
基于灰度共生矩阵和支持向量机的茶叶病害诊断研究*
2021-09-03 10:12:16周文玉
贵州科学 2021年4期
陈 荣,李 旺,周文玉
(1铜仁学院 大数据学院,贵州 铜仁 554300;2铜仁市为拓网络技术有限公司,贵州 铜仁 554300)
0 引言
茶叶作为茶农的重要经济支柱,在当前精准扶贫形势下是茶农脱贫的重要产业[1]。 消费者更加注重茶叶的品质,“绿色、生态、有机”茶叶成为茶叶市场的新宠儿[2]。然而,因为不能有效地诊断茶叶病害而滥用农药、化肥,严重地影响了茶叶的品质,损失了茶叶市场。因此,对茶叶病害进行正确的诊断对提高茶叶的竞争力极具重要意义。目前,茶叶的诊断主要靠茶农的经验和植物保护专家的病理知识进行主观、模糊的判断[3],缺乏客观的评估,即便有经验的专家在诊断茶叶病害时也常常出现错误。不同的茶叶病害由于致病的机理不同而使得茶叶病斑具有不同的纹理,因此可以利用提取茶叶病害的纹理特征和支持向量机技术来识别茶叶病害,提高茶叶病害诊断的科学性,促进数字农业的发展。
1 茶叶病害识别模型
1.1 基于灰度共生矩阵的纹理特征构造与提取
特征提取是茶叶病害图像识别的前提,只有正确地提取出病害的特征才能进行正确的识别。不同的茶叶病害有不同的纹理,灰度共生矩阵是分析纹理特征常用的二阶统计方法,描述了灰度空间的相关性,能够反映出纹理结构的变换[4],是一种区分能力较强的特征。
灰度共生矩阵Pd表示灰度为i和j的两个像素具有某种空间关系d的情况出现的次数[5]。常用的位置关系有0°、45°、90°、135°,也就是说不同的位置关系可以确定不同的灰度共生矩阵[6],进而不同的病害有不同的纹理特征。因此,本研究采用灰度共生矩阵提取了以下5种纹理特征。
1.1.1 对比度(Contrast)
对比度描述了纹理沟纹的深浅程度;值越大,纹理的沟纹越深,图像越清晰。计算公式:
(1)

1.1.2 相关性(Correlation)
相关性描述了相邻像素间灰度的线性关系,即像素间的相似度;当灰度共生矩阵中各元素的值相差越大,则相关性就越小。计算公式:
(2)
1.1.3 能量(Energy)
能量描述了图像灰度分布的均匀程度;当灰度共生矩阵中各元素的值相差越大,则能量就越大。计算公式:
(3)
1.1.4 熵(Entropy)
熵是纹理图像的信息度量,描述了图像纹理的非均匀程度和复杂度;值越大,纹理越复杂。计算公式:
(4)
1.1.5 同质性(Homogeneity)
同质性描述了图像的局部平滑性。计算公式:
(5)
1.2 支持向量机算法
支持向量机(Support Vector Machine,SVM)是一种分类性能好的分类识别技术,能够兼顾训练误差和测试误差,能够有效地解决小样本、高维、非线性等方面的识别问题[7]。
对于线性可分的问题,可以被一个分类线(二维空间)或分类面(多维空间)无差错的分开,使分类间隔最大的分类线(面)为最优分类线(面)。如图1(a)所示。设线性可分的样本集{(xi,yi),i=1,2,…,N;j=1,2},求出最优分类判决函数为[8]:
(6)
式中,α*为支持向量对应的拉格朗日乘数;b*为分类阈值;x为待分类的测试样本;xi(i=1,2,…,N)为N个训练样本。
对于线性不可分的问题,如图1(b)所示。允许个别样本分类错误近似实现可分,权衡考虑最大分类间隔和最小错分样本数,引入正松弛项ξi和代价系数C两个参数,最终求出最优分类判决函数与式(6)同。
