
多模态下的互补物品的多样性推荐
2021-08-24 03:06肖庆华刘学军施浩杰
小型微型计算机系统 2021年9期
肖庆华,刘学军,施浩杰
(南京工业大学 计算机科学与技术学院,南京 211816)
1 引 言
大数据、物联网等技术快速发展,互联网中的各类应用层出不穷导致了数据呈现爆炸式增长[1],由于数据量的庞大和冗杂,导致了严重的“信息过载”的问题,在纷杂的信息中找到自己需要的信息是一件很困难的事;同样地,使自己生产的信息受到广大用户的关注,也是一件困难的事.推荐系统由此成为了解决这些矛盾的工具[2].推荐系统就是使用户和信息之间建立桥梁,从而让用户能够在庞大的数据空间中快速找到自己感兴趣的信息,一些用户自己产生的信息能够快速被其他用户捕捉,实现脱颖而出.随着移动互联网的发展,一些移动数据如社交、地理等数据为推荐系统提供了更多的数据来源,使研究更为广泛.
在人们买衣服的时候,总会有人问诸如这样的问题:“这件衬衫和那件牛仔裤配吗?”又或者在买电子产品诸如相机的时候,不知道要买哪些镜头以适配此相机?这些问题的产生就导致了推荐系统向更深的层次发展,互补替代推荐系统由此产生.在现代的推荐系统中,了解产品之间的关系是很重要的.例如,当用户正在寻找手机时,推荐其它手机可能是有意义的,但是一旦他们购买了手机,我们可能会推荐电池、外壳或充电器,这两种类型的推荐被称为替代品和互补品:替代品是可以替代其它同类产品而相互购买的产品,而互补品是可以和其它同类产品同时购买的产品.
根据上述问题,利用互补替代推荐系统就可以解决.如图1所示,当一个用户买了相机、手机或者羽毛球拍后,根据互补推荐算法,可以很快地为该用户推荐出相关互补产品,例如相机的互补产品有镜头、相机包、闪存卡等,手机的互补产品有手机壳、充电器、数据线等,羽毛球拍的互补产品有羽毛球、羽毛球服饰、羽毛球包等.

