基于高斯混合模型的土壤环境质量分区研究
2021-09-06 09:56刘佳斌郜允兵李永涛徐卓揆潘瑜春杨晶张婉秋
农业环境科学学报 2021年8期
刘佳斌,郜允兵,李永涛,徐卓揆,潘瑜春,杨晶,张婉秋,4
(1.华南农业大学,广州 510642;2.北京农业信息技术研究中心,北京 100097;3.长沙理工大学交通运输工程学院,长沙 410114;4.中国矿业大学(北京),北京 100083)
土壤重金属污染已经成为世界性的环境问题[1]。2014 年原环境保护部和原国土资源部联合发布的《全国土壤污染状况调查公报》指出耕地土壤重金属点位超标率为19.4%,耕地土壤环境质量堪忧。2016年5 月国务院发布了《土壤污染防治行动计划》(简称“土十条”),要求深入开展土壤重金属污染调查,掌握土壤环境质量状况,实施农用地分类管理,保障农业生产环境安全[2]。我国一直关注土壤环境质量采样工作,“七五”以来,环境、农业、国土等部门开展了多次土壤环境监测调查工作,积累了大量的土壤环境质量数据[3]。基于土壤采样点开展环境质量分区研究可为土壤污染的精准识别、风险管控区的精准划定、管控措施精准制定提供辅助决策依据,是当前土壤环境质量评价技术研究的热点,具有重要的学术价值和现实意义[4-5]。
土壤环境质量受自然和人为因素影响,影响因素(成土母质、土壤类型、成土过程、土壤质地、河流、道路、重点企业等)与土壤环境质量空间分异并不一致,直接采用环境影响因素进行中小尺度的环境质量分区效果不佳[6-7]。2002 年,美国环境学家DORAN 等[8]提出了土壤环境质量的概念,揭示了固有环境条件、环境质量指标与环境质量空间格局形成的关系。KARLEN 等[9]从土壤使用功能入手分析了微观、宏观尺度上导致土壤环境质量变化影响因素。郭书海等[10]以土壤环境质量影响因素为基础,采用影响因素空间叠加分析法进行了国家尺度的土壤环境质量综合区划研究。
土壤采样是对区域环境质量的抽样,其样点蕴含且反映了区域环境质量的情况,基于采样点的环境质量分区,是区域环境质量分类后在空间域上的映射,可以通过对采样点的属性/空间聚类来实现。常用的点模式聚类方法主要有基于划分、基于密度、基于模型、基于网格、基于层次等方法,在使用时也存在一定局限性[11-14]。局部Moran’s I 指数常用于基于属性相关性的点模式空间聚类,可以对样点观测值的高高(高值点聚集)、高低(高值点被低值点包围,表现为高值异常点)、低高(低值点被高值点包围,表现为低值异常点)、低低(低值点聚集)等聚集模式和异常邻接模式识别[15],用于对污染指标的空间聚集和异常区进行刻画,但其聚类或者异常的空间模式仅是基于样点均值相对高低的反映,与人们对真实环境污染阈值绝对量的认知仍有区别[16]。K-均值家族聚类以类与类之间的空间距离之和最小为约束条件,单靠空间距离不能真正体现人为、自然影响综合作用环境质量的分异性和相似性[17]。土壤环境质量可以看作自然环境因素、人为活动因素等多个驱动力的单独或者交互作用,将环境影响因素对土壤指标的作用近似看作多个高斯过程或者其他随机过程,则基于采样点的环境质量分类分区可以采用高斯混合模型进行聚类分析。徐烨等[18]运用高斯混合模型(Gaussian mixed model,GMM)聚类方法将采样点总体分解为多个不同环境效应作用的高斯簇集合,探索了土壤采样点类型与企业空间分布间的关联。但该聚类算法的目标函数初始分类参数设定存在一定主观性,容易造成聚类结果的过拟合或欠拟合[19-21]。
