
云计算环境下的海量图像查重算法设计
2021-09-01 14:18:34高兴
绥化学院学报 2021年9期
高 兴
(沈阳音乐学院公共基础部 辽宁沈阳 110818)
云计算技术是借助于大规模低成本的服务器构成的分布式计算系统,将海量的数据通过网络云进行分解或者分类,将结果传送或者反馈给用户。云计算能够按照用户需求提供云服务,且具备运行成本低、可靠性高、扩展性好等优势[1]。云计算包括虚拟化技术、分布式海量数据存储和分布式计算技术,可以实现庞大、复杂的数据信息等资源处理,使海量的数据信息在较短时间内完成处理,提高数据信息的处理效率[2]。图像作为当下主要的信息传播方式,在众多领域都广泛应用,如何在海量的图像中判断相同的图像,已然成为当下图像查重领域的主要研究内容。
一、云计算环境下的海量图像查重算法
(一)云计算环境下的海量图像识别技术。海量图像分类是图像查重的前提,为了更好地完成海量图像分类,采用云计算技术完成[3]。在云平台上利用云计算技术实现图像分类处理的整体流程。图像分类需先提取云平台上图像数据库中的图像特征,并将待分类图像特征与图像库中图像特征进行匹配,根据匹配结果完成图像的类别划分[4]。云计算技术图像分类原理如图1所示。其中,图像预处理主要作用是完成图像的色彩转换,并将转换后的图像存储。采用相关特征提取方法完成存储图像的数据计算,获取图像特征[5]。

图1 云计算技术图像分类原理
利用图像分类器将图像特征数据样本进行训练,并将训练后的结果存储于本地文件中,用于图像分类。分类器主要运行步骤如下所述:
(1)通过云平台上传海量图像数据信息,上传完成提交后,从分布式文件系统中获取数据源,通过数据集群配置划分数据,并分类处理上传的Reduce和Map,并输入Reduce和Map过程中的节点信息。
(2)操作时,读入储存在分布式文件系统中图像样本的同时,使用遗传算法优化数据样本参数类型转换后的组合参数,完成svm—train函数的调入。为获取支持向量,需完成样本数据的训练,并将处理结果输入在Reduce中。
