
结合注意力与多尺度时空信息的行为识别算法
2021-08-24 03:06秦宇龙王永雄胡川飞
小型微型计算机系统 2021年9期
秦宇龙,王永雄,胡川飞,邵 杭
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
视频人体行为识别指的是利用计算机相关算法,对视频序列进行特征捕获、提取、分析、处理,并实现对其中的人体动作行为进行正确理解和认知[1].随着信息技术的发展,视频行为识别已被广泛地应用于安防监控、人机交互、异常行为检测、人机混合增强、自动驾驶、智能服务等领域[2].但是,相比于二维静态图像的处理和识别,识别视频中的人体动作行为不仅要利用视频序列的空间信息,还需要获取其时间信息.因此,视频行为识别在具有广阔的应用前景的同时,仍面临着模型参数量较大、时空特征提取效率较低、对视角敏感和识别精度不理想等诸多挑战[3].
当前,视频行为识别算法主要可以分为两个大类:基于手工特征提取的识别方法和基于深度学习的识别方法.传统的行为识别,需要逐帧地对视频进行手工特征提取,以获得相应的特征向量,再基于特定的分类器进行分类[4].这类方法主要包括:基于3D-Harris角点特征的行为识别[5],基于3D梯度直方图(3DHOG)特征描述子的行为识别[6],基于光流直方图(HOF)特征描述子的行为识别[7]以及改进的密集轨迹光流算法(iDT)[8]等.但是,这些传统算法在特征提取过程中的计算量较大且泛化能力较差,通常只适用于在特定、规模较小的视频数据集上完成识别任务,难以满足对大规模视频数据进行高效处理的需求.
得益于深度学习的快速发展,通过卷积层和池化层进行堆叠的卷积神经网络,已被证明具有优异的特征提取能力.在目标检测、图像分割、图像修复[9]等领域取得到了广泛的应用和显著的成果.基于深度学习的行为识别方法,在减少计算成本、提高网络泛化能力的同时,可以实现端到端的训练、测试与应用,实现对海量数据的高效处理.
根据卷积核形式的不同,基于深度学习的行为识别方法,可以分为基于2D卷积网络和基于3D卷积网络两大类别.其中,基于2D卷积网络的算法以Simonyan等人[10]提出的双流卷积网络(Two-stream CNN)为代表.该方法提出对双分支结构,分别使用RGB图像和相邻帧之间的光流图像作为两个网络分支模块的输入,以此来同时获取视频的时间信息和空间信息.网络对两部分的分类得分进行融合并得到最终的判别结果.双流结构的出现,为其后一系列的行为识别算法奠定了基础.Feichtenhofer等人[11]在双流主干网络中,结合特定的VGGNet,研究了信息融合的位置对于识别精度的影响;Wang等人[12]将Bn-Inception应用到双流结构,提出TSN算法,实现对长时间序列的视频进行建模分类;Christoph等人[13]提出横向连接的SlowFast网络,使用不同速率的视频序列作为两个分支的输入,并通过横向连接进行识别分类.基于2D卷积网络的方法,大多采用信息融合的方式,间接实现视频中时空信息的提取.但是,这样的做法会破坏视频中时空信息的完整性,同时采用手工标定的特征作为网络额外的输入信息,导致计算开销仍旧较大,极大影响算法的训练效率和应用范围.
相比于2D卷积的方法,基于3D卷积网络的方法,网络结构更加简单高效.可以直接有效地从原始视频中提取时空特征信息,而无需额外的信息融合,极大提高网络提取时空特征的效率.Ji等人[14]在传统2D卷积的基础上,引入3D卷积对时空维度进行提取,并首次将其应用在行为识别领域.Tran等人[15]通过3D卷积层、3D池化层的堆叠连接,构建了一个简单高效的网络架构C3D.该网络可直接从原始输入视频中提取时空特征,证明了3D卷积网络在时空信息提取方面的优越表现.
