
基于平行语料库的英汉跨语言信息检索设计研究
2021-09-05 11:43叶雪,梁娟
电子设计工程 2021年17期
叶 雪,梁 娟
(陕西财经职业技术学院,陕西 咸阳 712099)
信息时代中出现了大量的数字信息,文本信息为最常用、最基本的方式,为了能够在海量文本信息中寻找自己所需要的,人们需要高效检索工具。如何能够对非结构数据进行存储与查询,属于重点研究内容[1]。上世纪90年代,人们对信息检索的要求越来越高,不再满足同个语种检索,要在检索结果中具备多语种信息。在国际互联网不断发展的过程中,Internet中信息资源数量与类型越来越丰富,语言也具备不平衡性与多样性。网络用户数量也越来越多,掌握语言也多样化。因为网络资源语种多样性与网络用户对语言掌握的差异化,导致人们通过网络对信息检索出现语言障碍,为非英语国家用户使用网络信息带来了不便[2]。因此,英汉跨语言信息检索设计的研究具有重要意义。
1 系统结构设计
跨语言信息检索(CLIR)中的查询根据长度划分为长查询、短查询与标题查询,查询翻译已经成为针对跨语言信息检索最流行的技术,性能达到单纯检索效率的50%~75%;并且创建查询翻译处理模块和创建文档翻译处理模块对比,前者比较容易实现[3]。所以,将基于平行语料库的查询翻译作为跨越源语和目标语的语言界限方法,并且用英语双语词典作为主体的知识源实现查询翻译处理。在创建的面向英汉跨语言信息检索系统中,重点为汉语IR与查询翻译。实现系统的思想为:使初始源语(英语)查询翻译成为目标语(汉语)单词列表,之后通过翻译处理进行查询,利用汉语IR技术和概率方法得到相应文档列表。通过全自动的方式实现全部查询处理,包括短查询、长查询的翻译处理[4],图1为英汉跨语言信息检索系统的结构。

图1 英汉跨语言信息检索系统的结构
2 英汉跨语言信息检索的设计
2.1 翻译算法
英汉跨语言信息检索的翻译算法主要包括预处理、预分析和翻译处理,其中预处理指的是英语查询分词、大小写变换、标记标点符号等预处理过程;翻译处理为实现英语查询短语层、词汇层两层翻译的处理过程;预分析指的是实现英语查询中单词形态恢复、禁用词标记、词性分析等处理的过程[5]。
2.1.1 预处理
英语分词查询过程中,要利用不同标点符号启发式方法分割句子,以空格作为标志,将每个句子字符切割成为单词流;针对通过分词处理得到的单词流,使其中的标点符号实现标注处理;因为英语查询大部分都是新闻报道标题,首字母都是大写形式的词汇,所以要正确判断,针对单词首字母进行大小写变换处理,为后续操作提供正确信息[6]。
2.1.2 预分析
英语查询通过预处理之后,预分析要标注其中的禁用词,并且恢复变换形势的单词。一个词可能会具有多种不同的词性,在不同句子中的语法性能各有不同。所以,要决定一个词的词类需在具体句子中以其他词的语法功能进行判定。基于隐马尔可夫模型HMM词性标注器实现正确地标注词类[7]。
因为英语查询中具备变化形式的单词,不利于得到正确的翻译结果,所以,要通过英汉双语词典,利用不规则形态恢复表和规则变化启发式实现单词形态恢复处理,得到相应的原形[8]。
