
Distributed Asynchronous Learning for Multipath Data Transmission Based on P-DDQN
2021-08-21 09:35KangLiuWeiQuanDeyunGaoChengxiaoYuMingyuanLiuYumingZhang
China Communications 2021年8期
Kang Liu,Wei Quan,Deyun Gao,Chengxiao Yu,Mingyuan Liu,Yuming Zhang
School of Electronic and Information Engineering,Beijing Jiaotong University,Beijing 100044,China
Abstract:Adaptive packet scheduling can efficiently enhance the performance of multipath Data Transmission.However,realizing precise packet scheduling is challenging due to the nature of high dynamics and unpredictability of network link states.To this end,this paper proposes a distributed asynchronous deep reinforcement learning framework to intensify the dynamics and prediction of adaptive packet scheduling.Our framework contains two parts:local asynchronous packet scheduling and distributed cooperative control center.In local asynchronous packet scheduling,an asynchronous prioritized replay double deep Q-learning packets scheduling algorithm is proposed for dynamic adaptive packet scheduling learning,which makes a combination of prioritized replay double deep Q-learning network(P-DDQN)to make the fitting analysis.In distributed cooperative control center,a distributed scheduling learning and neural fitting acceleration algorithm to adaptively update neural network parameters of P-DDQN for more precise packet scheduling.Experimental results show that our solution has a better performance than Random weight algorithm and Round–Robin algorithm in throughput and loss ratio.Further,our solution has 1.32 times and 1.54 times better than Random weight algorithm and Round–Robin algorithm on the stability of multipath data transmission,respectively.
Keywords:distributed asynchronous learning; multipath data transmission;deep reinforcement learning
I.INTRODUCTION
With the development of the Fifth Generation(5G)cellular network and the Internet-of-Things(IoT),there are 5.7 billion mobile users by 2023 compared to 5.1 billion in 2018.Simultaneously,it is expected there are 14.7 billion mobile IoT device connections on the Internet by 2023[1].The rapid growth of devices heralds the explosion of wireless network data.Correspondingly,how to guarantee quality-of-service(QoS)of data transmission has become the focus of research.
Facing the complexity and differences of performance indicators in the wireless networks,especially for data transmission,researchers propose many efficient methods.For example,based on the heuristic model,some researchers used an information-aware method for throughput or power management[2],[3].In recent years,the rapid development of machine learning has inter adaptive peculiarity which is fit for the variation of network states.Therefore,ML-based methods have made great progress in network optimization[4–8].Compared with many traditional heuristic algorithms,the prediction of MLbased methods[9]is fitting for the high dynamic nature of wireless network optimization.
Due to the development of devices and technology,multipath transmission has become the focus of data transmission optimization.Especially,the combination of multipath scheduling and machine learning makes further improvement of efficient data transmission[10–15].Facing the rapid increase of wireless connections on the Internet makes network states more complex and time-varying,researchers proposed multiple algorithms to solve problems.Online learning,as a classical machine learning algorithm,is based on the feedback of the optical environment for action optimization.And researchers have made a better combination of online learning and network and have performed online learning in theory and practical applications[16].For example,in the aspect of algorithm,some researchers proposed deep Q-learning networks(DQN),which not only realize the adaptive management for the dynamics of network states but also cater to different joint objectives optimization[17,18].In addition,double DQN,as an evolution of DQN,uses twice Q-learning over neural networks to find the optimal action,which can further accelerate the optimization process and avoid over-fitting[19–22].Recently,as a novel machine learning algorithm,prioritized Replay double DQN(P-DDQN)is proposed[23].Comparing with DDQN,P-DDQN performs hierarchical optimization processing on empirical data by a tree structure.The neural network training process uses structured data for data selection to replace the original random selection method of DDQN for more fastfitting learning.
Moreover,with the development of large-scale and big data of wireless networks,the training of machine learning methods has become more complex and timeconsuming.Therefore,in the aspect of the framework,some researchers proposed the centralized learning framework for security and data analysis,etc,which needs precise global optimization[24,25].But,centralized learning needs data aggregation which causes a lot of transmission delay.Many times,the states of the network have changed again before centralized learning is finished.Therefore,a distributed learning framework is designed for cutting down the training time and enhancing the real-time by reducing training samples and training steps[26–28].Inevitably,distributed learning easily falls into the local optimum and the accuracy of long-time global optimization will be affected.Facing the local optimum,researchers begin to make many optimizations for avoiding the local optimum and accelerating the process of distributed learning.For example,some researchers proposed the technology of sharing memory and coding for speeding up the calculation process[29–31].There are also some researchers to improve the inner framework of online learning algorithms for enhancing the accuracy[32–35].In fact,in most instances,the online learning algorithm and framework are fixed at the beginning,which runs through the entire learning process and determines the pros and cons of the algorithm.It cannot be changed easily.Therefore,most of the researchers who focus on problem research,are only change the reward-penalty loss function of algorithms based on an inherent problem by their experience[34,35].But,in most cases,the network optimization online learning problem,such as online data transmission,is very complex and timing changes with the environment.Appropriate rewardpenalty loss function settings are very important and difficult to achieve.There is no complete theory for research at present,and researchers can only make specific analysis problems.