图1 互补推荐示例
目前的互补替代推荐系统主要针对其准确性而进行很多深入研究.然而,在准确性逐步提高的情况下,互补推荐本身的其它一些属性没有得到重视,例如多样性研究.在保证互补推荐的准确性前提下,推荐列表的多样性也很重要,当推荐列表的多样性提升时,用户的接受程度也会变高,用户的参考方案也相应地变多.本文主要研究如何在互补推荐的准确性前提下提升推荐列表的多样性,最大化用户满意度,根据此问题提出了基于多模态互补物品的多样性推荐方法,称为DR-MCI(Diversity Recommendations of Multi-modal Complementary Items).该方法利用卷积神经网络、doc2vec和贝叶斯平均评分对互补物品对的图像、描述文本以及评分信息进行特征表述,计算两个物品之间的特征距离,然后进行非线性组合形成初步的推荐列表,最后加入用户偏好特征进行多样性推荐.
2 相关工作
2.1 传统推荐方法
传统推荐方法分为基于内容、协同过滤和混合推荐.基于内容的推荐就是根据用户评分的物品,寻找其它内容与之相似的物品作为推荐,但是这种方法一般会遇到特征提取困难的问题;协同过滤推荐就是利用用户之间的相似兴趣,发现用户对物品的潜在爱好;混合推荐,顾名思义,就是结合一种或者多种推荐方法,形成统一的推荐模型进行推荐.
包推荐(Package Recommendation)是一种特殊形式的多领域相关推荐方法,通过智能化的方式将项目之间进行组合,将具有一定关系的物品进行打包推荐给用户.Interdonato等人[3]首次提出了一种通用的包推荐方法,通过分析用户偏好,根据帕累托最优方法选取top-k项目分配到给定包中.为了提升包推荐的精度,一些研究通过限定包的规模从而达到提升效率的目的.Villavivencio等人[4]针对多样性研究提出复合推荐方法,该方法主要针对旅游方案的推荐,但是因其通过分层多样集的方法使该推荐也适用于其它领域.
2.2 融合深度学习的推荐方法
近年来,深度学习在图像处理、自然语言处理等领域取得了很大的突破[5],使推荐系统有了更多的研究方向.Li等[6]提出了RNS模型,即神经序列推荐模型,利用A-CNN即感知卷积网络技术获得用户潜在偏好.Ma等[7]提出了交叉注意记忆模型(CoA-CAMN),该模型通过VGG-Net16获取图片信息并与推文结合,最终获得用户偏好信息.Wu等[8]使用生成对抗网络(GAN)构建了推荐模型—PD-GAN,它是由生成网络和判别网络组成,该模型主要是产生多样化且相关的推荐项,从而增加推荐结果的多样性.
2.3 深度学习方法在互补替代推荐中的应用
互补产品推荐的传统方法依赖于行为和非视觉数据,如客户共同浏览或共同购买的数据.然而,某些领域,如时尚领域,主要是基于视觉的.Julian等[9,10]利用人们的视觉图片数据进行互补替代推荐的研究,他们感兴趣的是揭示成对物品的外观之间的关系,特别是建模人类的概念,即哪些物体是互补的,哪些可以被视为可接受的替代品.他们利用视觉线索,以一种非监督的方式来学习分布的共同发生的互补项目在现实世界的图像.实际上,还有很多互补替代关系是基于文本的,Zhao等[11]将商品的标题信息向量化,输入到孪生网络中训练预测出互补概率;Julian等[12]使用的主要数据来源是产品评论的文本,从这些文本中建模并预测产品之间的关系.Zhang等[13]提出将基于视觉的和基于文本的结合起来实现互补推荐.
3 DR-MCI方法
3.1 互补替代关系感知
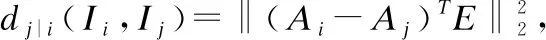
3.2 模型框架
假设我们有物品集I=[I1,I2,…,In]和互补集Ci=[ric1,ric2,…,rici],i∈{1,2,…},表示的是待查询物品Ii和待推荐物品IC1,IC2,…,ICi∈I具有互补关系.模型的前半部分主要是构建两个物品之间的互补距离公式,dm(Ii,Ij),dt(Ii,Ij),dr(Ii,Ij),其中,dm(Ii,Ij)表示物品Ii和物品Ij的图片之间的距离,dt(Ii,Ij)表示物品Ii和物品Ij的描述文本之间的距离,dr(Ii,Ij)表示物品Ii和物品Ij的评分之间的距离,也称物品Ij的质量期望,然后将这3种距离进行非线性组合,得到统一的距离公式d(Ii,Ij),最后可以得到初步的互补推荐结果;模型的后半部分是将前半部分得到的推荐物品进行深层次的分析,结合物品之间的替代关系,利用bandits算法实现多样性推荐.总体框架如图2所示.
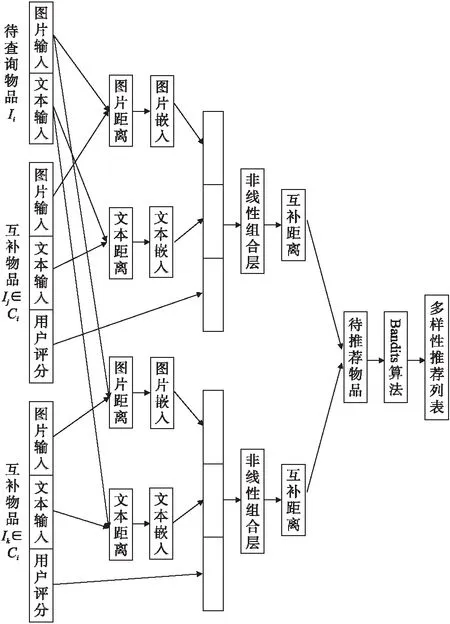
图2 互补物品多样性推荐框架
3.3 图片模态的距离测量
首先,需要将电商平台上的商品图片进行视觉特征提取,根据文献[9],我们可以提取高维图片特征,使用的技术是卷积神经网络[14](CNN),CNN模型通过ImageNet预训练过,实际上,我们需要的是CNN全连接层的第2层为输出层,并且图片向量的维度为fm=4096,在提取高维图片特征之后,通过马氏变换矩阵可以实现降维,最终作为图片的嵌入层[7],马氏变换就是通过去除掉一些不相关的点,从而实现降维.接着计算马氏距离来表示图片之间的距离,具体表示形式如等式(1)所示:
(1)
其中,mi和mj是高维嵌入向量,表示物品Ii和物品Ij的图片特征向量,∑即协方差矩阵,它是马氏距离的重要组成部分,EM∈Rfm×fem是低阶马氏变换矩阵,fem则是嵌入图片维度.根据此距离公式,使用sigmoid转移函数可以计算两个物品属于某一关系的概率:
(2)
根据这个概率等式,使用极大似然估计法可以训练出EM,最终获得图片模态的互补替代程度.
3.4 文本模态的距离测量
以上基于图片模态的互补替代距离的计算可以表达出两个物品的互补替代程度,但是在某些时候,紧紧凭借这一个模态往往是不够的,因为图片也具有一定的欺骗性,如图3所示,一个长得像打火机的U盘和真实的打火机是种类完全不同的两个物品,玩具熊和熊状的背包也是两个功能不同的物品,因此光从图片角度去推荐互补替代产品有时会影响准确度,由此提出了利用物品的描述文本实现更精确的推荐.一个物品有id、标题、类型和评论文本等属性,我们可以构建两个物品在标题或者评论文本尺度上的距离函数dt(Ii,Ij),该函数就是表示物品Ii和物品Ij的标题以及评论文本之间的距离,即互补程度.