(3)实现Reduce的操作过程,采用数据形式key/value完成分类和排序Map函数的转换,向实现规定的路径文件中输入处理后的数据,输出图像分类结果。
(二)基于Zernike矩阵的图像比对。
1.比对算法流程。采用Zernike矩阵完成分类图像比对,步骤为:
(1)由于图像旋转后可能存在伪边块,为将其去除,需要先完成两幅对比图像(图像A和B)的伪边块检测,确定两幅图像的区域和大小,将伪边块去除后,保存图像区域的有效内容[6],即为A1和B1。
(2)采用插值法对B1实行图像归一化处理,使B1和A1的大小相同,得出B2。
(3)将A1旋转,旋转次数为s,每次旋转角度为360/s,计算A1每次旋转结束后的第T个Zernike矩,并且T≥2,根据计算得出的数值构建S*T矩阵,其为:

(4)对矩阵KA的每一列进行均值和标准差的计算,获取均值向量和标准差向量,分别为其中:
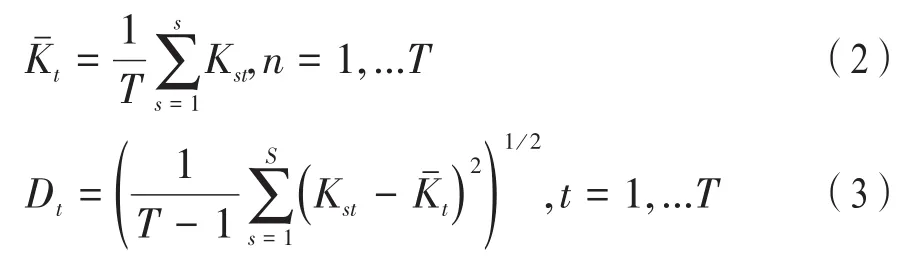
(5)无需对B2进行旋转,对A1相对应的T个Zernike矩进行计算,得出矩值向量VB。
其具体流程如图2所示。
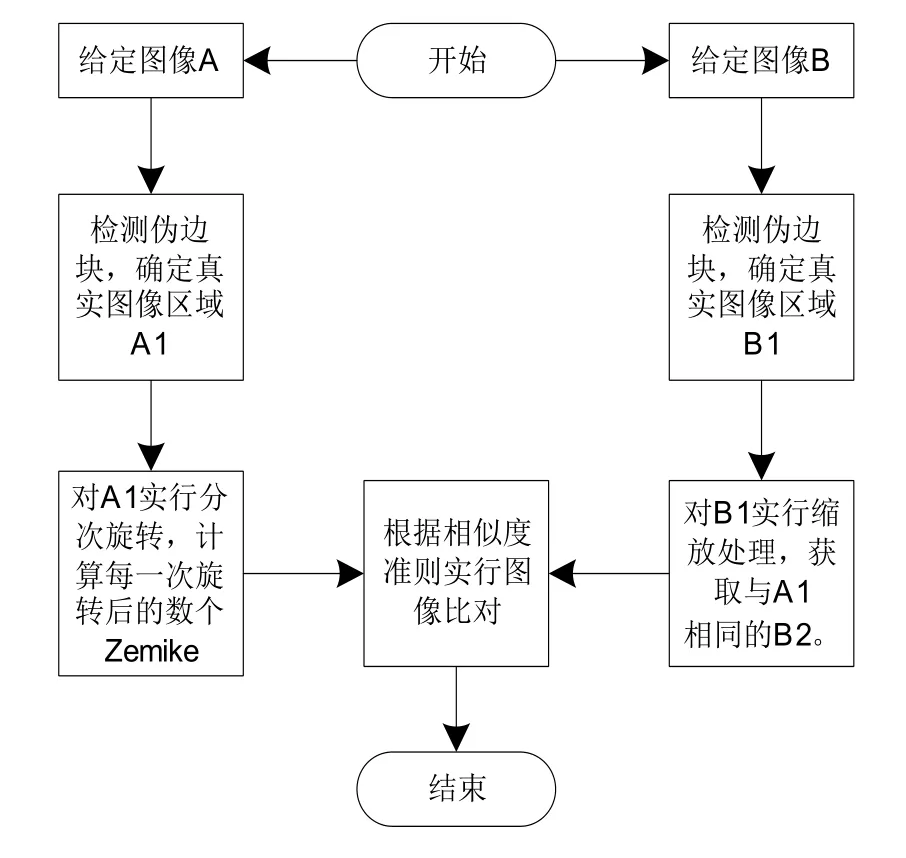
图2 算法比对流程
2.真实图像区域大小的确定。由于图像旋转后四周会出现伪边块,通常情况下伪边块的区域呈现黑色、白色或者是其他的单一灰度区域[7]。为了解决伪边块对Zernike矩值造成的影响,需对所有伪边块实行区分。对图像靠近四条边沿位置的像素值进行扫描后,统计像素值的出现概率。如果某个像素值出现比例较大,判断该像素值在旋转后形成伪边块像素值,将该像素值的临近四条边沿的连通图像区域判断为伪边块。为确定真实图像的实际大小,从而保障后续的图像大小归一化,则处理步骤如下:
(1)为将图像转化为黑白图像,根据图像像素值采取二值化方式完成图像处理。伪边块区域作为单独一类,其余区域归为另一类,均判断为真实图像。