Except for the design of the scheduling framework and algorithms of data transmission,the dynamics and adaptivity of the scheduling process are also very important,which affects the performance of multipath data transmission.Therefore,researchers propose the Programming Protocol-independent Packet Processors(P4),which works in conjunction with Software Defined Network(SDN)control protocols like OpenFlow[36,37].P4 and SDN realize the separation of the control plane and the data plane of the data forwarding process.P4 is used to confiture a software-defined switch(such as P4 behavioral-model switch,BMV2),telling it how packets are to be processed.SDN controller uses P4 to indirectly control the overall forwarding logic,whereas the SDN controller can be artificially and dynamically controlled.At this time,P4 has been used in many research fields such as security[38],load balance management[39]etc.Certainly,the design of optical smartNIC[40]also make the P4 into consideration.
In this paper,we propose a distributed asynchronous deep reinforcement learning framework(DADF)for multipath data transmission to improve system stability and throughput,and to reduce packet loss ratio and RTT.In this framework,there are two working parts,local asynchronous packet scheduling(Laps)and distributed cooperative control center(DC3).Laps are performing for multipath packet scheduling.We propose an asynchronous prioritized replay double deep Q-learning packet scheduling algorithm(ADPS)to help each learner(Laps)for multipath packet scheduling management.ADPS performs packets scheduling over multiple paths according to the network states at the executing timeslot based on P-DDQN.Facing the large scale of learners,we use DC3 to make cooperative learning for more precise packet scheduling to fit the network states.In DC3,we propose the distributed scheduling learning and neural fitting acceleration algorithm(DSNA)to help Laps for accelerating and updating neural network training.When the learning process begins,each learner will choose a suitable learner to learn the neural network parameters of PDDQN by dynamic weights adjustment with the feedback.In a word,the learner will make multipath packets scheduling with ADPS.Then,learners will initiative/timed call DC3 to make cooperative learning to enhance scheduling accuracy.The main contributions are as follows.
•We propose a distributed asynchronous deep reinforcement learning framework for multipath adaptive packet scheduling.The framework also supports distributed cooperative learning to enhance the stability of large-scale data transmission.
•We design ADPS to make specific packet scheduling management.ADPS uses P-DDQN to make efficient adaptive scheduling policy adjustments for the high dynamic nature of data transmission.
•We design DSNA to explore the global stable of packet scheduling by adaptive reward-penalty loss function adjustment of neural network and to accelerate the learning process of ADPS.
The remainder of this paper is organized as follows.Section II introduces some related works.The details of our distributed asynchronous deep reinforcement framework and network model are presented in Section III.Section IV makes a detailed description of algorithms.Section V gives a simulation for the overall framework and algorithm.Section VI makes some conclusions.
II.RELATED WORKS
Comprehensive and efficient data transmission management is the main part to realize network optimization.Therefore,some researchers used queue-aware and channel-estimator methods to maximize throughout[2]and realize optimal transmission power allocation[3].Similar heuristic models also make some other outcomes.However,methods of the heuristic models always take action until something happened,which is hysteretic.
Besides,researchers also proposed data clustering machine learning algorithms to reduce data transmission[4].In the following,Sagduyu et al.used deep learning to guarantee the security of data transmission[6].AlTouset.al.use reinforcement learning to design a power control algorithm for reducing transmission delay[7].Certainly,Su et al.inserted deep reinforcement learning into routing select algorithm for improving transmission sharing and enhancing throughput[8].Also,Yu and Gabriel et al.proposed a multipath transmission method based on network coding[10]and multi-path randomly schedule for unstable channels[12],respectively.Outstandingly,The combination of machine learning and multi-path transmission flexibly make multi-objective joint optimization based on multiple indicators[13,14].