常用的土壤环境质量评价方法有单项污染指数法、内梅罗指数法、污染负荷指数法、环境风险指数法、地累积指数法、潜在生态危害指数法、灰色聚类法、健康风险评价方法等。上述这些评价方法被单独或者联合应用于农田土壤污染评价,前人利用单项污染评价指数、内梅罗综合污染指数、地积累指数、潜在生态危害指数等方法[22-24]开展评价工作,并评估了农田土壤污染的程度,计算了各种风险指数,但这些方法反映的是土壤环境质量某方面或者对污染指标加权综合,不一定适合环境质量分区识别。分析研究区土壤环境质量指标的最小集,也是一种环境质量的表征方法。基于此,本文提出基于采样点与辅助变量的区域土壤环境质量分区方法,采用主要影响因素对土壤环境质量预分类,通过主成分分析获得的特征向量集合表征土壤环境质量,以此构建高斯混合模型对土壤采样点聚类,避免采样点分类初始化的随机性导致聚类结果陷入局部最优解,并以北京市顺义区土壤采样数据为例验证方法的有效性。
1 材料与方法
1.1 研究区概况
顺义区位于北京市东北部,位于40°00′~40°18′N、116°28′~116°59′E。区内耕地面积为404.05 km2,占土地总面积的39.56%,为北京市传统农业区。主要种植作物为小麦、玉米、蔬菜和水果。农业用地以粮食生产为主,种植模式为冬小麦-夏玉米。土壤样品采集于2009 年8 月至11 月,样本点的布局和数量根据农用地的利用方式和面积进行确定,采样方法为4 分法混合,包含4 个子样,共采集耕层(0~20 cm)土壤样品412 个,使用GPS 定位记录样点中心位置,采样点主要分布于粮田、菜地、果园、设施农业用地等,其中后沙峪、南法信、天竺、马坡、仁和等区域未进行采样,为非调查区。根据采样点的土地利用方式,分为菜地、果园、荒地、林地、苗圃、设施农业用地和水浇地,采样点分布如图1 所示。所有样品在室内自然风干,碾压磨碎后过100 目尼龙网筛,土壤样品按照EPA Methods 3050B 的方法使用HNO3、HCl 和H2O2混合溶液消解。消解液中的As、Cd、Cu、Pb和Zn使用等离子发射光谱(ICP-OES,Thermo iCAP 6300,USA)测定,使用HNO3∶HCl(1∶1)在100 ℃消解,消解液使用原子荧光光谱(AFS,Titan AFS 830,China)测定Hg 的含量。每个样品重复测3 次,样品处理和分析的质量控制采用分析土壤标准参考物质GSS-1 和GSS-4(国家标准物质中心)。
成土母质[25]、土壤类型、土壤质地、土地利用方式、工矿企业排放、河流等是可能影响该区域土壤环境质量空间差异的因素[26-27]。研究区土壤成土母质均为第四纪黄土,不存在岩石岩性上的差异。区域内土壤类型包含潮土、褐土、水稻土3类,土壤质地分为轻壤质、中壤质、砂壤质,其空间分布如图2(a)、图2(b)所示,土壤类型的空间连片性强于土壤质地;区内主要河流有怀河、潮白河、金鸡河等,工矿企业主要分布在河流下游区域附近,其空间分布如图2(c)、图2(d)所示,河流、工矿企业按照辐射范围划定影响区,可以看出工矿企业聚集度具有一定的空间异质性。
