
基于大数据的非常规油气藏产能预测模型研究
2021-08-23 15:11任宗孝徐建平韩忠霞余坚强
石油化工应用 2021年7期
冯 震,任宗孝,徐建平,韩忠霞,余坚强
(1.西安石油大学石油工程学院,陕西西安 710065;2.中国石化集团中原石油勘探局有限公司钻采社会服务中心,河南濮阳 457001;3.长城钻探钻井三公司,辽宁盘锦 124010)
非常规油气藏是常规能源有效的接替资源,是全球油气供应可持续发展的能源保证。但由于非常规油气藏特殊的地质条件及大规模压裂工艺的实施导致储层出现多种跨尺度渗流介质,使得油气藏渗流规律异常复杂,传统方法很难准确预测非常规油气藏产能。此外,非常规油气藏的开发和生产过程中产生了大量的数据,如何合理有效利用这些数据建立数据驱动的生产性能统计方法也是目前亟待解决的问题。本文就以上问题调研了基于大数据分析(Big Data Analysis)建立产能递减模型进行开发效果预测的方法。
1 产能模型的介绍
通过调研可知,非常规油气藏产能预测模型方法主要分为三类:(1)机理模型产能预测方法;(2)递减曲线产能预测方法;(3)基于大数据的产能预测方法。
机理模型产能预测方法是在一定假设的基础上建立的,不能完全反映真实地层渗流规律及油气井产能大小。递减曲线预测方法往往假定递减率为常数,但实际开发过程中递减率是随时间变化的变量。基于大数据的产能预测方法多使用递减曲线分析方法和机器学习方法(ML),考虑非常规油气藏地质数据、工程数据及生产数据,可揭示众多参数对油气井产能的影响规律。大数据分析方法对勘探开发过程中的原始数据进行计算,不存在任何机理和模型假设。目前,基于大数据建立非常规油气藏产能预测模型在国外得到了一定的发展,但国内学者研究应用较少。因此,有必要加强该方向的研究。
2 递减曲线分析
递减曲线分析(DCA)方法以生产数据为基础,对未来的产量进行预测,是一种基于生产数据的经验回归方法。在非常规储层中,DCA 技术已被广泛应用于预测页岩油气井的未来产能[1,2]。常用的递减曲线有Arps递减曲线、拉伸指数递减(SEDM)模型、Duong 模型和Logistic 增长模型等。这些模型的简要说明如下:
2.1 Arps 递减模型
Arps 模型由Arps(1954 年)提出,用于估算常规油气井的最终采收率。该模型假设井底流体、储层情况及生产作业不发生明显变化。Arps 模型可表示为:
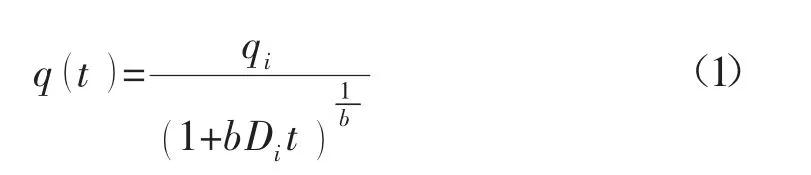
式中:q (t)-t 时刻的速率,桶/每天;qi-初始速率,桶/每天;Di-初始下降速率,月-1;b-双曲下降系数,无量次;t-时间,月。