Furthermore,to enhance the adaptivity of methods,some researchers like Xu et al.used deep Q-learning networks(DQN)to realize the adaptive management for the dynamics of network sites,to cater for different joint objectives optimization[17,18].Besides,Pan and other teams used double DQN to find the optimal control action,which can further accelerate the optimization process and minimization problem[19,20].Compared with DQN,double DQN implements the selection of actions and the evaluation of actions with different value functions to avoid the over-fitting of prediction.Alsadi et al.also proposed Mini-Batch Gradient Descent Method to accelerate the training based on gradient adjustment.Such as Stochastic Gradient Descent and Batch Gradient Descent method[21].Similarly,Liu et al.proposed a method to train samples with priority.The bigger the reward,the more important the sample,which makes the training process accelerated[22].
Except for the above algorithmic improvements,facing the problems of large-scale network optimization,researchers propose a centralized learning model and distributed learning model for global optimization and reducing delay.For example,the teams of Nasr and Terzieva respectively used the centralized learning framework for security and data analysis,which needs precise global optimization[24,25].However,according to the high efficiency of distributed learning and precise of machine learning,Lyu et al.designed distributed machine learning to realize online data partitioning[26].Certainly,the accelerated training researches also improve the practical application of distributed machine learning[29].With the increase of network uses,distributed learning has become the main practical application framework.Hence,researchers proposed many different methods for enhancing the global generalization of distributed learning framework.Lim et al.proposed the methods of sharing samples for distributed learning.Unified data collection and extraction processing can strengthen the overall degree of optimization.But the transmission delay of samples will increase.Therefore,Lee et al.made the coding into data transmission for cutting down the quantity of samples[31].For professional machine learning structure designers,they filter the information by simplifying the internal structure of the neural network to improve the processing accuracy[32–35].Teams of Anand used the targeted analysis of reward-penalty loss function to improve a variety of specific problems[34,35].The method of rewardpenalty loss function setting is effective and easy to implement.
III.FRAMEWORK AND MODEL DESIGN
3.1 DADF
For improving the accuracy of packet scheduling,we design a distributed asynchronous deep reinforcement framework,shown in Figure 1.The framework consists of two parts,Laps and DC3.
The Laps is working as a smart learner in the local of users for packet scheduling control,shown in Figure 2.In Laps,we design two parts to perform the packet scheduling.Firstly,the online packet scheduling model(Scheduler)uses the trained P-DDQN to execute online scheduling.The online packet scheduling will schedule all arrival packets over multiple paths based on corresponding ratios(Action)made by P-DDQN with inputs(States)at eachscheduling timeslot(ST).Secondly,the Offline double deep Qlearning network(P-DDQN)training based the samples inExperience Poolto train the neural network.This part contains three components,Observer,Experience PoolandTrainer.Observeris to collect statestand actionatat eachttimeslot.Then,due to reward function of P-DDQN,we getrt=reward(st).By the time going,Observergets many tuples{st,at,rt,st+1},which are stored inExperience Poolby queue stack.Experience Poolis a memory with finite space.Trainerperforms the training of P-DDQN based on samples which are chosen fromExperience Pool.
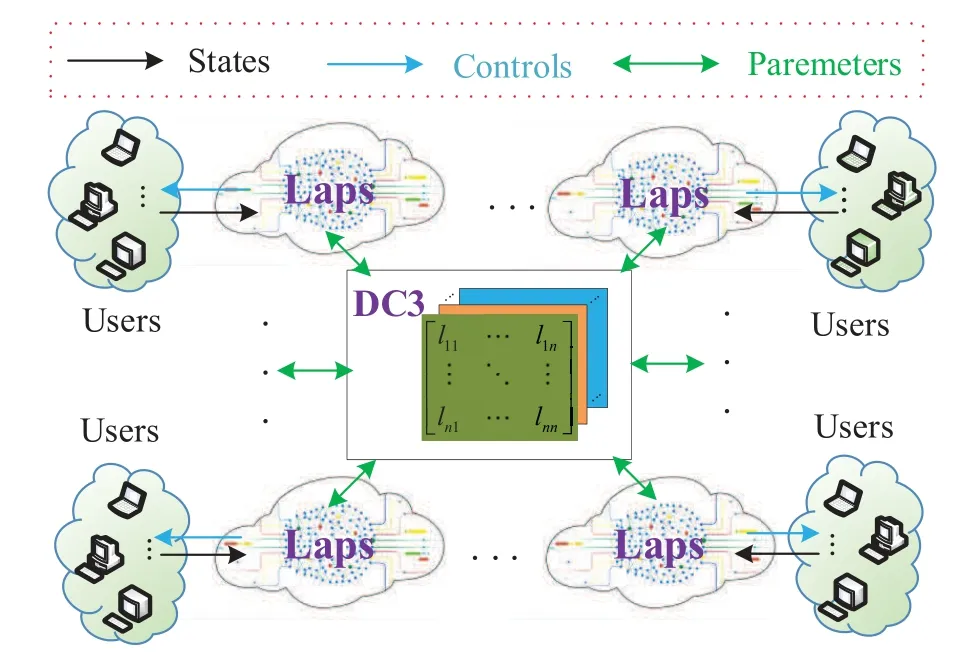
Figure 1.The distributed asynchronous deep reinforcement framework(DADF).