1.2 研究方法
基于高斯混合模型的土壤环境质量分区研究主要包括3 个部分:首先,对土壤采样点的重金属指标归一化处理后进行主成分分析,选取特征值大于1 的主成分共同反映区域土壤环境质量综合特征,并运用地理探测器筛选影响土壤环境质量综合特征的主要因素,按主要影响因素类别对采样点进行预分类;其次,基于采样点的预分类方案构建高斯混合模型(Gaussian mixed model,GMM),以期望最大化算法(Expectation-maximum algorithm,EM 算法)对高斯混合模型中各子高斯函数的权重(α)、均值(μ)、标准差(σ)参数进行迭代求解;最后,以采样点构建泰森多边形,并将采样点分类结果赋值到多边形后进行同类多边形合并,形成环境质量初步分区,结合自然与人为影响因素的范围对分区结果进行边界调整。
1.2.1 主要影响因素分析
区域土壤重金属受自然或者人为因素影响,重金属在产生过程中往往存在一定伴生性[28],在数值上表现为强弱不一的相关性,直接采用原始观测值进行聚类分析容易受到噪声干扰。本文采用主成分分析法(PCA)对归一化后的412个土壤样品的重金属指标(Cd、As、Cr、Hg、Cu、Pb、Zn等)进行特征降维,筛选前N个数值>1的特征值(N≥1)及对应特征向量,并对原始数据进行特征向量投影变换,变换后得到特征向量组PC(PC1,PC2,…PCN),N个特征向量可表征区域环境质量综合特征,反映不同重金属指标的总体相似性和差异性。
采样点的初始分类数对最终环境质量分类有影响,容易导致分类结果陷入局部最优解。在进行高斯混合建模前有必要对区域环境质量主要环境影响因素进行识别,通过主要影响因素分类对采样点进行预分类。地理探测器[29]可以用于探测环境质量特征变量PCN的空间分异性(也称空间分层或者分类),即探测环境质量影响因素Y(是土壤类型、土壤质地、土地利用方式、工矿企业排放、河流等中的一个类别型变量)多大程度上解释了环境质量特征变量PCN的空间分异,统计量q通过F检验,则说明该影响因素有较强解释力。具体计算公式及步骤如下:
式中:h=1,2,…,L为环境质量影响因素Yi(z1i,z2i,…,zLi)分类或环境质量特征PC 的分层;Nh和N分别为层h和全区的采样点数分别为相应层h和全区的土壤环境质量特征的方差。qϵ[0,1],其q值越大表明影响因素Y对特征变量PCN的解释力越强,此时环境影响因素Y的分类数可以作为高斯混合模型建模的预分类数K。q的显著性可采用F非中心分布进行检验,见公式(2)。
式中:N为采样点数;λ为非中心度。
对研究区域中各环境影响因素分层下的异质性进行比较,通过显著性检验的影响因素为采样点的主要影响因素。由于每个采样点空间位置上的土壤环境辅助变量因子属性具有唯一性,因此通过空间对应关系可将具有相同影响因素类型的采样点分为同一类,作为土壤采样点的预分类。该预分类方法基本可以保证各类采样点之间呈现出分异规律,是一种合理的初始化方式。