(2)对二值化后的黑白图像实行边缘检测以及其中存在的直线进行检测,将图像中相交后可构成矩形的四条直线看作真实图像的边界。
(3)确定由四条直线相交构成的矩形,将其看作为真实图像区域,并依据四个直线交点坐标,确定真实图像大小。
3.归一化相似度准则。真实图像之间的相似程度通过相似度准则进行衡量,其取值范围在[0,1]之间。当Zernike矩的阶数较高时,计算结果与较低阶的矩值存在很大差别,甚至存在数个数量级的差别。为保证每一个Zernike矩阵作用的统一和均衡,对VB实行归一化处理,获取,其中:

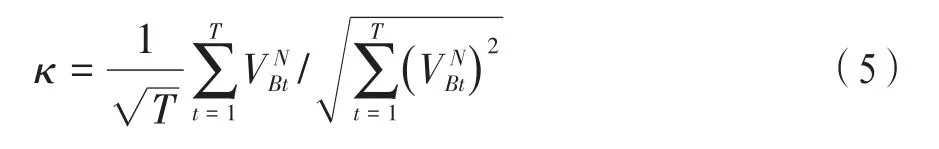
如果获取的相似度κ值大于设定的阈值,则表示两幅图像的内容相同,反之,则不相同。根据相似结果判断图像重复情况,完成图像查重。对和VB的相似度进行计算,如果已经经过归一化处理,并且成为一个全1向量,则两幅图像相似度为:
二、仿真测试结果与分析
选取某图像库作为研究对象,展开相关测试分析。该图像库共有图像数量82000张,重复图像共10087张。其中主要分为风景类图像14600张,重复图像4220张;建筑类图像12800,人物类图像3020张;文字文本类图像18400张,重复图像1120张;动物类图像11200,重复图像728张;玩具类图像25000张,重复图像999张。
(一)分类性能测试。测试本文算法的图像分类性能,从节点数量对图像识别时间的影响和图像分类精度两个方面完成测试,测试结果如表1、表2所示。分析表1可知:本文算法进行图像识别过程中,如果云计算平台上只有2个节点时,玩具类图像数据交换所需时间较长,该现象表明针对图像识别,两台计算机所需时间较大程度大于1台计算机识别所需时间。当节点数量为3个以上时,随着节点数量的增加,处理相同数量图像所需的时间逐渐减少。该测试结果表明,节点数量的增加,会增加图像分类的速度,可根据需要分类的图像数量,选择适合的节点数量。
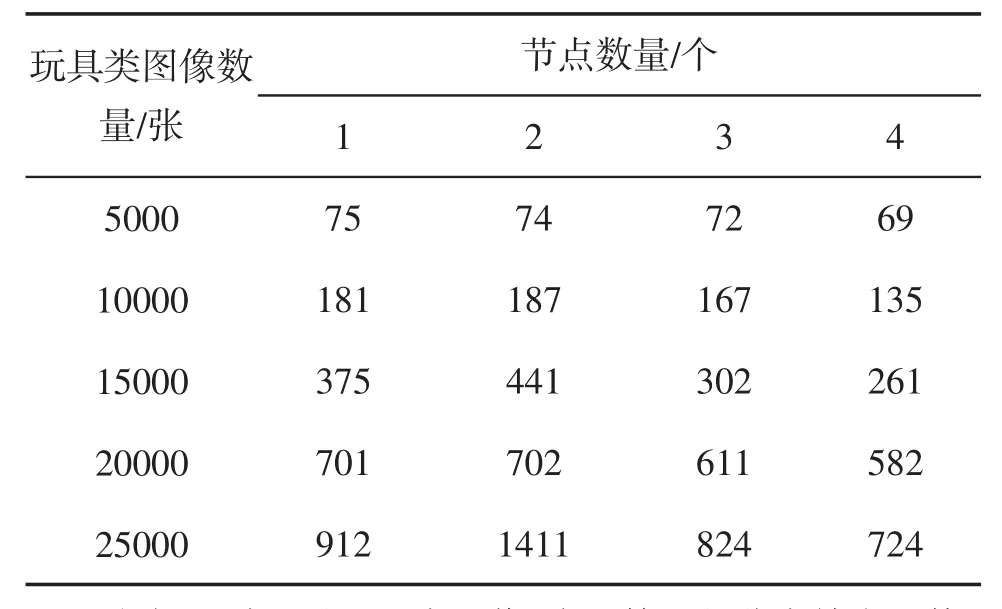
表1 不同节点数量下图像识别时间/ms