此后,以C3D 网络为基础的3D卷积神经网络成为主流方法之一,但其结构复杂、参数量庞大、不易于训练.针对3D卷积神经网络和人体行为多样化等问题,研究者以提高时空特征提取的效率或减少网络参数为目标,进行更深层次的探索.Tran等人[16]提出Res3D网络,将残差思想与3D卷积相结合,来解决网络中梯度消失的问题.Diba等人[17]和Carreira等人[18]从不同的层面将Inception的思想扩展到3D卷积,提出T3D和I3D网络.通过不同尺度的卷积,来捕获丰富的时空信息.但其参数量较大,易造成模型参数的大量冗余.Qiu等人[19]和Tran等人[20]结合时空分割的思想,对经典的3D卷积的结构分解为时间卷积和空间卷积.有效减少网络参数量同时,增加了卷积内部的非线性关系,提高网络提取时空特征效果.但其卷积尺寸固定不变,缺乏对不同尺度时空特征的层次结构进行分析,导致其时空感受野单一,对多样化的人体行为识别的泛化性较差.Tran等人[21]借助分组卷积,在通道维度进行研究,通过通道维度的交互,提高特征提取的效率.Yang等人[22]引入视觉速率(Visual tempo)的概念,对视频动作的速率快慢进行研究,提出TPN网络.该网络通过特征金字塔结构特性,实现多尺度特征的提取与融合,验证了多尺度的特征提取,有利于网络识别效果的提升.但是,利用金字塔结构获取多尺度信息,时间复杂度较高,网络结构较复杂,在训练优化方面有一定的难度.
为了更简洁、有效地实现视频中的行为识别目标,本文提出一种新颖的多尺度通道分离的时空卷积网络(MCST-Net)用于人体行为识别.该网络以MCST模块为基础,在特征的通道维度进行分割,特征子集通过不同分支的卷积处理后,得到不同尺度的时空特征并进行多尺度融合.MCST模块的类残差结构,在参数量有所降低的前提下,可以有效地获得多种尺度的时空感受野范围,充分地利用特征各维度的信息进行训练.这使网络在视频样本中提取丰富的时空特征,达到提高网络对视频对象理解能力的目标.同时,为了优化MCST-Net提出了一种改进的非局部注意力模块(Improved non-local attention module,INLA).该模块在Wang等人[23]提出非局部注意力模块的基础上,增加了多种尺度的池化模块进行采样操作.通过多种尺度的采样点信息,等效的代替特征图中的所有位置,在时空维度上降低特征的尺寸大小,有效解决了非局部注意力机制中的时间复杂度高和占用显存较大的问题.并建立时空特征的全局依赖关系,获取时空特征中的关键信息.本文提出的网络结构有利于解决人体行为识别中,网络泛化能力较弱、参数量大、结构复杂等问题,并在公开数据集UCF101[24]和HMDB51[25]上取得了优异的识别效果,分别达到77.4%和45.2%的识别准确率,超过目前主流的行为识别方法.
2 多尺度通道分离的时空卷积网络MCST-Net
本文提出的网络架构MCST-Net如图1所示.使用多个MCST模块(见图2)作为网络的主体卷积层,并在网络的中段加入INLA模块(见图3).该网络可以有效地提取视频中的时空特征,具有较优异的视频理解能力.
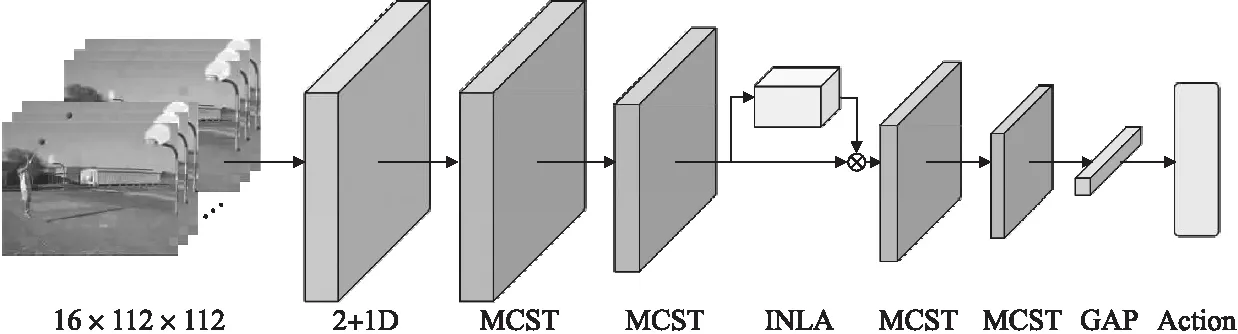
图1 MCST-Net网络架构图
2.1 多尺度通道分离的时空卷积模块MCST
提出的多尺度通道分离的时空卷积模块(MCST),是MCST-Net的主体部分,用于提高网络的视频识别能力.在多尺度时空特征提取的过程中,MCST模块没有采用并行时空金字塔的方法,而是借鉴Res2net[26]中图像特征的提取方式,通过构建层内的类残差结构,对输入特征的通道进行分割,获得多个子集依次进行卷积操作,并将各分支的输出层次化连接,实现多尺度融合.这样在不引入额外参数的条件下,依次将一组卷积的输出特征和另一组卷积的输入特征相组合,等效地扩大每个卷积的感受野范围,获得多尺度的时空特征.MCST模块充分利用了特征通道维度的信息,获得更丰富的时空特征,提高网络的行为识别效果.MCST模块的结构如图2所示.

