
UTMCQA:融合多任务的复杂问答模型
2021-08-24 03:06周高峰高盛祥余正涛寇梦珂
小型微型计算机系统 2021年9期
周高峰,高盛祥,余正涛,宋 燃,寇梦珂
1(昆明理工大学 信息工程与自动化学院,昆明 650500) 2(昆明理工大学 云南省人工智能重点实验室,昆明 650500)
1 引 言
当前大部分问答系统可以较好地回答简单(单跳)事实型问题[1],例如:“谁是电影《泰坦尼克号》的导演?”,此类问题仅包含单一事实,可以通过查询知识库中的单个关系(或路径)或检索某个文本段落来解决.但是,真实应用中的问题往往涉及多个实体和关系,同时它们之间具有复杂的约束限制和推理模式,这类问题常称为复杂问题[2,3],如:“What is the currency used in the region that has time zone Central Western Time Zone?”,该问题中涉及“currency”、“region”、“Central Western Time Zone”等实体以及“Entity-is”、“Entity-use”、“Entity-have”等实体间关系和“time zone”等约束情况,此类复杂问题需要综合利用多个支撑线索才能回答,因此处理复杂问题中的多个语义单元及它们之间的复杂关系至关重要.
知识库是处理复杂问题的一个重要信息源,目前利用知识库处理复杂问题的主流方法可以分为基于模板、语义解析和问题分解3类.其中,基于模板的方法[4,5]通常将自然语言问题映射到基于知识库的预先定义好的模板库,再使用对应的模板进行查询.语义解析技术[6-9]旨在为自然语言问题构造语义分析树或等价查询结构,把问题转换为对应知识库的查询语句进而通过检索获取答案.问题分解技术[2,9,10]将复杂的问题分解成多个相关但更简单的子问题,并以子问题的答案作为证据支撑得出最终答案.但此种方法的缺点在于系统的性能往往受到知识库不完整性的影响.相反,文本库往往包含了知识库中不存在的实体信息,其丰富的信息可以弥补知识库不完整的缺陷.最近的方法[11-13]通过融合结构化知识库和非结构化文本两个信息源,构建问题的相关子图并利用图表示学习的方法进行问答,在问答领域显示出巨大潜力.
虽然目前对复杂问题(多跳问题)的研究日益火热,但仍有很多挑战,主要包括:1)大多数问答系统没有关注到复杂问题中丰富的语义信息,大部分模型以流水线形式进行,实体链接、关系检测等各模块独立学习,各个模块不能通过相互作用弥补不足;2)虽然融合知识库和文本库的方法[12,13]在处理复杂问题上的效果显著,但是大多数系统的语义空间不统一.自然语言问题嵌入之后,转而用其他方法例如IDF相似度寻找实体信息,这样可能会造成语义歧义和语义融合困难.
为了解决上述问题,我们提出了一种称为UTMCQA(Uniform Multi-task Trainable framework for Complex Question Answering)的新框架.我们不假定信息在知识库或文档中,而是复合的,并且假设一个子图对应于一个问题.图1给出了UTMCQA框架概述.针对挑战1,我们使用预训练模型Albert[14]统一训练命名实体识别,句法分析,关系分类等主要任务,使各个模块中的信息相互作用,从而学习到复杂问句中的丰富语义信息;针对挑战2,我们在GraphNet[12]的基础上,采用BERT模型分析问题,结合语义相似从知识库和文本库获取问题相关的实体或句子,并根据其关联关系构建并迭代更新问题的图模型;最后根据构建的子图在一定范围内选择问题的最终答案.
本文在公开的大规模复杂问题数据集ComplexWebQuestion[15]上测试UTMCQA框架.实验表明,相较于其他模型,本文提出的问答框架UTMCQA在多个场景设置下均取得了最好的效果,并且验证了命名实体识别,句法分析,关系抽取等自然语言任务对框架的提升作用.本文的主要贡献包括:1)使用预训练语言模型(ALBERT)在同一语义空间统一训练命名实体识别,句法分析,关系抽取等任务;2)结合语义相似获取知识库和文本中的相关实体信息;3)在统一的语义空间进行子图更新和扩展;4)在大规模公开复杂问题数据集ComplexWebQuestion上的不同场景下的实验效果均有较好提升.
