
基于深度强化学习的异构云任务调度研究
2021-09-08 03:45何先波
太原师范学院学报(自然科学版) 2021年3期
古 丹,张 鹰,何先波
(西华师范大学 计算机学院,四川 南充 637009)
0 引言
云计算[1]作为一种大规模的异构服务器集群,允许用户通过互联网以低廉的价格租用高性能的服务.云端处理大量应用的同时对云计算平台任务调度的性能要求也急剧加升.一方面,大量终端用户提交的任务具有动态不确定性,任务到达时间及任务所需资源未知.另一方面异构性在云环境中很常见,首先,用户提交的大规模请求是异构的,如计算密集型和I/O密集型.其次,云环境下部署的不同服务器的硬件配置是异构的.动态工作负载会导致同处虚拟机之间的资源竞争,因此,如何实现大规模动态异构任务与虚拟机实例之间的映射,同时保证虚拟机实例之间的负载均衡,是学术界和研究的热点.
为了应对上述挑战,现有的方法大多侧重于运用排队论[2]、控制论[3]等理论研究,将调度系统建立为数学模型,对作业调度方案进行理论分析.但是,由于这些解决方案对时间和资源非常敏感,因此它们不适用于动态负载.此外,启发式调度算法[4]将任务分配视为NP问题,在静态环境下进行任务调度,忽略了云环境的动态性.
针对未知类型的工作负载输入,本文采用K-means聚类方法[5]对任务进行解析,识别其类型.其次,将任务调度问题定义为动态优化问题,并利用DDPG(深度确定性策略梯度)[6]算法求解该问题.最后,本文评估了在实际工作负载下所提出的调度器的效能,与现有的调度方法相比,该方法在任务响应时间和VM实例间的负载均衡方面表现良好.
1 系统框架
一个常见的任务调度系统包括最终用户、聚类器、云服务提供者和应用程序提供者.图1所示为任务调度系统的框架.首先,应用提供商从云服务公共平台租用不同类型的VM实例,形成自己的服务资源池.其次,聚类器对提交的任务进行识别、聚类和处理,再将具有该类型信息的任务提交给任务调度模块.调度模块由两部分组成:监视器和基于深度强化学习的任务调度器.监视器负责获取所有状态信息,包括虚拟机状态和任务状态.状态信息作为输入发送到任务调度器,并输出任务分配策略.最后,调度系统根据该策略分配和执行任务.

图1 任务调度框架图
2 任务调度算法设计研究
2.1 任务负载聚类
聚类阶段负责提取负载的类型特征,并将其发送到基于深度强化学习的在线决策阶段.本文使用K-means算法进行聚类分析,其流程如表1.

表1 任务聚类伪代码实现
2.2 异构感知的云任务调度算法设计
2.2.1 状态空间、动作空间、奖励函数设计
2.2.1.1 状态空间
当前环境的状态由任务状态和VM实例状态组成,更详细地说,任务属性包括任务大小、任务所需CPU利用率和任务类型.即任务状态表示为si=(mii,cpuUtli,taskTypei).对于每个VM实例,其状态由VM处理速率、任务等待时间和VM类型组成,即sk=(mipsk,waitTk,vmTypek),则状态空间表示为:
i=1,…I;k=1,…,K.
(1)
2.2.1.2 动作空间
当用户提交I个任务,动作空间被表示为这I个任务分别分配的虚拟机的编号组成的一个向量.vmIdi表示为任务i分配的虚拟机编号,则动作空间表示为:
actionik=[vmId1,vmId2,…,vmIdi,…,vmIdI]
vmIdi=1,…,I.
(2)
2.2.1.3 奖励函数
奖励可以判断行动策略的质量,可以帮助智能体更新策略,以至未来做出更好的决策.在本文提出的模型中,奖励定义为任务平均响应时间.
rewardIK=α×avgTik.