图3 容易混淆的图片举例
对于标题和评论文本的表示方面,有人提出过分布式表示的方法[15],但我们使用的文本长度以及单词量都比较大,因此我们用doc2vec[16,17]的技术实现文本单词的向量化是比较合适的.在这之前,需要引入word2vector[18,19],它是一个将单词转化为向量形式的工具.它的基本思想是把自然语言中的每一个词,表示成一个统一意义维度的短向量,任何一门语言,都是由一堆的词组成,所有的词,构成一个词汇表,词汇表,可以用一个长长的向量来表示.词的个数,就是词汇表向量的维度,那么,任何一个词,都可以表示成一个向量.在此基础上,将每个单词的向量进行叠加组合就可以表示出一段句子甚至一篇文档的向量形式,doc2vec就是在word2vec的思想上进行延伸的.
基于以上,将距离表示的描述公式化可以得到等式(3):
(3)
其中,ti和tj是嵌入向量,表示物品Ii和物品Ij的文本特征向量,用doc2vec训练而成,经过实验验证,最终选择模型训练的窗口大小为20,文本向量维度为ft=100,矩阵ET∈Rft×fet是需要训练得到的最终文本特征来表示互补关系,fet是文本嵌入维度.同样是使用sigmoid转移函数计算两个物品属于某一关系的概率,最终获得文本模态的互补替代程度.
3.5 加入评分生成初步推荐
当我们得到图片模态和文本模态的互补距离时,将这两种模态进行线性组合是可以得到推荐结果的,即pdm(Ii,Ij)+qdt(Ii,Ij),p和q是超参数,但是这样会存在一个问题,推荐结果很粗糙,只是单纯的将最接近互补关系的物品推荐给用户,而没有考虑到用户喜不喜欢、需不需要,这时推荐质量很低,因此提出了将用户评分所隐含的喜好程度加入到互补推荐过程,根据文献[13],我们使用贝叶斯推断.用户的评分是参差不齐的,有些物品有大量用户评分过,而有些物品评分稀疏,直接利用均值来表示一个物品的评分是不合理的,而贝叶斯推断可以解决此问题,它通过不断修正先验概率,最终得到后验概率,即用户对物品i的期望θi.
首先定义随机变量:
(4)
表示物品i的第k个评分是好的还是坏的,rik即物品i的第k个评分,ηr是阈值评判是好的评分还是差的评分,qik的概率密度函数可表示为等式(5):