2 相关工作
问答系统的关注热点由简单单跳问题转移到了复杂的多跳问题.基于模板的方法[4,5,16]查询速度快,有良好的可解释性,但是复杂问题往往有多种表达形式,需要建立庞大的模板库,这个过程人工开销很大.语义解析技术为复杂问题构造语义分析树或等价查询结构.Hu[7]通过状态转移的方法把一个复杂问题转化为一个查询图,通过匹配潜在的知识图谱获得问题的答案.Luo[8]使用神经网络对复杂查询图的完整语义进行显式编码来处理复杂问题任务.Sun[17]用骨架语法来表达复杂问题的宏观结构,从而生成更精确的依赖关系来提高下游的语义解析任务.但语义解析的方法通常依赖于句法类似的依赖关系.分割阶段和语义分析阶段都存在错误积累.问题分解技术是应对复杂问题更为直观的策略.Talmor[2]和Min[18]等人将原始问题构建为多个跨距并利用端到端的深度神经网络模型训练.这些工作通常通过人类注释的监督学习或者启发式算法生成子问题,但收集分解标记并不容易,Perez[10]探索了无监督的方法来生成子问题.关注到子问题回答顺序的随意性会导致搜索空间大,漏掉答案的风险高,Zhang[19]通过优化这些顺序进一步改善了问答的性能.Zhang[9]在嵌入空间拆分问题,然后通过语义解析分裂问题转化为结构化SPARQL查询.而目前大部分系统并没有关注问题中丰富的语义信息,我们利用预训练模型Albert统一训练命名实体识别,句法分析,关系检测等多个任务,在一定程度上解决了单个任务出错引起的错误传递问题,并将学习到的复杂问题中的丰富语义信息应用到下游子图构建任务.
联合知识库和文本库是提升复杂问答推理的有效形式Das[11]将Universal Schema[20]扩展到QA的应用当中,将两个不同来源的信息分别编码放入Memory Networks[21]中,以处理文本与知识库组合中的大量事实.GRAFT-Net[12]将知识库实体和文本放入同一个子图,利用图表示学习网络,训练单个基于Graph-CNN的模型以从子图中提取答案.PullNet[13]类似于GRAFT-Net,使用一个迭代过程来构造一个包含问题相关信息的特定于问题的子图,之后使用另一个图CNN从子图中提取答案.然而对于知识库或文本库中相关的句子或事实,现有算法大都是通过基于词频的方式发现,并不能应对复杂问答存在的复杂语义和复杂关系.我们利用语义相似作为启发信息,在统一的语义空间中进行分析和计算,并通过队列算法动态地结合上游任务的语义信息进行子图扩展,最后在图的广度范围进行答案选择,解决了不同训练过程带来的语义融合困难的问题.
3 模 型
3.1 任务定义
我们的目标是学习一个模型,对于给定的一个复杂问题q=(w1,…,w|q|),其中wi(1≤i≤|q|)表示复杂问题中的单词;从知识库K=(V,E,R)和文本库D={d1,…,d|D|}获取答案{a}q.其中V,E,R分别表示实体、关联、关系集合,di=(w1,…,w|di|)表示包含v∈V的句子;关联e∈E,表示为(vs,r,vo)三元组,其中vs,vo∈V,r∈R.
本文中为了获取答案:1)基于BERT模型学习问题q及其相关句子的语义特征,主要任务包括命名实体识别、句法分析、关系抽取等.给定问题q=(w1,…,w|q|),以及查找到的与问题q相关的候选实体集合Vq=(v1,…,v|v|)和候选句子集合Dq=(d1,…,d|q|),构造输入模型的数据格式为:[CLS]w1…w|q|[SEP]v1[#]…[#]v|v|[SEP]d1[&]…[&]d|q|,其中Vq包含的实体之间使用token“[#]”作为分割符,Dq包含的句子之间使用token“[&]”作为分隔符.同时在训练时,用与答案等长的“[mask]”串对问题q=(w1,…,w|q|)中的疑问词进行替代填充;2)根据问题q的语义特征从知识库K=(V,E,R)和文本库D={d1,…,d|D|}中获取相关实体或句子,并根据其关联关系构建并更新问题q的图模型Gq=([Kq,Dq,vq],Eq);3)根据Gq选择最终答案.整个过程均由可以训练的模型组成,具体如图1 UTMCQA模型所示.为此,我们将分3部分介绍UTMCQA模型:语义分析部分、图模型构建部分、答案选择部分.
