
On Distributed Object Storage Architecture Based on Mimic Defense
2021-08-21 09:36HaiyangYuHuiLiXinYangHuajunMa
China Communications 2021年8期
Haiyang Yu,Hui Li,*,Xin Yang,Huajun Ma
1 Shenzhen Graduate School,Peking University,Shenzhen 518055,China
2 Shenzhen Key Lab of Information Theory & Future Network Arch.,Shenzhen 518055,China
Abstract:With the advent of the era of big data,cloud computing,Internet of things,and other information industries continue to develop.There is an increasing amount of unstructured data such as pictures,audio,and video on the Internet.And the distributed object storage system has become the mainstream cloud storage solution.With the increasing number of distributed applications,data security in the distributed object storage system has become the focus.For the distributed object storage system,traditional defenses are means that fix discovered system vulnerabilities and backdoors by patching,or means to modify the corresponding structure and upgrade.However,these two kinds of means are hysteretic and hardly deal with unknown security threats.Based on mimic defense theory,this paper constructs the principle framework of the distributed object storage system and introduces the dynamic redundancy and heterogeneous function in the distributed object storage system architecture,which increases the attack cost,and greatly improves the security and availability of data.
Keywords:distributed object storage system; mimic defense;data security
I.INTRODUCTION
With the rapid development of the global economy and continuous technological innovation,cloud computing,big data,artificial intelligence,etc.are booming.With the development of Internet technology and the birth of rich media,data forms are various,such as images,video,audio,text,various office documents,etc.,and there is no correlation between data[1].
OSS(Object Storage Service),called object-based storage,is a method of solving and processing discrete units.On the other hand,it can provide data storage services based on objects in distributed systems.Object storage supports S3 or SOAP storage interface to provide external storage service[2],which can be directly used for the application.
The emergence of object storage brings good news to enterprises and individuals,which gradually migrate data to object storage.Object storage has gradually become the mainstream solution of cloud storage.Amazon released AWS S3(simple storage service)service in 2006[3].Because of its successful application,the rest style interfaces based on GET,PUT,POST and DELETE provided by S3 have gradually become the standard interfaces in object storage,and are gradually used by other enterprises.
Object storage is naturally suitable for storing unstructured data.More and more applications and enterprises use object storage.In recent years,distributed object storage has become the most widely used solution for cloud storage,such as Amazon S3(simple storage service),Google Cloud Storage[4],Openstack Swift[5]and so on.Object storage interface is often implemented based on HTTP(Hyper Text Transfer Protocol)or HTTPS(Hyper Text Transfer Protocol over secure socket layer)protocol.Compared with file storage and data block storage,object storage is more suitable for the Internet,and the advantage of object storage lies in this.Distributed object storage system takes object as the basic unit to manage,and provides Simple Object Access protocol(SOAP)or Representative State Transfer(REST)style storage interface to realize data storage service.This storage method based on object interface makes the system easy to share,cross platform and high performance[6].
Data security refers to the defense capability that the database has to protect data.It is used to prevent unauthorized disclosure,modification,or intentional or unintentional destruction of data[7].With the widespread use of distributed object systems,the security of the system becomes increasingly important.Accidents such as data leakage,data tampering,and data loss frequently occur in object storage systems,causing incalculable losses to individuals and system service providers[8].
To solve the problem of data security,measures such as access control technology,data information encryption technology and security management technology can be taken.The purpose of access control technology is to allow or deny a person or program the use of a resource.Data information encryption technology is to prevent the disclosure of user data information,data information encryption storage.Security management technology includes audit management,security threat and vulnerability management,and also needs to set up a special security management server.
Mimic Defense[9]is an active defense behavior.Since its idea has been applied in the cyberspace security field,it is often used as the abbreviation of cyberspace mimic defense(CMD).The mimic defense is a theory put forward by Wu Jiangxing,an academician of the Chinese Academy of Engineering,to prevent serious threats to the system caused by”unknown loopholes” by imitating the ”mimic phenomenon” in the biological world[9].
Dynamic Heterogeneous Redundancy[9](DHR)is a principle method for mimicry defense.It is based on the Dissimilar Redundancy Structure(DRS)in the reliability field and introduces multi-dimensional dynamic redundancy.It has high reliability of DRS and high security of mimicry at the same time[10].Due to the security of mimicry mechanism,the existing literature has applied it to router[11],web[12],storage[13]and other fields.
The foundation of DHR architecture is heterogeneity.The greater the difference in attributes between the executor sets,the less likely to have the same loopholes and the stronger the defense capabilities.Redundancy technology is a technology that uses component parallel models to improve system reliability.Through the combination of redundancy and heterogeneity,attackers who rely on a specific environment and platform cannot easily break the system.The dynamic transformation mechanism adds dynamics based on redundancy and heterogeneity.When one or more isomers are breached,after receiving the warning message,the dynamic transformation mechanism will regenerate new isomers to replace the currently attacked isomers.The information cannot be reproduced due to previous attacks and the environment.Then all the work the attacker did before will be wiped out.