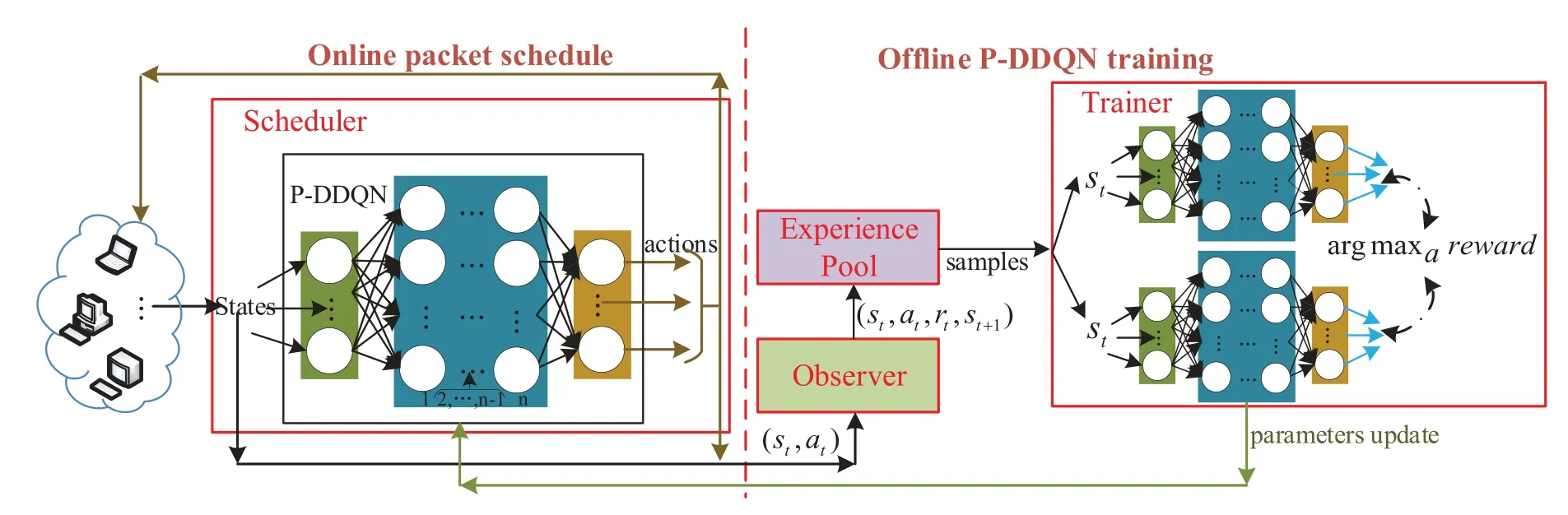
Figure 2.The process of local asynchronous packet scheduling(Laps).
The DC3 is working for distributed learning management and parameter sharing.The learning process in DC3 consists of two parts:scheduling learning and fitting acceleration learning.The scheduling learning is working for global parameters exchange.The learner will call DC3 for scheduling learning when the learner thinks the network performance is jitter.In the following,DC3 will call all learners to upload their global parameters,including reward function and neural network parameters.Certainly,the value of performance jitter will also be sent to DC3.DC3 will choose the most stable learner and send its global parameters for the request learner to learning.At this time,the request learner(requester)iand exchange learner(exchanger)jare marked as same groupgi={requester,exchanger,...}.Correspondingly,only learners who belong to the same group can perform the following fitting acceleration learning.
The fitting acceleration learning is to help learners for neural network parameters updating.Each learner can initiative or timed request parameters update by DC3.Then,DC3 will call all learners to upload their neural parameters and feedback to DC3.DC3 will choose the best learner which has the highest feedback to make neural parameters learning for the request learner.In detail,all learning weights of each learner constitute an update matrix tableLi≜{lij;i,j={1,2,...,N},i∈gi,j∈gi}in DC3.Nis the number of learners.In addition,lij∈[0,1],means learneriand learnerjare not connected and they do not learn from each other.Otherwise,andmean the total learning rate of any learner with other learners is 1.Each learner will choose one learner which has the biggestlijfor learning by the probabilityη.Otherwise,randomly chooses one learner to learn.
