
一种基于改进PCFG句法分析的需求模板符合性检查优化方法
2021-08-24 03:06曹步展王立松康介祥高忠杰于梦元
小型微型计算机系统 2021年9期
曹步展,王立松,康介祥,高忠杰,王 辉,尹 伟,于梦元
1(南京航空航天大学 计算机科学与技术学院,南京 210000) 2(中国航空无线电电子研究所 软件部,上海 200233)
1 引 言
在软件工程领域中,软件需求通常采用自然语言描述.自然语言拥有易于理解,且适用于多种领域的需求描述等优点.但与此同时,自然语言在运用过程中可能会带有歧义,导致难以自动分析等问题.因此,软件需求的描述可能存在二义性、不完整性等特点[1].需求工程(Requirement Engineering,RE)是软件开发的基础[2].在需求工程中,使用需求模板对自然语言需求进行规范化,则能够尽可能地减少歧义.需求模板是对需求的一种规范描述[3],是减少自然语言需求中二义性的一种有效工具[4].它能够使自然语言需求更加易于自动分析,因此被广泛应用于航空电子、汽车工业、核工业等安全关键领域中.同时,需求模板符合性检查是自然语言处理在需求领域的重要研究方向.传统的手工检查不仅耗时耗力,而且当需求发生变化时,还需要反复进行符合性检查,因此效率较为低下.针对这一问题,许多学者展开了研究,并提出了一些基于组块分析的需求模板符合性自动检查方法[5-8].这些方法大大提高了需求模板符合性检查的效率.图1展示了常用的需求模板之一,Rupp模板[9].除此之外,还有EARS模板[10].
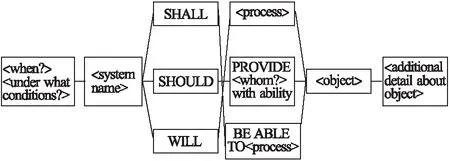
图1 Rupp模板[9]
在需求模板符合性检查方法中,最重要的是组块分析,分为名词组块分析和动词组块分析[5-8].现有方法是只根据分词和词性标注的结果,按照一定的规则将几个连续的单词序列组合成名词组块或者动词组块.与完整的句法分析相比,组块分析有复杂性低、可扩展性好、健壮性好等优势,并且句法分析不能保证生成一棵句法分析树.然而,仅仅通过组块分析并不能最终准确地提取出最佳的名词短语或动词短语,因此书写需求的工作者需要避免使用过于复杂的名词短语.然而,在部分场合中为了将需求的参与者或者对象描述清楚,不得不使用较为复杂的名词短语.现有的很多方法[5-8]仅使用组块分析,并未采用句法分析树,因此只能找到组成复杂短语的原子短语,而不能揭示需求语句的完整语义,无法识别复杂的短语,进而导致难以提取最佳的组块.
针对以上问题,本文提出一种基于改进PCFG句法分析的需求模板符合性检查方法,对需求进行句法分析,然后提取解析器得到的所有名词组块.根据词性、名词组块以及动词组块,提取出需求中所有的建模元素,通过建模元素判断需求是否符合模板.这种基于改进PCFG句法分析的需求模板符合性检查方法,考虑了结构之间的依存关系、词汇对句法结构的影响以及上下文间单词词性的相互影响,具有较高的准确率.
2 PCFG4TCC方法
本节介绍一种基于改进PCFG句法分析的需求模板符合性检查方法——PCFG4TCC方法.该方法主要用到了自然语言处理的关键技术之一,即句法分析.作为自然语言处理的一个关键环节,句法分析的主要任务是确定句子的句法结构或句子中词汇之间的依存关系.句法分析分为句法结构分析和依存关系分析.句法结构分析又称为句法成分分析或短语结构分析.获取整个句子的句法结构称为完全句法分析或完全短语结构分析.获得局部成分的句法分析称为局部分析或浅层分析.依存关系分析又称为依存句法分析或依存结构分析,简称依存分析.