Erasure Coding(EC),a data redundancy mechanism in distributed systems,has been widely researched and applied in data processing and other fields due to its high storage utilization and strong data availability[14].A(k,n)-threshold erasure code splits the original data intokparts,then generatesn(n > k)slices using a complex encoding algorithm,and finally stores them in different nodes.The original data can be recovered by using anym(m ≥k)slices.Whenm=k,this erasure code is a maximum distance separable(MDS)[15]code,which has the property of optimal storage utilization.In particular,the Reed-Solomon code is the most widely studied coding scheme that satisfies the characteristics of MDS in history.It has been used in actual large-scale distributed storage systems,such as Microsoft Windows Azur[16],Ceph[17],HDFS[18],etc.
This paper proposes a distributed object storage framework based on mimic defense and multiple ECs.The main contributions of this paper are as follows.
1)Mimicry modification of the system can be combined with the traditional security defense mechanism such as access control mechanism to further enhance its security.
2)The log of blockchain storage system is used to achieve the purpose of non tampering and traceability of logs.
3)Consistent hash[19]algorithm is used to distribute and locate data efficiently.
The remaining sections of this paper are structured as follows.Section II introduces the distributed object storage system model based on mimic defense.Section III introduces the system architecture design.Section IV introduces the functional module design of the system,and Section V analyzes the system through experimental simulation.Section VI gives the conclusion and future work.
II.SYSTEM MODEL
Distributed object storage systems usually store object data and object metadata separately,thereby separating the control flow and data flow of the system,so that the system has high throughput and high scalability[20].
2.1 Mimic Distributed Object Storage Model
Distributed object storage architecture generally consists of three parts:Client,Object-based Storage Device,and Metadata Server.Among them,the client provides users with a simple and easy-to-use storage service platform,and interacts with metadata servers and object storage devices.The metadata server is responsible for the storage and management of object metadata and provides functions such as object location service and permission access control for clients.The object storage device is the core of the object storage and is responsible for managing persistent objects.When the object is stored,the device provides an object access interface for the client and completes data reading and writing for the client.
The mimic distributed object storage model adds multiple erasure codes,dynamic random transformations,and other functions,and uses multiple redundancies and active defense mechanisms to increase the redundancy and the uncertainty of data storage,to respond to attacks,and improve the system security.
In the system,data management and metadata management are separated.The monitor is added to the system.And data management nodes and metadata management nodes are dynamically configured.The system provides users with a mimic object service interface.The system model is shown in Figure 1.Among them,the mimic object service interface realizes redundancy and heterogeneity,and the monitor realizes the dynamic configuration.
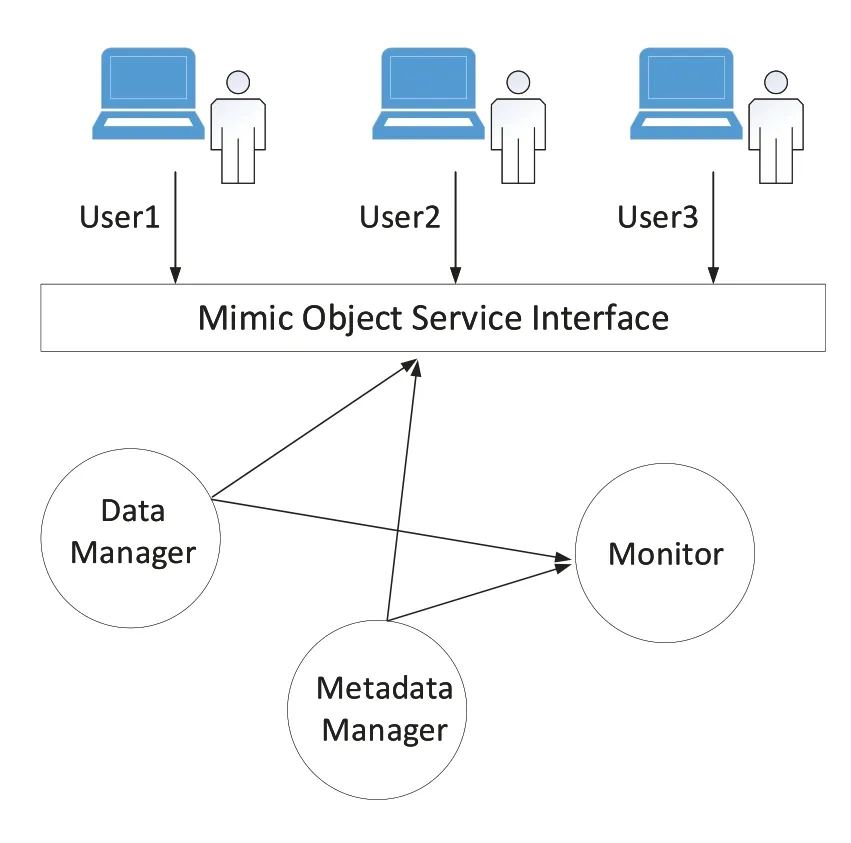
Figure 1.Mimic distributed object storage model.