图2 MCST模块结构图
在我们的MCST模块中,使用时空分割的2+1D卷积块,代替经典的3×3×3的3D卷积,分别处理特征的时间维度和空间维度,以此控制卷积部分的参数量.然后采用类残差的结构,将卷积块组合,等效地获取多个尺度的时空感受野.具体来讲,对于给定的输入特征X,首先经过1×1×1的卷积处理,完成特征通道维度的交互,并均匀地将输入特征X的C1个通道分割为S个子集(图1中尺度参数S=4),记为xi,其中i∈{1,2,…,S}.则每个子集的时空维度大小与输入特征相同,而通道数C′输入特征的1/S,即C′=C1/S.然后,除了x1子集外,每个特征子集xi分别经过一个类残差结构的分支,每个分支都有一组对应的2+1D卷积,记作Ri().一个特征xi经过一组2+1D卷积处理后,提取出一个尺度的时空特征yi.得到的yi通过类残差结构,与下一组输入特征xi+1相结合,一起作为下一分支中2+1D卷积Ri+1()的输入,进行处理.依次重复该过程,使每个子集都经过2+1D卷积的进行特征提取,等效地获得扩大时空感受野范围,直到获得所有分支输出的时空特征.各分支输出特征yi的获取过程,可表示为:
(1)
在分割过程中,通过层次化连接的类残差结构,重复利用不同卷积组之间的特征,有利于扩大卷积层的时空感受野范围,实现多尺度时空特征的提取,使网络获得更加丰富的视频信息.此外,在x1子集对应的分支中,MCST模块省略了卷积操作,直接对该子集特征进行重复利用,一定程度上减少了模块的参数数量.
获得各子集的时空特征yi后,将所有的时空特征连接起来,并通过1×1×1的卷积,进行信息融合.通过一个2+1D卷积块进一步处理,并与残差结构相结合,避免梯度消失等问题.最后获得MCST模块输出的时空特征,输出结果的计算如公式(2)所示:
Y=X+F([y1;y2;…;ys])
(2)
其中,X代表MCST模块的输入特征,Y代表输出特征,F()代表最后的2+1D卷积处理操作.
MCST模块通过控制尺度参数S,调整模块中时空感受野的范围.相比于固定感受野的方法,MCST模块可以学习更丰富的时空特征,参数数量也有一定的降低.
2.2 改进的非局部注意力模块INLA
注意力机制是一种权重自动配置的机制.通过学习相关特征,对输入特征的权重重新分配,提高网络对于相关特征的提取效果.Wang等人提出的非局部注意力模块(Non-local Black,NL),采用非局部均值设计,通过建立特征图中所有位置的全局依赖关系,获取特征的时空上下文关系,进而提高网络的特征提取能力.在I3D、SlowFast等网络中已经证明,NL模块可以有效地提升网络对于全局特征的表达能力,进一步提高人体行为的识别准确率.
但是,在使用3D卷积网络对视频任务进行处理的过程中,采用NL模块计算特征图中所有位置的全局依赖关系,会导致注意力机制的计算量较大,占用过多的显卡内存,降低了网络的训练效率.所以本文提出一种改进的非局部注意力模块(INLA).此模块在建立特征全局依赖关系的同时,通过采样操作,降低注意力机制的计算量,减少注意力机制占用的显存空间,使MCST-Net更加高效的完成人体行为识别任务.
INLA模块的整体结构如图3所示.与NL模块相类似,INLA模块由Value、Key和Query 3个分支组成.但在Value和Key分支中,增加了采样操作.采样的操作过程如图3中虚线框内所示.具体来讲,首先将输入的特征X∈RC×T×H×W,分别送入3个分支的1×1×1卷积,进行通道维度的重构.然后对Query分支的时空维度进行展开处理,即N=T×H×W.得到该分支的输出特征q∈RN×C,可由公式(3)表示,其中Wq()代表该分支的卷积和展开过程.

图3 INLA结构图
q=Wq(X)
(3)
而对于Value和Key分支,增加了采样处理的操作.采样过程参考了空间金字塔池化层的思想,使用多种尺度的3D自适应池化层,对输入特征进行采样处理.采样的尺度分别为[1,3,5,8],将时空特征按照4种尺度进行平均池化,以代表不同时空特征区域的注意力特征.并对输出的注意力特征,进行展开和拼接处理,则采样点总数U可通过公式(4)表示.
