
基于深度神经网络的医药专利文本聚类模型研究
2021-09-08 03:45王思源何先波
太原师范学院学报(自然科学版) 2021年3期
王思源,何先波
(西华师范大学 计算机学院,四川 南充 637002)
0 引言
近年来,医药专利文本数量呈爆发式增长,通过对医药专利文本划分的研究,可以挖掘生物医药行业潜在竞争力、提升项目的研究水平以及加快新药研发进度.医药专利文本主要包括摘要、权利项、专利申请书、说明书以及申请相关信息等内容[1].本课题从医药专利的文本特点和现实需求出发,对医药专利文本的深度特征提取与聚类算法开展研究,提升了医药专利文本聚类的质量,减轻了人工标注专利的负担.
1 研究现状
研究者为了更好地挖掘专利文本信息,在专利文本特征提取和聚类方法上进行不断地研究与创新,进一步提升了专利文本聚类质量.
如薛淑晖等人[2]使用TF-IDF方法提取VSM模型向量中的关键词,然后用K-Means聚类得到专利文本聚类结果,提升了专利文本聚类结果.Jun等人[3]基于NB方法对专利数据进行聚类,用后验概率作为距离值构造聚类结果树状图,实现了高效聚类.姚长青等人[4]使用潜在语义索引(Latent Semantic Indexing,LSI)的方法对专利文本进行特征降维,并改进了K-Means算法,一定程度上缓解了聚类特征维度问题.
2 模型结构
本文设计的基于深度神经网络的医药专利文本聚类模型主要分成三个模块,包含文本预处理、深度特征提取和聚类分析模块.模型流程图如图1所示.

图1 医药专利文本聚类模型流程图
2.1 文本预处理
在文本预处理模块,首先使用Jieba分词工具进行分词;其次使用正则化指令去除专利文本中的无用标签、特殊符号对数据进行清洗;最后根据医药专利文本的特征,在“哈工大停用词表”的基础上扩充停用词表,将医药专利文本都包含了“本发明”“一种”“所述”“方法”等词汇作为停用词,建立专有的医药专利停用词表,过滤掉专利文本中出现频率高但信息量少的停用词.
2.2 深度特征提取
在深度特征提取模块,主要分为词向量化表示和特征提取两部分.先将预处理后的医药专利文本表示为词向量,然后将训练好的词向量作为深度特征提取网络的输入,通过设计的特征提取网络挖掘医药专利文本的深度潜在特征.
在词向量化表示方法上,使用基于全局统计的GloVe[5]模型训练医药专利文本词向量.GloVe模型中的相关参数设置:词向量维度为300,窗口大小为15,最小词频为15,最大迭代次数为20.
针对特征提取方法的选择,本文设计了一种基于卷积神经网络(Convolutional Neural Networks,CNN)[6]与双向LSTM(Bidirectional Long Short-Term Memory,Bi-LSTM)[7]的深度特征提取网络,本文将该网络简称为CBL深度特征提取网络.CBL网络整合了CNN与RNN的优点,由输入层、CNN层、RNN层和全连接层组成,其网络结构图如图2所示.
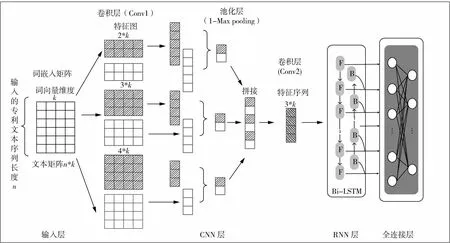
图2 CBL深度特征提取网络结构图
输入层输入是词向量矩阵表示的文档,每个单词由一整行的词向量表示.由于医药专利文本词汇过长,为了提升网络的训练速度和效率,设置每篇医药专利文档输入的最长长度为2 000个特征词,利用TF-IDF方法根据特征词重要程度进行排序选择.