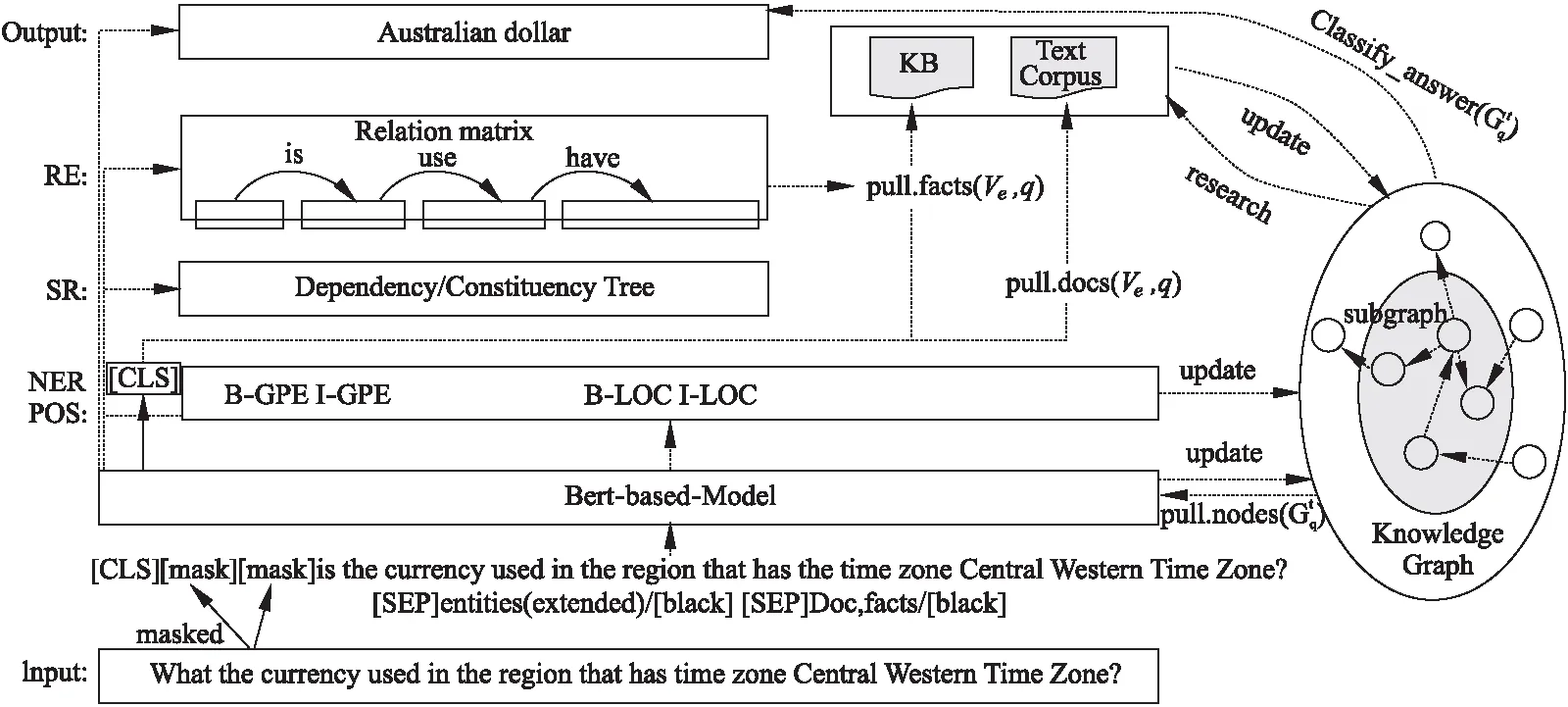
注:NER、POS、SR、RE分别表示命名实体识别、词性标注、句法分析、关系抽取,多个任务共享底层Bert;最右边表示迭代地从问题、知识库和文本库中获取实体、事实和句子以更新问题子图,并从子图中选择问题的最终答案.
3.2 语义分析
将复杂问题中多重或隐含的信息识别出来并不容易,为此我们采用预训练模型BERT作为基础编码器,并在其上构建可训练的多任务模型(多个任务共享底层BERT,并各自有自己的上层网络和损失函数)以更好地学习复杂问题所包含的丰富语法及语义信息,为构建和扩展面向复杂问题的图模型提供启发信息.具体请参考模型结构图2 “What is the currency used in the region that has time zone Central Western Time Zone?”的语义分析构图.下面,我们按照问题q的语义特征提取流程分别介绍相关处理.

