
基于双通道互斥信息编码模型的问句复述识别
2021-08-31 06:10白岩洪宇朱朦朦周夏冰张民
山西大学学报(自然科学版) 2021年3期
白岩,洪宇,朱朦朦,周夏冰,张民
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
问句复述识别的核心任务是判断两两自然问句之间是否具备一致的含义,例如,例1 中的两条疑问句互为复述关系。问句复述识别有助于实现面向大规模问答集合中同质异构问题的检索和相关答案的高速获取,从而能够支撑基于知识库(比如限定域FAQ 或在线问答百科)的事实性问答系统。近期,利用神经网络模型实现问句的编码,并将两两问句的编码信息进行比照的判别策略,已成为问句复述识别的主要方法。其中,针对问句的浅层语义信息进行深度编码,是这一框架中的核心技术。文本继承这一研究思路,并侧重研究面向问句复述问题的编码方法。
[例1]<复述问句样本>
“What are some amazing or least known fact of Indian railway?”
“What are least known or some amazing fact of Indian railway?”
现有基于神经网络的问句语义编码方法,侧重利用表示学习技术提高神经元对语义的感知能力,借以为判别模型提供可靠的语义表示向量。然而,本文前期研究发现,现有编码方法往往难以辨识高迷惑性的浅层语义信息,从而无法越过伪真的语义陷阱。比如,例2 中的两条疑问句有着一致的句子成分,却因为语序的些许变换(“bad”和“good”交换位置)形成了微妙的语义差异,两者之间大范围一致的浅层语义信息极易误导现有编码模型,而不易察觉的语义差异却决定了问句之间真正的复述关系(本例为非复述问句样本)。因此,现有编码方法欠缺一种“反思”的能力。根本原因在于,其对语义编码的结果是否真正有助于复述判别,缺乏可供甄别的依据。
[例2]<非复述问句样本>
“What factors cause a good person to become bad?”
“What factors cause a bad person become good?”
针对上述问题,本文提出一种结合了“自否定机制”的双通道互斥信息编码模型,并简单地将一层全连接层作为可靠性感知器予以应用。具体地,本文利用两个可调BERT[1]编码器建立互为独立的编码通道,并将其中一个BERT 作为通用语义编码通道,另一个作为“自否定”编码通道。前者借助逼近“正解”的方式,获取问句对子的总体语义表示;后者则通过逼近“误解”的方式,获取问句对子的语义表示。最终,本文将两种表示一并输入非线性全连接层进行联合编码。上述用于逼近正解的编码通道与传统的编码方式无异,都是借助最小化判别损失进行表示学习的模型。相对地,逼近误解的编码通道则有着相悖的角色,其借助最大化判别损失进行表示学习。目的是提取问句对子中最易于导致误判的信息进行特征表示,形成自我否定的学习模式,从而刚性地产出可供模型进行“反思”的依据。在编码过程中,连接于双通道BERT 之后的全连接层,用于权衡不同通道给出的浅层语义信息,借助最小化判别损失的过程,训练自身甄别可靠语义信息的能力。
