
一种面向异构边缘架构的实时高能效图像分类任务划分策略
2021-08-24 03:31杨晶晶薛明浩王继禾
小型微型计算机系统 2021年9期
杨晶晶,薛明浩,王继禾
1(西安交通大学 机械结构强度与振动国家重点实验室,西安 710049) 2(北京航空工程技术研究中心,北京 100076) 3(西北工业大学 计算机学院,西安 710129)
1 引 言
近年来,神经网络在众多领域都取得了很大的进展.与此同时,边缘设备的快速发展也在一定程度上推动了轻量级神经网络的研究[1].然而,一般的神经网络在训练过程中并没有考虑到具体的应用场景.事实上,在某些特定的应用场景中,神经网络处理的数据存在很大的偏差[2],即某些类别的数据在整个数据集中出现的频率相对较高.如果使用通用神经网络处理这样的数据集,那么对于低频和高频类别的评估则近乎相同,无法体现出数据的特异性.此外,网络模型的分类效果与模型的规模有关.分类类别越多的网络,复杂度也越高,越不适合部署在资源有限的边缘设备上[3].
目前,学界对于在边缘设备上高效部署神经网络开展了一定的研究工作.Mohd等人[4]尝试在异构环境上实现高效部署神经网络,提出了任务划分的思想,根据应用场景将数据进行划分.在异构边缘设备的前端(CPU)和后端(GPU)采用两种低功耗、高精度的网络模型[5]分别处理高频和低频数据.但是,由于异构边缘设备前后端之间的的处理性能差异较大[6],并且前端CPU在处理神经网络训练任务以外,还需要处理其他实时任务,因此如何根据CPU和GPU的计算资源在前后端之间合理分配工作负载是亟待解决的问题.
本文在任务划分理论的基础上,提出了一种根据边缘异构设备前端负载情况动态进行任务分区的调度算法.该算法估计前端CPU一段时间内的利用情况,根据计算能力和资源占用的不同,分别将不同的负载动态分配给前端和后端,以提高执行效率.
本文的主要贡献有:
1)提出了一种实时任务CPU负载估计模型,即在某一周期时段内估计CPU的负载情况;
2)提出了一种实现异构边缘设备前后端动态负载均衡的任务分区策略;
3)对所提出的策略进行了实验评估,并与传统策略进行对比,在不影响分类精度的情况下,能耗上降低了31.4%,实现了高性能.
2 相关概念
2.1 异构边缘设备
近年来,智能手机等移动设备的广泛应用推动了边缘设备的加速发展.边缘设备在使用过程中所产生的数据量巨大,仅凭中心化的服务器平台难以做到数据的高效处理[7].为了提升边缘设备的数据处理能力,一些硬件制造商在传统边缘设备中增加了额外的处理单元,异构边缘设备应运而生[8].异构边缘设备通常由通用处理单元(CPU)和专用处理单元(例如GPU)组成,分别称为前端和后端.虽然边缘设备所占有的存储容量和资源有限,但其高性能和低功耗的优势使得在边缘设备上部署神经网络成为可能[9].
2.2 神经网络
运行神经网络需要消耗大量的计算和内存资源,这使得在资源受限的边缘设备上部署神经网络困难重重.MobileNet[10]和ShuffleNet[11]是适用于移动和边缘视觉设备的高效卷积神经网络.MobileNet通过使用深度可分离卷积来构建轻量级网络,它将传统卷积划分为点卷积和深度卷积两部分,大大降低了参数的数量,提升了网络模型的效率.但是,MobileNet所产生的大量1×1点卷积同时也增加了计算的复杂度,为了改善这一问题,ShuffleNet通过添加组卷积来降低计算复杂度,同时还增加了一个shuffle层用于帮助信息在不同特征组之间的流动.