(4)
两个分支的输出特征为v∈RU×C和k∈RC×U,通过公式(5)、公式(6)表示,其中Wv()、Wk()代表两分支的卷积过程,S()代表各分支的采样过程.
v=S(Wv(X))
(5)
k=S(Wk(X))
(6)
将输出特征k和q相乘,并经过softmax函数进行归一化处理,得到该模块中的相似矩阵.最后与输出特征q相乘,得到INLA模块的最终输出Y,则INLA模块获得注意力权重的过程可通过公式(7)表示:
Y=v×softmax(k×q)
(7)
在NL模块中,通过计算所有位置的全局依赖关系,获得注意力权重.其时间复杂度主要来自于3个分支的矩阵乘积部分,可以记作O(CN2).而INLA模块通过计算采样点的全局依赖关系,来降低计算量.以U个采样点代替特征的所有点,则INAL的时间复杂度为O(CNU).当输入注意力模块的特征尺寸为8×28×28时,特征的位置点个数N=T×H×W=6272,远远大于采样点U=665,因此INLA模块可以有效降低模块的时间复杂度,减少模块占用的显存空间.INLA模块在保留特征的全局依赖关系的前提下,不会改变输入输出特征的尺寸,可以与多种网络结构相结合,具有一定的通用性.同时,该模块解决了非局部注意力机制中计算量较大的问题,提高MCST-Net在人体行为识别任务中的准确率和训练效率.
3 实验结果与分析
为了验证本文提出的MCST-Net在视频行为识别任务中的有效性,本文在两个主流的数据集UCF101和HMDB51进行大量的实验.所做实验基于Pytorch 3.0的深度学习框架,使用Nvidia Geforce GTX 1080 GPU硬件平台来实现.本节首先介绍本文算法中相关细节和参数设定.然后在相关数据集下,对网络的不同部分的进行消融实验,研究各部分对网络识别效果的影响.最后与目前主流识别方法的测试准确率进行比较.
3.1 实验数据集
为验证本文所提算法的有效性和普适性,我们使用两个不同类型的人体行为公开数据集UCF101和HMDB51进行实验.
UCF101数据集是人体行为识别领域最经典的数据集之一.其数据样本来源于视频网站YouTube上的各类行为动作视频,分为101个动作类别,共13320段视频.主要包括人-物交互,人-人交互,弹奏乐器等行为.UCF101数据集具有行为动作多样、背景杂乱和相机抖动等特点,使得样本内容更贴近现实动作,识别起来更具挑战性.也是行为识别领域评估网络效果时,最常使用的数据集之一.
HMDB51数据集由布朗大学发布的一个行为识别数据集.该数据集的样本主要来源于电影、YouTube和Google视频等.其中包含了51个动作类别,共6849个视频片段,每个类别至少包含101个视频样本.主要包括面部动作、一般身体动作和对象交互动作等5种类型.由于样本的来源较广、视频场景复杂、光照条件多变等因素,HMDB51是目前最具挑战性的行为识别数据集之一.
3.2 网络训练设置
预处理:首先,参考C3D、Resnet3D等文章的方式,对视频数据进行预处理.将25fps的视频样本,逐帧地分解为若干个视频段,每段包含16帧连续的RGB视频帧.在网络训练的过程中,数据扩充的方法,可以有效处理过拟合问题.所以本文在训练网络时,为了防止出现样本不足导致过拟合而影响网络泛化能力的问题,采用随机翻转和多尺度偏移随机裁剪的方法,对数据集的训练样本进行数据扩充,来增加数据样本的多样性,提高网络学习特征效果.因为有序的视频帧之间存在复杂的时空特征信息,所以在进行数据扩充时,同一视频段的16个视频帧,需采用相同的处理方式进行处理,避免破坏其时序相关性.对于训练样本,将输入尺寸的320×240像素的视频帧,按比例缩放为171×128像素大小.再进行随机裁剪,固定为112×112像素的视频段,并使用ImageNet dataset标准化系数,对输入视频段进行标准化处理,以加快网络的收敛速度.最后,按50%的概率对数据样本进行水平翻转处理.而对于验证集的样本,只进行尺寸缩放、中心裁剪和标准化处理.