1.2.2 采样点的聚类方法
高斯混合模型是多个高斯分布函数的线性组合,理论上GMM可以拟合出任意类型的分布,通常用于解决同一集合下的数据包含多个不同的分布、同一类分布但参数不同、不同类型的分布(比如正态分布和伯努利分布)等情况。区域环境质量受自然和人为因素综合作用,其概率分布往往呈右偏态分布(图3),若将自然或者人为因素影响的过程看作多个高斯过程或者其他随机过程的综合效应,则可用高斯混合模型表示。高斯混合模型一般采用EM算法进行参数的求解。本文以主要影响因素的K个分层,即主要影响因素的K个类型对土壤环境质量综合特征预分类(见1.2.1),在此基础上,通过高斯混合模型对特征变量PC聚类建模,并使用期望最大化算法(EM算法)对模型中的参数进行估计,具体步骤如下:
(1)高斯混合模型初始化
将K个高斯模型线性组合的高斯混合模型P作为区域环境质量模拟,其表现形式为:
式中:a=(a1,a2,…,an),ai为第i个土壤采样点上的环境综合特征向量;K为子高斯模型个数;θ=(α1,α2,…,αK;θ1,θ2,…,θK);αk为系数为第k个分模型高斯分布密度分别为第k个分布的期望和方差。
初始化时以模型变量γik表示分类结果,结合采样点与第k类环境影响因素因子的对应关系,预分类过程如下:
所得到的γik初始值由采样点在土壤环境主导因素影响下的分类情况确定。则完整数据集合A=完整数据的对数似然函数为:
(2)参数估算
E步:计算分模型k对观测数据ai的响应度,计算方法如下:
其中θ是上一步迭代运算求得的参数值。
M步:求Q对θ的极大值,即求新一轮迭代的模型参数,计算方法如下:
1.2.3 初始分类结果的分区
在实际土壤环境质量管理中需要基于同类相近原则对土壤采样点划类归区,形成具有等级关系的子区域[30]。本文在土壤采样点聚类分析结果上,根据采样点集的几何位置生成相应泰森多边形(Voronoi图),将具有共享边(Rook 连接)且有相同聚类等级的泰森多边形要素合并为初步分层要素,并赋予相应的类型,实现土壤采样点“点到面”的变换(泰森多边形法)。针对破碎化现象严重的区域,依据相近相似性原则,进一步结合河流、道路等边界对分区范围进行边界调整。
1.3 数据处理过程
本文数据处理方法及步骤如下:(1)运用SPSS 25对Cd、As、Cr、Hg、Cu、Pb、Zn 7种土壤重金属含量进行统计分析、正态分布检验和皮尔森(Pearson)相关性分析,探索数据的统计规律和各重金属之间的相关性。(2)通过SPSS 对多种土壤重金属采样数据进行主成分分析,提取表征土壤环境质量的主成分综合变量。(3)采用地理探测器软件(www.geodetector.cn)分析土壤类型、土壤质地、土地利用类型等环境影响辅助因素与主成分向量之间的相关关系。(4)基于MATLAB 2017a 平台编写基于先验环境影响主导因素预分类的高斯混合模型(GMM)算法,对代表土壤环境质量综合特征的主成分向量进行聚类分析。(5)根据采样点空间位置信息运用ArcGIS 10.5 生成相应范围的泰森多边形,并将互为邻域且具有相同分类属性的多边形要素合并后,作为初步分层(分类结果)。(6)在ArcGIS 平台中结合研究区河流、道路分布,对初步分区结果的边界进行调整。