本文利用上述编码方法与多层感知机(MLP)构建问句复述识别器,并在国际通用语料集QQP[2]上对其进行测试。实验结果显示,相较于单通道BERT 编码方法,本文方法产生了3.39%(ACC 测度)的性能提升,且与现有国际前沿技术相比,获得了较高竞争力水平的总体性能。本文组织结构如下,第1 节简要回顾目前的主流问句复述技术;第2、3、4 节详细介绍基于双通道互斥信息编码的问句复述识别方法和模型的训练过程;第5 节给出实验结果和相应分析;第6 节总结全文。本文实验所涉及的所有源码和技术报告,将对外自由共享。
1 相关工作
问句复述识别是自然语言处理领域中非常核心的任务,该任务简单直观的衡量了模型对于语义的理解程度。目前在QQP 这一数据集上处理方法分为两类。一类是以BERT 为代表的大规模预训练模型,这类模型通过大规模的无监督或半监督方式训练,得到一个充分的语义表示,从而使得模型在整体语义表达中更准确;另外一类则是以DIIN[3]为代表的交互式匹配模型,通过复杂的模型结构和密集的交互操作,关注每个词与其他词的匹配关系,让模型捕获更多深层交互信息,同时使用BiL⁃STM 再从整体上融合交互信息。模型大多需要辅助更多粒度的输入信息帮助提升性能,例如DIIN模型的词向量融合了词级别、字符级别、句法级别的信息,这使得模型的参数规模变得非常大。下面我们列举了近些年较为典型和热门的模型。
·ABCNN:将注意力机制引入到卷积神经网络中是ABCNN 模型[4]提出的主要创新点,使用共享权重的神经网络结构对句对分别编码。这类方法的优点在于共享权重网络有效的减少了网络参数规模,更便于训练。但是在语义匹配的粒度上较粗,对于单词级别的深度交互信息利用的很少。
·BiMPM:相比于ABCNN,BiMPM 模型将每个输入语句自身先进行单词级别的匹配,然后将匹配结果经过神经网络编码。编码后的句对将进行交互匹配,获得两个句子之间的匹配特征。他从多个角度进行匹配,解决了交互不充分的问题。
·ESIM:与BiMPM 模型一样,ESIM 模型[5]也是匹配任务中常用的模型。该模型将注意力机制加入到了BiLSTM 中,同时捕捉局部的匹配特征与全局匹配特征,在短文本匹配任务上性能较好,同时训练速度更快。
·DIIN:密集交互推理网络(DIIN)通过使用更密集的注意力交互矩阵来获取更丰富的语义匹配信息。同时,在输入编码层,将输入数据扩展到单词级、字符级别以及句法级别的特征,将其拼接后作为每个词的编码。其优点在于能够考虑到不同粒度的编码信息,同时通过深度的交互操作获取更加丰富的语义特征。
从这些典型的模型设计中,我们可以发现他们将注意力放在了如何获取更多的特征来辅助判断。而我们的模型则不同,我们利用简单模型抽取语义特征,但是利用模型的自否定机制来对抗单一模型,让模型在判断时考虑到反面被单一模型忽略的信息,并做出更明智的选择。这一方式让模型在逻辑层面上具备了“自我反思”的能力,不是一味的提升模型的复杂性,转而让模型利用已有的信息,站在多角度综合考虑做出判断。实验表明,我们的方法能够提升问句复述识别的准确性,接近目前模型在QQP 数据集上的最优性能。同时,在更加复杂的PAWS 数据集上,也达到了最佳性能。
2 基于BERT 的双通道互斥编码模型
本文的核心问题是形成具有“自否定”能力的问句语义编码模型,并能保证“自否定”过程并不干扰正常的语义表示学习和感知过程。因此,本文采用了双通道编码框架,并在每个通道中设置唯一的可调BERT 编码器进行独立编码和表示学习。图1显示了该模型的整体架构,其中,BERTα所在的通道以最小化判别损失为表示学习目标;相对地,BERTβ所在的通道则有着不同的角色,其目标是促使BERTβ“学习如何犯错”,即最小化相对于错误解的判别损失。为了在下文中方便读者区分两者,本文将BERTα称为自信语义编码器,而BERTβ为“自否定”语义编码器。
