
融入时间的兴趣点协同推荐算法
2021-09-09 08:09:26陈红梅
计算机应用 2021年8期
包 玄,陈红梅,肖 清
(云南大学信息学院,昆明 650500)
0 引言
随着全球定位系统、移动互联网等信息技术的发展以及移动设备的普及,基于位置的社交网络(Location-Based Social Network,LBSN)受到越来越多人的喜爱,人们在网络平台(如Yelp、微博、Twitter等)上分享丰富的位置相关信息,使得位置数据激剧膨胀,导致信息过载,不论服务商还是用户,都难以从海量位置数据中获取感兴趣的信息,于是位置推荐应运而生,其中兴趣点(Point-Of-Interest,POI)推荐备受关注。POI推荐是根据用户的POI访问历史,以及用户和POI的描述信息,分析用户兴趣偏好,发现用户潜在感兴趣的POI并推荐给用户。POI推荐不仅可以帮助用户快速获取所需信息,改进用户体验,也可以帮助服务商快速定位目标客户,提高商业利润。
传统POI推荐大致可以描述为:首先,将用户的POI访问历史建模为一个二维签到矩阵User-POI,用以表达用户访问POI的情况,例如,如果用户u访问过POIl,则签到矩阵元素(u,l)的值1,否则为0。然后,基于签到矩阵User-POI,采用协同过滤技术,学习用户的POI偏好,估计用户没访问过但可能感兴趣的POI评分,即签到矩阵中为0的元素的可能值。最后,按估计的评分高低,将用户没访问过但可能感兴趣的POI推荐给用户。
为了提升POI推荐效果,研究者在传统推荐的基础上,融合上下文信息,如用户间的社交关系、POI间的距离关系等。最近,研究者也开始关注用户访问POI的时间信息。文献[1-2]的研究表明,人们一天的活动具有规律性。例如,中午12点用户大概率访问餐馆,半夜12点访问酒吧等。在POI推荐中,如果不考虑时间因素,则可能出现中午11点向用户推荐酒吧,晚上12点向用户推荐餐馆,降低POI推荐效果。因此,在POI推荐中,时间是一个重要的影响因素。
基于上述分析,本文研究融入时间的POI推荐,问题描述为:根据用户的POI访问历史(包括用户、时间、POI信息),分析用户的访问时间及POI偏好,发现用户潜在感兴趣的POI及访问时间,按时间推荐POI给用户。为解决该问题,本文主要做了如下工作:
1)首先,分析用户的POI访问历史,探索用户访问POI的时间关系,发现两个关于不同时间片间POI访问相似度变化的规律。
2)然后,基于上述两个发现规律,提出新的用户签到数据平滑方法和候选POI评分计算方法,进而提出一个融入时间的POI协同推荐模型。
3)最后,在两个真实数据集Foursquare和Gowalla上进行实验,评估所提出的推荐模型。实验结果表明所提推荐算法在精确率、召回率、平均绝对误差方面均优于对比算法。
1 相关工作
推荐系统广泛采用的技术是协同过滤(Collaborative Filtering,CF),可分为基于记忆的协同过滤(Memory-Based CF)和基于模型的协同过滤(Model-Based CF)。基于记忆的协同过滤又可分为基于用户的协同过滤和基于项目的协同过滤。该类方法依据相似的用户(项目)具有相似的偏好,主要包括两个关键步骤:首先计算用户(项目)相似度,然后利用相似用户(项目)的加权评分估计目标用户对未评分项目的评分,从而根据评分形成推荐列表[2]。基于模型的协同过滤采用数据挖掘和机器学习,建立推荐模型,该类方法包括决策树模型、贝叶斯方法、矩阵分解方法等[3]。
针对位置数据膨胀及信息过载,上述推荐技术被用于POI推荐,在此分两类进行介绍:
1)POI推荐。
为了提升POI推荐效果,研究者在传统方法上融合上下文信息,如用户间的社会关系、POI间的距离关系等。文献[4]采用线性插值将用户间的社会关系以及POI间的距离关系融入基于用户的协同过滤框架;文献[5]在基于用户的协同过滤框架中融入用户间的社会关系,并贝叶斯方法对空间影响进行建模;文献[6]探索用户的2-度好友的社交影响,采用PageRank算法计算地点影响力,采用核密度估计方法发现用户的位置偏好,最后将三者融合进行POI推荐;文献[7]将用户偏好和个性化的地理社会影响整合到地理社会推荐框架中,提出一种潜在的基于地理社会关系的POI推荐模型;文献[8-10]利用社会友谊提高推荐的效率和性能,计算所有用户之间的相似性,并利用用户相似性作为正则化约束矩阵分解。
2)考虑时间因素的POI推荐。
由于用户会在不同的时间访问不同类型的POI(如餐馆、咖啡店、酒吧),所以时间是POI推荐中的重要因素。为了进一步提升POI推荐效果,增强用户体验,最近,研究者也开始关注融合用户访问POI的时间信息,提出了考虑时间因素的POI推荐。文献[2]在基于用户的协同过滤框架下建模用户偏好和时间影响,采用幂律分布建模地理影响,提出了融合时间与地理影响的时间感知POI推荐算法;文献[11-12]中提出了一种基于张量因子分解的协同过滤方法,利用一个高阶张量来融合用户签到的异构上下文信息——时间信息、社交关系、地理位置;文献[13]用概率模型将用户对地点的兴趣度,用户所处的时间段和地点自身的流行度融合起来进行POI推荐;文献[14]在基于用户协同过滤的基础上,结合有序图探索用户偏好,基于用户当前时间的位置,为用户推荐下一个访问的POI;文献[15]将用户签到的时间信息以及空间信息融入用户相似度的计算中,提出一种改进的基于用户协同过滤的算法;文献[16]用有向图表示用户的历史访问数据,考虑相似用户、时间以及签到序列,基于图的性质提出一种新颖的基于用户协同过滤模型。
本文受文献[2]启发,研究融入时间的POI推荐,但是与文献[2]不同,本文深入分析用户签到的时间关系,基于两个关于不同时间片间POI访问相似度变化规律的发现(将在3.1节中详述),提出新的用户签到数据平滑方法和候选POI评分计算方法,进而提出一个融入时间的POI推荐模型,不仅有效解决了签到数据的稀疏性问题,还获得了相对较高的推荐质量。
2 基于用户的协同推荐
本文所用符号和含义描述如表1所示。