2.1 组块分析
组块分析是一项核心的NLP技术,是局部句法分析的一个重要任务.简而言之,组块分析是将句子划分为几个不重叠的片段的过程.组块分析最重要的部分是名词组块分析和动词组块分析,即提取出句子中的名词短语和动词短语.名词短语是动词的主语或宾语.动词短语(VP)有时也被称为动词词组,是一个包含动词、情态动词、助词和修饰语(通常是副词)的片段.组块具有扁平结构,而由自然语言处理解析器(如Stanford Parser[11])产生的片段可以有任意深度.
组块分析比起句法分析有两个主要的优势:计算成本较低,计算复杂度为O(n),其中n表示句子的长度,而相比之下,句法分析的复杂度为O(n3);其次,组块分析必然会产生输出结果,而句法分析无法保证产生语法解析树,由此可见组块分析方法拥有较好的鲁棒性.
组块分析的具体步骤如下.
1)分词.通过分词,将需求文档分割成若干个单词和数字,并标注上Token的标签.Token可以是单词、数字或者符号.
2)进行分句,将需求文档划分为若干个句子,并标注上Sentence的标签.
3)进行词性标注,对句子中的每个单词和数字按照其词性进行分类,在Token标签上加上词性(名词、动词或者形容词等).词性标注一般使用Penn Treebank标注集.
4)进行组块分析,组块分析主要可分为名词组块分析和动词组块分析.使用RETA Chunker和OpenNLP Chunker进行名词组块分析,即提取出名词短语,并将名词短语标注上NP的标签.使用ANNIE Chunker进行动词组块分析,即提取出动词短语,并将动词短语标注上VP的标签.名词短语和动词短语也称作名词组块和动词组块.组块分析部分的流程如图2所示.

图2 组块分析流程图
2.2 基于PCFG的句法分析方法
2.2.1 PCFG文法
PCFG文法是基于概率的上下文无关文法,被认为是统计和规则方法的结合.PCFG文法可以表示为一个五元组G=
1)X是终结符集.
2)V是非终结符集.
3)S是文法的开始符号,S∈V.
4)R是有序偶对(α,β)的集合,即产生的规则集.
5)P是每个产生规则的统计概率.
2.2.2 Viterbi算法
Viterbi算法是一种利用动态规划思想计算所有句法分析树中的最大概率的方法.Viterbi算法可以描述为如下形式:
Step 1.初始化:
Yii(A)=P(A→wi),1≤i≤n
(1)
Step 2.归纳计算:j=1…n,i=1…n-j,重复如下计算:
(2)
(3)
其中,N为PCFG文法G(S)的非终结符集.
Step 3.终结:
(4)
2.2.3 使用改进的Viterbi算法进行句法分析
在3.1节的名词组块分析中,只是提取了自然语言需求中的原子名词短语,无法识别复杂的短语,这影响了需求模板符合性检查的效果.所以,在这一节引入了改进的Viterbi算法对自然语言需求进行完全句法分析,提取出自然语言需求的复杂名词短语.