2.2 Storage Model Characteristics
The distributed object storage system that incorporates mimic features has the following characteristics:
1.Redundancy
The system adopts a data redundancy strategy that combines erasure codes and multiple copies.For object data,the system adopts a redundancy strategy of multiple erasure codes,which can improve hardware utilization and data reliability.For object metadata,the system adopts a multi-copy redundancy strategy.
2.Heterogeneity
At the software level,the system realizes the heterogeneous characteristics of mimicry through data redundancy.When the system stores data,it uses multiple erasure codes to encode the data.At the hardware level,data nodes and metadata nodes use hardware devices with different architectures,different operating system platforms,and different operating system versions.Use physical dissimilarity to increase the heterogeneity of the system and prevent rapid attacks on a single vulnerability.
3.Dynamic configuration
The system mainly realizes the dynamics of mimic defense through the monitor module.The monitor module is responsible for monitoring the data nodes and metadata nodes,updating the status of the data nodes and metadata nodes according to the traces of the attacker,and can actively take them offline when necessary,and send data migration instructions.After the node is successfully offline,the administrator needs to repair the node to eliminate security risks.Nodes in safe can be online at any time and added to the running system.In addition,when using erasure code to encode data,the parameters of the erasure code are dynamically changed,which increases the uncertainty of the system and further improves the security of the system.
4.Low storage cost
Compared with the multi-copy strategy,erasure code has the characteristics of smaller memory usage,higher fault tolerance,and smaller repair bandwidth.The system adopts multiple erasure codes as the realization of redundancy and heterogeneity,which has high space utilization and strong fault tolerance.Uploaded files are encoded by erasure code,and data is stored in units of code blocks.The fine-grained data deduplication effect is provided,which further improves the space utilization rate.
5.Log tamper resistance
The log information is stored in the blockchain in the system to ensure that the log information cannot be tampered with.And the system can make corresponding strategies based on the log audit results to improve the security and performance of the system.
III.SYSTEM ARCHITECTURE DESIGN
The system integrates mimic defense mechanism,its architecture is shown in Figure 2.
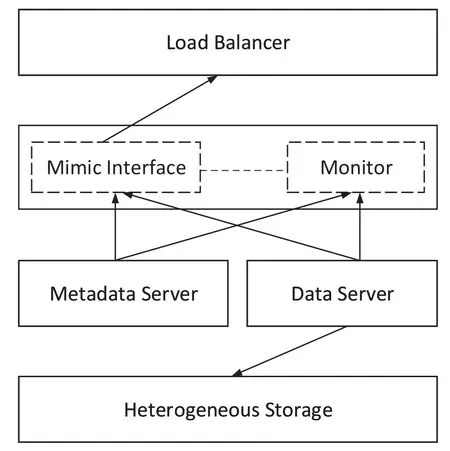
Figure 2.System architecture.
The system is mainly divided into three parts:mimic interface service layer,metadata service layer,and data service layer.Each layer of service is composed of multiple service nodes,supports horizontal expansion,and fundamentally solves the problem of data capacity.The metadata service layer and data service layer are completely transparent to users.
3.1 Mimic Interface Service
There are three states of service nodes of the mimic interface service layer:executor,monitor,and candidate.The executor,monitor,and candidate can all be multi-nodes.The executor provides REST-based HTTPS interface services and is responsible for processing client requests forwarded by the load balancing layer.The monitor is responsible for monitoring the status information of the metadata service and data service nodes and detecting whether they are attacked and whether there is data loss.And take the initiative to take the node offline and other functions.All data nodes in the system are distributed to monitors.Each monitor is responsible for managing the status of some nodes,and each data node is uniquely managed by one monitor.Each monitor not only needs to save the state of the data nodes that it needs to manage but also needs to save the data nodes managed by other monitors.When a new monitor is added or an old monitor exits,the topology of the data node managed by the monitor in the system can be dynamically updated.
Every monitor needs to have at least one candidate.When a monitor’s service is unavailable,one of the monitor’s candidates can become a new monitor and continue to provide services.Candidates are to ensure the high availability of monitors.
The mimic interface service perceives data nodes and metadata nodes through heartbeat information.The consistent hash is adopted to locate and route data information and metadata information through two hash rings respectively.The data transmission between the mimic interface service,metadata service,and data service is through HTTPS protocol to ensure security.
3.2 Metadata Service
The metadata service layer is responsible for managing the metadata information of the file,such as the creation time of the file,the permission information of the file,the correction code information of the file,etc.The metadata service layer is composed of multiple metadata services and supports horizontal expansion.Each metadata service is an independent program.
Metadata service stores metadata in elasticsearch cluster.Metadata service uses elasticsearch database to manage structured metadata,and metadata service and elasticsearch cluster are independent.Metadata service provides rest style HTTPS interface.Each metadata service will send heartbeat information to inform other nodes of its own existence.