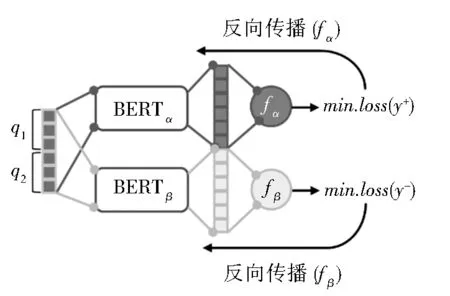
图1 双通道独立编码架构和互斥损失计算Fig. 1 Double-channel independent encoding framework as well as mutual exclusion loss computation
具体地,给定一对有待判定复述关系(复述或非复述)的疑问句q1和q2,本文将两者的词项序列进行拼接,形成输入表示Q:Q=[CLS,q1,SEP,q2,SEP]。其中,q1和q2皆为长度为128(词项个数)的词项序列(Token sequence)。本文利用Transform⁃ers 集成包中的分词工具①https://github.com/huggingface/transformers实现词项序列的获取,且约定在任意疑问句的实际长度低于128 的情况下,利用[PAD]标记进行序列补全,而在长度高于128的情况下,从问句的尾部进行节略。
针对任意的输入表示Q,本文分别采用自信编码 器BERTα和 自 否 定 编 码 器BERTβ进 行 语 义 编码,分别获得128×768 维的分布式编码状态:xα=BERTα(Q)和xβ=BERTβ(Q)(xα∈ℝ128×768且xβ∈ℝ128×768)。在此基础上,本文在两个编码器之后,分别连接一组多层(中间层为1 层)感知机,以此形成二元分类的复述判别模型。判别模型的计算方法如下:
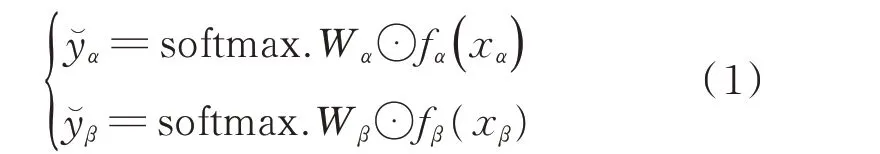
其中,Wα∈ℝ768和Wβ∈ℝ768为可调参数,softmax 为归一化指数函数。fα和fβ皆为非线性变换函数(感知机的中间层),且都拥有独立的变换参数w和b(w∈ℝ768128,b∈ℝ768),即fα(xα)=wαxα+bα;fβ(xβ)=wβxβ+bβ。此外,y̆α和y̆β表示复述 判别的概率化预测结果,其越趋近于1,则表示疑问句互为复述的或然率越高。
在训练过程中,自信编码器BERTα和自否定编码器BERTβ所在的通道将进行截然不同的反向求参(即Loss 反向传播,Back Propagation),其差异仅在于驱动反向学习的损失计量方法互为不同。前者侧重最小化相对于正解“y+”的损失,后者则着力最小化相对于误解“y-”的损失。正解和误解是相对于标准复述关系标记(Ground-truth Tag)的正反两面的标量。比如,给定的一对疑问句,且假设两者确实具有复述关系(即互为复述),则“y+”等于1(表征正解为复述关系),同时“y-”等于0(表征误解为非复述关系);相反,如果给定的疑问句之间并未具备复述关系,则“y+”等于0(表征正解为非复述关系),同时“y-”等于1(表征误解为复述关系)。由此,上述两个通道形成了如下互为排斥的表示学习过程:
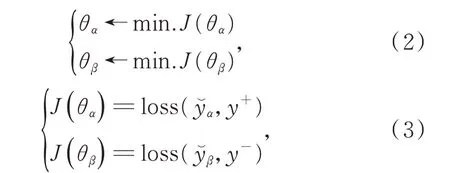