2.3 Hot/Cold-Class
通常,在训练神经网络的过程中,所使用的训练集都是均匀的,即每个类中训练数据的数量是相差无几或者相同的,这是为了让网络可以兼顾到数据集中所有类别的数据,从而使网络具备判断所有类别数据的能力.但是在某些实际场景下,网络所要处理的数据可能是不均匀的,也就是有一定的偏置性[12],即可能某一类数据或者几类数据出现的频率很高,剩余类别数据出现的频率较低,比如将神经网络在医学胸片影像分析领域的应用,由此提出了Hot/Cold-Class的概念.
所谓Hot-Class就是在特定场景下出现频率较高的一种或者几种类别的数据,而剩余的出现频率较低的类别则统一归为Cold-Class,将数据以这种形式进行划分的目的是充分利用异构嵌入式设备的特点.一般情况下,通用处理器的性能相对较低,只能进行较小规模的运算,不足以运行针对所有类别数据的完整的网络[13],而专用处理器则针对某些特定的数据具有较高的性能,有能力运行一个能够分辨所有类别的完整的网络.根据异构嵌入式设备的这个特点,将整个神经网络的训练任务进行划分[14],将异构嵌入式设备中的CPU作为前端,部署一个较为简单高效的网络,该网络在训练时只负责Hot-Class数据,即网络仅识别Hot-Class数据;把异构嵌入式设备的专用处理器(GPU)作为后端,部署一个更为复杂的网络,该网络在训练时负责所有类别的数据,即可以识别所有类别的数据.
样本置信度是正确划分Hot-Class和Cold-Class的关键.通常,图像分类的每个输出结果均是一个One-Hot[15]向量,向量中元素的值表示某个类出现的概率,值越大,对应类出现的概率也越大.One-Hot向量应该相对清晰,即向量中的最大值应远远大于其他值.One-Hot向量越清晰,分类效果越好.在信源中,需要考虑所有可能情况的平均不确定性,假设信源符号有n个值:U1,U2,…,Un每个值对应概率为:P1,P2,…,Pn,且各种符号相互独立.所有符号的平均不确定性则为各个符号不确定性-logPi的统计平均值(E),称之为信号熵.式(1)为信号熵的计算公式.
(1)
式(1)可以准确满足网络输出的一个One-Hot向量,与此同时,信息熵是度量信息的指标,信息熵的值就越低,一个系统越有序,某个类别出现的概率就越高,说明该模型分类效果较好.
(2)
式(2)是典型的熵值计算公式,其中C表示所有可能的类,xi表示每个类的可能性.但是式(2)的自然性质会引起熵值范围的不确定性,因此有学者将熵值限制在[0,1]范围内,修正后的公式如式(3)所示.
(3)
传统策略中没有进行前后端之间的调度,即不考虑前后端之间的负载情况,其根据样本置信度将数据进行划分,数据在被送入前端网络时,在整个被处理数据中占多数的Hot-Class数据将会被前端网络直接进行处理,得到结果,然后将剩余的Cold-Class数据转移至后端(GPU),通过后端更加复杂的网络对数据进行更加精细的处理,从而得到最终的结果.
由于传统策略并没有考虑到前后端之间的负载差异,前端的处理能力较弱,如果将所有的数据都送入前端进行处理,前端的负载会很重,而处理能力很强的后端却仅处理在数据中占少数的Cold-Class数据,这就导致了前后端之间资源利用的失衡.
3 负载均衡的分区调度
3.1 异构实时任务的模型假设
假设神经网络训练任务的训练样本数为N,分区调度过程中,动态分配给前端CPU的样本数为nCPU,则后端GPU需要处理的样本数量nGPU=N-nCPU.
假设CPU和GPU处理一张图片的时间单元是恒定的,分别为tCPU和tGPU,则CPU和GPU处理完对应数量样本的时间单元分别为nCPUtCPU和(N-nCPU)tGPU.
