补以往消歧任务未能获取局部特征的缺陷。
1 相关工作
Word2vec(Word to vector)是一款开源词向量生成工具,被广泛应用于图像处理、知识挖掘、自然语言处理等领域。由于中文词语多元与复杂性,导致Word2vec在自然语言处理方面的应用效果不尽如人意,为此李小涛等[7]为了提高语义相似度计算精度提出一种改进算法,弥补Word2vec生成的向量不能区别多义词的缺陷。近年,面对中文语言的多变性与词语的多义性,很多学者从向量的使用到向量的改进做了一系列研究工作。张春祥等[8]利用邻近词的词性、词形等相关信息作为特征融入消歧任务中,取得了较好的效果。
词义消歧方面张雄等[9]采用融合多个特征的方法,达到对于信息的充分挖掘,实现人名消歧。大部分学者采用机器学习进行词义消歧[10],例如王旭阳等[11]通过对于上下文信息的充分挖掘,并结合机器学习达到消歧的目的。Mikolov等[12]则揭示连续空间词表征中的语言规律,使得语境信息能更好地融入。郭宇飞等[13]根据同一个词在不同的上下文环境下可以形成不同的框架,提出了一种基于框架的消歧方法。Huang等[14]则是通过对百度百科全书网页的抓取,产生多义、同义和索引集合,经过训练后确定文本相关性,并在MongoDB(Mongo Data Base)中管理实体。除了常见的消歧方法,Chen等[15]通过结合词义对模型改造,在中大型文件消歧方面也取得了不错的效果。林泽斐等[16]将多特征与实体链接技术结合实现词义消除。曾健荣等[17]则针对专家库构建过程中的同名歧义问题,融合已发表论文中的多种特征从而解决了同名消歧问题。
2 义原与Word2vec词向量及融合表示
2.1 HowNet及其义原
知网(HowNet)是一个解释词语概念与属性间关系的知识库。义原是知识库中不能再分割的最小的单位[18],所以在知网知识库中每一个词语都可以使用若干义原表示。也正是HowNet的这种多义原表示方法,使其能够突破词语本身,从而更加深入了解词语背后的意义。这种结构化的知识网络体系,使得知识对于计算机而言是可操作的,正是因为这一点,知网中的义原词才能够表示为可以操作使用的词向量。由于HowNet知识库中有关于西藏畜牧业领域的记录较少,所以本文对知识库进行了扩充。扩充示例内容如下:{NO.=120497;W_C=螃蟹甲;G_C=N;E_C=;W_E=Crab carapace;G_E=N;E_E=;DEF=Tibetan Medicine|藏药,street|街道}。其中:NO.在知识库中表示序号;W_C、G_C、E_C表示中文信息,分别代表词语、词性以及举例;W_E、G_E、E_E表示英文信息,分别代表英文的词语、词性以及举例;DEF为词语诠释,即词语的不同义原。
2.2 基于HowNet义原的词向量表示
基于HowNet义原的词向量表示(HowNet-Sememe Word embedding Representation,H-SWR)流程大致有两个步骤:首先对义原进行向量化;其次融合目标词的若干义原词向量生成目标词向量。具体表示过程如下。
首先,使用随机初始化的方法将义原初始化为一个义原矩阵Msememe,其次,将义原矩阵进行预处理(施密特正交化、单位化)后得到正交单位矩阵Mdefo:

式(1)中Mdefo是 一 个n×m的 义 原 矩 阵,其 中(α1,α2,…,αn)为对应义原向量的n组标准正交单位基,其中每个义原向量为m维。由于在HowNet中每一个词语由若干义原解释,所以可以把目标词看成其对应义原词向量在其向量子空间的投影。最后,在完成义原的词向量表示后,目标词语的词向量便可使用义原向量的加权平均表示,表示公式如式(2)所示:

式(2)中α为目标词对应义原词向量表示,m为当前目标词的义原数量。对于义原向量与义原的对应关系,本文采用建立索引的方法,即每一个义原向量及其对应义原建立“semid”,其中一个义原的sem对应一个义原向量的“id”,通过“id”再进行look-up操作,以此确定它们的对应关系。
语料训练方面,本节以“藏医藏药雪莲花作为药物”句子为例,空格为词语之间的分隔符,待预测词语为“雪莲花”。基于义原生成的词向量训练过程如图1所示。