根据模板,使用改进的Viterbi算法,进行句法分析.改进的Viterbi算法使用PCFG方法,给定上下文无关文法G,以及句子S,通过将树上每一个结点生成其分支结点的概率相乘,计算句法分析树的概率P(T|S,G).若一个句子有多棵句法分析树,可以根据概率值对所有的句法分析树进行排序.PCFG可以使用句法排歧,面对多个分析结果选择概率最大的分析树作为句法分析的结果,即argmaxTP(T|S,G).如图3所示,使用Viterbi算法进行句法分析能够对需求语句生成一棵最优的句法分析树.然后,检索句法分析树上的每个节点SyntaxTreeNode,提取其中cat属性为NP的部分,即为名词组块,同样标注上NP的标签.使用appelt控制选项(第3行),可以确保再同一文本区域中检测到多个名词组块时,只标记长度最长的一个.使用3.1节与本节的这些标签来进行需求模板符合性检查.提取句法分析树上父节点为NP的Token序列伪代码如下:
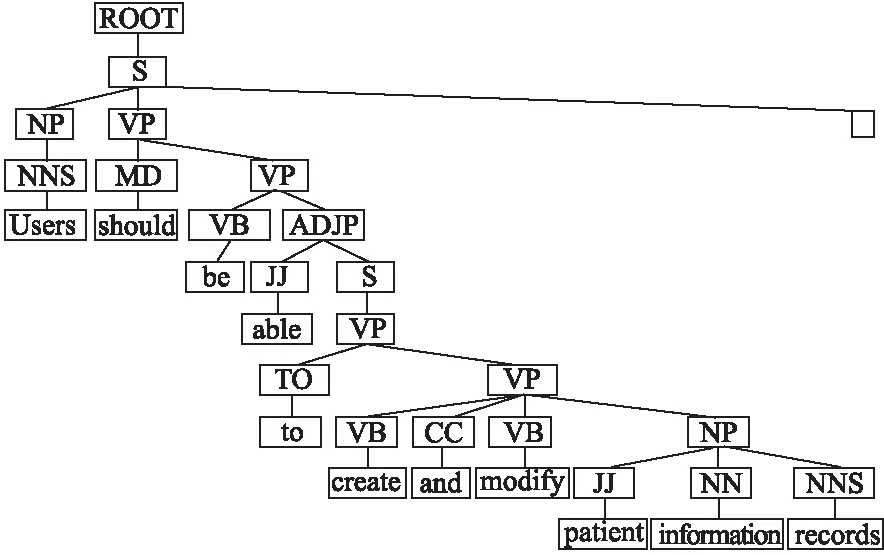
图3 句法分析树
输入:句法分析树SyntaxTree
输出:名词组块集合NPs
1. for each SyntaxTreeNode in SyntaxTree
2. if SyntaxTreeNode.cat==NP
3. NPs.add(SyntaxTreeNode)
4. end if
5. End for
6. Return NPs
2.3 模板定义
根据Rupp模板,给出Rupp模板的BNF语法,如表1所示.其中,,即<细节>,表示对象的详细信息,从对象之后到句子末尾的单词序列(不包含对象).Rupp模板的语法模式可以表示为,即<条件><名词短语><情态动词短语><名词短语><细节>.
2.4 模板检查
根据表1中Rupp模板的BNF范式,进行需求模板符合性检查的流程如图4所示.

表1 Rupp模板的BNF语法
对于图4流程的每一步,其具体步骤如下:
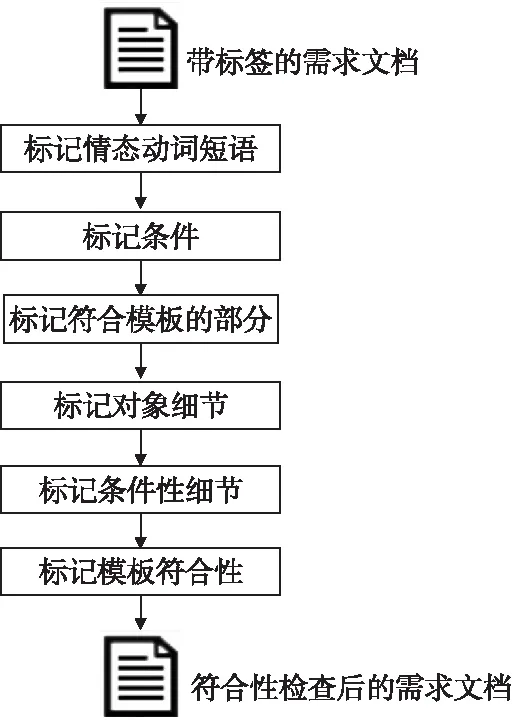
图4 需求模板符合性检查的流程
Step 1.标记以情态动词shall、should、will、can、could开头的动词短语Modal_VP.
Step 2.标记以条件关键字if、after、before、as soon as、when、while、in case开头的有效句子中的条件Condition.
Step 3.将句首或条件Condition之后的名词短语NP标记为System_Name;将System_Name之后的不包含”provide”的情态动词短语标记为过程process;将process之后的NP标记为对象object;将这3部分以及条件Condition(即符合性片段)标记为Conformant_Segment.