2.1.3 翻译处理
词汇层翻译是通过英汉双语词典的基本词典部分进行逐词翻译,其中包括词义消歧问题。语境条件为语法语义参数,在具体词选择的过程中,对词义进行标记,此标记表示一定的语义、语法特征,即概念码[9]。
短语层翻译是通过英汉双语词典成语部分实现,涉及远距离、近距离短语识别的问题,重点为近距离短语识别和翻译处理过程,使用正向最大匹配法,过程为:
1)通过英汉双语词典得到以目前查询词作为领头词的短语集合;
2)创建基于目前查询词,并且具有词汇数和短语集合各成员的短语。
对比所创建的短语和短语集合的各成员,假如有一对成功匹配,就进行短语标记,若除了处理部分以外第一个单词属于当前查询词,则重复匹配过程;假如有多对成功匹配,就要选择长度最大的进行短语标记,并将其作为目前查询词,重复匹配过程;假如没有匹配成功,使目前查询词相邻的下个单词成为目前查询词,重复匹配过程[10]。
在处理过程中,利用式(1)进行翻译处理和排序:

以式(2)定义语项权重:
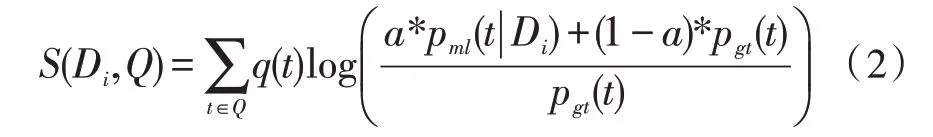
式(2)中的q(t)为语项t权重,一般为查询频率:
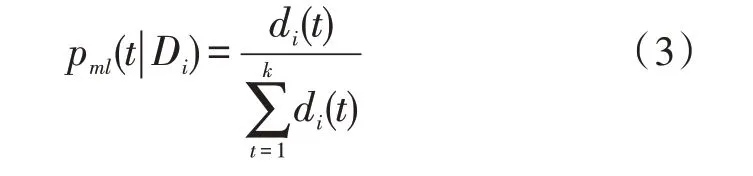
式(3)中,di(t)为语项t在文档Di中出现的次数,k为语料库不同的语项数目,n为文档集文档数目。
对于p(t)中Turing-Good的估计,利用pat(t)=pr(t)r*/N得到:

式中,r为语项t在文档集中出现的次数,Nr为文档集中r次语项数目,N为文档集观察得出的全部语项数目。针对每篇文档,能够通过以上公式实现处理和排序。
2.2 索引模块设计
索引模块在分析预处理纯文本文件之后,创建倒排索引生成索引文件在磁盘中写入,从而实现全文索引,图2为索引用例图,图3为索引模块图。在开始索引时,要得到待索引文档集路径,需保存索引文件路径,并分析是否要重建索引参数[11]。之后,新建索引对象、分词模块加载分词词典,对文档进行读取。如果文档为中文,就调用分词模块实现分词处理;如果是英文,则不需要分词,通过解析器对文档进行解析,以此为索引对象增加此文档对象,最后利用写索引机制使词语单词等信息写入到索引中,并且生成索引文件保存在磁盘中[12]。
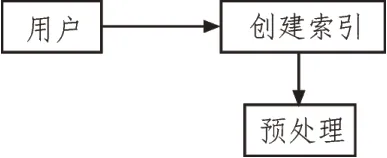
图2 索引用例图
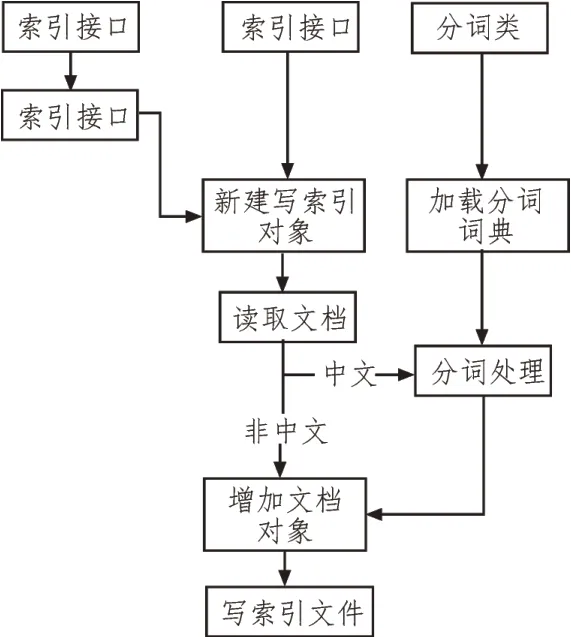
图3 索引模块图
在开始索引时,要将待索引文本路径根据扫描的文本文件实现内容的读入,之后创建写索引对象,加载分词词典,调用分词模块并实现分词处理,将得到的词用空格分开[13]。最终,将此词写入索引,通过分析器分析。之后调用IndexEriter类中的addDocument对CLucene调用实现索引,用directory类对CLucene索引存储的位置进行描述。其属于抽象类,有两个子类,能够提供特定的存取索引方法。对于待索引大量文档集,将文档存储路径告知CLucene,实现Directory实例的生成,并且将此实例传递给构造函数[14]。然后,利用Directory实现IndexWrieer,在某个指定目录中创建索引文件,并存储在磁盘中。