由于异构边缘设备中,神经网络的训练需要满足一定的实时性要求,因此前后端样本处理时间应满足如下约束条件:
|nCPUtCPU-(N-nCPU)tGPU|≤δ
(4)
其中δ为规定的延迟要求.
假设前端CPU在处理神经网络训练任务以外,还需要处理n个实时任务,K={k1,k2,…,kn},每个任务ki表示为(Ci,Di),其中Ci为任务ki的到达时间,Di为任务ki的死限,Ci≤Pi,且任意时间段内,处理任务所需要的负载量不超过CPU的总负载量.

3.2 实时任务CPU负载估计模型
将神经网络训练样本分配给CPU之前,需要周期性地对CPU进行负载估计,通过计算某一周期内其他实时任务所占用的CPU利用率,可以得出该周期内CPU的剩余利用率,这部分剩余利用率就用于神经网络的训练任务.如图1所示,假设以时间间隔Δ为周期对CPU进行负载估计,在某一周期t1~t2内,其中t2-t1=Δ,即t1为周期起始时刻,t2为周期终止时刻,假设CPU在t1时刻可知下一周期内需要处理的实时任务集合为K′⊂K,则需要估计K′中每一个实时任务的CPU利用率.
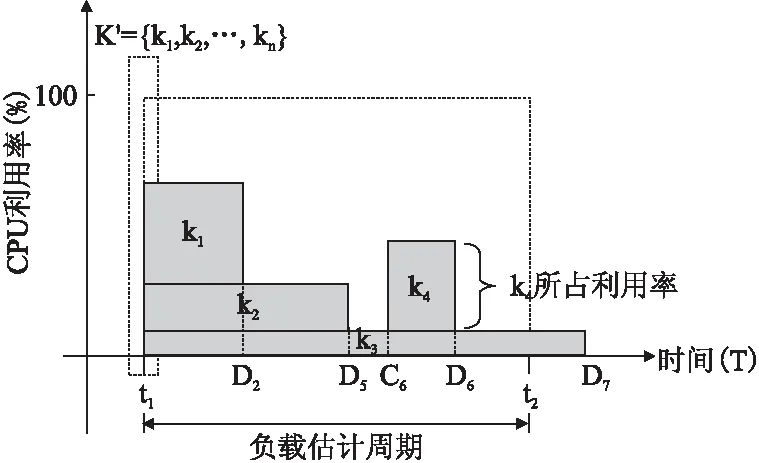
图1 负载估计示意图
当任务ki的到达时间Ci≤t1且死限Di≤t2时,表明ki为CPU正在处理的实时任务且需要在该周期处理结束,此类任务集合用K(1)⊂K′表示.K(1)任务集合的最小CPU利用单元U(K(1))计算公式如式(4)所示.
(5)
当ki的到达时间Ci>t1且死限Di≤t2时,表明ki为该周期内新到达的任务且需要在该周期内处理结束,此类任务用集合K(2)⊂K′表示.K(2)任务集合的最小CPU利用单元U(K(2))计算公式如式(5)所示.
(6)
当ki的到达时间Ci≤t1且死限Di>t2时,表明ki为CPU正在处理的任务且死限在后续周期内,此类任务用集合K(3)⊂K′表示.K(3)任务集合的CPU最小利用单元U(K(3))计算公式如式(6)所示.
(7)
当ki的到达时间Ci>t1且死限Di>t2时,表明ki为该周期内新到达的任务且死限在后续周期内,此类任务用集合K(4)⊂K′表示.K(4)任务集合的CPU最小利用单元U(K(4))计算公式如式(7)所示.
(8)
在周期t1~t2时间段内,CPU完成任务集K′的最小利用单元为Umin(Δ)=U(K(1))+U(K(2))+U(K(3))+U(K(4)),则该周期内CPU剩余最大可利用时间单元Space(Δ)=Δ-Umin(Δ),即为图中阴影线所示部分.