注:ner表示实体,pos表示实体词性;实体间关系、实体间句法依赖、实体间成分依赖分别用实线箭头、虚线箭头、方形标示出.
3.2.1 命名实体识别+词性标注
在复杂问答中,命名实体识别(Named Entity Recognition,NER)和词性标注(Part of Speech,POS)均扮演着重要角色,很多问答出现错误都与该任务密切相关,一旦NER或POS发生错误,后续的处理也会随之产生级联误差;然而,目前的复杂问答算法并没有专门将以上两个任务作为必备的训练任务,而是利用外部系统(如Stanford NER,NLTK)进行识别,通常情况下此类通用的外部系统得到的识别结果中存在不少错误,其会大大降低复杂问答系统的性能.鉴于此,我们在框架中融合了命名实体识别和词性标注任务:
Oner/pos=CRF(BiLSTM(tanh(H[1],…,H[|q|]))
(1)
其中,H[1],…,H[|q|]表示问题q中所有单词的BERT输出,tanh,BiLSTM,CRF分别表示tanh函数,双向LSTM(Bidirectional LSTM),条件随机场.我们将这两个任务和后续的问答任务一起训练,此任务需要预先人工标注出句子中的命名实体和词性以提供监督信息,损失函数采用交叉熵损失函数.
3.2.2 句法分析
在复杂问答中,句法分析对于判断问题的复杂逻辑关系,有着重要的启发作用,其中依赖树(Dependency tree)和成分树(Constituency tree)尤为重要,因此让模型学习到句子中词与词之间的句法依赖关系以及不同词扮演的不同成分对正确回答问题有很大帮助.在这里,我们按照 HPSG[22]的做法将两者以Joint Span的形式定义span scores和dependence scores作为学习目标,句子中的词经过BERT模型的输出作为句法分析网络的输入,并用现有句法解析工具的结果作为监督信号(现有的句法解析工具可以标示出词之间的关系以及每个词的成分),具体计算过程如下:
relss=tanh(concat([H[i]-H[j],H[i]+H[j]]))
(2)
s(i,j)ss=sigmoid(linearss(relss))
(3)
s(i,j,l)ss=[s(i,j)ss]l
(4)
(5)
relds=concat([tanh(H[i]),tanh(H[j]),tanh(H[i]WH[j])])
(6)
s(i,j)ds=sigmoid(lineards(relds))
(7)
s(i,j,l)ds=[s(i,j)ds]l
(8)
其中ss为span-score的简写,ds为dependence-score的简写,s(i,j)span-score,s(i,j,l)span-score,s(T)span-score分别表示BERT输出H[i],H[j]之间,标注为l及其整个树T的跨度分数;同样的,s(i,j)dependence-score,s(i,j,l)dependence-score分别表示H[i],H[j]之间及标注为l的依赖性得分,linearss和lineards表示线性函数.对于句法关系训练的loss函数有如下定义:
(9)
loss(θ)ds=-(logPθ(H[parent]|H[child])+logPθ(l|H[parent],H[child]))
(10)
loss(θ)syntactic=loss(θ)ss+loss(θ)ds
(11)
3.2.3 关系抽取
在复杂问答中,一个问题往往包含实体之间多重或者隐含的关系,而这些关系可以深刻揭示问题的答案线索或答案本身.为此,我们以关系抽取作为复杂问答的重要线索,让网络能够学习到实体间丰富的关系,此任务也需要人工预先标注出句子中实体词之间的关系作为监督信息,类似的,此任务也以BERT模型的输出作为关系抽取网络的输入,具体的计算过程如下:
relre=concat([Maxpool(H[1],…,H[|ve1|]),
Maxpool(H[1],…,H[|ve2|]))
(12)
H[ve1,ve2]=linearre1(tanh(relre)
(13)
(14)
(15)
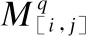
3.2.4 语义相似
对于知识库K或文本库D中与问题q相关的句子或事实fact,现有算法大都通过实体链接系统发现,并按照IDF相似度将之排序并获取TOP N的数据[13].但这种基于词频的算法缺乏对句子的深度理解,不足以处理复杂问答中所存在的不同语义和复杂关系的问题.为此,我们增加定义了可训练的语义相似作为IDF的启发信息,通过网络来自适应地计算问题和事实之间的相似度:
simq=linearsim(tanh(H[q]))
(16)
simfact=linearsim(tanh(H[fact]))
(17)
(18)
其中,H[q],H[fact]分别是问题q和相关句子或事实fact的通过BERT编码之后的句首输出,cos是余弦相似度函数,损失函数采用均方误差函数.