3.2 Problem Description and Formulation
3.2.1 Problem Description Facing the problem of data transmission optimization,realizing dynamic adaptive packet scheduling is an efficient solution.As a machine learning algorithm with accelerated training capabilities,P-DDQN has high dynamics and real-time processing capabilities.Therefore,we design a distributed learning scheduling method to make packet scheduling based on P-DDQN.
Considering the practical packet scheduling process,we should pre-define the inner structure of the corresponding neural network in P-DDQN.Then,we need to format the actual data packet scheduling process into the process of P-DDQN.Firstly,our purpose is to perform multi-path data transmission for enhancing throughput.Naturally,we need to consider the main influence:transmission links and their transmission capacity.Considering the dynamics of practical states of links,we need to choose the main parameter(st)of links and to define the performing timeslott.Following this way,the scheduling process can use fine-grained adjustment to ensure the stability of the long-term transmission capacity of the link.Then,we get corresponding management strategy aspolicy(t)≜F(st)at each timeslott,whereF(·)is the neural network function of P-DDQN.Finally,data transmission of every link obtains targeted data scheduling guidance.
3.2.2 Problem Formulation
Suppose there areNlearners to make packet scheduling based on ADPS.The working process is divided into discrete timeslots ast∈{1,2,...,T}.According to statesstat timeslott,learner will has an actionat={pm;m∈{1,2,...,M}}to make packet scheduling forMpaths based on the policymeans the packet scheduling ratio form-th path.Therefore,realizing optimal packet scheduling is to find the optimal control policy based on P-DDQN.Certainly,how to get an optimal trained P-DDQN is the following problem.We will find the optimalpolicy(θQ)by maximizing the reward in long training time,as Eq.(1):
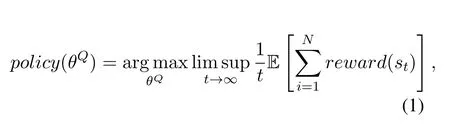
whereθQare parameters of P-DDQN,which constitutes the scheduling policy.However,in this paper,we want to realize multiple network optimization,such as enhancing throughput,reducing delay(RTT),and cutting down packet loss.Therefore,we formulate packet scheduling as an optimization problem:
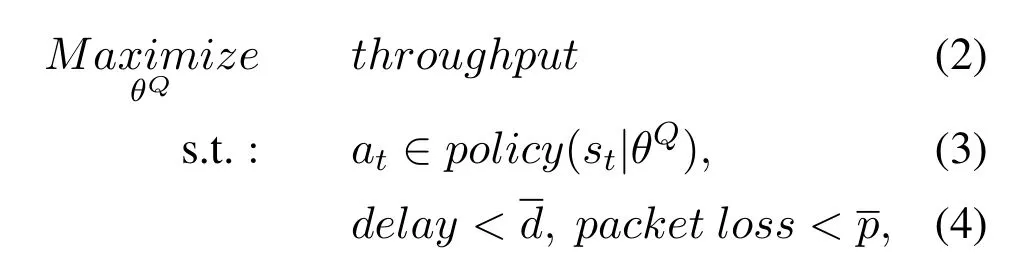
whereandare constant.
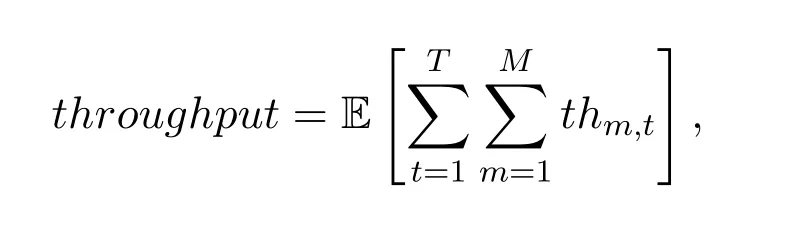
wherethm,tis throughput of pathmat timeslott.But,in a practical network environment,some network properties are interactional and subjected to each other.Therefore,for making full use of the superiority of P-DDQN,we formulate the overall optimization problem to maximize throughput,minimize delay,and packet loss,which subjects to bandwidth and congestion window size.According to Lagrange multiplier method,and Eq.(1)–Eq.(4),we get Eq.(5):
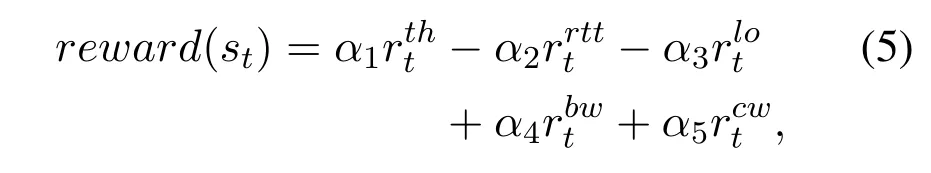
whereα1,α2,α3,α4,α5are weights of each inputs and their values range is(0,1).
thm,tis throughput of pathmat timeslottin ST.