3.3 负载均衡算法
由于前端CPU处理能力较弱,并且还需要处理额外的实时任务,如果所有神经网络数据都进入前端处理,前端负载会很重,而后端处理能力很强,但它只处理数量占少数的Cold-Class数据,这就导致资源利用很不平衡.本文提出了一种在前后端之间动态任务分区的算法,该算法根据负载估计模型,每隔一定周期估计周期内的CPU剩余负载,据此分配前后端处理的数据量.算法描述如下:
步骤1.根据负载估计模型,在某一周期开始时估计Δ时间段内,神经网络任务以外任务集所占用的CPU最小利用单元,则剩余可用于神经网络训练的利用单元达到最大,即为Space(Δ);
步骤2.在不超过Space(Δ)的前提下,将部分训练数据分配给前端CPU,其余数据分配给后端GPU,前端处理延迟为front_delay,后端处理延迟为back_delay;
步骤3.判断前后端是否满足实时条件|front_delay-back_delay|≤δ,其中δ为延迟要求.若满足条件则得到数据的分区均衡点lbalance;若不满足条件则以Symbol为步长,调整前后端数据分区;
步骤4.在下一周期重复步骤1-步骤4.
算法1.负载均衡算法
输出:lbalance
1.Initializeallvariables
2.foreachperiodt2→t1do
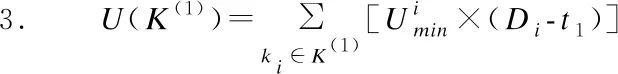
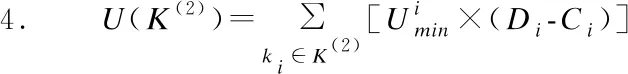

7.Umin(Δ)=U(K(1))+U(K(2))+U(K(3))+U(K(4))
8.Space(Δ)=Δ-Umin(Δ)
9.front_load=Space(Δ)
10.forfront_load≤Space(Δ)do
11.lbalance=front_load
12.if|front_latency-back_latency|≤δ
13.returnl_balance
14.break
15.else
16.front_load=front_load-Symbol
17.back_load=back_load+Symbol
18.endif
19.endfor
20.endfor
4 实验设计与结果分析
4.1 实验环境
本文所使用的服务器端配备有一块32GB的DDR4内存,一块12GB的DDR5显存、384位宽的英伟达TitanXP显卡,6核12线程的英特尔酷睿i7-8700k处理器.实验中所使用的数据集为Tiny-ImageNet.Tiny-ImageNet来源于ImageNet数据集,但是相比于ImageNet,Tiny-ImageNet的数据规模更小.Tiny-ImageNet共有200个类别,每张图片为64×64的3通道RGB图像;而在ImageNet中,每张图片大小为224×224.由于异构边缘设备资源受限的特征,所部署的神经网络不能过于复杂,因此更加适合中小型数据集的训练.在本文实验中,随机选取10个类别作为Hot-Class,其余类别作为Cold-Class.实验中使用的异构边缘设备为英伟达JetsonTX1开发版,配备有4GBLPDDR4内存,4核ARMCortex-A57处理器,256核Maxwell显卡.此外,还使用了神经网络框架Pytorch来实现网络架构.实验对所提出的策略进行了评估,并在实时性与能耗方面与传统的策略进行了对比.
4.2 实验评估
4.2.1 样本置信度与负载均衡
在本文中,我们通过实验来确定样本置信度的阈值,用以划分数据.通过前端网络分别对500个Hot-Class和500个Cold-Class数据进行处理,得到了样本置信度的分布情况,如图2、图3所示.从图中可以看出,Hot-Class和Cold-Class样本的置信度分布差异较大,Hot-Class样本的置信度分布区间较为集中,而Cold-Class样本的置信度分布则趋于均匀,大多数置信度区间内的样本数量相近.