其 中,θα表 示 自 信 编 码 器BERTα通 道 的 全 部 参 数,包括wα,bα,Wα(即fα(xα)中的参数)和BERTα的参数;θβ则表示BERTβ通道的全部参数,包括wβ,bβ,Wβ(即fβ(xβ)中 的 参 数)和BERTβ的 参 数。此 外,“←min.J(θ)”表示借助最小化损失函数J(θ)反向求参的过程,损失函数的计算方法将在第3 节给出详细解释。
3 利用互斥编码信息的复述识别模型
本文利用双通道互斥编码模型,形成自信语义编码信息xα和自否定语义编码信息xβ,并将两者进行拼接,形成整体的编码表示X:X=[xα,xβ]。在此基础上,本文将X输入一套独立的多层感知机,借此进行问句复述“是与否”的二元判定,其计算方法如下:
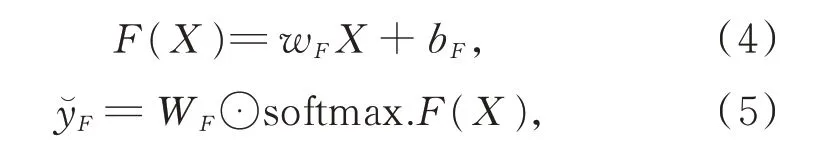
其中,F(X)为非线性变换函数(感知机的中间层),WF∈ℝ768,wF∈ℝ768×1536和bF∈ℝ768表示感知机中的可调参数,y̆F表示借助F(X)和变换参数WF计算所得的预测结果(y̆F越趋近于1,则表示疑问句互为复述的或然率越高)。
值得说明的是,上述感知机是独立于双通道互斥编码之外的最终二元判别器,无论是训练阶段或是测试阶段,其纳入的信息皆为饱和训练后的编码通道的输出,即fα(xα)和fβ(xβ)的输出。图2 给出了双通道互斥编码模型和感知机F之间的计算逻辑,从神经网络的结构层面而言,感知机F直接拼接在两个编码通道之后,仅仅利用双通道的编码输出作为其自身的输入,但其表示学习过程(反向求参)并不影响双通道编码模型自身的表示学习过程。关于训练过程的操作细节将在下一节进行介绍。
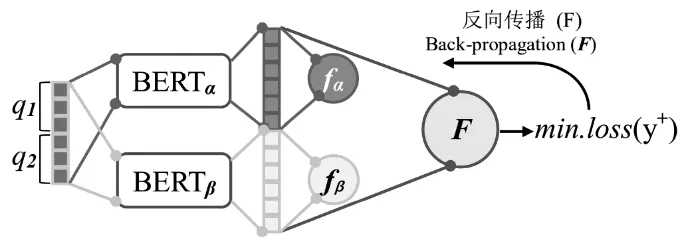
图2 综合自信语义编码和自否定语义编码的联合表示学习Fig. 2 Joint representation learning by coupling self-confi⁃dence and self-disavowing semantic encoding
此外,线性变换函数F(X)表示学习过程以逼近正解作为训练目标,反向求参的计算将采用最小化正解判别损失的方式予以进行,其计算公式如下所示(其中θF表征感知机中的所有参数,包括wF,bF和WF):
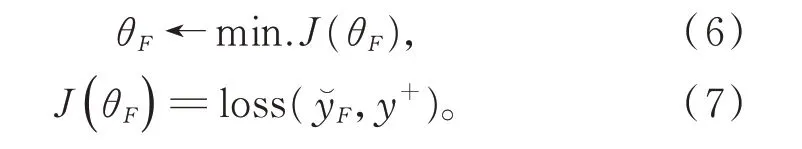
4 训练过程及损失计算
问句复述识别的整体架构包含两个预训练模型BERTα和BERTβ,以及三个多层感知机的中间层fα(xα)、fβ(xβ)和F(X)。其中,BERTα与fα(xα)共同组成了自信语义编码通道,BERTβ与fβ(xβ)组成了自否定语义编码通道,而F(X)是凌驾于双通道之上的判别模型。值得留意的是,fα(xα)、fβ(xβ)与F(X)具有相同的计算逻辑,都能与感知机的输出层形成复述判别功能,三者的区别仅限于训练和测试阶段的角色。下面对上述模型在训练和测试过程中的应用方法给予解释:
①自信语义编码通道将被实施独立训练,期间fα(xα)给出的语义表示将参与二元复述判别,用以支持复述判别损失的计算和反向参数学习(如公式1、2 和3)。同理,自否定语义编码通道也将进行独立训练,fβ(xβ)的角色等同于fα(xα),皆为支持复述判别和编码通道内所有参数的求解。
②在 测 试 阶 段,fα(xα)和fβ(xβ)形 成 的 语 义 编码,将不再借助感知机的输出层形成二元复述判别的预测结果。相对地,两者给出的语义编码将被作为F(X)的输入,并由F(X)所在的感知机进行最终的复述识别。