Aboveall,accordingtost={tht,rttt,lot,bwt,cwt},we can perform Laps for the training of P-DDQN based on{st,at,rt,st+1}.
IV.ADPS AND DSNA ALGORITHMS
In Laps,we need to perform fine-grained data packet scheduling management based on changes in network transmission capabilities.However,the transmission capacity of network links presents a complex and highly dynamic characteristics with changes in network attributes.Therefore,we choose P-DDQN as the core to schedule packets,because the convolution layer of neural network structure in P-DDQN can deeply efficient approach the coupling degree of all inputs inst={tht,rttt,lot,bwt,cwt}.Then,P-DDQN uses a full connection layer to simulate the interaction of all paths.The main process of Laps is the training process inTrainer.
For P-DDQN,its purpose is to find optimal neural network parametersθQby maximizing the reward in a long time training.The training process based the interaction of two neural networks,execute-networkQ(s,a|θQ)and comparer-networkQ′(s,a|θQ′).Scheduleralso has the same schedulenetworkQs(s,a|θQ)for packet scheduling like execute-networkQ(s,a|θQ).For execute-networkQ(s,a|θQ),we use state-action value functionQ(s,a)to make iterative optimization so as to find an optimal action,as
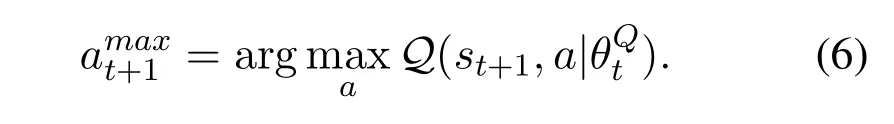
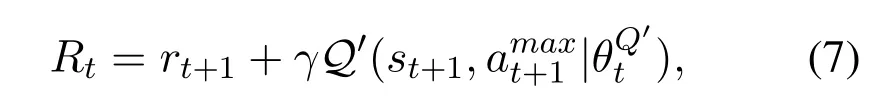
whereγis a constant.Then,we use Eq.(8)to adjust the parametersby minimizing the mean square error.
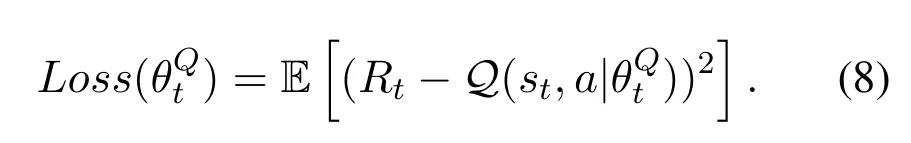
Finally,we make Batch Gradient Descent method(BGD)[21]and Prioritized Replay DQN[22]into consideration,we get whereωjis prioritized weights of samplej.kis the size of mini-batch samples fromExperience Pool.
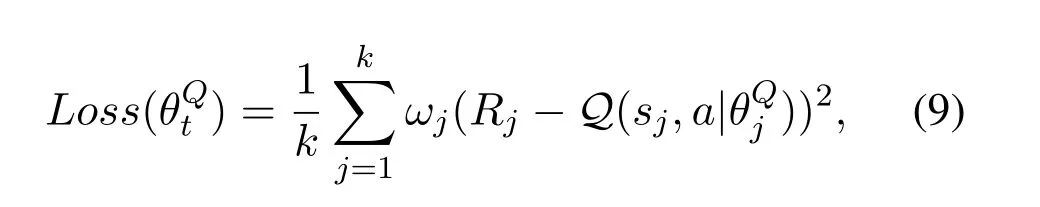
For each learner,Figure 2 shows the overall process of local P-DDQN training and packet scheduling.We also propose ADPS to show detailed steps.In algorithm 1,there are two threads,which respectively execute online packet scheduling and experience collection by time seriestand offline P-DDQN training inTrainer.ADPS firstly initializes the parameters of neural network for the following process(line 3-4).InScheduler,online packet scheduling(line 5-9)not only do packet scheduling based on schedule-networkQs(θQ)and inputsst,but also collects samples forExperience PoolbyObserver.Experience Poolhas finite space,when new samples come,some stale data will be dropped.InTrainer,offline P-DDQN training of execute-networkQ(s,a|θQ)is executed(line 10-16)and the schedule-networkQs(θQ)also is correspondingly improved by neural parametersθQ.