参数设定和训练:本实验在相关数据集下,使用随机初始化权值的方式训练网络模型.经过预处理后,以大小为16×112×112像素的RGB视频帧作为网络输入.训练过程中,使用随机梯度下降法和交叉熵损失函数,对模型进行优化训练,动量设为0.9,权重衰减系数设为0.005.网络训练的初始学习率设为0.005,每迭代10次,学习率就减少为原来的1/10,共进行39次迭代.
3.3 网络架构
本文主要使用MCST-Net-10以及Res3D-10的网络进行实验,网络架构的具体设定如表1所示.MCST-Net-10在卷积1后,采用大小为1×2×2,时间步长为1,空间步长为2的3D池化层进行空间下采样,来缩小特征图的空间尺度.在网络的前期,为了保留更多的时序信息,不进行时间下采样.而在卷积块3、4、5后,统一使用大小为2×2×2,步长为2的3D池化层,对特征进行时空下采样,降低特征的时空尺度.网络模型中,所有时空卷积的步长设为1,并在卷积处理后进行批量归一化和激活函数(ReLU)操作.最后通过全局平均池化、全连接层以及softmax函数完成网络的动作分类.
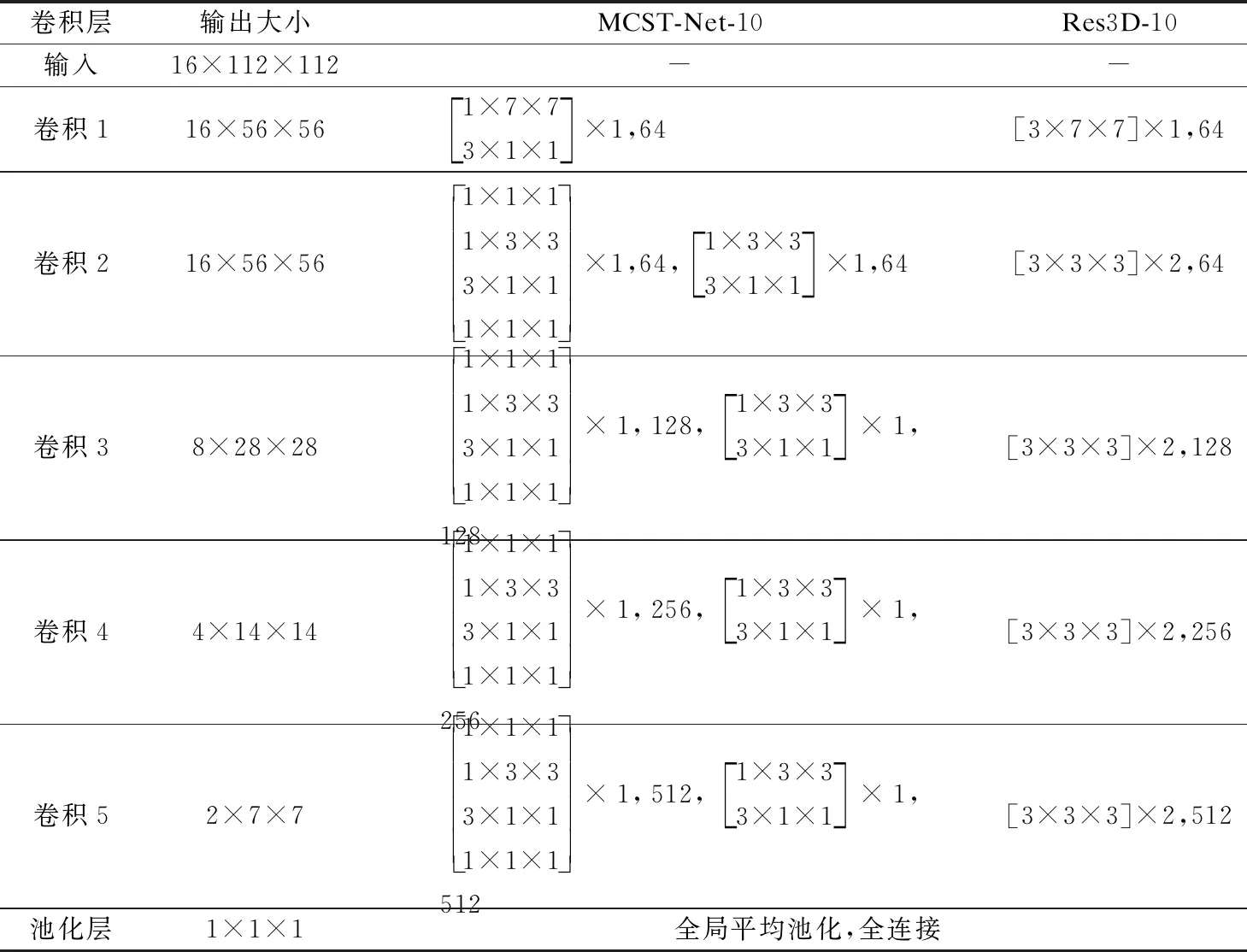
表1 MCST-Net-10和Res3D-10网络架构
3.4 MCST模块与基于3D卷积方法的对比实验与分析
为了验证本文所提出的MCST模块的有效性,我们首先对基于3D卷积的两种经典方法:Res3D网络和R2+1D网络进行复现.Res3D网络在经典的3D卷积结构中,增加残差结构,解决了梯度消失的问题;而R2+1D网络将3D卷积进行时空分割,有效降低3D卷积的参数量,提高网络的提取效率.本文在相同条件下,基于UCF101数据集与未添加注意力模块的MCST-Net进行对比实验,从识别准确率和网络参数两方面进行分析评估.其中MCST模块的尺度参数设为4,实验结果如表2所示.整个训练过程中,各网络测试准确率的变化情况如图4所示.