图1 基于义原的词向量表示Fig.1 Word embedding representation based on sememe
示例中根据窗口大小找到左右各两个词语的id,再根据id找到标注的义原,义原生成义原向量,最后借助式(2)和上下文表示层得到标准词向量表示并通过输出层输出。图1中上下文表示层定义如式(3)所示:

其中:Ci为目标词上下文词向量,δ为定义的窗口大小。训练方式与连续词袋(Continuous Bag Of Words,CBOW)模型相似,指定窗口大小为5,维度为100。由于基于义原生成的词向量是借助于有知识基础的模型上计算得出,所以蕴含大量语言学知识,即使在大规模语料中也能表现出较好的稳定性,并且生成的词向量只受义原信息的约束,所以在低频词表示方面表现出色,但这也导致其在词义区分方面尚有不足,存在词义混淆的弊端。
2.3 基于Word2vec的词向量表示
词向量的表示方法中,One-hot最为直观简洁,这种表示方法较为简单,由数字1与0组成,向量长度为文本词的个数且数字“1”唯一,但是该种方法会带来数据稀疏问题,尤其在维度较大时不宜采用。另一种词向量表示方法为分布式表示,对比One-hot方法,该方法将词映射在向量空间以解决数据稀疏的问题,一般训练维度在100~300维,能较好地体现词语间的相关性与依赖性,所以在词向量的表示过程中一般都是采用分布式的办法。
比较Word2vec的两种模型,CBOW模型在语义表示方面效果更优,所以本文选用CBOW模型。训练参数窗口大小设置为5,同时为了词向量的融合表示,训练维度与2.2节维度保持一致。假设输入词序列为C=(x1,x2,…,xn)的情况下,CBOW目标函数定义如下:

其中:m为窗口大小,n为词数,xi为预测目标词。P为上下文已知的xi的概率,通过softmax函数计算:

其中:wi为中心词的词向量表示,wo为wi的上下文词语的词向量的均值。
向量训练过程中采用随机梯度上升法将目标函数最大化,再经过语料库整体的训练,最终得到词典库中每个词对应的词向量。由于CBOW模型生成的词向量是经过充分的训练而获得的,所以在语义表示与区分方面十分出色,但是也存在低频词表示质量较差、在大规模语料中表示不稳定等问题。以“鼠兔”一词为例,在领域语料中出现的频率不足万分之一,在普通语料中更低,使得机器对其学习不充足而导致上述问题。
2.4 词向量加权融合
词向量表示方面,基于Word2vec生成的词向量在词语语义表示方面十分出色,但是这种通过机器训练和依赖数据驱动的方法,使词向量表示在低频词方面质量不高,且在语料较大时生成词向量的性能不稳定。而依赖HowNet知识库义原生成的词向量,虽然能较好解决上述问题,但是在词义区分方面尚有不足,存在词义混淆的问题。针对单一模型训练的词向量表示词义混淆、质量差以及稳定性等问题,采用两种词向量加权融合的表示方式,取长补短,弥补单一词向量表示的不足。本文采用线性归一化的方法融合词向量,其中基于HSWR生成的词向量定义为WHownet,基于Word2vec生成的词向量定义为WWord2vec。融合向量表示公式定义如式(6)表示:

其中式(6)中的符号⊕为各向量逐元素相加,归一化公式本文采用sigmoid函数,对W进行线性归一化,具体公式如下:

3 实体消歧
实体消歧分为五步:1)候选实体生成;2)实体相似度计算;3)类别相似度计算;4)主题相似度计算;5)三类相似度融合。消歧流程如图2所示。

图2 消歧流程Fig.2 Disambiguation flow
本文采用无标注的知识库文本训练词向量模型,通过训练将每个词映射到词向量空间中,两个模型的向量分别体现了知识的融入和词语在深层次的一些语义特征。其次,生成候选实体集,目的是为每一个待消歧指称项提供若干个可能的候选实体以防止在消歧过程中需要查找整个知识库而导致低效问题。从候选实体与背景文本中获取指称项与类别名称,并使用两个模型进行向量化及融合表示以计算实体相似度与类别相似度。利用主题模型对文档进行训练,使用聚类算法对主题特征的关键词进行分类,融合词向量对其进行表示并计算主题相似度值。最后将三类相似度值进行加权融合,选取最高准确率的数据为结果,达到消歧目的。
3.1 候选实体生成
百度百科作为中文知识库,它在更新中文知识方面比维基百科及时,而且能提供有助于获取信息的结构特征,所以本文通过百度百科获取实体的名称及其对应关系。候选实体生成的具体过程如下:首先,对待消歧文档进行实体标注,并将标注出的实体作为待消歧实体;其次,根据标注实体获取百度百科页面信息,同时保存百度百科中对应的标注实体名称;再次,通过消歧页面,获取与标注实体名称相同但是指代不同的实体;最后,将上述与待消歧实体名称相同的所有词语保存作为候选实体。
3.2 待消歧实体与候选实体相似度计算
对于实体间相似度计算。首先,对待消歧文本进行分词以及停用词过滤等操作;其次,根据2.4节将两种词向量进行融合表示以获得待消歧实体指称项的融合词向量表示;最后,通过候选实体信息摘要以获取候选实体背景文本,预处理后生成候选实体融合词向量表示。融合后的词向量表示可以很大程度地代表这个词。本文通过对比待消歧实体与候选实体的融合词向量相似度来判断二者是否具有联系,与其他研究一样,本文也利用余弦相似度值衡量待消歧实体与候选实体相似度,比较它们之间的依赖关系。余弦相似度计算公式如式(8)所示:

其中:c表示待消歧实体指称项目词向量,gi表示候选实体指称项词向量,式(8)结果代表待消歧实体与候选实体之间的语义依赖关系强弱程度,即它们之间语义关系相似程度。
3.3 实体类别特征相似度计算
实体间的包含关系又称为上下位关系,本文借助上下位关系中的上位词使得词语有更多的词义信息,将其作为实体类别特征,计算实体类别相似度。上下位关系层次结构如图3所示。
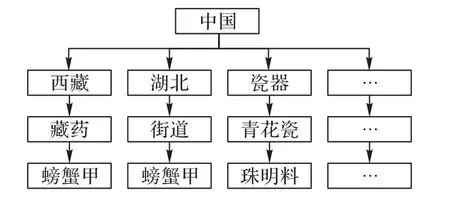
图3 上下位关系Fig.3 Upper-lower relationship
图3中可以看出“螃蟹甲”的上位词为“藏药”和“西藏”,也可以是“街道”和“湖北”。上位词“藏药”和“西藏”表示“螃蟹甲”属于藏药类别;上位词“街道”和“湖北”表示“螃蟹甲”又属于地名类别。藏药类别与地名类别是两个完全不同的实体类别,代表完全不同的语义。由此可见,把实体的类别特征用于实体语义消歧是非常必要的,类别特征在消歧任务中必将发挥重要作用。对于待消歧实体,本文使用聚类算法对词向量进行分类,并利用式(8)计算每个词向量的空间距离,选择离聚类中心最近的若干词作为类别特征高频词语,然后在HowNet知识库中进行“查找”操作,查找高频词的若干上位词作为类别名称。例如“牦牛”的上位词有“牲畜”与“纪录片”等,将它们作为“牦牛”的不同类别名称。再次,为保持候选实体类别名称与候选实体指称的一致性,本文选择从百度百科词条标签中获取候选实体类别名称,获取的候选实体类别名称与待消歧实体类别名称进行相似度比较,以计算二者相似度。例如待消歧实体“冬虫夏草”的上位词为“菌”与“保健品”等,而其候选实体的类别为“麦角菌科”与“藏药”等。将候选实体每个类别名称与待消歧实体每个类别名称分别两两交叉配对,例如(菌 麦角菌科)、(菌 藏药)、(保健品 麦角菌科)、(保健品藏药)等类别名称对,然后利用式(8)计算每一对词语的相似度值。每一对相似度定义为ei,并对它们进行排序,为每个候选实体保留一个最大相似度值,类别特征相似度公式定义如(9)所示:

3.4 实体主题特征相似度计算
潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)主题模型是一个依赖于词袋(bag of words)生成文本主题的具有三层结构的贝叶斯概率模型。工作原理是将文档形象化为一个词频向量,从而使得文本信息转变为可用于建模的数字信息,但是这也导致其没有改变词与词之间的顺序,所以本文不得不对LDA主题模型进行适当改进。文章通过对不同主题的多义词进行标注,使用W′=w,t对多义词与主题特征词语进行联合表示取代原先存入词袋模型的多义词,并通过原先模型进行语料训练从而得到不同主题下的词向量表示以解决词序问题。同时对词向量进行聚类操作,使用式(8)计算向量距离,获取离聚类中心最近的若干词作为主题关键词,使词向量携带主题特征信息。具体步骤如下:
首先,对待消歧文本进行过滤停用词以及断句等预处理,利用改进的LDA主题模型对预处理文档进行主题建模,借助Gibbs抽样算法选取最佳参数。其次,引用支持向量机的方法进行聚类操作,并由上述被替换原词袋模型的训练好的模型进行分类,确定局部文字主题,并对主题文本进行融合词向量表示。利用K-means聚类算法实现分类并使用余弦相似度计算每个词向量的空间距离,选择距离聚类中心最近的若干词作为主题特征关键词。最后在主题关键词提取过程中获取不同主题关键词集合,将不同聚类结果的关键词进行融合词向量表示,其中词语不同类别个数为后续主题特征个数,将在同一主题特征下的关键词设为集合S,关键词个数定义为m,集合中的关键词定义为i,融合词向量表示为wi(i=1,2,…,m),候选实体摘要文本经过分词、去标点等预处理后使用H-SWR进行词向量表示,再使用Word2vec进行词向量表示,最后融合词向量表示定义为ni,可得主题特征相似度定义式(10)所示:

本文通过改进的LDA主题模型,即将原先多义词通过标注并添加主题信息以取代原来的词语,使得其得到的关键词集合都属于同一主题,从而较好地解决了本节开头提出的问题。
3.5 融合三类特征相似度
为了充分利用多类特征相似度进行实体消歧,同时也能最大限度地提高消歧准确率,本文采用加权融合的方法对多类特征进行融合。多特征融合相似度定义为:E=αE1+βE2+χE3,其中:E1表示待消歧实体与候选实体相似度,E2表示实体类别特征相似度,E3表示实体主题特征相似度。通过八组比较实验结果获得一组最佳权重系数。第一组实验中设置α=0.1不变,β、χ初值分别为0.1和0.8,以这三个参数为权重值系数计算相似度值并记录,之后β、χ值分别以正负0.1步长进行调整,每次调整后的新参数作为权重值系数计算相似度值并记录,以此类推,β、χ的终值分别为0.8和0.1,然后选取这组实验中相似度值最大的那次实验的权重值系数作为第一组实验结果并记录。第二组、第三组、……、第八组实验中设置α值分别分为0.2,0.3,…,0.8;β、χ取值与第一组实验方法相同,分别获得其他七组实验的最好权重值系数,最后比较八组实验获得的八个相似度值,选择最高相似度值的那组参数值作为α、β、χ的最佳权重系数。
4 实验与结果分析
4.1 语料的获取和模型的训练
使用H-SWR进行词向量表示方面,得出模型后输入语料进行训练,语料的训练方式与CBOW模型相似。为了防止两类词向量融合维度出现过高的情况,实验指定窗口大小为5,维度定为100,实现平台为PyCharm 2018.3.7。在使用Word2vec进行词向量表示方面,训练模型采用连续词袋模型,定义窗口大小为5,维度100。对于语料选择方面,本文使用维基百科离线知识库进行训练。
候选实体获取方面,由于百科知识库中涉及领域太广,所以本文选择西藏畜牧业领域分类下的页面信息,进行摘要提取,候选义项摘要保存于文本。测试语料爬取有关西藏畜牧业领域的文本共30篇,还有手工标注的西藏畜牧业领域的文本10篇,其中标注文本中的词数共计161 518个,标注有关领域实体指称29692个。标注的每一篇文本中的实体名称通过与获得的候选实体对比作为实验的结果的验证。使用准确率判断本文方法的优劣与可行性,准确率定义如下:

4.2 词向量融合表示的效果分析
该组实验用于对比词向量融合与否对相似度计算准确率的影响。词向量相似度对比的优劣通常可以通过观察给定词对的评价分数来判定其优劣程度。所以本文采用斯皮尔曼(Spearman)系数用于评估词语相似度准确率,Spearman系数是一种评价词语相似度算法准确度的有效方式,计算公式如式(12)所示:

其中:p表示斯皮尔曼相关系数,系数越大说明用于计算相似度的词向量更为优质;n表示元素个数;di表示一个排行差分集合中的元素,本文将获得的相似度经过比例缩小后与其对应人工评分定义为变量(X,Y),并对两个变量的数据进行排序并记录为(Z,W),其中(Z,W)的值便为秩次,而秩次间的差值就是di。本文用于测试的标准数据集为wordsim-240,每行格式为一对标准词对与数值在0~5的人工评分。实验结果如表1所示。