3.2.5 问答链接
复杂问答最终是对各种实体选择问题的答案进行排序,本文引入问答链接来表征问题q与备选实体v之间的距离或相似度,并以语义相似作为启发信息,具体定义如下:
linkqm=relu(linearlink(H[qm]))
(19)
linkv=relu(linearlink(H[v]))
(20)
(21)

3.3 图模型构建
以问题q为中心,将知识库K和文本库D中与问题q相关的事实或句子,按照相互关联关系,构建成问题q的图模型Gq=([Kq,Dq,vq],Eq),其中图模型的节点Kq,Dq,vq分别表示知识库K,文本库D及问题q中的事实、句子和实体,边Eq则是它们之间的语义相似,问答链接或关系等产生的高相关度的关联.
一般地,图模型主要按照如下流程建立[12,23]:
2)按照图相邻关系,更新节点表示:
(22)
其中,Nr(v)表示实体v的入度节点,φ表示转换函数,一般为神经网络模型,每一次根据当前节点上一次的表示以及邻居节点的表示来更新当前节点的表示,本文在此基础上进行改进.
3.3.1 节点初始化
在复杂问答场景中主要涉及到3类节点(实体,句子,事实),本文均使用BERT模型的输出作为节点的初始化表示:
其中,H[q]表示问题q,H[v]表示相关实体,H[fact]表示相关句子或事实;H[q]是问题经过BERT编码后的句首输出,H[v]是实体的BERT输出经过Maxpool池化后得到的表示,H[fact]则是句子或事实的BERT的句首输出,OX表示问题q经过语义分析后得到的启发信息,例如关系抽取,句法分析等内容,具体的,这里将语义分析得到的输出序列做Maxpool作为Ox.
3.3.2 节点更新
节点更新分为两种类型:一种是实体更新,一种为句子更新,我们参考Graftnet[12]更新方式.但是,不同于Gq的邻接矩阵,本文将各种语义分析的启发信息合并到节点更新的过程中.
3.3.3 节点扩展
节点扩展即根据图模型中的现有节点通过知识库K和文本库D中相关的事实或句子扩充图模型的过程.假设Hexp是待扩展实体[exp]的Bert输出,H[q]和H[fact]分别代表问题q和相关的句子或事实fact的BERT句首输出:
1)获取知识库K中事实和文本库D中句子fact:
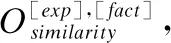
(23)
Okb-ranking=affine(BiLSTM(Okb-scores))
(24)
而排名结果Okb-ranking则是将Okb-scores通过BiLSTM(Bidirectional-LSTM)和affine仿射函数映射到排名列表中得到.同时,我们定义了可微分的Triple Loss函数来学习排名:
(25)
(26)

2)选择扩展节点:
算法.节点扩展(包含节点扩展中1)和2))
a) 经过如上步骤1)之后,首先对获得的事实和句子进行NER,POS,RE,SR分析;
b) 建立队列并更新:
对象队列Oqueue:按照问题q中包含命名实体(包括普通实体)、名词、动词、疑问词、形容词(一般级,比较级,最高级)的基本顺序分别建立队列;将a)步骤中通过NER,POS分析出的命名实体、名词、动词、疑问词、形容词分别插入到它们相应的队列中;
关系队列Rqueue:遍历问题q和a)步骤后获得的句子经过RE分析后所得到的关系集合,按照每个关系中涉及的两个实体索引以上对象队列,并根据关系的方向性加入到每个实体对应的链表中:如,“Central Western Time Zone”与“Region”存在“Entity-Have”关系,则对象队列中“Region”增加指向“Central Western Time Zone”的链表项;
句法队列Squeue:将问题q和a)步骤后获得的句子进行SR分析得到的依赖和成分关系添加到对象队列中:其中依赖关系按照有向关系处理,参考关系队列方式;而成分关系是无向关系,则对相应对象都添加链表项;
如队列初次建立,则以上所有队列和链表项都包含一个visited_time数据,初始值为0;
选择扩展节点:
引入:问题q的覆盖度是对象队列,关系队列,句法队列中涉及问题q的队列和链表项目中visited_time非零的项目个数的加权累加,wo、wr、ws是加权系数,counter计算队列非零项目的个数:
Cover(Gq)=wocounter(Oqueue)+wrcounter(Rqueue)+wscounter(Squeue)
而Cover(Gq,v)表示增加访问实体v后,问题q的最大可能的覆盖度.