CNN层主要由卷积、池化和卷积层组成.卷积层(Convolution Layer,Conv)中设置滤波器的宽度与输入词向量矩阵的宽度相同,保证了单词作为NLP中的最小粒度;为了获得丰富的专利文本特征,Conv1和Conv2中使用了多个不同大小的滤波器,同时为了得到同一窗口中更多互补的特征,使用了同一大小多个数量的滤波器,实现并行抽取特征.池化层(Pooling Layer)中使用步长为1的最大池化,聚焦重要特征、去掉冗余信息.
RNN层中,为了有效获得专利文本的时序信息、解决长时间依赖的问题,使用Bi-LSTM网络实现上下文特征提取.Bi-LSTM网络是对单向LSTM网络的扩展,引入第二层反向的LSTM网络,输出结果由这两个正反方向的LSTM状态共同决定.结构图中,F(Forward)表示正向的LSTM单元结构,B(Backward)表示反向的LSTM单元结构,该网络的输出能同时考虑文本特征的前后因素.
最后全连接层将前几层网络得到的医药专利文本特征信息进行整合,得到最终的专利文本特征向量,并将其作为聚类算法的输入.CBL网络结构的具体参数设置如表1所示.

表1 CBL深度特征提取网络的参数设置
2.3 聚类分析
在聚类分析模块,针对传统K-Means算法存在的对初始中心点和离群点敏感问题,在初始中心点的选取和目标函数做出了优化.本文将改进的K-Means算法简称为优化KM聚类算法.
2.3.1 目标函数的优化
K-Means是一种基于目标函数并采用梯度下降法寻找目标函数最小值的算法.原始K-Means算法的目标函数J公式为:
(1)
式中,d(x,ci)2=‖x-ci‖2表示距离空间中样本点x与簇中心点ci之间的欧氏距离.
本文针对离群点的问题,给目标函数添加了一个惩罚项用于检测离群点,得到的新目标函数J′,公式为:
(2)
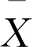
2.3.2 初始中心点的选择
本文提出的优化KM算法以初始中心点(质心)的选择作为切入点,采用多次随机分组取最优的策略.优化KM算法的具体过程为:
Step1:把专利样本特征随机分成K组,计算每组特征的均值,并将其作为每组聚类的初始质心.
Step2:计算选取初始质心的首次迭代结果的目标函数值分数.
Step3:重复以上两个步骤,进行N次初始质心的随机选择,比较每次计算得到的目标函数值分数,选择分数最小的一组作为初始中心点,即实现多次随机选择,得到最优聚类初始质心.最终得到的初始质心将优于其他N-1 次的结果.
Step4:直到簇质心位置不再发生变化或目标函数值最小化,则KM算法终止.
3 实验结果与分析
3.1 数据集分析
本课题主要针对医药专利文本进行实验,选取的医药专利数据集主要来自药智网和汤森路透专利数据库.共获得277 085条医药专利数据,选取的医药专利数据都属于单标签数据.收集到的医药专利数据集主要分为12种类别.由于从网上得到的医药专利数据中部分信息不完整、存在缺失值,因此本文选取的专利数据中都包含了标题、摘要和主权项三项内容.对收集到的医药专利数据进行随机采样,从每一类中随机抽取5 000条作为实验数据集,不足5 000条的类别全部选取.每一类的医药专利数据分布和随机抽取的实验数量,如表2 所示.

表2 实验数据分布
3.2 实验评价指标
聚类查准率(Precision,Pre)是指得到的聚类结果中,每个簇中正确划分的准确性指标.聚类查全率(Recall,Re)是指得到的聚类结果中每类样本正确划分到对应类簇的指标.
假定C={C1,C2,…,Ck}是聚类生成的聚簇集,将簇Ck和标注的类别i进行计算,得到的查准率和查全率公式分别为:
Pre(Ck,i)=n(Ck,i)/nk
(3)
Re(Ck,i)=n(Ck,i)/ni
(4)
式中,n(Ck,i)为簇Ck与i类中所共有的文档个数,nk表示划分到簇Ck中的文档个数,ni为预设类别i中的文档个数.