(3)
2.2.2 基于DDPG的云任务调度算法设计
DDPG在线决策阶段使用动作网络和批评网络,离线训练阶段利用经验回放和目标网络训练动作网络和批评网络.表2显示了基于DDPG的任务调度算法.

表2 基于DDPG的任务调度伪代码实现
2.2.3 异构感知的动作探索策略
原始的DDPG算法中的探索方式为OU过程.它在时序上具有很好的相关性,对于有惯性的系统探索效率较高.但在调度系统中,由于任务的爆炸性,这种探索方式不能很好地平衡智能体探索和重复利用的问题;并且云环境中存在的异构性使得任务处理的速度有所差别,所以在本文提出一种异构感知动作探索策略.如表3为其伪代码实现.

表3 异构感知动作探索策略伪代码实现
3 实验结果分析
3.1 实验环境及实验数据
所有实验均在pythorch1.4和jdk1.8的python3.6仿真环境下进行.服务器配置3.4 GHz Intel Core i7处理器和16 GB内存.为简化实验,应用程序提供商从Iaas供应商租用了20个VM实例,包括4种类型,每种类型的VM有5个实例.使用Alibaba-Cluster-trace-v2018作为工作负载数据,这是Alibaba集群使用情况跟踪.它提供任务跟踪,包括任务开始时间、CPU利用率、内存利用率和任务大小.本文使用了第五天的负载跟踪数据,其中每分钟提交的任务数平均为2 268个,最大为2 957个.本文截取了最后500 000个跟踪数据作为数据集.K-means中的K值设置为4.
调度算法中的网络包括两组演员-评论家网络,即四个神经网络,分别是演员网络、评论家网络、目标演员网络和目标评论家网络.每个网络有四个完全连接的层.目标网络的更新方式为软更新,软更新参数设置为ω=0.01.经验池的大小设置为D=1 000,最小的样本大小Ω=32,并选择Adam优化器作为网络优化器.演员和评论家网络的学习率分别为0.000 6和0.001.探索率的值ε初始化为0.95,递减率为0.999,最小值为0.1.
为了评估本文提出的任务调度方案,比较了其他五种任务调度方法:随机调度Random,循环调度RR,最早调度Earliest和基于DQN的任务调度.随机调度方法将任务随机分配给VM实例.循环调度方法将用户请求依次轮询分配给VM实例.最早的调度方法将用户提交的任务分配给最早的空闲VM实例.
3.2 实验结果及分析
如图2(a)所示,不同任务类型相对于VM实例类型的分配结果,平均匹配度为56.3%.如图2(b)所示,与其他算法相比,除本文算法外,Earliest是最好的算法,但是CDDPG的平均任务响应时间比earliest好22%.随机调度算法的平均任务响应时间最长,CDDPG的平均任务响应时间比随机调度算法高72%.图2(c)显示了VM实例的CPU利用率标准差的比较.如图所示,CDDPG在CPU利用率标准差方面比其他算法平均低10%.这表明我们提出的算法能够更好地保证大规模动态环境下的负载均衡.