3.3 Data Service
The data service layer is responsible for data storage.The data service layer is composed of multiple data services and supports horizontal expansion.Each data service is an independent program,and it can mount different storage clusters such as IPFS,CephFS,etc.to make the bottom layer heterogeneous and replaceable.In this article,the data service uses the local file system to store file data.The data service stores not the information of the whole file,but the coding block information of the file after erasure coding.After the file data is encoded by erasure code,it is stored in the data service with each block as a unit.The location information of each block is stored in the metadata information of the metadata service.
Data service provides rest style HTTPS interface.Each data service will send heartbeat information to inform other nodes of its own existence.
IV.FUNCTIONAL MODULE DESIGN
4.1 Mimic Feature Function Module
1.Dynamic configuration
In the mimic interface service layer,the monitor internally maintains all the states of the data service layer and the metadata service layer.The status parameters include the number of times the node has been attacked,the number of data loss,and the number of data tampering.And according to these states to replace the data service node and metadata service node.The monitor will also randomly select the object file in the system to check whether its data block is lost or tampered with.If it exists,it will be recorded in the corresponding data service node status,and the object will be restored.At the same time,the monitor will also record the attack information of the data node or metadata node.This attack information is an important indicator of the offline data service nodes and metadata service nodes.The system also uses erasure coding as a data redundancy strategy.Besides,each monitor has at least one candidate.When the monitor receives an attack or fails,one candidate will be selected as the new monitor to provide services to ensure high availability.Among them,the process of selecting a new monitor from the candidates is the same as the process of selecting the master in Raft[21].
2.Redundant,heterogeneous function module
When constructing a distributed object system based on mimic defense,the problem that needs to be solved is redundancy and heterogeneity.The heterogeneity of the system is mainly used in fault-tolerant mechanisms.In distributed systems,the commonly used fault-tolerant mechanisms include multiple copy and erasure codes.In the system,for object metadata,a three-copy redundancy strategy is used,that is,three copies of metadata information are stored.And for object data,an erasure code is used.In the system,a variety of erasure codes are constructed into an erasure code pool.When the object file is stored,three erasure codes are dynamically and randomly selected in the erasure code pool to encode them to realize the heterogeneous storage.Besides,the bottom layer of the data service node can store data through the local file system or by mounting a cluster.
Besides,physical heterogeneity can also be used to increase heterogeneity.Physical heterogeneity refers to the use of hardware devices with different architectures for data storage nodes and metadata storage nodes,different operating system platforms,and different operating system versions.Use physical dissimilarity to increase the heterogeneity of the system and prevent rapid attacks on a single vulnerability.
3.Dynamic selection algorithm
When storing objects,the system dynamically selects three erasure codes in the erasure code pool by dynamic selection algorithm to encode the content of the object.The dynamic selection algorithm needs to satisfy the following conditions.Firstly,it can select erasure codes with equal probability under the same conditions.Secondly,it can increase or decrease the probability of erasure codes being selected by weight.Finally,as the file gets larger,the erasure code’s data block and code block parameters change accordingly.But when the size of the object is too small,it uses the three-copy redundancy strategy to store the object.As the object size increases,the number of code blocks and data blocks will also increase.Dynamic selection algorithms can be implemented in a number of different ways,and can also be implemented simply through the hash algorithm.And hashing algorithm needs to have good efficiency and low hash collision probability.
Among all erasure codes,the decoding efficiency of different erasure codes is different.So different erasure codes have different weights.In the process of selecting erasure codes,the weight of erasure codes with higher encoding and decoding efficiency is set to be larger,to make them more likely to be selected.
4.2 Blockchain Log Module
The main characteristic of the blockchain is that it is open and non-tamperable.The blockchain that records logs in the system is a private chain,which is only open to users and system modules and is invisible to other applications.The log collection module collects and converts the log generated in the system,and then stores it in the log storage unit and the blockchain storage unit.The log module structure is shown in Figure 3.The log information includes service type,log level,operation time,source operation object,target operation object,and operation details.
When the system is running,the log collection module is responsible for collecting the log information of the log source,and then convert the log format and store it in the log storage module.At the same time,the log collection module will store batch logs in the blockchain storage unit.The log query and analysis unit queries the log information from the log storage unit,puts the result information into the result set,randomly selects part of the data from the result set to verify the operation in the blockchain storage unit,and marks the failed log as untrusted logs.
The system can make corresponding strategies based on the results of the log query and analysis unit to improve system security.If the attacker illegally tampered with the data or deleted the data,it would be recorded in the log and sent corresponding instructions to the monitor to restore and restore the data.If the security of some data nodes is lower than a certain threshold,the monitor will take measures such as data migration and reconstruction of isomers.Besides,through log statistics,the system can also find data with a higher frequency of access,and add these data to the cache,which can improve the performance of the entire system.