定义(覆盖增益):
Gaincover(Gq,v)=Cover(Gq,v)-Cover(Gq)
表示由于增加了增加访问实体v后,比原来覆盖度增加的数量.
ⅰ.将待扩展实体按照覆盖增益排序,选出Top N个实体,按照顺序并根据随机概率α=0.15选择实体,选择后实体所对应的Oqueue、Rqueue、Squeue相应的项目或链表visited_time 加1;
ⅱ.如果覆盖增益小于一定阈值ξ或者Oqueue队列长度大于一定阈值ζ时,则进行答案选择;
ⅲ.否则,进行步骤1).
3.4 答案选择
答案选择是在一定范围内,即图模型Gq广度范围内,选择实体集合中最优的实体,作为问题q的最终答案.对图模型Gq中涉及的实体集合进行排序与上节中语义分析中的问答链接相同,此处不再赘述.
4 实验及结果分析
4.1 实验数据
为了防止训练集到测试集的数据泄漏问题,我们在改进的数据集ComplexWebQuestion version 1.1[15]上验证我们的想法,其中包含34689个示例,数据集按比例(8∶1∶1)划分为27734个训练样本/ 3480个验证样本/ 3475个测试样本,每个样本中包含了问题、答案,Web片段和SPARQL查询.该数据集包含4种类型的复杂问题:组合型(46.7%)、合并型(42.4%)、最高级类型(5.3%)和比较级类型(5.6%).每一个问题要么是两个简单问题的组合,要么是一个简单问题的延伸.
4.2 评测标准
我们使用Precision@1(P@1)作为评估指标来测试我们的框架处理复杂问题的性能.即返回的最高得分的答案是否与正确答案之一匹配.
4.3 实验设置
本文在涉及到多跳的数据集上进行实验,并使用知识库Freebase(version 2015-08-02)和文本库(来自数据集Web Snippet)结合的基础信息一起完成推理.为了加快训练速度,对Freebase进行预处理,过滤掉所有不包含ComplexWebQuestion中实体或关系的三元组.我们的模型使用Adam算法[24]进行参数更新,学习率设置为0.0001,dropout设置为0.2,batchsize设置为{10,30,50},本文选择Albert-base[14],输出维度768.BilSTM设置为1层,linearss是1536×1的全连接网络,lineards是2304×1的全连接网络.关系抽取中Maxpool选择128个768×3的kernel,linearre1和linearre2分别是128×64和64×1的全连接网络,linearsim和linearlink均为768×384的全连接网络.
4.4 实验场景及基准模型设置
为了提高算法的泛化能力,贴近现实场景,我们参考PullNet[13]将实验分为3种测试场景:知识库K测试场景,文本库D测试场景,知识库K和文本库D混合测试场景.考虑到知识库的规模和实验速度,本文在知识库和文本库混合场景下,只使用了50%的KB.
我们选择KV-Mem(记忆网络,Key-Value Memory Networks[25]),GRAFT-Net[12],PullNet[13]等作为基线测试模型,所有模型都支持如上3种测试场景:KV-Mem将句子或事实编码后,形成Key-Value结构;Graft-Net 和PullNet以IDF 相似度获取文本库中的句子,使用PageRank-nibble算法[26]获取知识库中的事实;而我们的UTMCQA模型则是结合语义相似来动态获取相关实体和句子信息.
4.5 实验结果分析
本文的实验主要基于ComplexWebQuestion数据集进行模型的测试,并选择了KV-Mem,GraftNet,PullNet这3个基准模型进行对比.其中KV-Mem,GraftNet这两种模型能够放入内存的事实和文本的数量上都是有限的,通过表1注意到KV-Mem较其他模型表现较差,我们认为KV-Mem可以很方便的对先验知识进行编码,对键值的关注是在记忆上规范化的,这些记忆是KB事实(或文本句子),因此模型无法在同一时间为多个事实分配高的概率,从而在复杂问题上表现较差.而UTMCQA和PullNet类似,均能扩展子图模型,从而包含更多的信息进行答案选择.表1实验结果表明:在不同知识库和文档成分的数据上的实验,本文提出的方法相比于其他模型取得了更好的结果.