③F(X)所在的感知机需要独立训练,其前提是双通道编码模型(含BERTα、BERTβ、fα(xα)和fβ(xβ))都已得到完备训练,并能通过fα(xα)和fβ(xβ)的自信语义编码和自否定语义编码建立综合的表示X。在这一训练过程中,反向求参的对象仅仅涉及F(X)感知机内的参数(即WF、wF和bF)。
上述训练过程涉及的复述判别损失,皆采用py⁃torch 官方库提供的交叉熵求解方法进行计算,如下所示:
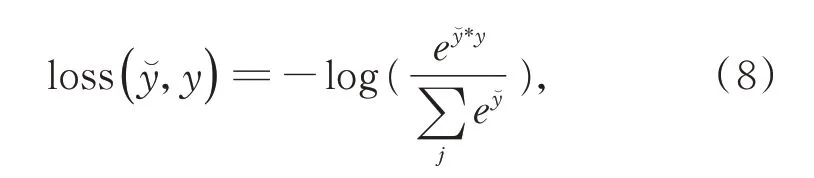
5 实验与分析
5.1 数据集与评价方法
本 文 实 验 在QQP 和PAWS[6]两 个 数 据 集 上 进行。QQP 数据集是从Quora 网站上获取的真实用户问题,非常贴近实际语言习惯。这一数据集是目前国际通用的问题复述识别数据集。PAWS 数据集是Google 于2019 年提出的一套增强难度的QQP数据集,其在QQP 原有数据的基础上补充了11 988条具有高迷惑性的问句复述样本。数据分析显示,尽管现有模型在QQP 已取得较高性能,但当特定样本体现语义异同的关键文字差异较小时,现有模型往往无法准确地感知复述和非复述关系。PAWS数据集增加了这类样本,包括交换单词位置形成的迷惑性复述样本,以及修改大量单词但维持语义不变的迷惑性非复述样本。
为了与前人工作进行对比,本文采用了通用的训练集和测试集划分方法,对QQP 按照9:1 的比例进行数据集划分(90%的训练样本;10%的测试样本),而对PAWS 则遵从了官方的划分方法。本文提出的模型并未进行开发和超参微调,因此并未进行开发集划分。训练集和测试集的样本数统计如表1 和2 所示。
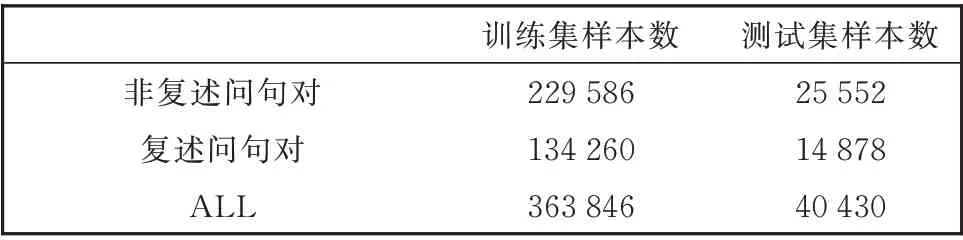
表1 QQP 数据集的样本统计Table 1 Statistics in QQP dataset
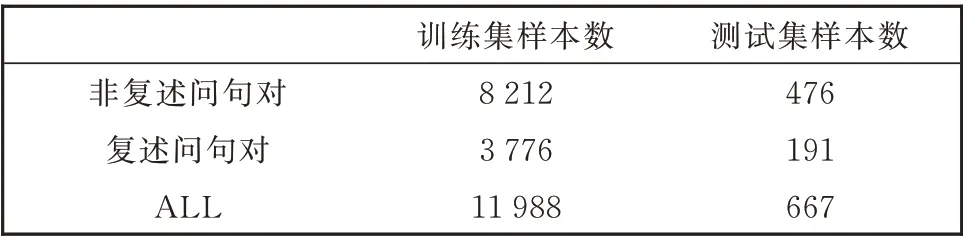
表2 PAWS 数据集的样本统计Table 2 Statistics in PAWS dataset
实验采用精度(Accuracy,简写为ACC)和ROC曲线[7]的区域性能累积值(Area Under Curve,简写为AUC)进行评测。其中,ROC 曲线记录了所有单位数量样本中(N组且M个/组)复述样本被正确预测的比例(y轴),以及非复述被错误预测为复述的比例(x轴)。由此,ROC 曲线愈加趋近于坐标平面的左上角,则表示系统的性能越好。ROC 曲线与x轴之间的面积即为AUC 数值,其有助于量化性能对比。相比于ACC 这一全局精度评估策略,ROC及AUC 更适于检验PAWS 数据集上的系统性能,原因在于其能够精细地体现迷惑性样本(含迷惑性复述和非复述样本)对系统性能产生的影响。
5.2 超参设置与训练环境
互斥信息编码器选用了基础版BERT 编码器[8],其编码向量维度为768,由12 层Transformer结构构成。使用的BERT 预训练模型参数是BERT 官方于2020 年3 月11 日发布的版本。预训练模型参数中包含了经过预训练调整的词向量。双通道互斥信息编码层中两个BERT 编码器结构完全一致,初始预训练参数也保持一致。在训练过程中,模型的学习率设置为0.001,训练轮次为10轮,Batch 大小设置为64,输入词序列长度限制为128。实验在4 块Nvidia-GTX1080 Ti 型号的GPU上训练,平均每一轮训练需要1.5 h。