表1 本文所用符号及其含义描述Tab.1 Symbols used in this paper and their meaning descriptions
基于用户的协同过滤(User-based collaborative filtering,U)算法,主要步骤是:首先,根据用户的POI访问历史度量用户间的相似性,找到目标用户的一组相似用户。然后,利用相似用户的加权评分,估计目标用户对没访问POI的评分,从而根据评分形成POI推荐列表。具体地,根据用户的POI访问历史,建立二维签到矩阵即User-POI矩阵,对于其中的每个元素Cul(u∈U,l∈I),如果用户u访问过POIl,则设置Cul=1,否则设置Cul=0。给定一个目标用户u,则用户u对没访问POIl的评分估计计算如式(1)所示:

其中Wuv表示目标用户u和相似用户v之间的相似度。两个用户间的相似性度量有多种,本文采用使用最广泛的余弦相似性度量,计算方法如下:

3 融入时间的POI协同推荐
3.1 时间关系分析
用户在一天甚至一周内的活动具有一定的规律。这个规律主要分为用户访问POI的时间差异性和连续性。差异性是指用户中午去餐馆,晚上去酒吧等;工作日在家和单位附近,而周末去离家较远的地方游玩等,即用户访问POI随时间的变化而变化。连续性是指在相邻时间段,用户的活动具有相似性[15]。例如,用户在中午12—13点会访问餐厅等相似的POI。因此,本文将一天按小时划分为24个时间片,如24(hh):01(mm):00(ss)为时间片0,10(hh):15(mm):30(ss)为时间片10,构成时间片集合T={0,1,…,23}。然后,在两个真实数据集Foursquare和Gowalla上,利用常用的相似性度量方法——余弦相似性,度量任意两个时间片间的相似度,分析用户访问POI的时间关系可发现:
1)用户在不同时间片访问的POI具有不同程度的相似性。
本文以Foursquare数据集上的结果为例。图1显示了该数据集上3个时间片(7点、12点和18点)与其他时间片的相似度曲线。从图1中可以看出这3个时间片与0—6点的相似度很低,在6点以后逐渐升高,7点以后(8—23点)的相似度均比6点以前的高。这和实际生活中大多数人上午6—7点出门,凌晨进入睡眠相符合。在18点时间片的曲线上,11点时相似度有小幅上升,同样,在7点与12点两个时间片的曲线上,17点和18点时相似度也有小幅上升,这符合早饭、午饭、晚饭的时间。综上,用户在不同时间片访问的POI具有不同程度的相似性。
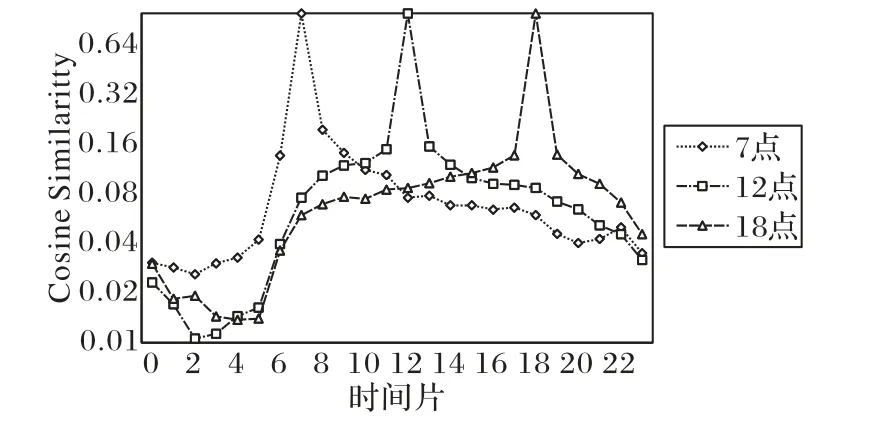