通过对比两种信息来源的区别得出,知识库是高度规则化结构化的知识,模型比较容易学习,而文本库虽然蕴含丰富信息但是由于自然语言表达的复杂多样性,其中的知识模型不易学习到,因此,单纯使用知识库(表1第1列)是要比单纯使用文本库(表1第2列)效果要好;但是也能看到,在50%的知识库上添加文本库,模型的效果得到了提升,这说明文本库也可以作为知识库的补充,以进一步提升模型性能,符合我们的预期;另外,只使用50%的知识库(表1第3列)时,模型的效果并没有降低50%,这可能是因为知识库涵盖的知识范围太大,而其中大部分知识可能与问题无关,因此下一步可以考虑针对具体任务和问题对知识库中的知识进行过滤.
其次,通过对比其他模型,UTMCQA加入命名实体识别、句法分析、关系抽取任务后,模型在两个信息源上的效果均得到提升,这说明本文选取的辅助任务确实可以普适性地提升模型对文本的深层次理解,有助于模型在后续阶段正确地回答问题.
为了更好地判断各个模块对模型的影响,我们在BERT输出的基础上把UTMCQA框架中涉及语义分析的任务做了统一的消融实验,分别设置如下实验:仅进行命名实体识别任务(表2第1行),进行命名实体识别和句法分析任务(表2第2行),进行命名实体识别、句法分析和关系抽取任务(表2第3行),任务全部涉及(表2第4行).数据表明,命名实体识别,句法分析,关系抽取等对模型提升都是有贡献的,各模块完全整合的模型比缺失模块的模型性能更好.通过进一步的分析,我们得出以下结论:1)知识库越完备,模型的效果提升越高,说明引入外部的结构化知识库有助于回答复杂问题;2)加入句法分析和关系抽取后的模型性能有提升,这也表明了复杂问句中的深层语义信息对于推理出复杂问题的答案有很大帮助.
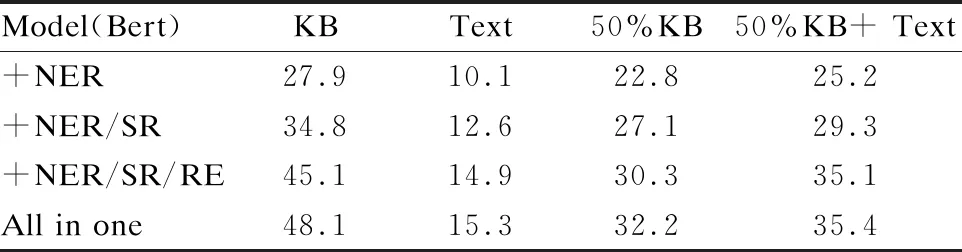
表2 基于BERT模型上的多任务消融实验结果
4.6 错误分析
我们随机挑选了100个UTMCQA框架在ComplexWebQuestion数据及上测评时P@1=0的问题.发现并总结出如下几类难以处理的问题类型:穷举类问题(54%):如“what countries fall in Eastern Europe and the country calling code is smallest?”其需要先列举出东欧地区的城市再进行相关计算,而本系统倾向于少量手工,缺少一些预定义规则来学习此类问题.否定类问题(12%):如“What music genre was don′t by the singer who wrote the song Whatever Gets You Through the Night sing?”此类问题的答案往往倾向于肯定回答而非否定.其他(32%):无约束类型,如“Which country with a population of 10,005,000 speaks Portuguese ? ”;少部分问题没有检测到实体,以及一部分聚合问题;编码错误等.
5 总 结
本文通过预训练模型BERT统一训练了命名实体识别,句法分析,关系抽取等任务,并将语义相似作为启发信息寻找知识库和文本库的相关实体,通过队列算法动态扩展子图,最后在子图的广度范围内,选择实体集合中最优的实体,作为最终答案.实验结果表明,与现有的解决方案相比,本文的UTMCQA框架具有更强的表达能力,在精度上优于最新的竞争对手.未来我们将针对错误分析中的错误类型,设计更多的启发式算法,改进模型的性能.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
汽车工程(2022年3期)2022-04-07
北京大学学报(自然科学版)(2022年1期)2022-02-21
科学导报·学术(2020年26期)2020-10-21
青年文学家(2016年32期)2016-12-23
长江学术(2015年1期)2015-02-27
——基于与QuestionPoint的对比
新世纪图书馆(2014年11期)2014-02-23
读写算·高年级(2009年3期)2009-11-16
意林(2009年12期)2009-02-11