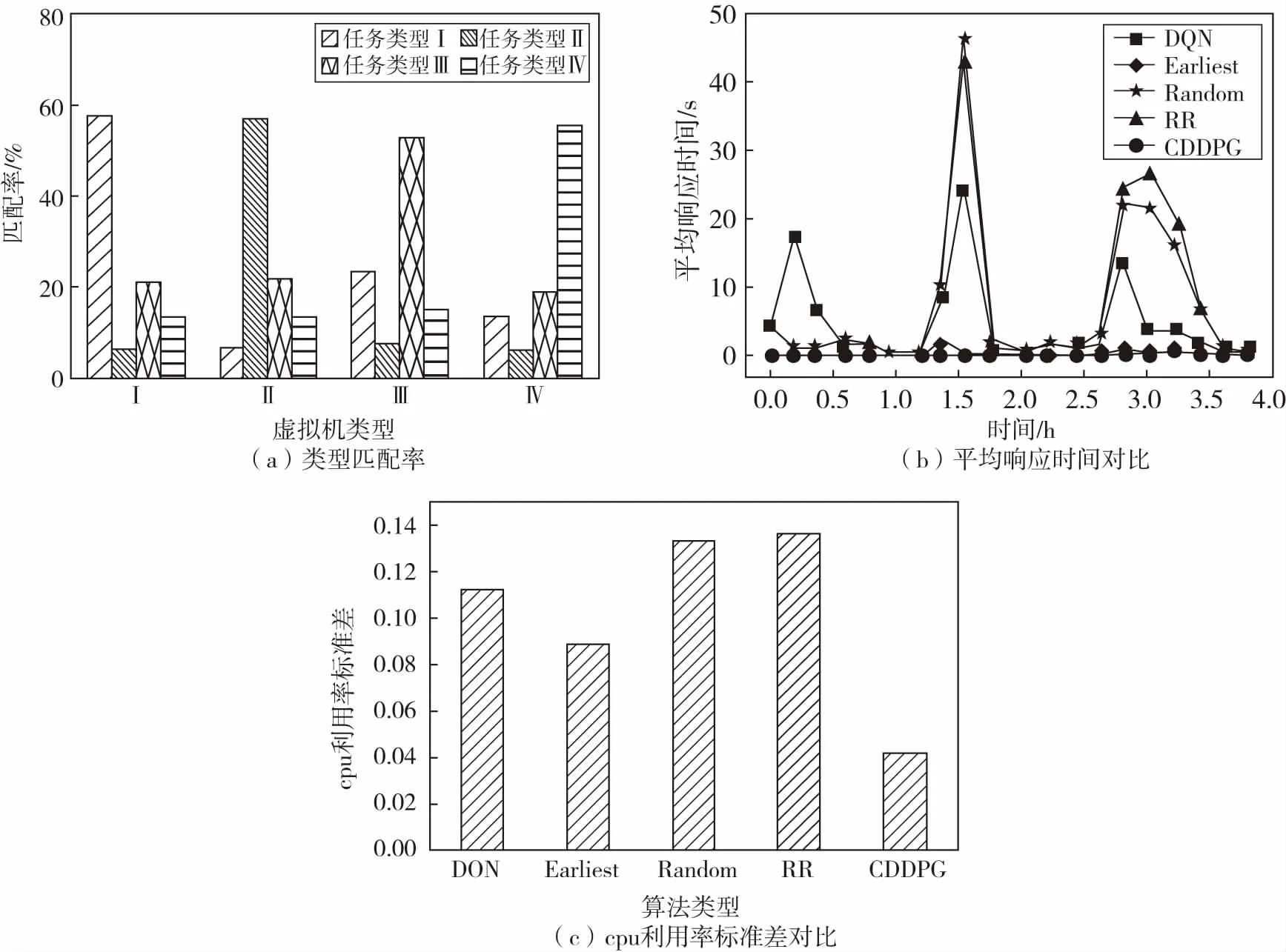
图2 实验结果图
4 总结
本文针对云环境中任务的高不确定性和动态波动性和云环境中集群的异构性,建立云任务调度框架,采用K-means聚类方法来识别不同的工作负载类型;提出基于异构感知的改进深度确定性的策略梯度方法实现任务调度.研究的不足在于调度目标考虑的不够全面,未来的研究中,会从单目标和多目标两个方面深入剖析算法优化的可行性.另外会从容错的角度,对提高调度的质量加以分析研究.
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
吉林大学学报(信息科学版)(2022年2期)2022-08-15
小学教学研究(2022年5期)2022-04-28
计算机测量与控制(2022年2期)2022-03-30
数字通信世界(2020年3期)2020-04-06
电子制作(2019年14期)2019-08-20
商周刊(2019年1期)2019-01-31
计算技术与自动化(2014年1期)2014-12-12
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