图1 给定时间片与任意时间片之间的相似度Fig.1 Similarities between given time slicesand other time slices
2)用户访问POI的相似性随时间差增加而衰减。
进一步,本文分析不同时间差下,用户访问POI的相似度,其 中,时 间 差Δt=|t-t'|(|t-t'|≤12)或Δt=24-|t-t'|(|t-t'|>12),结果如图2所示。
本文以Foursquare数据集上的结果为例。由图2可以看出时间差越大,时间片间相似度越低。当时间差为0时,在总相似度中占比为58%,剩余时间差占比为42%。即,相同时间片上用户签到偏好具有最大的相似性。也就是说,相同时间上用户偏好对用户决定是否访问某一POI的影响最大;同时其余时间片上的签到偏好也不能忽视。因此,本文首先利用所有时间片间的相似度平滑签到矩阵以缓解数据稀疏问题,进而使用平滑之后获得的签到矩阵,发现用户偏好。其次,利用相同时间片的用户访问偏好最相似这一特点,按时间给用户推荐POI,从而提高推荐效果。

图2 时间差与相似度Fig.2 Time differenceand similarity
3.2 融入时间的POI协同推荐算法
对签到数据按小时划分之后,原本的二维签到矩阵User-POI,被建模为一个三维签到张量即User-Time-POI。对于其中每个元素Cutl(u∈U,t∈T,l∈L),如果用户u在时间片t访问POIl,那么设置Cutl=1,否则设置Cutl=0。融入时间的POI协同推荐算法,首先利用获取的时间关系平滑用户的签到矩阵,然后根据平滑后的签到矩阵寻找相似用户,最后利用相似用户签到偏好为目标用户u在时间片t进行POI推荐。
3.2.1 时间片平滑


其中Simtt'表示时间片t与t'的相似度。采用常用的相似性方法——余弦相似性,计算如下:

3.2.2 用户相似度计算
为解决融入时间的POI协同推荐,首先寻找目标用户u的相似用户。为使搜索到的相似用户更加准确,在度量相似用户时,不仅考虑访问的POI,还加入访问的时间。例如,用户u1在时间t1以及t2访问l1和l2,用户u2在时间t1以及t2访问l2和l1,在不考虑时间的情况下,利用式(1)计算得到u1、u2的相似度为1,融入时间之后相似度为0。
在更加稀疏的三维签到张量中,直接引入时间计算两个用户相似度虽然会提高相似用户的质量,但当不同的用户在不同的时间片访问同一个POI时,直接加入时间片寻找相似用户忽略了用户在某一个时间片上签到行为和其他时间片上的签到行为具有相似性。例如,用户u和v分别在时间t1和t2访问l1,不考虑时间片相似的情况用户u和v的相似度为0;考虑时间片相似的情况,用户u和v的相似度则大于0。因此,根据平滑后的签到矩阵计算用户相似度,计算如式(5)所示:

3.2.3 POI推荐
由3.1节分析可知,相同时间片上用户签到偏好具有最大的相似性,即相同时间片上用户签到偏好对用户决定是否访问某一POI的影响最大。所以,本文利用相似用户在同一时间片的访问偏好评估候选POI。采用基于用户的协同过滤,以及3.2.1节中平滑后的签到矩阵、3.2.2节中的相似用户及其相似性,估计目标用户u在时间片t访问POIl的评分,计算方法如式(6)所示:

排序式(6)得到的估计评分,即可获得在时间片t,向目标用户u推荐的POI列表。融入时间的POI协同推荐(Timeincorporated User-based Collaborative Filtering POI recommendation,TUCF)算法描述如下。
输入:用户签到数据集,目标用户u,时间片集合T;
输出:目标用户u在各个时间片上的推荐列表。
1)将用户签到数据建模为User-Time-POI张量;
2)利用式(4)计算各个时间片间的余弦相似度;
3)根据式(3)平滑User-Time-POI签到张量;
4)根据式(5)计算用户间的相似度;
5)获取候选POI:用户在时间片t没有访问过的POI;
6)利用式(6)计算每个候选POI的评分;
7)对评估分数排序,取前N个POI作为推荐列表Rank,并返回Rank。
在TUCF算法中,选出估计评分最高的N个POI作为最终的推荐结果,根据实际推荐的情况N的取值不同。
4 实验与结果分析
4.1 实验设置
4.1.1 数据集
本文使用文献[2]提供的两个真实数据集Foursquare和Gowalla。Foursquare数据集为2010年8月—2011年7月的新加坡签到数据,包含2 321个用户,5 596个POI,共194 108条签到。Gowalla数据集为2009年8月—2010年9月加州和内华达州的签到数据,包含10 162个用户,24 250个POI,共456 988条签到。两个数据集中每个用户签到至少5个POI,每个POI至少被5个用户签到,每个数据集被划分为训练集、测试集和调参集。本文使用每个数据集中的训练集和测试集。
4.1.2 对比算法
为了验证本文所提出的融入时间的POI协同推荐(TUCF)算法的性能,选用了以下对比算法验证该算法的有效性:1)U算法[2];2)具有平滑增强时间偏好的协同过滤(Uwith Temporal preference with smoothing Enhancement,UTE)算法[2]。
4.1.3 评价指标
本文采用评价指标:精确率Precision、召回率Recall、平均绝对误差MAE来评估推荐算法的效果。在评估指标中涉及的符号和描述如表2所示。

表2 评估指标中的符号描述Tab.2 Description of symbolsused in evaluation indices
1)精确率和召回率。
采用文献[2]中的方法评估推荐算法的精确率和召回率。Pre@N(t)和Rec@N(t)分别表示在时间片t推荐N个POI的精确率和召回率,计算如式(7)~(8)所示:
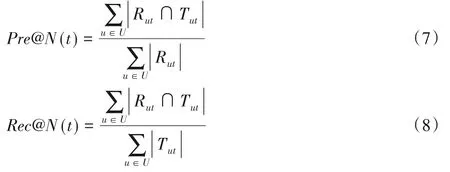
算法推荐N个POI的精确率Pre@N和召回率Rec@N是所有时间片的平均精确率和召回率,如式(9)~(10)所示:

2)平均绝对误差。
在签到张量中,如果用户u在时间t对POIl进行了签到则cutl=1,否则cutl=0,将其作为用户评分。首先计算每个时间片上的平均绝对误差MAE(t),然后平均所有时间片上的MAE(t),得到推荐算法的平均绝对误差。每个时间片上的平均绝对误差计算方法如式(11)所示:

推荐算法的平均绝对误差MAE是所有时间片的平均值,计算方法如式(12)所示:

4.2 实验结果与分析
本文TUCF算法与对比算法U和UTE的实验结果及分析如下。文中的相似用户数固定为500,推荐的POI个数N分别取5、10、15。
1)推荐算法的精确率和召回率。
TUCF、U和UTE算法在数据集Foursquare和Gowalla上的精确率和召回率如图3所示。
从图3可以看出:在两个数据集上,考虑时间因素的UTE算法、TUCF算法均优于未考虑时间因素的U算法,说明考虑时间因素可以提高POI推荐效果。同时TUCF算法的精确率和召回率均高于对比算法U和UTE。尤其是,在POI推荐数目N=5时,在Foursquare中TUCF算法比U算法在精确率以及召回率上分别提高了63%和69%,TUCF算法比UTE算法的精确率以及召回率分别提高了8%和12%,这表明采用时间关系平滑用户签到获取相似用户,以及利用相似用户在相同时间片的访问偏好,可以提高推荐效果。