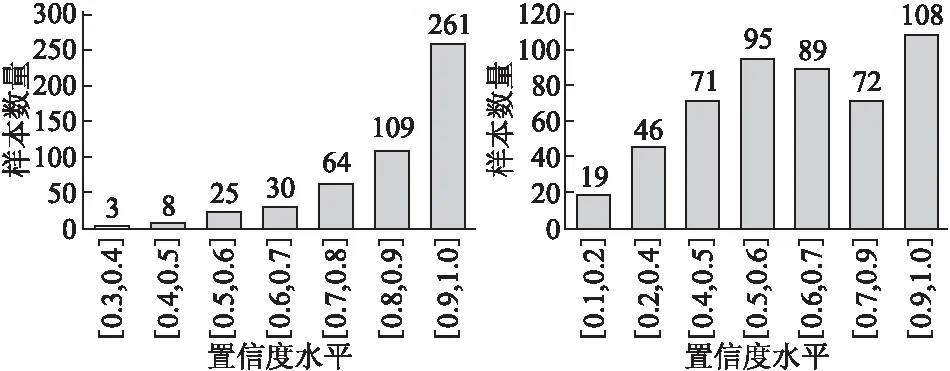
为了确定样本置信度阈值,实验对几种不同的测试数据进行了对比分析.图4展示了3个不同测试样本的置信度分布情况,每个测试样本中Hot-Class数据所占比例分别为60%、80%和100%.从图中可以看出,当500个测试样本均为Hot-Class数据时,置信度大于或等于0.7的样本数量为452,与网络模型的精度大致相同(模型精度约为98%),与此同时,Hot-Class样本占比60%和80%时也是如此.所以本文选取0.7作为样本的置信度阈值.
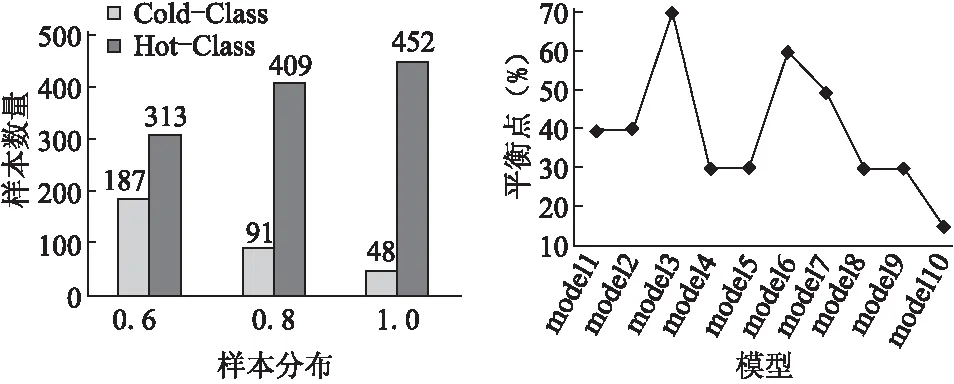
此外,本文根据算法1对负载均衡进行了验证.对于不同前端网络模型,我们通过实验得出了对应的负载均衡点,具体数据如图5所示.在后续的对比实验中,我们将根据负载均衡点,分别为前端和后端分配不同数量的图像,以最大程度发挥前端和后端的优势,提高资源利用率.
4.2.2 网络验证
尽可能满足边缘设备CPU有限的计算资源是前端网络设计的目标,因此前端只需要处理Hot-Class数据.本文对10种小型网络模型进行了比较,结果如表1所示.在模型1-7中,只包含一个卷积层,其余的模型均包含两个卷积层.此外,全连接层的数量也会对网络精度产生一定影响.