4.3 Data Positioning
In distributed systems,the consistent hashing[19]solves the problem of data distribution and routing in the dynamic network topology.The system uses consistent hashing to achieve efficient data location operations.
Two hash circles are used in the system to manage data information and metadata information.The system will encode the uploaded object,store all blocks in the data node,and store the metadata information of the object in the metadata node in three copies.
1.Upload
When receiving an object upload request sent by the client,the load balancing layer distributes the client request to the interface service layer,and the executor is responsible for processing the request.First,three erasure codes are selected through a dynamic selection algorithm.And erasure codes selected encode the uploaded object,and the encoded code block is stored to the corresponding data node through data location,and then the metadata information of the object is stored in the corresponding metadata node in the form of three copies,and finally returns the result information of the object upload request to the client.The object upload process is shown in Figure 4.
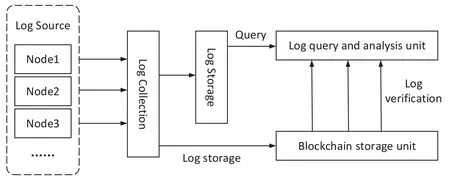
Figure 3.Log module structure.
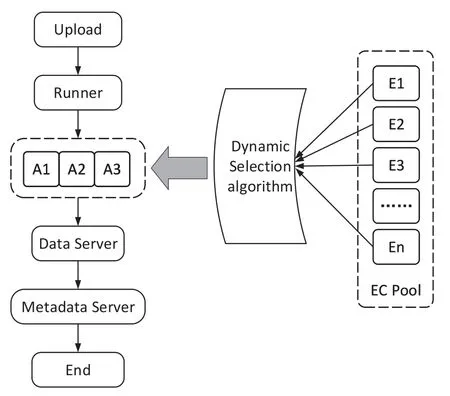
Figure 4.Upload object.
Data positioning is divided into two parts:data and metadata.1)Data.The system stores the coded blocks encoded by the erasure code to the data node respectively.When storing,each code block does the following operations:first,calculate the hash value of each code block,then find the smallest data node larger than the hash value according to this hash value,and finally store the code block to the data node.2)Metadata.The system stores the metadata in three metadata nodes.When storing,at first the system calculates hash value according to the object ID,and then maps its hash value to the hash ring according to the pseudorandom algorithm,selects three metadata nodes of the hash circle.The metadata information is respectively stored in the three metadata nodes.
2.Download
When receiving the object download request,the load balancing layer distributes the request to the interface service layer.The executor is responsible for processing the request.First,the system calculates the hash value according to object ID,maps the hash value to the hash ring of metadata through a pseudo-random algorithm,and obtain the metadata information from the first metadata node.Then obtain the hash values of all the coded blocks according to the metadata information,maps the hash values to the hash ring,select the small-est data node greater than the hash value as the target node,and obtain the coded block information from the target node.Three pieces of object information are decoded according to the corresponding erasure code and parameter information,and finally,the object information is returned to the client according to the principle of multi-value judgment.
4.4 Data Migration
When a data node performs online and offline operations,the data needs to be migrated.
1.Offline
Data migration[22]will occur in the following scenarios:the security of a data node is reduced due to multiple attacks,or the data node is unavailable due to hardware and other reasons.For this scenario,it is necessary to do some offline operation on the data node,but the data on the data node is not lost.The system only needs to do the data migration.
During data migration,you need to find the next data node of this data node clockwise in the hash ring.You may as well set the node to be migrated as A and the target node to be found as node B.In this case,you only need to migrate all the data from node A to node B.
2.Online
When a new data node is added to the system,data migration is also required.
When a new node is added,it is necessary to map the node to the hash ring,and then take the mapping point as the starting point,and the first node found in a clockwise direction is the target node.We may as well set the target node as A and the newly added node as B.At this time,we need to migrate part of the data in node A(the mapping on the hash ring falls on node B)to node B.
4.5 Data Recover y
Data recovery can be divided into the following two scenarios:
1.Pieces of data loss
At this point,only one data block is lost.Because of this situation,the system has two kinds of data repair strategies.When the user downloads an object,the system finds that a data block is lost.At this time,the system can use the erasure code to recover the data and store the recovered data block back to the data node.Besides,the monitor in the system will regularly and randomly select some objects to check whether there is data loss or tampering with the object.If so,it will recover data with the characteristics of erasure code,and store the recovered data on the data node again.
2.Partial or total data loss
At this time,some or even all of the data blocks are lost.The data node in the system not only stores the data of this node but also stores the metadata information corresponding to the data of this node and the metadata information of the previous node.The metadata information of the data stored in this node can be obtained from the next node.According to the metadata information,the whole metadata information can be queried in the metadata service node,and the data can be recovered by erasure code,and the recovered data will be stored in the node again.If the data node needs to be offline,the subsequent operations are the same as data migration.