5.3 实验对照模型
为了证明我们提出的双通道互斥信息编码模型能够提升模型在问句复述识别任务中的准确性,我们还分别实现了传统的BiLSTM(双向长短期记忆网络)[9]和单一BERT 编码模型[10],并在QQP 和PAWS 数据集上做了对比实验。
·BiLSTM:双向长短期记忆网络(BiLSTM)是RNN 被用于自然语言处理任务中的重要模型,它基于LSTM,但是通过双向处理,解决了LSTM在长序列编码时忽视早期序列信息的问题,在诸多NLP 任务中提升了LSTM 模型的性能。
·BERT:BERT 模型于2018 年被提出,是不同于BiLSTM 等模型的大规模预训练模型。BERT模型仅仅使用注意力机制来对序列信息进行编码,而没有使用复杂的神经网络结构。通过Mask Learn 方法实现大规模的无监督训练,以此获得预训练词向量表示。这一模型在几乎所有的NLP 任务中都表现出了显著的性能提升。本文的模型也正是基于BERT 模型来实现。
除了上述两个典型的模型以外,针对语义匹配问题,研究人员也先后提出了几种交互匹配的神经网络模型,也取得了较好的性能评分。问句复述识别任务本质上也是语义匹配的问题,因此我们也放在本文中进行对比。这部分的对比数据来源于PAWS 论文中发布的实验结果。
5.4 实验结果与对比分析
在QQP 数据集上,我们实现了BERT 模型、BiLSTM 模 型、BiMPM 模 型[11]来 进 行 对 比 实 验。对比实验数据见表3。其中,基础版的BERT 模型在开发集上的ACC 性能达到了85.92%,我们的模型在基础版BERT 模型的基础上,使用双通道互斥信息编码模型,将ACC 性能提升到了89.31%。这与目前最好的BERT 模型在QQP 数据集上的性能90.5% 非常接近。而我们仅仅使用了基础版的BERT 预训练模型就达到了这一性能。
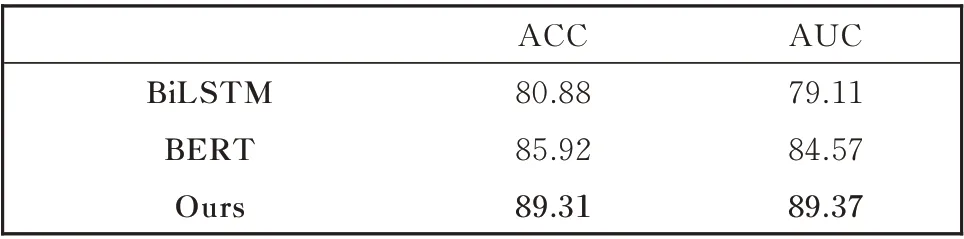
表3 QQP 数据集上模型性能对比Table 3 Performance comparison on QQP dataset
PAWS 数据集的实验在官方训练集与开发集上进行。作为QQP 数据集的升级版扩充,各个模型在未使用训练集再训练而仅仅使用QQP 数据集训练的前提下,从表4 中可以看出,各个模型的性能均大幅度下滑,我们的互斥信息编码模型的性能下降也非常巨大,但是依然和目前表现较好的模型持平。经过PAWS 训练集的训练后,BERT 模型的性能达到了80.2%,而我们的模型依然可以在此基础上提升到84.49%。
实验数据表明,本文提出的双通道互斥信息编码模型在更为复杂和具有迷惑性的PAWS 数据集上表现出了较高的正确性。此外,PAWS 数据集能够充分衡量一个模型对于语言的深层语义的表达能力,如简单的词袋模型(BOW)[12]不具备理解语义的能力,因此无论是否经过PAWS 训练集的训练都无法达到更高的准确度。而近几年提出的基于预训练的BERT 模型和基于匹配的交互模型都能够通过训练微调获得一定程度的性能提升。本文模型则在辨别这类复杂而又具有迷惑性的数据中表现得更好。自否定机制的利用让模型在使用经验判断的同时,考虑到经验所忽略的细节,从否定的角度衡量反面特征是否更具有说服力,以此达到自我纠正的目的。而这在准确性上获得了证明,这种方法有效。AUC 精度相比较于PAWS 上的最优性能83.1 提升了1%。