表1 Spearman相关系数对比Tab.1 Spearman correlation coefficient comparison
由实验结果可知,由人工知识与机器学习的词向量的结合是切实可行的,并且在词向量相似度计算的过程中表现出色。
4.3 权重值对实验结果影响
在消歧过程中,实体相似度、类别特征相似度以及主题特征相似度所占权重的不同对实验准确率有着很大的影响,通过实验的方法验证最佳权重值系数,把消歧准确率最高的权重值系数作为最佳系数,实验结果如表2所示。
对于权重值的选择方法如3.5节所述。即将三类特征权值总和定义为1,同时在不知道每一项权重值大小的情况下首先固定某一项权重值,同时对其他两项权重进行每次步长为0.1的调整,观察固定一项权重值不变时另外两项权重值变化的结果并记录这一组数据的最高值,之后固定权重值加0.1,并按上述方法推演。最终获取固定权重值为0.1~0.8的八组最高数据如表2所示,加粗字体为准确率最高权重值系数。最佳权重值为:α=0.3,β=0.2,χ=0.5。

表2 权重值选取数据汇总Tab.2 Selected weight value data summary
由于待消歧实体与候选实体相似度计算包含词语及其语义信息,且融合后的词向量携带大量结构化知识的信息,所以融合特征相似度占有比较重要的地位。对于类别特征相似度计算,由于其本身存在的作用是区别词语的不同类别特征,而类别的获取是聚类后的结果,致使该类特征所携带的语义信息相比前者较少,所以占比重较小。主题特征相似度方面,由于本文使用改进的LDA主题模型,使用携带特征信息的词语替换词原始词袋中的多义词,使得主题特征与唯一词语对应,很大程度解决了词语缺乏局部特征的问题,所以其不单携带词语本身语义信息,还具有大量的主题特征信息,所以其占比重最大。综上所述,因为不同的特征所携带的语义信息量不同致使权重值系数也不相同,而在本文消歧过程中待消歧实体与候选实体相似度与主题特征相似度的信息量明显更大一点,从而也起到了更为重要的作用。最终获取融合相似度后,对其进行排序操作,选取最高一组数据为最终结果。
4.4 特征关键词个数的影响
类别关键词与主题关键词数量多与少会影响消歧结果,为此通过实验来验证关键词数量对消歧结果影响,以确定最佳关键词数量。由图4可知,类别关键词为4个时消歧效果最好,这是由于如果关键词个数较少,所携带信息不足,而过多又会使得信息覆盖范围变广反而降低准确率。对于主题关键词个数,由实验结果可知当其在8个时消歧效果最好,相比类别特征,主题特征能更好地表示一个词语的语义,所以关键词个数较多。

图4 特征关键词数对准确率的影响Fig.4 Influenceof thenumber of feature keywordson accuracy
4.5 消歧效果对比
实验主要选择三个典型的消歧方法对本文方法的效果进行检验,它们分别为W ikify[19]、支持向量机(Support Vector Machine,SVM)[20]以及Knowledge Base[21]。Wikify着重于使用实体链接的方法以达到消歧的目的;以Knowledge Base为基础的消歧方法,特点是十分依赖知识库;SVM消歧的方法是一种图模型结合实体链接的消歧方法。实验结果如表3所示。

表3 不同消歧方法的准确率对比 单位:%Tab.3 Accuracy comparison of different disambiguation methods unit:%
从表3可看出,本文方法对比其他消歧方法准确率有所提高,与典型的图模型消歧方法相比准确率提高了7.6个百分点。与上述三种方法相比。本文方法首先增强了词向量表示的质量,其次弥补了词语语义容易混淆的不足,最后在消歧过程中添加了主题与类别特征信息以使得准确率有所提高。这说明多种词向量融合表示的多特征融合的消歧方法切实可行,融合后的词向量表示在相似度计算以及消歧方面中的效果也更为出色。
5 结语
本文针对主流消歧方法因信息携带不足而导致的消歧模型对多义词不能准确区分以及对于词向量表示低频词质量差,表示的语义信息容易混淆等问题,提出词向量的融合表示以及词语的多特征融合方法。实验结果表明,准确率比典型的图模型消歧方法有较大提高。下一步,将尝试融入深度学习并改进获取词向量特征的方法,减小消歧任务工作量,进一步提高准确率。
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
中国外汇(2019年18期)2019-11-25 01:41:54
电脑与电信(2018年12期)2018-03-23 02:37:20
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