4.6 Data Reliability Analysis
Assume that the average availability of each node is u,the probability that the node can work normally.For the system model proposed in this article,when the object is uploaded,the system will select a variety of erasure codes for encoding operation,as shown in Figure 4.And the erasure code in the system is all erasure code with MDS characteristics.Assuming that the uploaded object is encoded by erasure code,a total of n blocks are generated,of which there are m data blocks and k coding blocks,that is,n=m+k.Then if and only if the number of unattacked nodes in the system is less thank,that is,at mostk−1 nodes in the system are available,the attacker can attack successfully,and the original data will be lost.Through calculation,it can be concluded that the probability of the attacker’s success is:
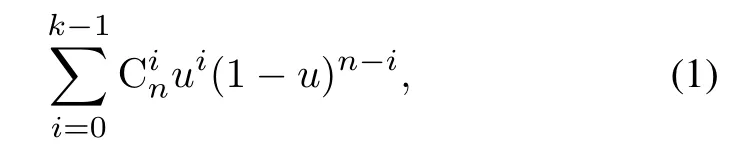
Correspondingly,the probability of data availabilityis:
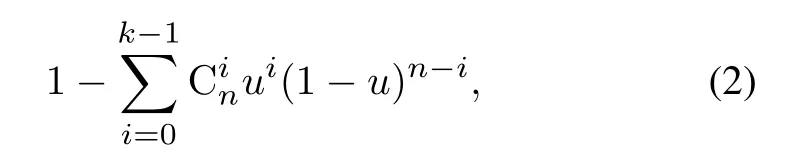
4.7 Failure Repair Analysis
When a node fails due to an attack,to maintain the redundancy of the system,it is necessary to download data from the node that has never failed,restore the lost data and store it in the corresponding node.This process is called the repair process.Replication technology can support fast data recovery.When a data block is lost,the system can directly copy the lost data from other nodes and store it on the corresponding node.For the erasure code,the repair process requires certain network resources and computing resources.In the repair process,firstly download data from k storage nodes,reconstruct the original data,reencode and store the missing data block on the corresponding node.Therefore,the system needs to take into account the following points:1)high node repair efficiency and support for fast and reliable data repair to shorten the time of the system being attacked; 2)node repair cost is small,fewer network resources are consumed in the repair process,and system repair costs are reduced.
4.8 Security Analysis
This paper uses mimicry defense to prohibit the improvement of data storage in distributed object storage system and verifies the availability of mimicry mechanism in distributed object storage system.It further enhances the security of the system on the basis of access control and other security measures.
The goal of mimicry defense is to change the system similarity,singleness,static and determinacy by using the dynamic,heterogeneous and redundant characteristics,so as to block or disrupt the attack,so as to achieve the requirement of system security risk control.The system desensitizes the data through erasure code,which can protect the confidentiality of data and the privacy of users.The system uses the mimicry defense mechanism,which can randomly and dynamically transform the storage state of data,increasing the uncertainty of data,increasing the difficulty and cost of the attacker to obtain data,and increasing the reliability of the system and the protection ability to deal with unknown attacks.
V.EXPERIMENT
5.1 Experimental Platform
All codes are implemented in the C++ programming language.An experiment platform is four machines with Intel(R)Xeon(R)Silver 4116 CPU running at 2.10GHZ with 16GB RAM,and the operating system is Ubuntu Server 18.04.And the network bandwidth is 1Gbps.
The distribution of test clusters is shown in Table 1.
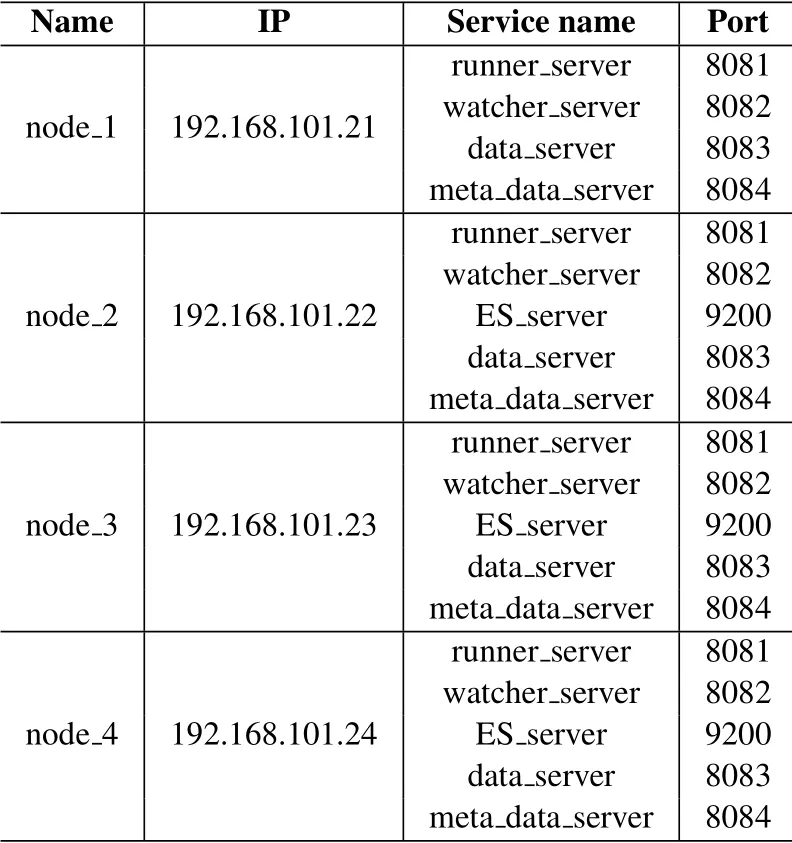
Table 1.Test cluster process distribution.