(5)
其中,qik服从伯努利分布qik~B(1,θi),此时物品Ii可以得到一个好的评分因此θi可以测量用户的期望,期望越高表示此物品评分越好.通过贝叶斯估计法可以得到θi的估计值,最终得到评分距离dr(Ii,Ij|θj)∝(1-θj|qjk).
当得到图片模态、文本模态以及评分期望后,为了得到初步的推荐结果,使用神经方法进行模型训练,将以上模态进行非线性组合,通过特征差异学习互补物之间的关系c(Ii,Ij|θj)=[dm(Ii,Ij),dt(Ii,Ij),dr(Ii,Ij|θj)],用此公式作为神经网络的非对称合并层,加入权重W和偏置b,并使用tanh作为激活函数,得到距离表示:
dn(Ii,Ij)=tanh(c(Ii,Ij|θj)×W1+b1)×W2
(6)
最终得到物品Ii和物品Ij属于互补关系的概率为:
(7)
ηd是学习到的互补阈值.
定义损失函数为:
L=-yijlog(P(rij∈Ci))-(1-yij)log(1-P(rij∈Ci))
(8)
其中,yij表示物品i和物品j是否存在互补关系.
3.6 生成多样性推荐
当得到初步的互补物品推荐后,由于缺乏多样性,因此,加入Bandits算法进行多样性推荐.Bandits算法就是为选择而生,对用户确定的兴趣进行迎合利用,当然用户对已知的兴趣总会腻的,因此需要不断探索用户新的兴趣,这样就实现了对某一个类型的物品推荐出更多这一类型的物品,从而实现多样性推荐.
Bandts算法是一个统称,我们使用汤姆森采样(Thompson sampling)算法实现,假设有很多台赌博机,可以摇臂,有赢和输两种情况,将物品比作赌博机,用户评分就是赢和输的凭证,假设每一个臂都有收益,且都有一个概率分布,其中有收益的概率为p,经过摇臂试验,估计出一个置信度较高的“p的概率分布”,假设每一次的分布都服从贝塔分布,即p~Beta(wins,lose),它具有两个参数,每次摇臂,有收益则这个臂的wins加1,无收益lose就加1,每次选臂的方式是,用每个臂当前的贝塔分布产生随机数b,选择所有b中最大的那个臂.
经过实验验证,在所有Bandits算法中,汤姆森采样在互补物品的多样性推荐上取得了不错的效果.
4 实验与分析
本文提出的网络结构基于Tensorflow平台实现,该试验在CPU为Intel Xeon E5-2630v3,显卡为GTX 1080Ti(11G),内存为32G的工作站上运行,操作系统为Window10,代码编写使用Python语言.
4.1 数据集和数据预处理
本文是针对电商平台而研究的一种推荐技术,因此使用的数据来自亚马逊(Amazon)商城提供的公开数据集(Amazon product data)(1)http://jmcauley.ucsd.edu/data/amazon,完整数据集中的物品数量超过100万件,包含4千多万个同购关系,共29个类别,由于数据量庞大,我们只选取了其中的5类商品,包括电子产品、衣服鞋子珠宝、图书、手机及配件和电影电视.在数据集官网中,我们可以很清晰的分辨出其中的数据格式,其中reviews数据压缩包包含了评论者编号(reviewerID)、商品编号(asin)、评论文本(reviewText)和评分(overall),meta数据压缩包中包含了商品编号(asin)、标题(title)、具有同购关系的商品(related),同购关系包括附带购买(also_bought)和同时购买(bought_together).
具体的数据规模如表1所示.

表1 数据集规模统计表
数据预处理需要对评论和元数据进行合并处理,即一个商品对应唯一的商品编号、来自多个用户的评论文本和评分、标题文本以及具有相关关系的商品编号.原始数据准备完成,还需要对图片数据进行处理,根据文献[9],我们可以得到每个商品编号对应的图片特征向量,其维度是4096维.对于标题文本和评论文本,我们需要将其向量化,在这之前,将标题和评论文本进行合并,即一个商品编号对应一个标题信息和多个用户的评论文本,然后利用doc2vec技术实现文本向量化,最终得到商品编号对应的文本特征向量,其维度是100维.
4.2 评价指标
在互补推荐的准确性方面,P@k(Precision)在推荐领域准确度测量方法中被广泛使用,它表示前k项中正确推荐的项目的比例.另外,准确性的测量还可以用等式(9)计算:
(9)
其中,当x>0时,S(x)=1,否则S(x)=0.
在多样性方面,先计算D(R(u)),即每个用户u的推荐结果R(u)中,每两个物品的不相似程度,然后计算所有用户的推荐列表不相似程度的均值D:
(10)
(11)
4.3 参数设置
通过对数据集的预处理和分析,训练集是选取所有数据的80%,20%为测试集.训练过程采用五折交叉验证法进行多次训练,图像和文本的潜在因素维度设置为10,对于评分,阈值设置为ηr=3.在训练推荐模型之前,需要训练文本向量化模型,其中训练的窗口大小w:{3,5,10,20},训练的文本向量长度l:{50,100,150,200},根据实验结果可知,训练窗口大小选取5,文本向量长度选取100最为合适.对于文本数据进行预处理的python代码已在github(2)https://github.com/tsinghuaxiao/text2vec网站上贴出.互补推荐模型的学习采用随机梯度下降法(stochastic gradient descent,SGD),可选取学习率α:{0.1,0.01,0.001,0.0001,0.00001}.
4.4 实验对比
为了验证所提出的算法的整体性能,将DR-MCI算法同以下4种方法—LRA、LRB、WNN、LMT进行了比较:
LRA即逻辑回归平均评分.本文将物品Ii和物品Ij的图片模态、文本模态和评分信息作为输入,计算两个物品互补的概率,其中评分是用平均评分,没有用到贝叶斯方法.
LRB即逻辑回归贝叶斯评分.前两者模态和LRA是相同的,唯一的区别就是评分使用的是贝叶斯推断.