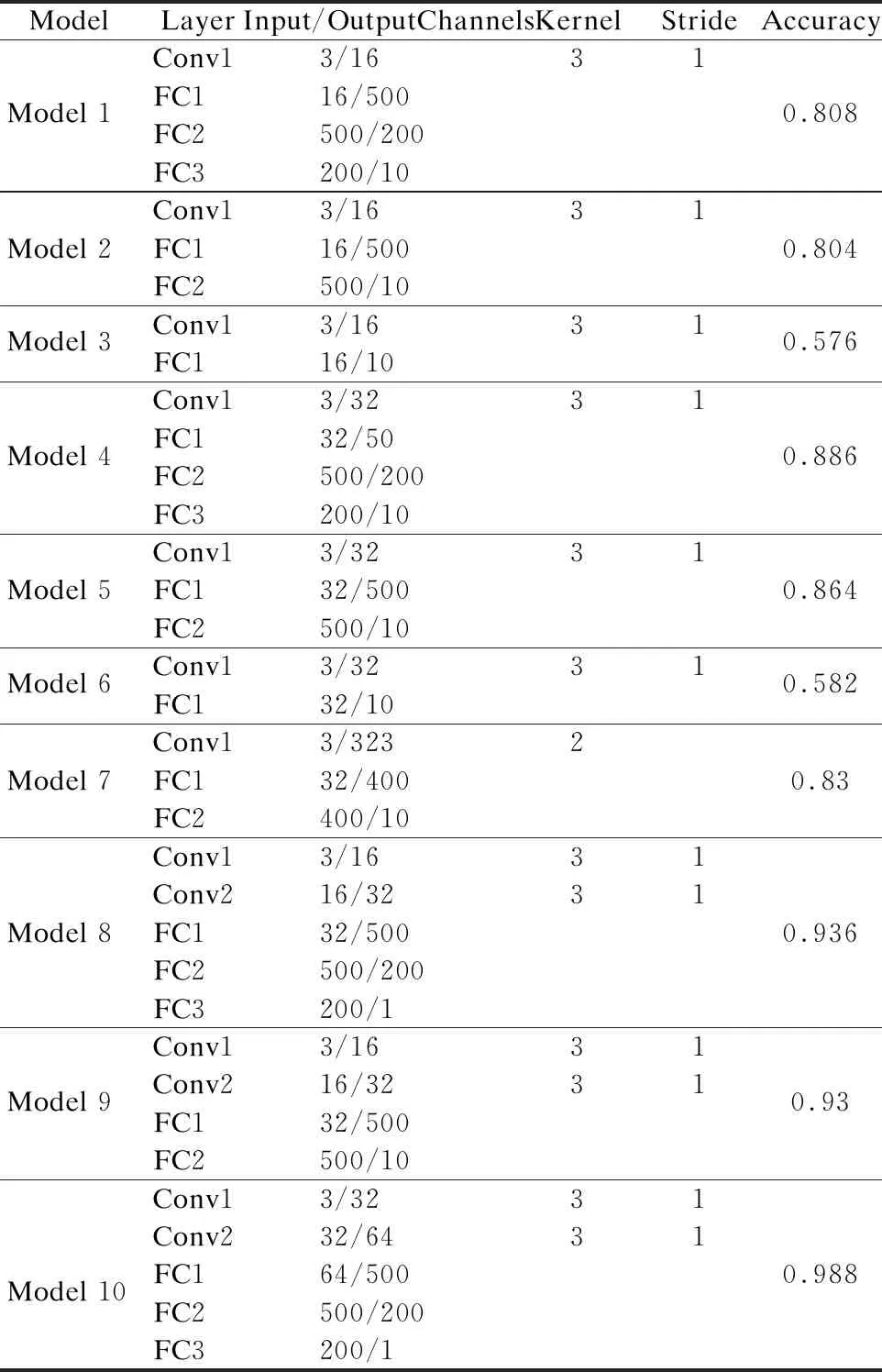
表1 前端网络结构和精度表
实验中设计的网络模型较为简单,能够满足异构边缘设备有限的计算能力和资源需求.从表1中可以看出,模型10具有最高的精度,达到了98.8%,但是其对应的网络结构也相对复杂,包含3个全连接层和两个卷积层.在选择网络模型时,需要考虑时延、能耗等因素,每个选择都要根据特定的边缘设备和应用场景.本文中,我们选择模型7部署到前端,其只包含两个全连接层和一个卷积层,相比于模型10,更为轻量级.虽然模型7的精度低于模型10,但其具有更优的时延和能耗.