Step 4.从Conformant_Segment末尾到句子Sentence的末尾标记为细节Details.
Step 5.将包含条件关键词的细节Details标记为条件性细节Conditional_Details.
Step 6.扫描所有需求,若其包含符合性片段Conformant_Segment,且不包含条件性细节Conditional_Details,则将其标记为符合模板templateConformance.否则,将其标记为不符合模板templateNonConformance
3 实验及分析
本节以“战术控制系统(Tactical Control System,TCS)”领域[12,13]以及“业务项目管理工具(Business Project Management Tool,BLIT)”领域[14]的需求描述为例,针对上述的领域需求模板,对两个领域的需求进行检查,并自动判断其是否符合模板.实验分为两部分,第1部分是组块分析,包括分词、分句、语法树分析、词性标注、名词组块分析以及动词组块分析,得到5715个单词及其词性,245个句子,10283个语法树节点,3306个名词短语以及671个动词短语;第2部分是需求模板一致性检查,通过语法模式匹配,识别出模板中所需的建模元素,包括8个条件、402个系统名、148个过程、148个对象以及146个细节,其中条件和细节是可选的元素,其余元素均为必要元素,根据这些建模元素以及位置关系判断该需求是否符合模板.本文的实验是在GATE系统中进行的,GATE系统主界面如图5所示.

图5 GATE系统主界面
为了验证本文方法改进的效果,分别在在TCS数据集、BLIT数据集上进行了对比试验,数据集分别有202、45条需求.根据3种方法得到的模板一致性检查结果,以精度、召回率以及F2度量作为评价指标进行对比.
精度(Precision)、召回率(Recall)和F2度量是评估模板一致性检查的效果的一项重要指标,定义如下:
假设符合模板为反例(N),不符合模板为正例(P).
真正(TP)表示实际为正例(P),系统标注为正例(P);真反(FN)表示实际为正例(P),系统中标注为反例(N);假正(FP)表示实际为反例(N),系统中标注为正例(P).
精度(Precision)表示抽取出来的所有正例中,实际也为正例的比例,即:
(5)
召回率(Recall)表示实际为正例的所有样本中,抽取出来的正例比例,即:
(6)
根据公式(5)、公式(6)得到的精度(Precision)、召回率(Recall),根据公式(7)计算F2度量(F2-measure),作为评估实验的最终标准,F2度量的计算公式如下:
(7)
实验结果如表2所示.

表2 3种方法对比结果
分析实验结果,可以发现,在TCS数据集中,PCFG4TCC方法在精度上略优于其他两种方法,召回率略低于其他两种方法,F2度量与其他两种方法持平.而在BLIT数据集中,PCFG4TCC方法在精度、召回率、F2度量上比原有方法均有所提升,分别达到了0.93,1和0.98.
4 总 结
本文提出一种基于改进PCFG句法分析的需求模板符合性检查优化方法,通过PCFG句法分析,提取出最佳的名词组块,进而得到需求模板符合性检查的最优建模元素,提高精度、召回率,从而达到提高F2度量的效果.通过实验将PCFG4TCC方法与RETA Chunker方法、OpenNLP Chunker方法进行比较,结果表明PCFG4TCC方法在精度、召回率方面均略有提高.本文方法仍有不足之处,未来考虑进一步提高其精度、召回率,并应用到更多更广的需求中去.
猜你喜欢
建材发展导向(2022年20期)2022-11-03
建材发展导向(2022年12期)2022-08-19
建材发展导向(2021年20期)2021-11-20
初中生学习指导·中考版(2020年5期)2020-09-10
考试与评价·高二版(2020年2期)2020-09-10
小学生作文辅导·下旬刊(2020年5期)2020-07-23
中学课程辅导·教师通讯(2020年22期)2020-02-04
中学生英语·外语教学与研究(2017年4期)2017-04-14
小学生时代·综合版(2009年11期)2009-12-29