对于非线性可分的问题,如图1(c)所示。利用核函数将低维空间中的非线性问题转换到高维空间中的线性可分问题,在高维空间中求最优分类面。求出最优分类判决函数为[9]:
(7)
式中,α*、b*、x、xi与式(6)同;SV为支持向量的集合。

图1 不同情况下的SVM分类识别模型Fig.1 SVM classification and recognition modelsunder different conditions
茶叶病害的识别属于多特征的非线性可分问题,不同的核函数表现不同的SVM算法,对茶叶病害的正确识别有比较大的影响。常用的核函数为[10]:
1)线性核函数(Linear):
K(x,y)=x·y
(8)
2)多项式核函数(Polynomial):
K(x,y)=[γ(x·y)+c]d
(9)
式中,d为确定映射空间的维度。
3)径向基核函数(RBF):
(10)
4)Sigmoid核函数:
K(x,y)=tanh[γ(x·y)+c]
(11)
2 材料与方法
2.1 茶叶病害图像获取和处理
贵州省梵净山区茶叶资源极其丰富,有野生茶树,有实生茶树,也有无性系茶园,非常利于茶叶病害样本的采集,采集时间为3月至5月早晨6∶00~8∶00的生长旺盛、病症明显的时间段,自然光照条件下采用Canon G35X110Z数码相机进行采集,图像大小为2200×1836像素,存储格式为JPG,采集了茶炭疽病、茶饼病和白星病3种较为常见的病害3×60共180幅图片,从每种病害中分别选取包含病斑、大小为90×90dpi的子图像80幅。
由于纹理特征是灰度图像在空间以一定形式变换产生的图案,因此在提取纹理特征前需要对采集的彩色图像进行灰度处理;为了抑制噪声对图像质量的影响,要对病害图像进行中值滤波平滑处理。如图2所示。

图2 茶叶病害图像预处理Fig.2 Preprocessing of tea disease images
2.2 实验工具的选择和SVM多分类识别器的建立
采用Matlab 8.0实现编程,采用Matlab图像处理工具箱进行图像处理。Matlab SVM工具箱主要通过svmtrain()函数实现识别模型的训练和svmclassify()函数实现模型的分类识别功能。但是它是一个二分器,只能用于两类样本的识别,为了解决多类样本的识别问题,本研究提出投票最大策略建立SVM多分类识别器。算法如下:
1)将茶炭疽病、茶饼病和白星病3类样本两两组成训练集,得到3个SVM二分类器,即(炭疽病,茶饼病)、(炭疽病,白星病)、(茶饼病,白星病)。
2)将炭疽病、茶饼病和白星病3类样本的票数初始化为0。
3)将测试样本x使用(炭疽病,茶饼病)分类,如果分类器将x判定为炭疽病,则炭疽病的票数增1,否则茶饼病的票数增1;将测试样本x使用(炭疽病,白星病)分类,如果分类器将x判定为炭疽病,则炭疽病的票数增1,否则白星病的票数增1;将测试样本x使用(茶饼病,白星病)分类,如果分类器将x判定为茶饼病,则茶饼病的票数增1,否则白星病的票数增1。
4)最后,计算将测试样本x分别判定为炭疽病、茶饼病和白星病的票数,谁的票数最大,该测试样本x就最终判定为该类病害。
3 结果与分析
3.1 不同核函数的SVM识别性能
从每种茶叶病害的纹理特征数据中随机选取100个样本作为训练集、30个样本作为测试集。上述5种纹理特征作为特征向量,分别采取径向基核函数、线性核函数、Sigmoid核函数、多项式核函数的SVM。训练参数设置:松弛项ξi=0.0038、代价系数C=26,其中:RBF核函数中的γ=1/3;Sigmoid核函数中γ=1/2,c=1;Polynomial核函数中的d=3,γ=1,c=1。识别结果如表1。