后端基于ShuffleNet进行网络设计,我们调整了网络的输入,同时去掉了一些不必要的部分,以满足后端的需求.通过实验训练,最终得到了适用于Tiny-ImageNet数据集的网络模型.
基于得到的前后端网络模型,我们分别对本文策略和传统策略进行了对比实验,得到了两种策略在Tiny-ImageNet数据集上的分类精度,如表2所示.可以看到,相较于传统策略,本文策略在分类精度上提高了1.1%.

表2 分类精度对比
4.2.3 实时性和能耗
在异构架构中训练神经网络任务需要满足实时性要求.本文分别使用20个包含不同图像数量的测试集对本文提出的策略和传统策略进行了实时性验证,其中Hot-Class样本数量占样本总数的80%,验证结果如表3所示.从表中可以看出,对于实验中所用的绝大部分训练集,本文所提出的策略均能很好地满足实时性的要求.而在传统策略中,需要在前端先完成Hot-Class数据的处理,再将Cold-Class数据送入后端进行处理,当图像数量较多时,很难满足实时性要求.

表3 实时性验证对比
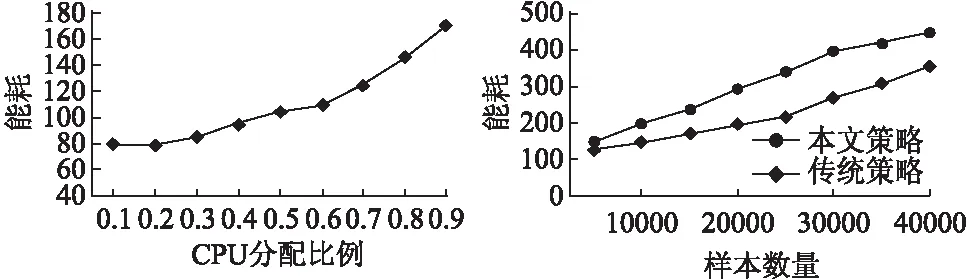
在本文中,我们通过实验对能耗进行了评估.图6为10000张图像的样本集合在不同GPU分配比例时的能耗情况.从图中可以看出,随着样本数量在GPU上分配比例的增加,神经网络训练的能耗总体上也呈现出上升的趋势.图7为本文策略和传统策略在处理不同数量样本集合时的能耗.可以看到,传统策略在处理不同数量的样本时,其能耗均要高于本文中所提出的策略,主要原因是因为前端CPU的性能较差,不适合做大量的卷积操作,从而导致处理时间过长,能耗大.相比之下,GPU由于核心众多,在卷积运算方面具有天然的优势.结果表明,与传统策略相比,本文策略的能耗降低了31.4%,实现了高性能.
5 结 语
本文根据异构边缘设备前后端处理能力差异很大的特点,在Hot/Cold-Class理论的基础上,提出了一种实现前后端之间动态负载均衡的任务分区算法.实验表明,本文所提出的算法可以在相对低延迟和低功耗的情况下,根据前端CPU负载的变化,动态地进行任务的分区,有效解决了异构边缘设备中前后端资源利用失衡的问题.
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
中国交通信息化(2022年7期)2022-10-27
计算技术与自动化(2022年2期)2022-07-04
小型微型计算机系统(2022年4期)2022-05-09
小学教学研究(2022年5期)2022-04-28
福建基础教育研究(2019年11期)2019-05-28
通信产业报(2016年44期)2017-03-13
中国科技纵横(2016年20期)2016-12-28
雕塑(1999年2期)1999-06-28
雕塑(1996年2期)1996-07-13