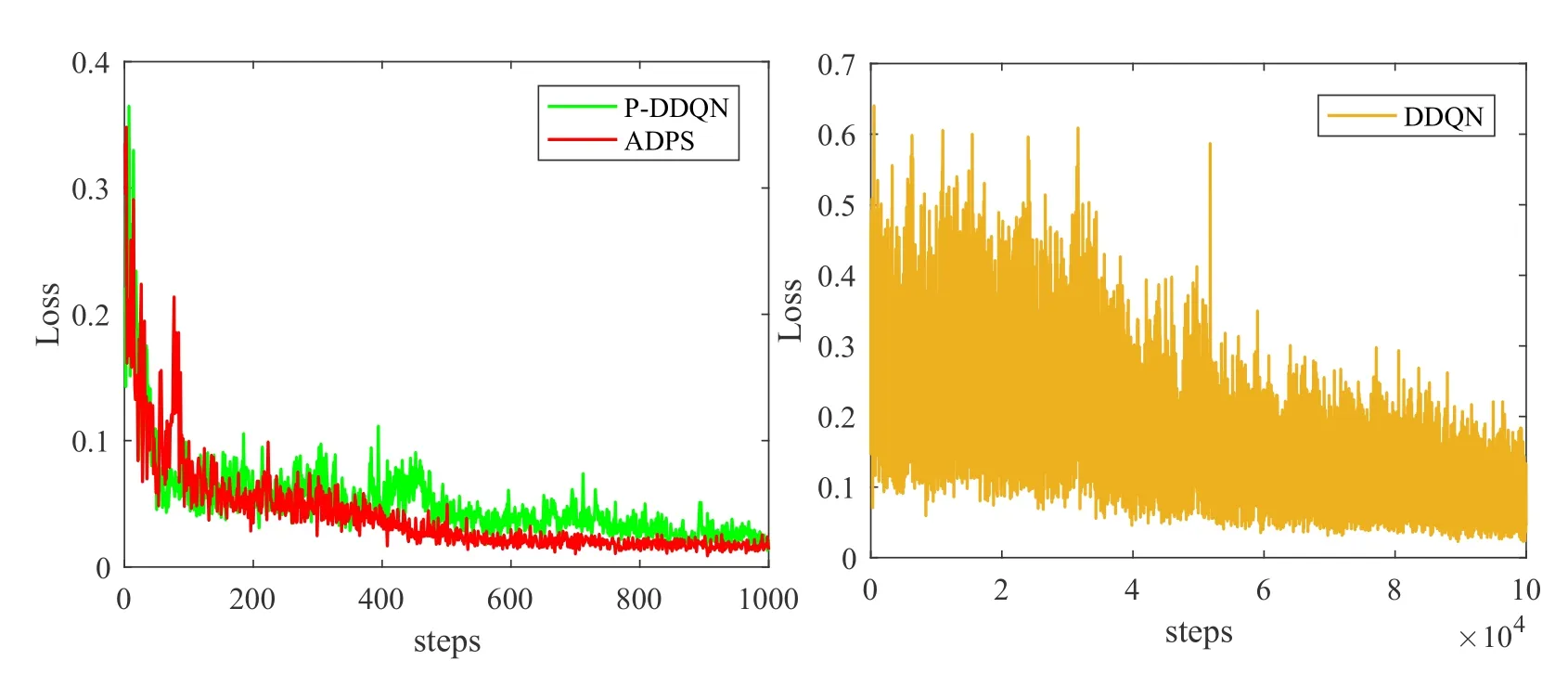
Figure 3.The converge comparison of ADPS,P-DDQN,DDQN.
When each learner executes Laps in local,DC3 can be timed or requested by a learner to perform learning.The learning process contains two steps,scheduling learning,and fitting acceleration learning.Firstly,in the process of scheduling learning,every learning will randomly set the weights of each input ofrewardat the beginning of learning for every learner.The random settings can more precise to reach the optimal network conditions and it is also very important for the optimal fitting convergence.For all learners,every learner has a fitting function as{fi(reward,θQ);i={1,2,...,N}}because of the difference ofreward.Then,learners doing the ADPS in Laps and calculate the neural network jitter judgment based on the data inExperience Pool.When jitter occurred,the learner will call DC3 for learning.DC3 will inform all learners for collecting parameters and choose the optimal network parameters for the request learner by jitter judgment standardjit.At this time,we use a Coefficient of Variation(C.V.)as the jitter judgment standard.C.V.is the standard deviation of the selected data divided by the average value of the data.