5.5 面向PAWS 的性能优势分析
额外地,实验使用ROC(Receiver Operating Characteristic)曲 线 与AUC(Area Under Curve)指标,二分类任务中分类器的优劣进行更为可见的分析。图3 与图4 是本文提出的“自否定机制”模型与原始BERT 模型在QQP 数据集和PAWS 数据集上的性能ROC 曲线对比图。
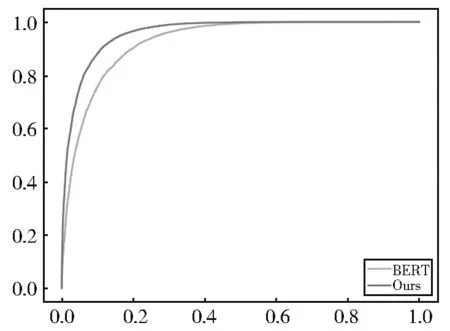
图3 模型在QQP 数据集上的ROC 曲线Fig. 3 ROC curve on QQP dataset
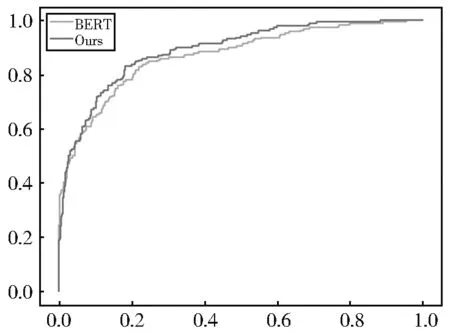
图4 模型在PAWS 数据集上的ROC 曲线Fig. 4 ROC curve on PAWS dataset
如图所示,在QQP 数据集上本文提出的模型与BERT 模型随着FPR(False positive rate)误判的比例升高,被正确判断的比例TPR(True Positive Rate)表现一致,因此在判断能力相近。但是在PAWS 数据集上,由于普遍存在的高迷惑性数据,使得BERT 模型随着FPR 比例的升高,TPR 的比例均低于本文提出的模型性能,验证了“自否定”模型相比于BERT 具有更强的辨别能力。
5.6 显著性分析
为了进一步论证本文模型性能的显著性,我们使用Johnson(1999)[13]提出的基于抽样的P值来进行检验。Johnson 提出P值的理想阈值为0.05,只有当P值小于0.05 时,我们才认为模型性能相较比较的模型性能具有显著的改善,否则认为模型性能改善不显著。此外,Dror(2018)[14]等人已经证明,P值越小,显著性越高。
本文在BERT 的基础上提出了“自否定”机制的判别模型,通过与BERT 模型进行对比,得出的P值为0.037,这说明我们的模型较BERT 模型具有明显的性能提升。
6 结 论
问句复述识别任务中,大部分数据仅仅使用浅层语义分析即可判断,但是更大挑战是深入到深层语义层面的识别问题。现有的模型往往无法捕获句子中细微的逻辑关系,仅仅停留在浅层的语义表示上。本文提出的互斥信息编码模型希望模型在捕获浅层语义信息的基础上,能够更全面的考虑语义信息,避免在面对高迷惑性数据时被定向干扰。使用自否定机制,不仅让模型能够提取出帮助判断的关键语义信息,同时也能够关注到容易导致误判的语义信息。在全面统筹信息的基础上作出判断。实验证明我们的方法对于提升模型的准确性具有很大的帮助。我们将继续探索这一方法的普适性和更优化的方案。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(中年级)(2021年12期)2021-12-30
昆明医科大学学报(2021年4期)2021-07-23
昆明医科大学学报(2021年4期)2021-07-23
就业与保障(2021年23期)2021-04-06
疯狂英语·新读写(2018年3期)2018-11-29
长江学术(2016年4期)2016-03-11
电脑爱好者(2015年22期)2015-09-10
长江学术(2015年1期)2015-02-27
电影新作(2014年2期)2014-02-27