LMT即低阶马氏变换.该方法在文献[7]中得到运用,但是只针对图片模态,在本实验中,使用到了图片模态、文本模态以及评分信息.
基于多模态互补物品的多样性推荐利用图片模态、文本模态以及评分信息,利用神经网络方法进行非线性组合,加上Bandits算法实现其互补多样性推荐.从表2可以看出,DR-MCI在亚马逊商城的5种类别商品数据集上以P@5和P@10实现了最先进的性能,验证了所提模型的有效性.在前两个方法LRA和LRB的比较中,可以得知,不管是P@5还是P@10,贝叶斯推断方法在处理大规模评分数据时具有很好的性能,这也是本文采用贝叶斯方法的原因.

表2 相关方法实验结果对比
为了验证多模态对实验的影响,本文对以下4种方法进行实验比较:
DR-MCI_M:该方法只考虑图片这单一模态,根据等式(1)进行实验.
DR-MCI_MT:该方法组合了图片和文本模态,没有考虑评分信息,即对图片距离和文本距离进行线性组合互补距离为pdm(Ii,Ij)+qdt(Ii,Ij).
DR-MCI_MTR:该方法将图片、文本和评分都考虑在内,但是使用的是传统的线性组合.
DR-MCI:最终,我们将所有模态都考虑在内,并且舍弃线性组合的方式,而采用神经方法进行非线性组合,从而训练出最终的模型.
根据图4的实验结果,可以看出,在不同模态组合当中,采用单一图片模态的效果是最差的,因为光从图片的角度去分析两个物品的互补程度是不合理的,很多时候图片具有欺骗性.随着模态的增加以及组合方式的改进,我们发现DR-MCI_MT和DR-MCI_MTR方法的准确率在逐步提升,本文提出的方法取得了最优的性能,平均准确率达到了0.767.

图4 不同模态组合下的实验对比
除了推荐的准确性能外,多样性在本文中的表现也很重要,因此根据Bandits算法选取的不同,设置了3种对照试验:
EG-D:Epsilon-Greedy算法,这是一个朴素Bandit算法,类似模拟退火的思想:首先在(0,1)之间选一个较小的数作为e,然后每次以概率e做一件事,即所有臂中随机选一个,最后每次以概率1-e选择到当前为止,平均收益最大的那个臂.

TS-D:汤姆森采样(Thompson Sampling)算法的核心思想就是利用beta(wins,lose)分布去选择合适的臂,具体算法在本文的3.6小节介绍过.
根据表3可知,在这3种算法中,TS-D的性能最优,其次是UCB-D,最后是EG-D,在所有Bandits算法中,UCB和汤姆森采样确实能表现得更优异,结合本文提出的多样性计算公式以及多次实验,最终验证该方法的有效性.

表3 多样性实验结果对比
5 总 结
本文针对现有的互补替代推荐方法的精度和多样性表现不足的问题,提出了基于图片、文本以及评分的多模态互补物品多样性推荐DR-MCI模型.在该模型中,通过对图片模态的卷积操作实现图片特征表示,对标题和评论文本进行文本向量化训练实现文本特征表示,对评分进行贝叶斯推断操作实现评分维度的选取,应用神经方法将这三者进行非线性组合,加入Bandits算法,最终实现互补替代多样性推荐.因为替代推荐原理和互补类似,只是选取的输入数据集不一样,因此本文主要对互补推荐进行了更加详细的描述.综合实验结果表明,所提出的算法优于基线算法,有效提升了互补替代推荐的精度和多样性.
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车工程师(2021年12期)2022-01-17
思维与智慧·上半月(2018年11期)2018-11-30
成长·读写月刊(2018年8期)2018-08-30
小天使·二年级语数英综合(2017年3期)2017-04-01
小天使·一年级语数英综合(2015年8期)2015-07-06
读者·校园版(2015年13期)2015-07-01
母子健康(2015年1期)2015-02-28
延河(下半月)(2014年3期)2014-02-28
电影新作(2014年1期)2014-02-27