Table 2.Test cluster process distribution.
5.2 Performance Analysis
The system uses the LoadRunner to upload and download on system performance,and calculates the upload and download rates of files under different client numbers and data sizes.As shown in Figure 5,Figure 6.
After analysis of the data in Figure 5,Figure 6,the following conclusions can be drawn:
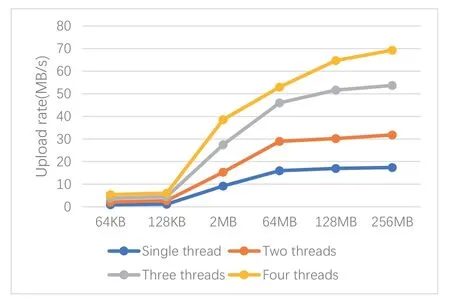
Figure 5.Upload rate under different number of threads and file size.
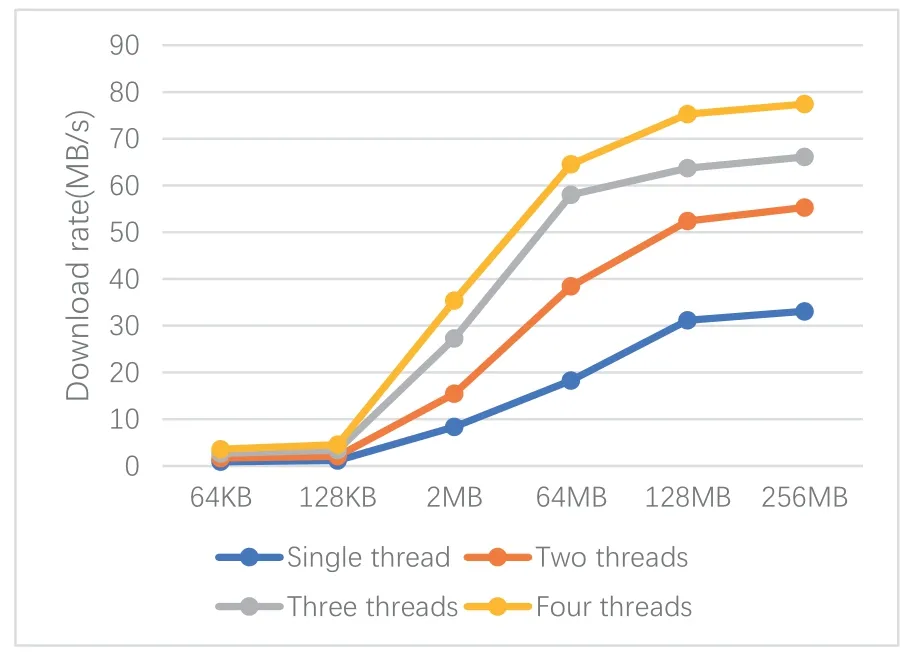
Figure 6.Download rate under different number of threads and file size.
1.When the number of threads downloading files on the client-side is constant,the upload and download rates of files increase as the file size increases.When the file size is larger than 128MB,the file download rate growth rate tends to be flat.
2.When the file size is constant,the file upload and download rate increases as the number of threads downloading files on the client-side increases.
3.The client can increase the file upload and download rate by reasonably segmenting the uploaded data.At the same time,the rate can also be improved by expanding the number of server nodes and improving the performance of server hardware.
When files are uploaded and downloaded,there is an erasure code encoding and decoding operation.This part will have a certain performance loss.When the file is downloaded,the executor will download multiple data for multi-value judgment,and this part has some performance loss.
5
.3 Erasure Code
In addition to the erasure code of jerasure,BRS(Binary Reed-Solomon)[23],BMBR(Binary Minimum Bandwidth Regenerating)[24],BMSR(Binary Minimum-storage Regenerating)[25]are also used in the system.When uploading and downloading files,the system selects three erasure codes to encode the file.Different erasure codes have different weights.Figure 7 shows the rate in different erasure codes to encode the file.And the size of the test file is 300MB.