图3 推荐算法的精确率和召回率比较Fig.3 Comparison of precision and recall of recommendation algorithms
2)各时间片上的精确率和召回率。
本文以Gowalla数据集上的结果为例,结果如图4所示,其中N=5。从图4中可以看出,精确率和召回率的变化在两个方法中相似,且TUCF算法在24个时间片上均高于UTE算法。在时间片11点时,两个算法的精确率和召回率达到最高,在时间片9点时,精确率和召回率达到最低。尤其在时间片7点时,TUCF算法的精确率和召回率相比UTE算法分别改善了67%和50%。这说明采用时间关系平滑用户签到获取相似用户,以及利用相似用户在相同时间片的访问偏好,可以提高推荐效果。

图4 不同时间片上的准确率和召回率比较Fig.4 Comparison of precision and recall on different time slices
3)MAE对比。
本节将推荐POI数量N固定为5,目标用户的相似用户数量M从50增长到2 000,分析相似用户数量对算法的影响,以图5所示的Foursquare数据集上的结果为例。
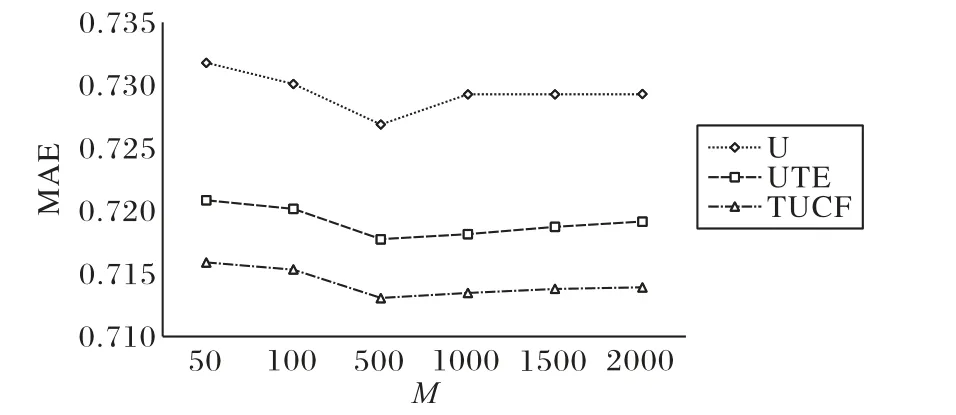
图5 MAE比较Fig.5 Comparison of MAE
从图5中可以看出当M取500时,取得较好的推荐效果,且对于不同的M,TUCF的MAE值均低于对比算法U和UTE。其中考虑时间因素的TUCF算法、UTE算法,MAE值均比未考虑时间因素的U算法低,说明考虑时间因素可以提高POI推荐效果。考虑时间因素的TUCF算法和UTE算法,TUCF算法的MAE值低于UTE算法,表明采用时间关系平滑用户签到获取相似用户,以及利用相似用户在相同时间片的访问偏好,可以提高推荐效果。
5 结语
本文分析基于位置的社交网络的用户签到数据,探索用户签到的时间关系,并利用时间关系对用户签到数据进行平滑处理,然后基于用户的协同过滤算法,提出了融入时间的协同过滤POI推荐算法。在两个真实数据集Foursquare和Gowalla上的实验结果表明,本文算法不仅可以有效缓解数据的稀疏性,还提高了POI推荐的精确率和召回率,减小了平均绝对误差。
时间作为POI推荐的一个重要因素,除了一天内不同时间对用户签到有影响,用户的签到行为还受星期或月份的影响,今后将进一步探索其他时间粒度。此外,POI通常具有类别信息,也将探索类别信息提高POI推荐效果的可能性。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
科学大众(2020年23期)2021-01-18 03:09:08
河北画报(2020年8期)2020-10-27 02:54:20
汽车观察(2019年2期)2019-03-15 06:00:50
中国卫生(2016年5期)2016-11-12 13:25:26
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