表1 不同核函数的SVM识别性能Tab.1 Recognition performance of SVM based ondifferent kernel functions
实验结果表明:不同核函数的SVM识别性能不同。径向基核函数对茶叶病害的识别性能最好,总识别率达到了86.67%,线性核函数和多项式核函数稍差,Sigmoid核函数的性能最低。所以,径向基核函数的SVM比较适合于茶叶炭疽病、茶饼病和白星病纹理特征下的识别。
3.2 不同训练样本数的SVM识别性能
从每种茶叶病害的纹理特征数据中随机选取120、90、60、30个样本作为训练集,每种茶叶病害另外分别选取30个作为测试集。采取径向基核函数的SVM型,识别结果如表2。训练参数设置:松弛项ξi=0.0038、代价系数C=26,RBF核函数中的γ=1/3。
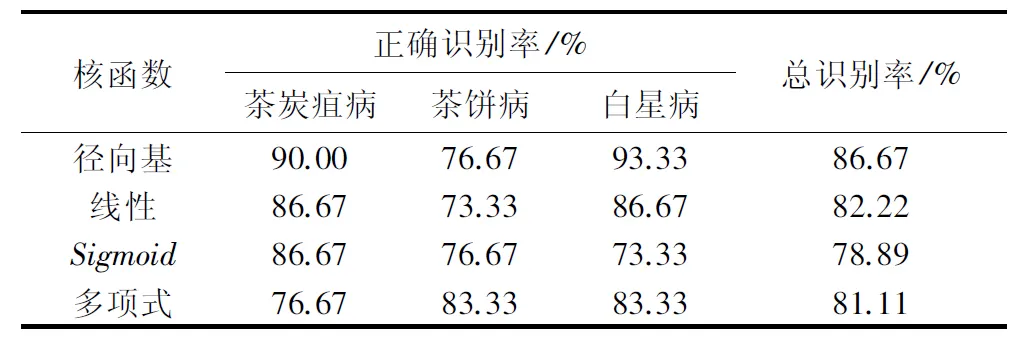
表2 不同训练样本数的SVM识别性能Tab.2 Recognition performance of SVM based ondifferent numbers of training samples
从表2可以看出,不同训练样本数的SVM识别性能不同。当训练样本在120和90的时候,识别率差别不是很大,都有比较高的识别率;当训练样本减到60和30的时候,识别率稍微下降,还在可以接受的范围内。这表明减少训练样本数对识别结果的影响不是很大,SVM稳定性好,在解决小样本分类的问题上有独特的优势。这是因为训练样本数快速的减少对支持向量数(即图1(a)(b)中H1和H2上面的样本点数)的减少影响比较小,只要样本中占少数的支持向量不变,分类模型基本保持不变,不会严重的影响到最优分类面,即分类判决正确率不会有太大的变化。
4 结论与展望
本文利用纹理特征和SVM的识别方法对茶叶病害进行识别,以灰度共生矩阵构造了5个纹理特征参数,茶叶病害识别结果表明:以对比度、相关性、能力、熵和同质性为纹理特征比较适合于茶叶病害的识别,识别率比较高;RBF核函数的SVM识别性能最好;SVM识别方法比较适合于训练样本数较少的病害识别。
本文以Matlab 8.0作为数据处理工具,对茶叶病害的SVM识别方法进行编程和实验,不能做到在茶园中实时识别。采用Python语言进行算法编程并移植到机器中以对茶叶病害进行实时诊断,促进机器学习和人工智能在农作物病害识别中的应用,这将是以后研究的重点。
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
茶叶学报(2022年2期)2022-07-26 01:00:14
现代畜牧科技(2021年4期)2021-07-21 06:13:34
西南农业学报(2021年3期)2021-05-25 05:20:58
软件(2020年3期)2020-04-20 01:45:18
醒狮国学(2019年10期)2019-02-24 06:54:26
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:00
Coco薇(2017年8期)2017-08-03 15:23:38
Coco薇(2015年5期)2016-03-29 23:22:15
营销界(2015年23期)2015-02-28 22:06:16