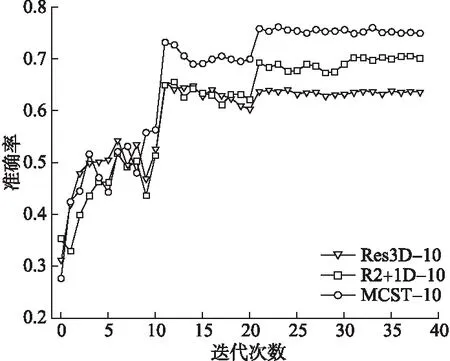
图4 基于UCF101数据集的测试准确率

表2 基于UCF101数据集的实验结果
实验结果可以看出,本文所提出的MCST-Net在识别准确率和网络参数方面明显优于Res3D网络和R2+1D网络两种经典的3D卷积方法.在网络深度相同的条件下,MCST-Net-10的识别准确率达到了76.0%,比R2+1D-10提高约5.4%,比Res3D-10提高约10.9%.而且MCST-Net-10的网络参数大约为583万个,仅为R2+1D-10的81%,Res3D-10的40.4%.参数量的下降,对于网络的优化与训练是非常有利的.实验结果进一步验证了MCST模块的优越表现.分析其原因是:MCST模块采用类残差的结构对输入特征进行通道分离,获得多尺度的时空感受野范围,可以更充分的利用各维度的特征信息.因此,MCST模块有利于学习更丰富的时空特征信息,使网络能够更全面的完成复杂动作的识别任务,而且识别准确率更高,参数利用更高效.
3.5 不同尺度MCST模块的对比实验与分析
MCST模块的核心思想是通过类残差的结构,分别对通道的多个子集进行卷积处理,获得多尺度时空特征.而这种分割的操作就引入了一个尺度参数S.在保证网络的深度、宽度等条件一致的前提下,本节通过一系列的实验,评估尺度参数S的改变,对于网络性能的影响.
由于S=2时,MCST模块在特征重利用的比例较高,不利于时空特征提取效果的提升,所以本节未对尺度参数S=2的情况进行研究.本节实验主要设定了3种尺度参数的方案,分别为S=3、S=4和S=5.在UCF101数据集上进行对比验证,整个实验过程中,各种尺度的训练准确率和测试准确率变化情况如图5(a)-图5(c)所示.根据实验结果可以看出,在实验前期,随着尺度参数的增大,训练准确率的提升速度略微减慢.这是由于尺度的增加,使网络的参数有所改变,导致网络的前期的优化效率略微降低.但随着迭代次数的增加,最终的训练准确率均可以达到很好的收敛效果.而测试准确率随着尺度参数的增大而有所提高,且后期测试准确率曲线更加平滑.