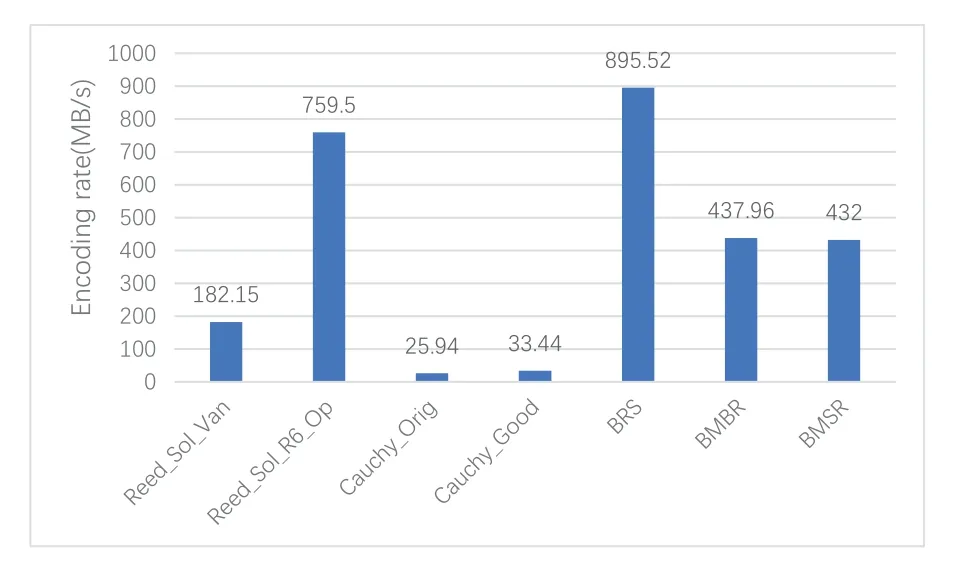
Figure 7.Encoding rate of(3,3)-threshold erasure code.
The system set different weights according to the encoding rate shown in Figure 7.In the process of selecting erasure codes,the weight of erasure codes with higher encoding and decoding efficiency is set to be larger,to make them more likely to be selected.
5.4 Security
In this section,the security of the system is tested.Before the security test experiment,upload the image named test.png.The security attack test is shown in Table 2.
When the system detects file exceptions,the system records the abnormal information and stores it in the log module.After the log module detects abnormal information,it triggers the monitor to repair the file and store the repaired data in the system again.When downloading this file,it is detected that this file is abnormal,and the operation of repairing this file will also be triggered.
After the first and second test cases occur,the system can repair the file,so the correct file data can still be downloaded from the client.After the third test case,data_server node_2 is shut down.When the system sends a request to this node,it finds that the node cannot work normally,so it will send the abnormal log of this node to the log module and inform the administrator,and the system will search for other normal node request data.So the client can still get the correct file data.After the fourth test case,the runner server on node_3 is shut down,the system will run through the runner_server on other nodes completes the processing of the request.
After the fifth test case occurs,when downloading the file,it is found that the redundant data of this file are different.The correct data will be identified by the integrity verification and security verification of the data(such as judging by the hash value of the file).At this time,the system will return the correct data and inform the administrator to check the security of the node with the wrong data to eliminate the security risks of the node.So the client can still download the correct file data.The experimental results show that the system can ensure the security of data in the experimental environment.
VI.CONCLUSION AND FUTURE WORK
Based on the distributed object system,this paper incorporates the DHR mechanism and proposes a mimic distributed object storage system architecture.By increasing the uncertainty of the system,the supply cost of the attacker’s attack on the system is increased,so that system vulnerabilities and backdoors are difficult to be exploited and triggered,effectively improving the security of the system.On the basis of the original security measures such as access control and data encryption,a mimic defense mechanism is added to further improve the security of the distributed object storage system.
In the system,the dynamic update of the status monitoring module,erasure code encoding and decoding calculation,data node,and metadata node status,etc.,increases the system’s response time.The future work is to establish an attack model for system verification,and conduct further research on various functional modules and mechanisms to improve the system architecture,to gradually change the status quo of asymmetric attack and defense costs,and passive defensive methods.
ACKNOWLEDGEMENT
This work is supported by National Keystone R&D Program of China(No.2017YFB0803204),Shenzhen Research Programs(JCYJ20170306092030521),the PCL Future Regional Network Facilities for Largescale Experiments and Applications(LZC0019),ZTE University Funding,Natural Science Foundation of China(NSFC)(No.61671001),GuangDong Prov.,R&D Key Program(No.2019B010137001),and the Shenzhen Municipal Development and Reform Commission(Disciplinary Development Program for Data Science and Intelligent Computing).

- China Communications的其它文章
- Two-Timescale Online Learning of Joint User Association and Resource Scheduling in Dynamic Mobile EdgeComputing
- SHFuzz:A Hybrid Fuzzing Method Assisted by Static Analysis for Binary Programs
- SecIngress:An API Gateway Framework to Secure Cloud Applications Based on N-Variant System
- Generative Trapdoors for Public Key Cryptography Based on Automatic Entropy Optimization
- A Safe and Reliable Heterogeneous Controller Deployment Approach in SDN
- Distributed Asynchronous Learning for Multipath Data Transmission Based on P-DDQN