在跨语言检索过程中,用户输入索引式、索引文件路径与查询相关度范围之后,系统能够进一步处理检索式,如果为中文检索式,则通过分词处理之后利用翻译构成最终英文检索式;如果为英文检索式就直接翻译,转变为中文检索式[15-16]。
3 系统测试
因为汉语查询集都是通过Big5字符集实现编码,汉语处理工具以基于GB字符编码为主,所以针对初始汉语查询集,要通过Big5码-GB码转换器,使其朝着GB字符集编码方式转变。文中选择3个新闻集合作为案例,一共有242 918篇文档,表1为相关英语语料库的统计数据。

表1 相关英语语料库的统计数据
针对目前信息检索系统,利用准确率与查全率对系统检索性能进行衡量。在检索过程中使用以下方法进行评价:利用多个检索系统对同个查询检索之后,将其返回的最相关的前100篇文档合并,并且对比文档集进行人工相关性评价。该方法能够降低评价工作量,还能够使评价准确度得到提高[17]。
在训练英语语料库过程中,得到最好的结果平均查准率为0.386 9,在汉语查询集和除了训练部分之外的英语语料库测试过程中,自动查询模式通过分词方式实现索引处理,最后单语使用基于n元组的切分方法实现索引处理。图4为测试结果,表2为汉英跨语言信息检索运行结果和平均中值对比。通过对比表明,汉英CLIR的运行中C-ECLIR1性能是最佳的。
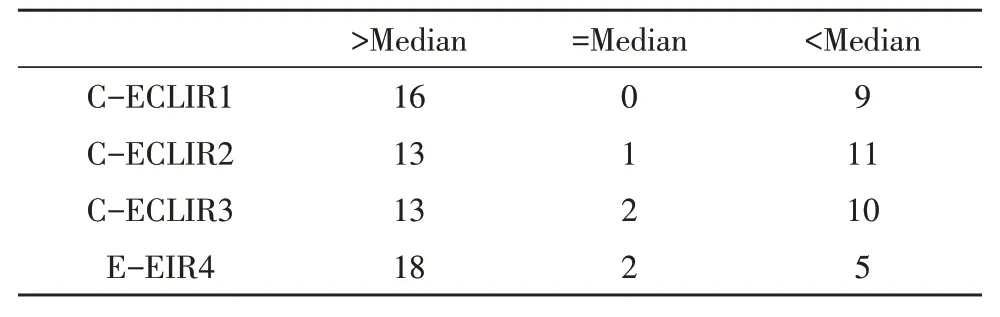
表2 汉英跨语言信息检索运行结果和平均中值对比
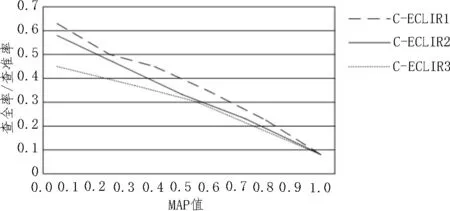
图4 测试结果
目前,所创建的跨语言信息检索系统已经初成规模。通过系统运行情况和测试评估可知,查询翻译器和汉语搜索引擎的系统性能满足要求[18]。
4 结束语
跨语言信息检索技术属于全新信息处理技术,此技术为计算语言学信息处理带来全新的解决途径。文中设计面向英汉的跨语言信息检索系统属于机器翻译技术在信息检索领域中使用的全新尝试,能够有效促进跨语言信息检索问题的解决。在英汉查询翻译中,主要将英汉双语词典作为主体的知识源。但是,除了词典完整性问题,还要通过词典中选择单词最佳翻译。以此,文中创建了英汉翻译处理模式和短语层翻译处理模式,与词类标记等信息结合,得到正确的翻译结果。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
新闻传播(2016年18期)2016-07-19
新闻传播(2016年11期)2016-07-10
现代计算机(2016年11期)2016-02-28
河北传媒研究(2015年1期)2015-07-12
山西大同大学学报(社会科学版)(2015年6期)2015-01-22
图书馆界(2013年5期)2013-03-11
外语学刊(2011年3期)2011-01-22