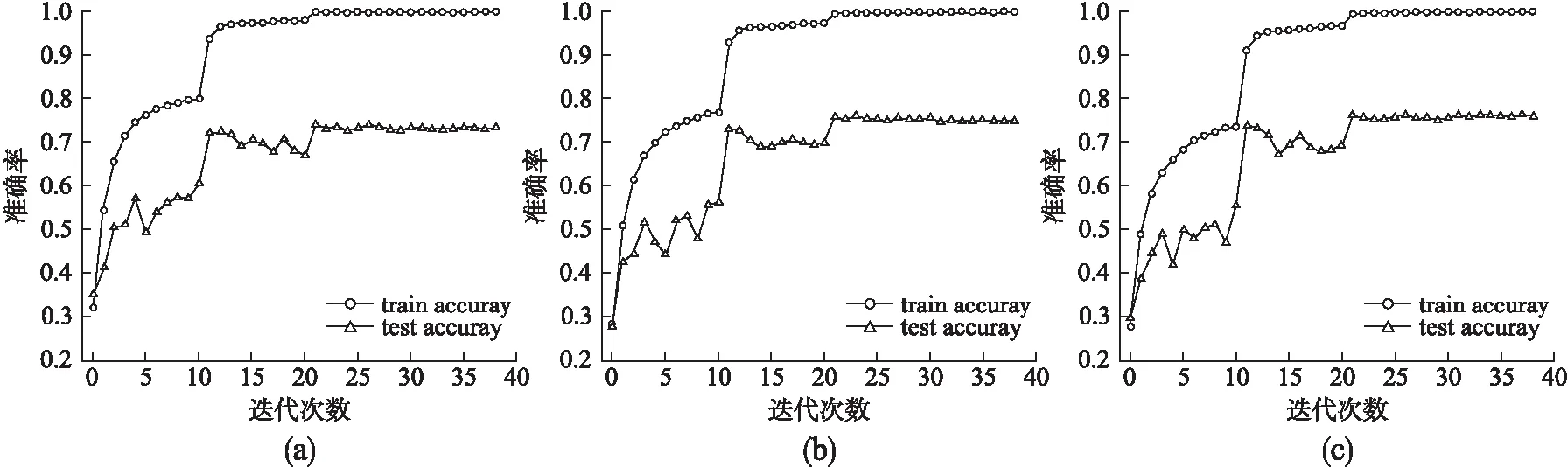
图5 不同尺度MCST-Net的实验结果
具体的测试准确率和网络参数结果如表3所示.由于尺度参数的增加,使得x1子集中的通道数下降,进行卷积处理的通道比例上升,所以网络所需的卷积数量也略有增加,参数量也逐步增加.而测试准确率,却随着尺度参数的增加而有所提升.但尺度S=5时,测试准确率的提升是有限的,相比S=4的结果,仅提升了0.3%.本文认为这是由于S=5时等效感受野将达到9×9×9,超出网络的后期的输入特征大小,无法进一步提高MCST模块提取时空特征的效果.所以在考虑测试结果和网络参数等条件下,尺度参数S=4时,MCST-Net的识别性能更加高效.实验结果证明了多尺度的时空感受野,有利于网络学习更丰富的时空特征,来提高网络在人体行为识别任务中的识别准确率.
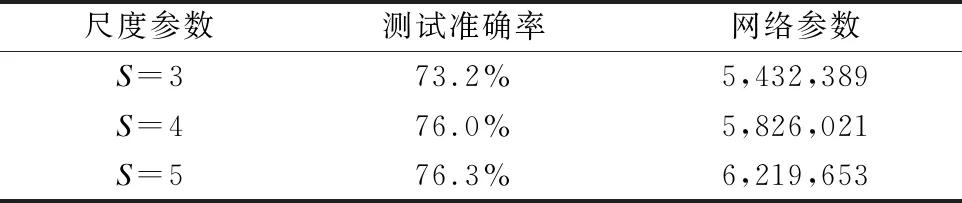
表3 不同尺度MCST-Net的实验结果
3.6 引入INLA模块的实验与分析
为了更有效地实现时空信息的提取,本文还提出了改进的非局部注意力模块INLA,增强相关特征的全局依赖关系.在相同的实验条件下,对未加注意模块、添加NL模块和添加INLA模块的3种网络进行对比实验.从识别准确率、网络参数、占用显存和训练时长方面进行对比.其中占用显存的大小是在batch size=1的条件下进行统计的,以避免并行训练等原因对其数值造成影响.实验结果如表4所示.

表4 添加注意力机制的实验结果
通过实验结果可以发现,添加了注意力模块的网络,在识别准确率方面都有所上升,大约提升1.42%~1.44%,而参数量仅增加约0.4%.证明了注意力机制的使用,可以有效地提高网络提取时空特征信息效果.INLA模块与NL模块对于网络性能的提升效果基本一致,仅相差0.02%,而二者在训练时长和占用显存方面有很大差别.相比于添加NL模块的网络83.2小时的训练时长,添加INLA模块的训练时长为78.0小时,大约降低了6.25%.间接证明了INLA模块有效的降低了注意力机制部分的时间复杂度.同时,添加NL模块的网络所需显存为2809MB,而添加INLA模块的网络仅需1957MB.大约降低了30.34%.对比实验的结果,进一步证明了INLA模块,在保持特征全局依赖关系的前提下,有效地降低了注意力模块的时间复杂度和占用显存空间,更有利于网络的训练与优化.