2 结果与分析
2.1 采样点探索性分析
与北京地区土壤重金属背景值相比较[31],除Pb外其他重金属(类金属)指标具有不同程度的积累效应。Cd、As、Hg、Cu、Pb 等重金属指标的变异系数均大于25%,达到了中等变异水平。除Cr 外其他土壤重金属频率分布图呈现不同程度右偏态,表明研究区内局部地区受工矿企业、河流灌溉等因素影响,Hg、Cd、As指标的最大值已接近筛选值,表明在某些样点上存在一定程度的风险。北京市土壤pH 均值为7.64[32],总体上看,各重金属含量均值、中位值低于《土壤环境质量农用地土壤污染风险管控标准(试行)》(GB 15618—2018)中pH 值大于7.5 时的筛选值,从土壤污染评价的角度看该区土壤总体质量属于优先保护类。顺义区土壤重金属描述性统计如表1所示。
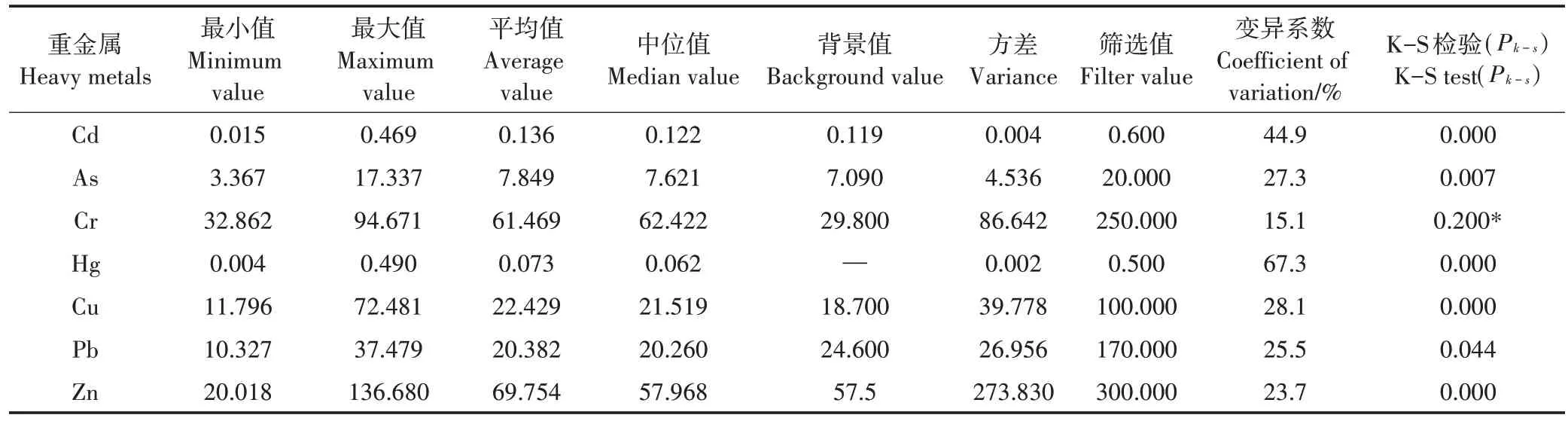
表1 区域土壤重金属统计特征(mg·kg-1)Table1 Statistical characteristics of heavy metal content in regional soil(mg·kg-1)
2.2 采样点预分类结果
基于Pearson 系数法分析各元素之间的相关性,结果如表2所示,其中Zn与Cu之间的相关性最强,相关系数高达0.476,说明该两个指标具有相对较高的信息重叠,As 与Cd、As 与Cu、Cd 与Cu、Cd 与Pb 之间具有较为显著的相关性(r≥0.2,P<0.05),说明其相互之间也存在部分信息重叠,存在一定程度的同位或伴生性,有相关性的土壤重金属指标可能受相同自然或人类活动因素影响。
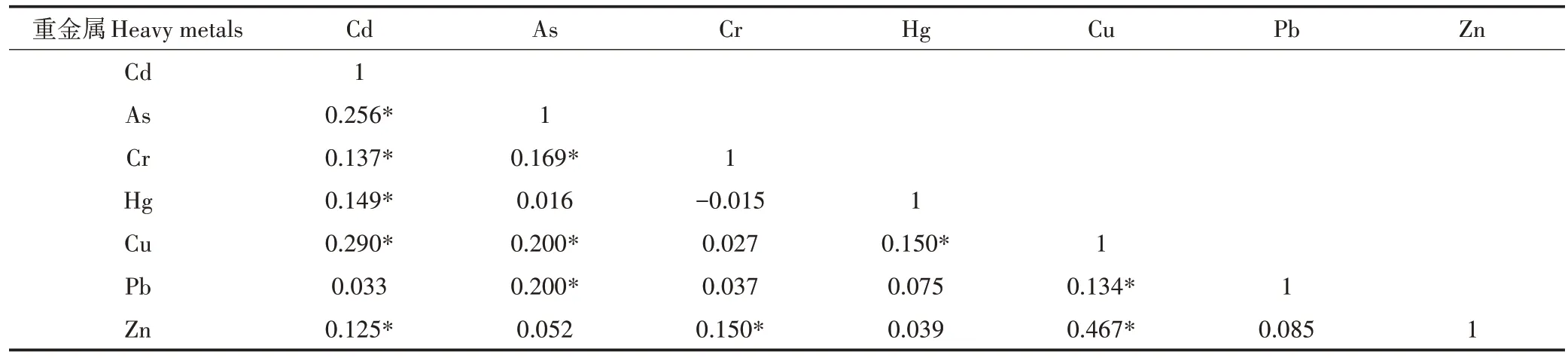
表2 土壤重金属含量相关系数矩阵Table2 The correlation coefficient matrix of soil heavy metal content
本研究采用PCA 分析法对土壤采样点重金属指标进行降维,其结果如表3 所示。选取特征值大于1.0(特征值表示原始指标投影到该特征向量后的方差大小,方差越大则保留的原始信息量也越大)的对应特征向量PC1(特征值1.885)、PC2(特征值1.112),二者累积贡献率达到了42.8%,从表3 中主成分的因子载荷系数可以看出主成分PC1 主要表征土壤中As、Pb、Zn的含量,主成分PC2主要反映土壤中Cd、Cr的含量,可用PC1、PC2 特征向量表征区域土壤环境综合质量特征。
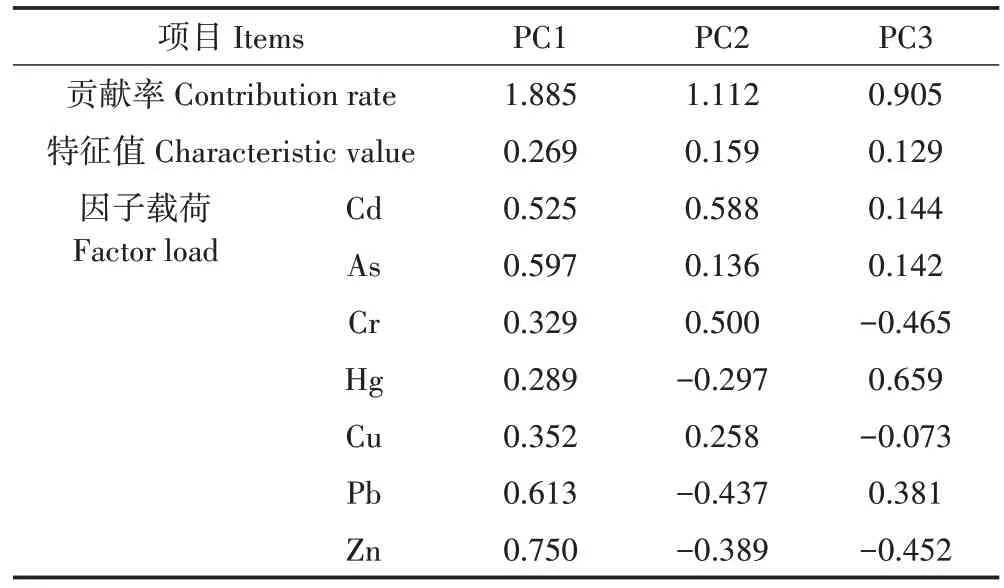
表3 土壤重金属的变量解释与主成分矩阵Table3 Variable interpretation and principal component matrix of heavy metals in soil