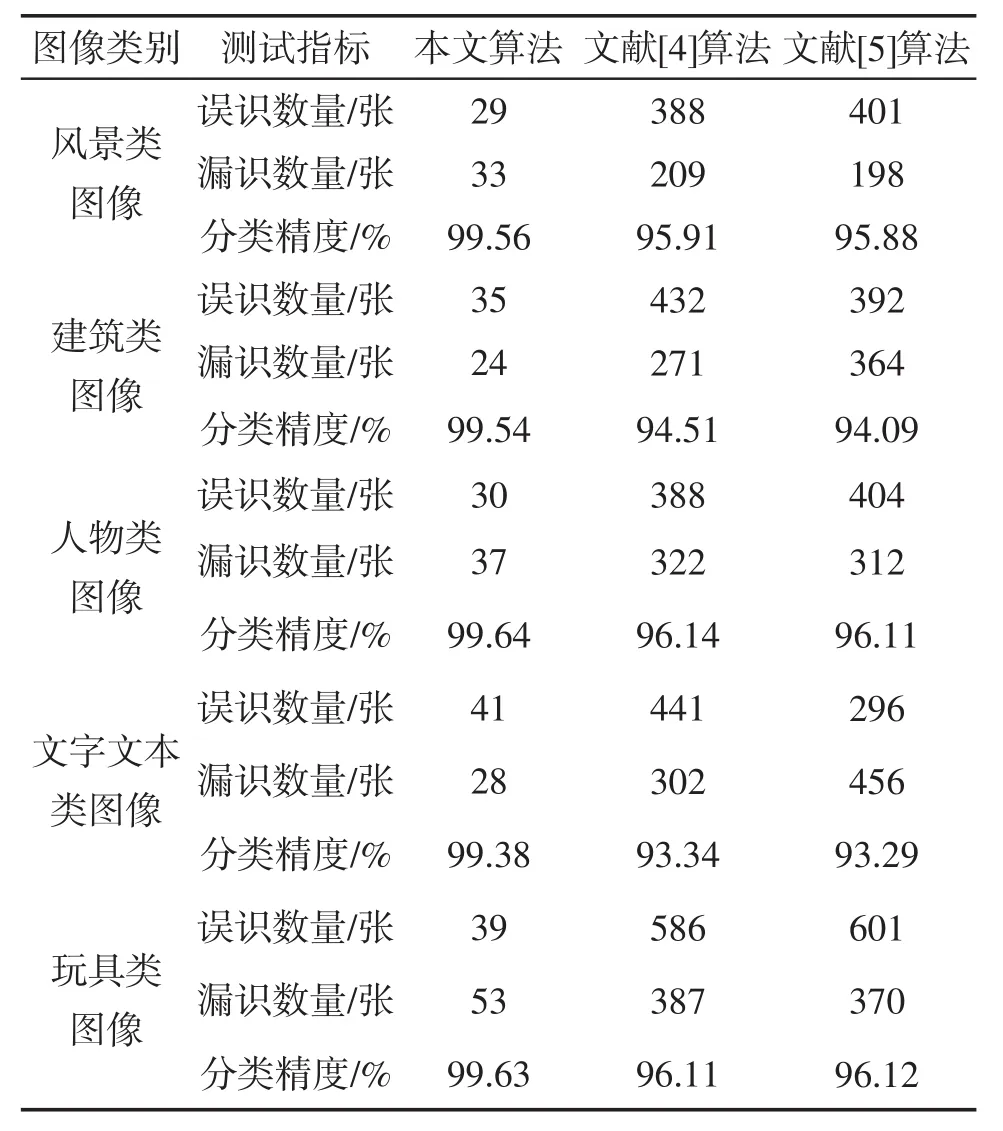
表2 三种算法的分类精度对比
从表2可知:对于五类图像,本文算法的分类精度最佳,分类精度均在99%以上对比算法的漏识和误识数量高于本文算法,它的分类精度低,这主要是因为本文算法采用云计算技术从通过分布式文件系统中获取海量图像数据源,通过数据集群配置划分处理数据,保证图像分类结果的精度。
(二)查重性能测试。为进一步测试本文算法查重性能,随机抽取人物类图像的一组图像,如图3所示。其中(a)图为原始给定图像,经其缩放60%后,进行逆时针旋转,得出(b)图,此时两幅图像内容相同,但是数据本身存在较大差别。选取4阶Zernike矩(共包含9个Zernike矩值),对(a)图进行旋转,每次旋转角度为20°,获取(a)图的Zernike矩值、标准差数值和(b)图的Zernike矩值、归一化后的数值,分别如表3、表4所示。分析表3可知:表中包含图3(a)图均值以及标准差的数值,相比较均值而言,可看出标准差相对很小,说明Zernike矩在进行图像不同角度旋转时,大小保持相对稳定,表示本文算法具备较好的旋转不变性。

图3 实验使用的图像
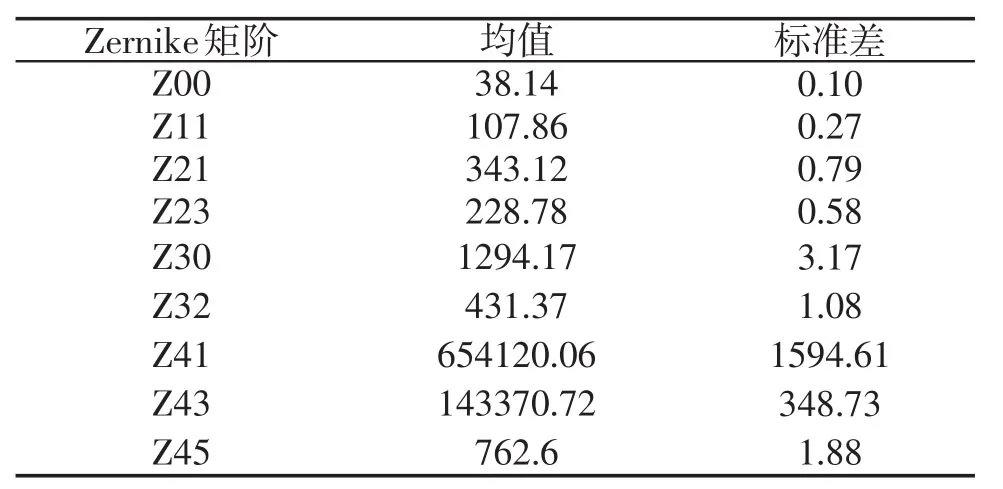
表3 (a)图的均值和标准

表4 (b)图的矩值和归一化值
分析表4可知:将获取的矩值通过公式(5)进行计算,获取相似度值。相似度值越高说明两幅图像内容相同,表明两幅图像重复。说明本文方法具备图像查重能力,可完成海量图像的查重。差
图像查重可理解为将重复图像聚集到相同的簇,因此,查重效果的衡量公式为:
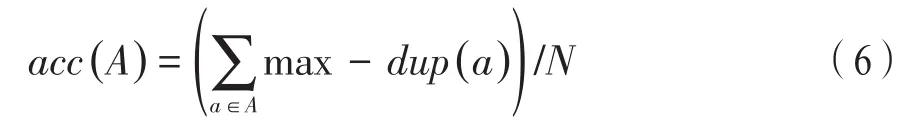
式中:A为图片重复检测的结果集合,其元素为检测到的重复图像,a中最大的真实重复图像数量为max-dup函数;如果a=[1,1,2,2,2,3,3],则max-dup(a)=3,表示2的个数为a中出现最多的元素数量,acc表示查重聚类纯度。