3.7 与目前主流方法的对比
为了进一步验证MCST-Net在行为识别方面的优越表现,分别在公开的人体行为数据集UCD101和HMDB51上训练网络,以RGB视频作输入,与目前主流的多种方法进行比较,识别准确率的对比结果如表5所示.
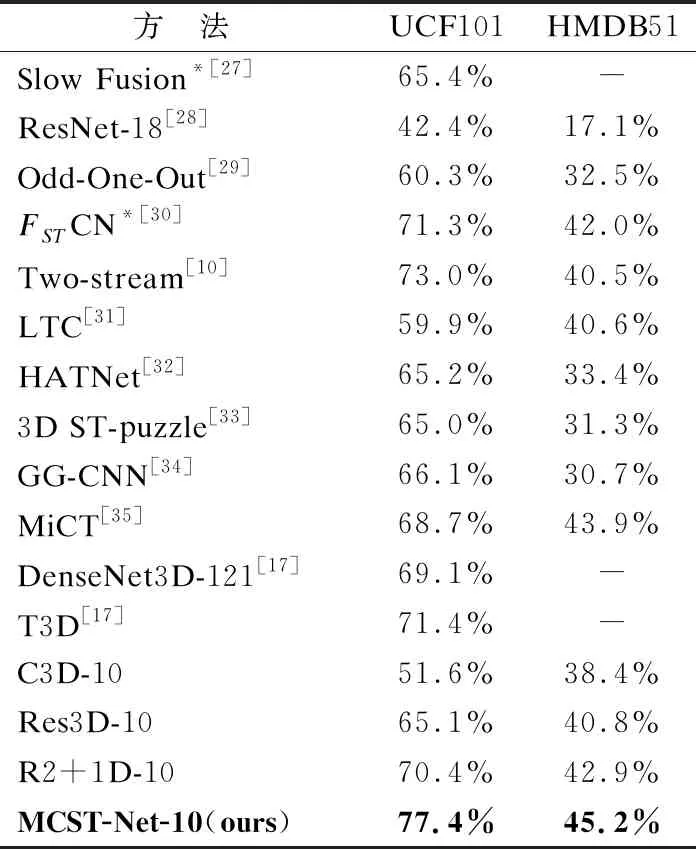
表5 不同方法的识别准确率对比
对比的结果可分为3组,分别为基于2D卷积的方法、基于3D卷积的方法和本文进行复现的方法.基于2D卷积的方法,选取了5个比较具有代表性的方法,以此与3D卷积的方法形成对比,其中*表示该方法需要额外的预训练或多类别输入等操作,才能达到的实验结果.基于3D卷积的几种方法,从不同角度,对3D卷积网络进行优化或考虑不同的方式,来处理视频样本.本文复现的几种方法,为了保证实验的公平性,网络深度统一设为10层.
通过表5的对比结果可知,本文提出的MCST-Net,在两个公开数据集中都取得了最好的识别效果,分别达到77.4%和45.2%的测试准确率.相比2D卷积的方法,本文的MCST-Net无需预训练等额外操作,就能取得更优的识别准确率,比多类别输入的Two-stream方法,还要提高4.4%和3.2%,较大幅度地提高了网络的泛化性和普适性.而相比3D卷积的方法,同样使用UCF101和HMDB51从新开始训练,MCST-Net获得了最高的识别准确率,比表中最优的3D卷积方法T3D网络,还要提高约5%和4%的识别准确率.从表5可以看出,MCST模块和INLA模块相结合,可以有效地提取视频样本中的时空特征.从而使整个网络具有较好的泛化能力和识别效果.
4 结 论
本文提出了一种简单高效的多尺度通道分离的时空卷积网络(MCST-Net)用于人体行为识别.在网络中使用类残差结构的MCST模块,获得多尺度的时空特征,使网络从视频样本中提取到的时空信息更加丰富.此外,提出了一种改进的注意力机制INLA模块,进一步增强时空特征的全局依赖关系,使网络更加高效的完成人体行为识别任务.所提出的MCST-Net在两个经典数据集UCF101和HMDB51进行多组实验评估,识别准确率可以达到77.4%和45.2%.相比目前人体行为识别的几种主流方法,MCST-Net都取得了更优异的识别效果,具有提取时空信息更丰富、参数量更少、泛化性更强等优点,进一步提高人体行为识别的准确率.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
中国信息化周报(2015年1期)2015-04-09