2.2 拉伸指数递减(SEDM)模型
拉伸指数递减(SEDM)模型由Valko(2009 年)提出,是一种类似于Arps 模型的递减曲线模型,可用于计算页岩气井的不稳定流动状态。拉伸指数递减模型可表示为:

式中:q(t)-t 时刻的速率,桶/每天;qi-初始速率,桶/每天;τ-特征松弛时间,月;n-指数参数,无量纲;t-时间,月。
与边界控制流相比,该模型会导致瞬态流动,生产需要超过一定年限才能准确地估计参数。SEDM 模型在确定未知参数时也需要进行复杂的计算。
2.3 Duong 模型
Duong 模型由Duong(2010 年)提出,是一种基于页岩气藏长期线性流动的经验推导递减模型,该模型可以准确描述裂缝主导的产量递减特征,适用于非常规油气藏的产量计算。Duong 模型可表示为:
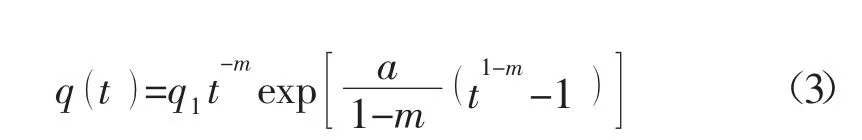
式中:q (t)-t 时刻的流量,桶/每天;q1-第一天的流量,桶/每天;a-截距常数;m-斜率参数;t-时间,月。
Duong 模型使用统计方法来分析储层产量,得到一个预测范围,将预测结果以P90-P50-P10 的形式分布(见图1),具有较高的准确性。但在数值模拟的过程中Duong 模型不能反映页岩油气流动特征。
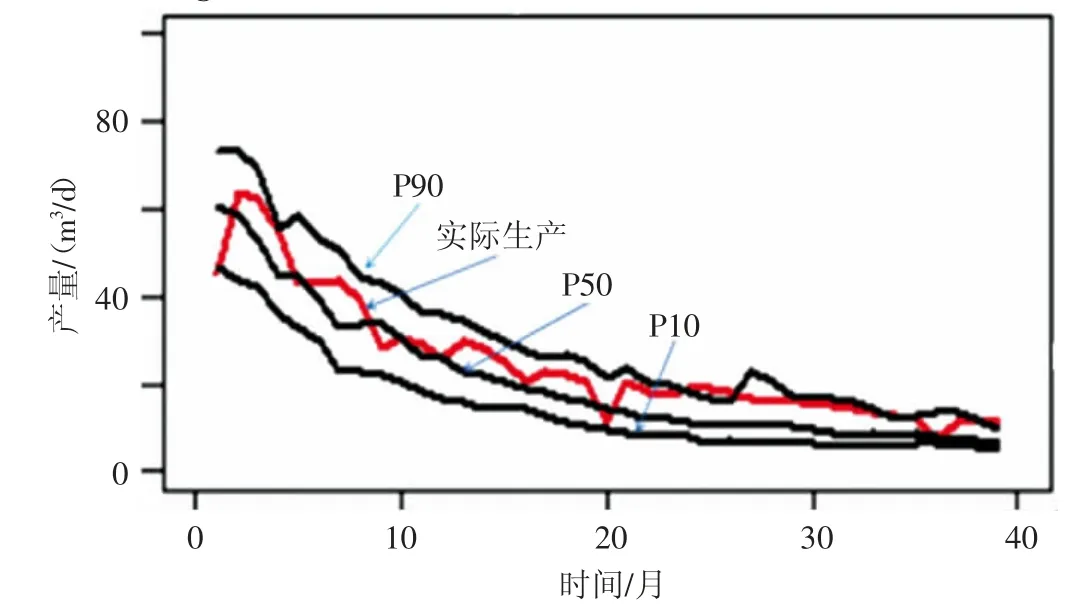
图1 Duong 方法与实际值的比较
2.4 Logistic 增长模型
Logistic 增长模型由Clark 等(2008 年)提出,是一种基于极低渗透率储层预测油气井产量的模型。Logistic 增长模型可表示为:
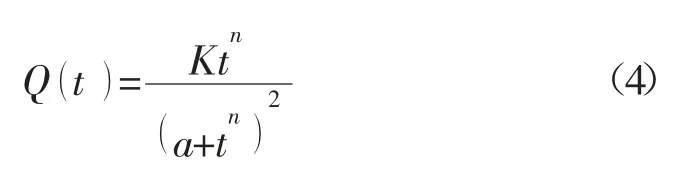
式中:Q-累积产量;t-时间;n-双曲指数;a-常数;K-承载能力。
Logistic 增长模型可以准确地预测井内流体的动态变化过程并得到最终采收率。该模型还可以根据经验预测非常规油气藏的储量。但Logistic 模型不能预测非实物价值。
递减曲线分析方法已被大量应用于非常规油气藏产能预测过程。然而,当使用单一的方法来预测产量和最终采收率时,很难得到一个准确的结果。由于这些方法本身存在局限性,无法完全准确的表达非常规油气藏的实际渗流情况。为了改善这个问题,一些学者在非常规油气藏产能预测过程中引入了机器学习的方法建立新的模型,将工程数据、生产数据、地震和测井数据融入其中,使预测精准度大大提高。
3 机器学习方法