以人物图像数据集为例,采用三种算法对其进行相似度查询,测试三种算法在相似度阈值变化的情况下,acc的变化结果如图4所示。分析图4可知:本文算法在相似度阈值变化的情况下,acc值高于两种对比算法那,明本文算法进行图像查重的图像相似度查重效果最佳。两种对比算法的acc值相对较低,由于阈值的变化导致大量图像被错误地检测为重复。本文方法具备较好的分类性能,可将相同类别的图像划分为一个集合,极大程度降低了图像相似度检测的错误数量,保证图像相似度检测的精度。并且根据图中曲线变化,结合阈值的固定的范围可以看出,本文算法在相似度阈值为0.8~0.9范围内,acc精度最高。

图4 不同算法acc变化结果
三、结论
为了实现海量图像内容查重,设计了云计算环境下的海量图像查重算法,测试结果表明:云计算技术的节点数量对于海量图像分类存在影响,可根据图像数量适当选择合适的节点;针对五种类型图像,本文算法的分类精度高,为后续图像高精度查重奠定了可靠基础;本文算法具备较好的旋转不变性,可有效完成图像查重。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
科教新报(2021年18期)2021-06-11 13:25:24
宁波开放大学学报(2020年4期)2021-01-06 09:06:52
当代陕西(2019年14期)2019-08-26 09:42:00
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:42
杂文月刊(2018年20期)2018-11-14 21:28:46
杂文月刊(选刊版)(2018年10期)2018-05-14 10:44:56
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
小猕猴智力画刊(2016年6期)2016-05-14 21:40:48
现代企业(2015年5期)2015-02-28 18:51:08