特征测量(F1-Measure,F1)据查准率和查全率得到.簇Ck对于类别i的F1(Ck,i)公式为:
(5)
聚类精确度 (Accuracy,Acc) 用于判断聚类结果正确划分的程度.聚类精确度公式为:
(6)
式中,k和i分别表示聚类对象的预测标签和真实标签,n为样本总数,δ表示指示函数:
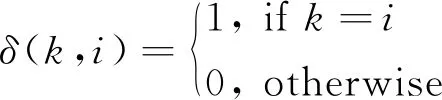
(7)
四个指标的值取值范围均在0~1之间,值越接近1,得到的聚类质量越好.
3.3 实验结果分析
3.3.1 实验环境和说明
实验使用Pycharm工具作为软件开发平台,使用Windows10操作系统,计算机处理器为Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz,GPU为Nvidia GeForce GTX 1060 6GB.
3.3.2 实验结果
3.3.2.1 特征提取方法的对比
为了验证本课题设计的CBL深度特征提取网络能否有效地提取医药专利深层特征,以及是否提升医药专利文本聚类的性能,与常用于文本聚类的TF-IDF[8],LSA[9]和CNN特征提取方法进行了比较.在实验过程中仅改变特征提取的方法,其他步骤处理相同.实验结果如表3所示.

表3 在不同特征提取方法的比较
实验结果表明,神经网络模型在特征提取上更具有优势.同时本文提出的CBL深度特征提取网络是对典型CNN的改进,较典型CNN特征提取方法得到的聚类结果各指标提升了3%以上.因此,本文设计的特征提取方法能更好地提取医药专利文本特征.
3.3.2.2 模型对比
为了验证本文提出的医药专利文本聚类模型的整体聚类性能,同现有的KNN,NB,SVM[10]和RF[11]专利文本划分模型进行了对比实验.在实验过程中文本预处理步骤处理相同,实验结果如表4所示.实验结果表明,本文模型在四个指标上都表现很好,得到的值在94%以上且比较稳定,与现有的专利文本划分模型相比,得到的聚类效果更好.
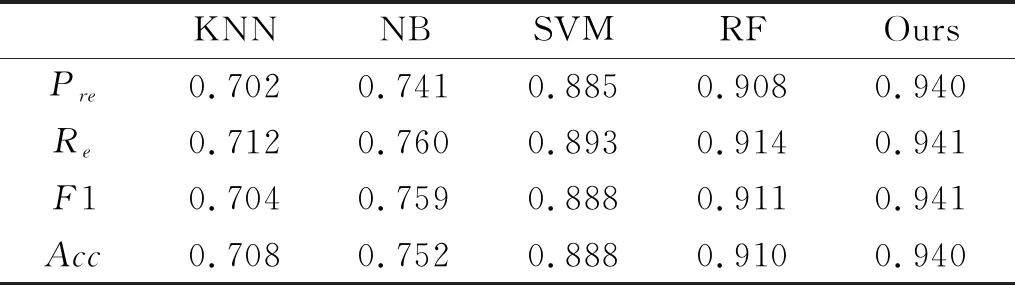
表4 各模型之间的对比
4 结语
本文主要是针对医药专利文本数据进行的聚类研究,本文提出的基于深度神经网络的文本聚类模型也可以应用于其他复杂长文本的聚类分析.在未来的研究过程中,深度特征提取网络的CNN部分,本文使用的是1-Maxpooling进行池化,今后可以尝试使用动态k-Maxpooling进行池化,来进一步提升复杂长文本的特征提取质量.
猜你喜欢
医药导报(2022年1期)2022-01-17
云南医药(2021年3期)2021-07-21
中华养生保健(2020年1期)2020-11-16
内蒙古民族大学学报(社会科学版)(2020年1期)2020-11-03
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
现代计算机(2018年27期)2018-10-25
雷达学报(2017年6期)2017-03-26