机器学习(ML)技术在油气勘探和生产领域的应用较广。这些技术已被研究人员用于优化生产工艺和井位[3]、预测产量[4]、进行敏感性分析和历史匹配[5]。
机器学习(ML)方法可通过自动化过程建立分析模型,几乎不受人为的影响。模型可以自动理解数据并进行分类和形成决策。ML 技术能够有效地优化决策过程和提高操作性能,流程(见图2)。
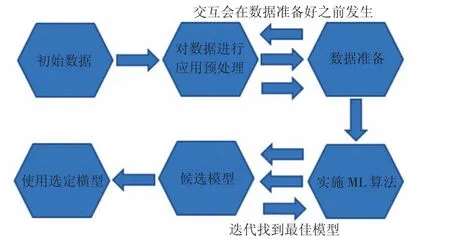
图2 机器学习方法的流程图
ML 算法能够科学地表达自变量和因变量之间的相互关系。为了提高生产预测效果和分析结果的准确性,选择恰当的机器学习方法是十分重要的。几种常用的方法概括如下。
3.1 神经网络(ANN)
人工神经网络技术源于对哺乳动物中枢神经系统的研究。每一个网络都是由多个相互连接的神经元组成,按层排列。当某个条件发生时,这些神经元根据其加权输入交换消息,加权输入通过线性组合被加在一起,最后通过激活函数计算单位的输出。该过程由五个基本要素组成:一组输入向量(xi)、一组加权链接(wi),一个加法器(Σ)、一个激活函数(f)和输出标量(y)。人工神经元(见图3)。
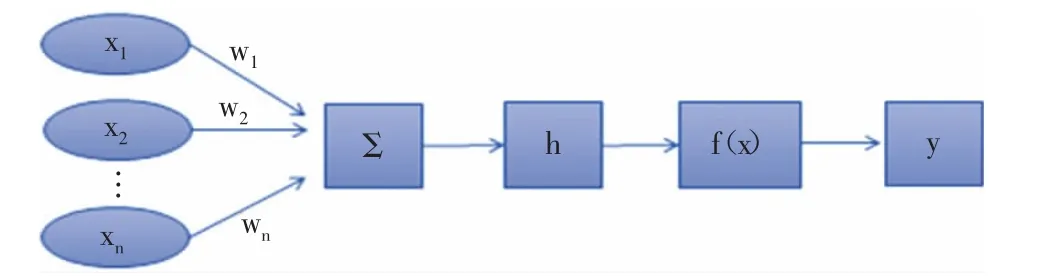
图3 人工神经元模型
这种模型中,信息沿单一方向流动(输入层-隐藏层-输出层)利用了多层排列方式,可进行多层处理(见图4)将数据通过多层思维过程进行表示。
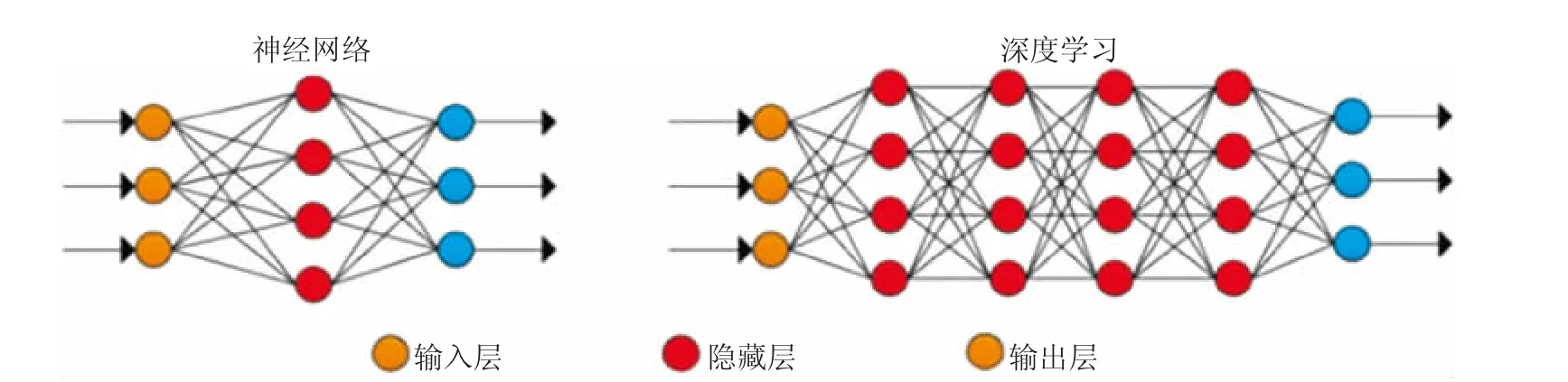
图4 神经网络(ANN)技术示意图
3.2 随机森林(RF)
随机森林是一种基于集成的机器学习算法。该算法从整个训练数据集随机抽取训练数据和描述性变量,构造了多个二叉决策树。在形成随机森林的整棵决策树中,每个个体单元的选择数量不同,并且对每棵决策树的选择分类值预测也不同。对单个单元的预测概率进行估算时利用随机决策树方法可以修正决策树对训练数据集的过拟合倾向,从而提高预测的准确性。
3.3 支持向量机(SVM)
支持向量机(SVM)多应用于与分类和回归有关的问题。对于一组给定的训练数据,该算法可在具有无限维数的空间中确定一个或一组可以对数据进行分类的超平面,在几个超平面中选择最好的一个。决策函数由一组训练数据点组成,称为支持向量。这些训练数据点靠近超平面,对超平面的位置和方向有重大影响。SVM算法除了可以将输入数据间接映射到高维特征空间进行线性分类外,还可以进行非线性分类。当特征数量远远超过样本数量时,为了避免过拟合问题,必须选择恰当的核函数,这时正则化就变得非常重要。
4 非常规油气资源产量预测技术研究