本文在采用主成分降维后的特征向量PC1、PC2进行采样点预分组时,通过地理探测器分析土壤环境影响因素Y{土壤质地、土壤类型、土地利用类型、河流影响、工矿企业影响范围}对特征向量PC1、PC2 的解释力,即分析土壤环境影响因素Y对特征向量PC1、PC2的q值的显著性。地理探测器检验各分组下样点主成分间分异结果如表4 所示。主成分PC1 在土壤质地(轻质壤、中质壤、沙质壤,根据砂粒度与黏粒度分类)、河流影响区的分类下q统计量满足F检验的显著性差异。其中,河流影响区以相关研究[33]为基础,通过半径1 km 的河流缓冲区获得。主成分PC2在土壤质地、土壤类型与土地利用类型的分类下q统计量具有显著性差异。研究区内土壤母质类型差异较小,而土壤质地的黏粒度越重则重金属淋溶程度越低,同时土壤胶体的吸附能力也越强[34],在一定程度上影响了土壤重金属的迁移和扩散能力。土壤环境质量的特征向量PC1、PC2 在土壤质地各类型中皆具有显著性差异,表明土壤质地对土壤环境质量空间分异有较好解释力。因此,采用土壤质地的空间分层作为土壤采样点预分类方案。

表4 不同影响因素分组下样点主成分间分异检验结果Table4 Test results of soil samples in different groups
2.3 土壤环境质量分区
采用土壤质地类型分区(轻壤质、中壤质、砂壤质)将土壤采样点初步分成3 类,作为高斯混合模型构建中研究区土壤环境质量主成分特征向量的初始类型,利用EM 算法对高斯混合模型中未知参数进行迭代求解,直到各子数据集符合正态分布概率最大。EM 算法对高斯混合模型(也称为GEM 聚类)进行求解的终止条件为似然函数收敛。经过32 次EM 迭代运算后,土壤采样点分成A、B、C 3 个种类,各类样点数目分别为279、99、34。基于此,运用泰森多边形划分法构建包含土壤采样点的土壤环境质量初步分区,结果如图5(a)所示。参考河流、道路对初步分区中细碎图斑进行适度调整,调整后的局部单元内部有多个类型空间分层时,将其归为面积占优的空间分区类型,最终形成土壤环境质量分区[图5(b)]。
为了进一步说明研究区环境质量分区合理性,本文查阅了影响土壤环境质量的文献资料[35-36](禽养殖业分布信息、河流道路空间分布数据、土壤类型数据、工矿企业空间分布等),并以呈现右偏态分布的土壤重金属指标Pb 在各分区中统计分布为例展开说明,对三类区的环境质量特点及可能原因进行分析。(1)A 类环境质量区:区内土壤重金属指标Pb 均值为14.06 mg·kg-1,方差为2.19 mg·kg-1,能通过正态分布检验,均值比较平稳。该区内土壤类型以潮土为主,面积占整个A 区面积的74.27%,土壤质地以轻壤质为主,占该子区域面积的50.80%,且与A 类分区具有较强的一致性,根据相关研究,轻质潮土上的腐殖质积累过程较弱[37],河流影响区占该子区域的24%,区内人为因素影响较小,土壤环境质量相对稳定;(2)B类环境质量区:区内土壤重金属指标Pb 均值为21.70 mg·kg-1,方差为3.72 mg·kg-1,比较平稳,能通过正态分布检验,但均值略高于A 类区,含量波动情况也略大于A类区。