Aditya 等在2017 年[6]利用公开的Eagle Ford 地层数据,将Arps、拉伸指数递减(SEDM)、Duong 等递减曲线模型与相关完井参数(纬度、经度、完成长度、总垂直深度、支撑剂和压裂液量)结合起来,建立了一种新的预测建模,可以在潜在的新井位快速生成递减曲线。并且使用随机森林(RF)、支持向量机(SVM)等方法来模拟井的产量递减行为。利用递减曲线模型和机器学习结合的方法来对不同的参数变量进行排名,优选出最具影响力的参数,从而更好地指导生产。研究发现,与使用机器学习的其他模型相比,使用SVM 的SEDM 更适合预测流量。此外,最具影响力的预测指标是初始流速,支撑剂总量、总垂直深度排名第二、第三。
Luo 等在2019 年[7]利用随机森林(RF)和深度神经网络(DNN)算法建立了一种非线性模型,用来预测6个月的累积石油产量。考虑到的关键参数有等地质参数结构深度、总有机碳(TOC)、厚度的形成、层的平均厚度、方解石层数等,计算井在Eagle Ford 生产力的影响。此外,完井参数(支撑剂用量、压裂液类型、测量深度、射孔长度、原油重力、完井及生产日期等)都是描述Eagle Ford 油井产能的关键输入参数。研究表明,在预测能力方面,非线性模型表现较好,这是由于输入和输出变量之间的复杂关系导致非线性模型模拟的生产情况更切近实际。近几年来学者们基于大数据建立产能预测的一些研究(见表1)。

表1 非常规油气资源产量预测技术研究
5 结论
(1)基于大数据的产能预测模型结合了油气藏地质数据、工程数据及生产数据,尽可能多的使用了所有与生产有关的数据,极大的提高了模型预测的精确性。
(2)基于大数据的产能预测模型可从数量庞大的输入参数中优选出影响产能的最主要几个影响因素。
(3)大数据在石油工业中的应用作为较新的研究方向,有很多亟待解决的问题等待着后来者去探索研究。
(4)通过人工智能算法让“海量”数据“自己说话”,客观真实揭示非常规油气藏开发规律,对我国非常规资源的高效快速开发具有重要指导意义。
猜你喜欢
黄河之声(2022年10期)2022-09-27
教育教学论坛(2022年29期)2022-09-01
出版人(2022年8期)2022-08-23
——以孤岛1号凹隆域低部位为例
油气地质与采收率(2022年4期)2022-07-30
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
化工管理(2021年8期)2021-01-09
英语文摘(2020年6期)2020-09-21
考试周刊(2017年57期)2018-01-29