该区内同样以轻壤质潮土为主,潮土面积占整个B 区面积的49.42%,轻壤质占该子区域面积的55.40%,相比A 区略有减少,区内水资源相对丰富,河流总数和水量较大,按河流灌溉可达性分析占整个区内面积的27%,该区域以农业种植为主,主要种植水果蔬菜,用地呈现出高生产资料投入与轮作频率大的特征,同时区内农村居民地分布较多[38],土壤中容易发生一定的重金属累积;(3)C 类环境质量区:C 类区的土壤重金属Pb均值和方差分别为27.97 mg·kg-1与18.91 mg·kg-1,变化波动较大,但也满足正态分布检验。该区也以轻壤质潮土为主,潮土面积占整个C 区面积的65.17%,轻壤质占该子区域面积的50.80%,该区内工矿企业影响面积占该区49.4%,工矿企业用地面积相对较大,且子区域处于潮白河、箭杆河主要干道上,受河流影响面积占比高达48.1%,同时在2009 年前后禽类养殖业也较发达,粪便和饲料粉尘通过污水排放和大气沉降对周边产生影响,易造成重金属聚集[39]。
3 讨论
为了进一步说明聚类方法对土壤环境质量分区结果的影响,本文采用K-means 聚类分析、自组织特征映射神经网络(Self-organizing feature maps,SOFM)聚类进行土壤样点聚类方法的对比分析。具体聚类实验时,也采用上文提到的基于土壤质地预分类的土壤样点的PC1、PC2 特征向量作为聚类模型计算的输入,分类数K统一设置为3。在K-means聚类时,选择欧式距离为度量方式,直到没有对象被重新分配给不同的聚类,整体误差平方和局部最小为止;在SOFM聚类中,竞争层神经元个数依次设置为3,采用六角形拓扑结构,训练次数为500,直到竞争型神经网络取得最优解,聚类中心没有再发生变化。初步聚类结果按A、B、C 3类标记到土壤样点,采用泰森多边形法构建土壤样点初步分区,并依据河流、道路对细碎图斑进行分区边界微调。K-means 聚类下的A、B、C 类型点位数分别为244、56、112,在调整过程中有23.27 km2的B 类、12.55 km2的C 类调入A 类型,调整面积占总面积的2.8%;SOFM聚类下的A、B、C类型点位数分别为151、134、127,在调整过程中有16.13 km2的B类、46.88 km2的C 类调入A 类型,调整面积占总面积的7.73%,分区结果如图6(a)、图6(b)所示。
为比较3 种聚类分区结果的差异性,分别对各类型分区中的主成分进行统计分析,不同分区下主成分特征向量统计特征如表5 所示,通过比较各成分特征向量在不同子分区中的均值差异,其中以GEM 聚类分区中的差异最为明显;且在本文的GEM 聚类分区中,成分特征向量在A、B、C 3种分区下均能满足显著性检验,能揭示受相同环境影响因素作用的可能性,而在SOFM 聚类分区中,主成分PC1 在A、C 类区中都不能通过显著性检验,在K-means 聚类分区中,主成分PC2在B类区中不能通过显著性检验。
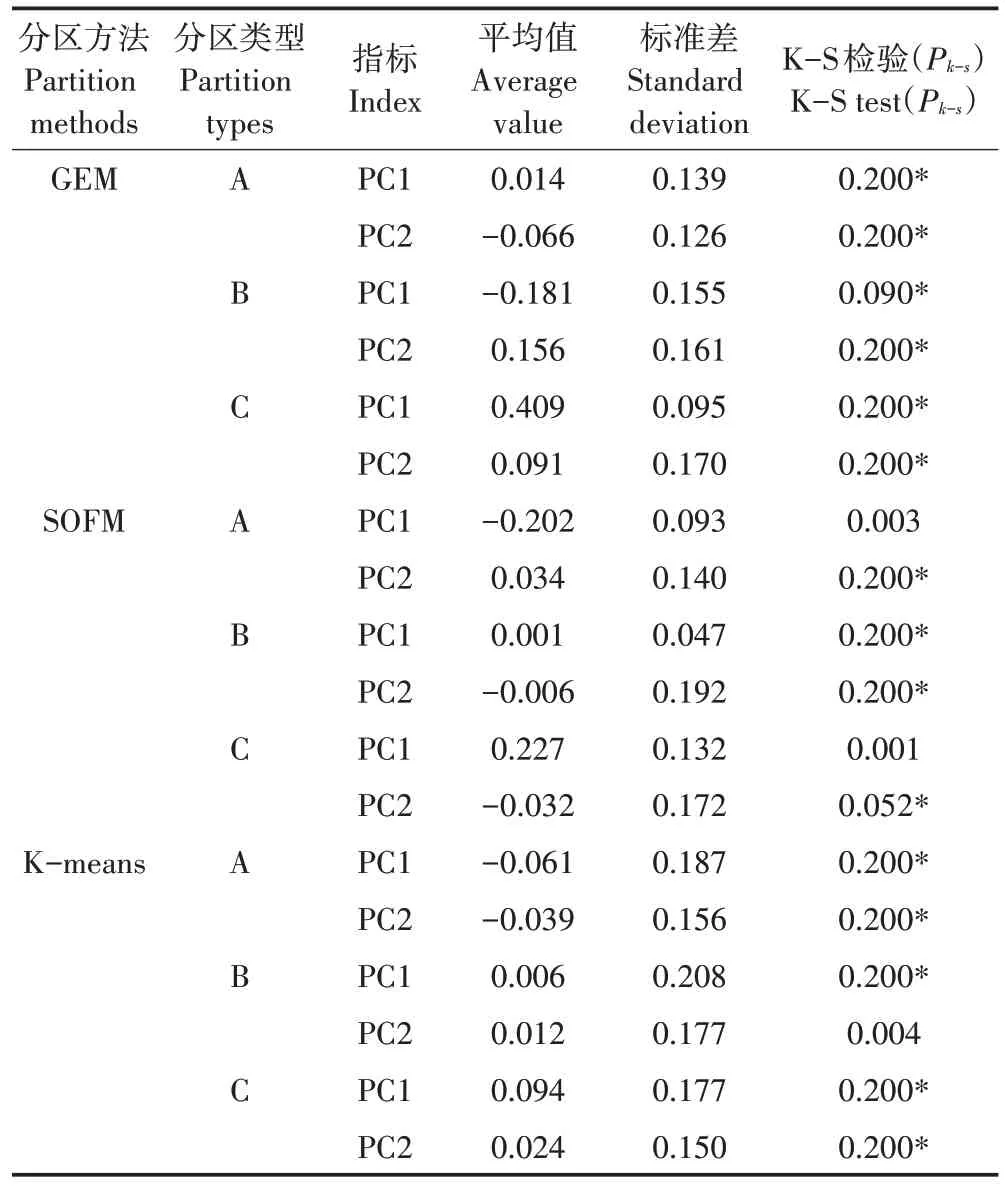
表5 不同分区下主成分特征向量统计特征Table5 Statistical characteristics of principal component eigenvectors in different partitions
为进一步比较3 种聚类方法的分区结果的差异性,本文采用地理探测器探测分区结果分析土壤环境综合质量的PC1、PC2 的解释力。采用GMM 分区结果、SOFM分区、K-means分区中的类型数作为地理探测器中自变量PC 的分层数,PC1、PC2作为自变量,各分区下样点综合质量分异性结果如表6 所示,其中主成分PC1 在GEM 聚类分区与SOFM 聚类分区下具有显著性差异,主成分PC2 仅在GEM 聚类分区方法下具有显著性差异,而K-means聚类方法下的主成分均无显著性差异。其可能原因是:SOFM 聚类是基于神经网络训练的分类,在各权向量分别向各个聚类模式群的中心位置靠拢时,容易受神经元排列的拓扑结构影响,导致权重分配不均[40];针对土壤采样点含量通常呈现右偏态分布的特性,K-means 聚类分析是以类与类之间的距离之和最小为约束的分类方法,只对各类的紧凑性进行约束,却不是针对重金属含量的分布特征进行划分[41];本研究中所采用的GEM 聚类方法是以多个高斯函数对右偏态分布的土壤环境质量进行描述,假设每个正态分布函数代表不同分类的重金属含量,相同分类的采样点具有同一数学期望和方差,将采样点分成受不同环境因素作用的多个正态分布类型,GEM 聚类分析让异类之间的差异性更大,同类之间的相似性更大,因而相比其他分层分区方法有着更好的空间分层异质性,使所得的分区结果与土壤环境质量空间分布具有高度一致性。
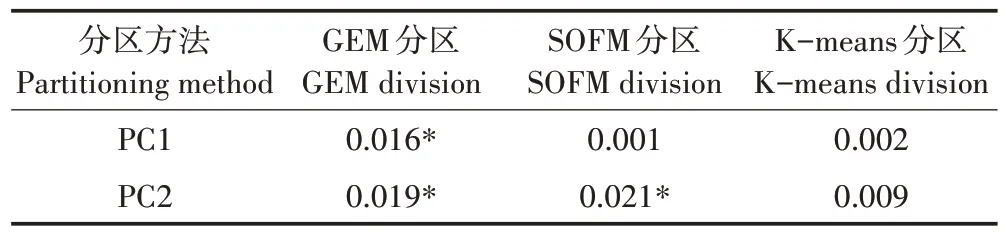
表6 不同分区方法下主成分间分异检验结果Table6 Test results of differentiation between principal components under different zoning methods
4 结论
(1)土壤重金属含量是环境影响因素综合作用的结果,基于高斯混合模型的聚类方法可用于区域环境质量分区。基于主要影响因素的土壤采样点预分类策略,避免了土壤采样点初始化分类的盲目性,有助于聚类结果的快速收敛,避免聚类结果陷入局部最优,环境质量分区的结果更接近客观认知。该土壤环境质量分区方法兼顾了采样点属性特征与环境辅助变量信息,分区方法在应用中具有可推广性,可为全国监测点的环境质量分区提供参考。
(2)以聚类分析的思想解析土壤环境质量空间分布具有良好的效果,基于高斯混合模型的聚类分区充分考虑工矿企业、河流、道路、土壤质地、土壤类型等不同影响的作用范围和尺度特征,可准确客观反映土壤环境质量分布的情况,是了解污染状况、过程、格局的手段和方法。不同类型空间分类分级是进行精准管理的前提,准确的先验分区可用于进一步指导布点监测调查。
猜你喜欢
中国农业科学(2022年17期)2022-09-19
中国应急管理科学(2022年2期)2022-05-23
保定学院学报(2022年2期)2022-04-07
皮革制作与环保科技(2021年6期)2021-11-28
炎黄地理(2018年11期)2019-01-24
数学学习与研究(2018年15期)2018-11-12
中学数学研究(2008年11期)2008-01-05