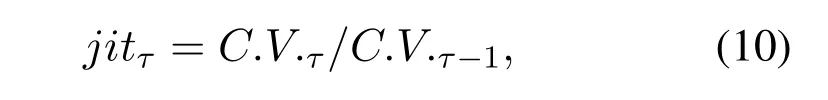
whereτis the time update point and it constrains at least one timeslott.

Algorithm 1.The asynchronous prioritized replay double deep Q-learning packets scheduling algorithm(ADPS).1:Input:Learning rate γ,update rate ε,random probability ψ,Experience Pool P.2:Output:Execute-network parameters θQ.3:Randomly initialize parameters θQ of executenetwork Q(θQ)and scheduling-network Qs(θQ).4:Initializes comparer-network Q′(θQ′),and make θQ′ ←θQ.5:/// Online packet scheduling and experience collection///6: Scheduler records current states st,and calculates action at by Qs(θQ)with probability ψ or randomly selects action at.7: Scheduler performs packet scheduling with at for users.8: Observer formats tuple{st,at,rt,st+1},makes initialize current sample j’s priority ωj,and sends this tuple to Experience Pool.9: Experience Pool stores the tuple{st,at,rt,st+1}in P and updates tree structure by ωj.10:///Offline P-DDQN training in Trainer///11:for iteration=1,...,T do 12:Chooses k samples from P by tree structure.13:Calculates cumulate target reward of k samples,Rj=images/BZ_75_1499_1894_1535_1940.pngrj+1+γQ′(sj+1,amaxj+1|θQ′t),Working,rj+1,End.14:Updates θQ by minimizing the mean square error,Minimize 1 kk ωj(Rj −Q(sj,a|θQ j))2.j=1 15:Updates parameter: θQ′t ←εθQ t +(1 −ε)θQ′t .16:Updates current samples’tree structure by ωj,j∈k=|Rj −Q(sj,a|θQ j)|.17:if Laps is dormant then 18:break.19:end if 20:end for
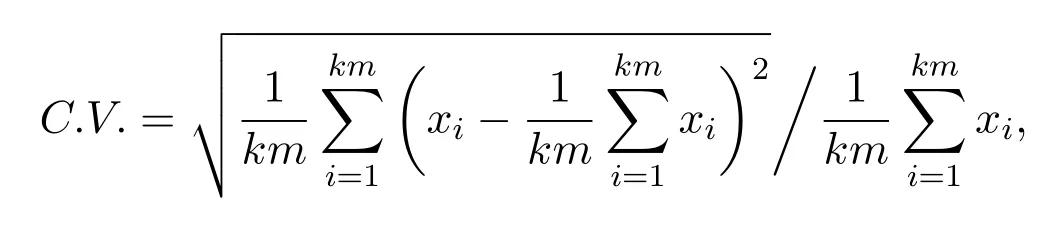
wherekmare the samples fromExperience Poolandkmless than the sizekofExperience Pool.xiis the value of reward in each samples.Certainly,when the updating finished,DC3 needs to make a group recordG={gi={fj(reward,θQ);j∈{1,...,n},n ≤N},i ≤N}for learners who have the same parameters ofrewardand neural network for the next fitting acceleration learning process.Secondly,in the process of fitting acceleration learning,the learning process between learnersmust belong to the same group record.In other words,these learners have the samereward.When DC3 calls all learners to make update learning,DC3 needs to maintain weight a matrix table for distributed cooperative learning.Each learningiwill send their Q-network parametersand feedbackhij,τto DC3.
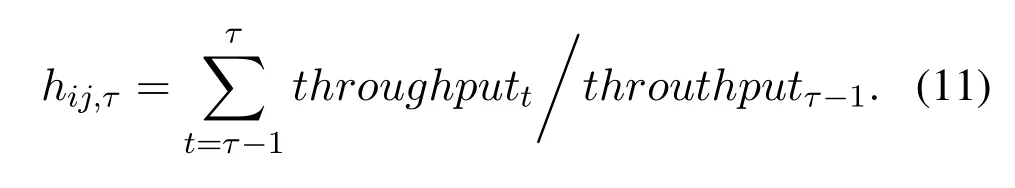
hij,τis the feedback of learneritojatτ-th update.DC3 will firstly update weight matrix tableLibased on allhij,τs by
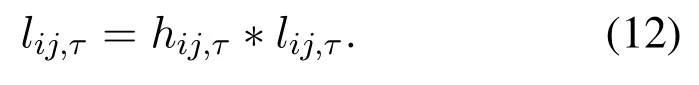
Certainly,the weight matrix table should following the constraint byIn the following,each learner will select max weight of learnerjfor parameter update with probabilityη,η∈(0,1),or randomly select learnerk,as
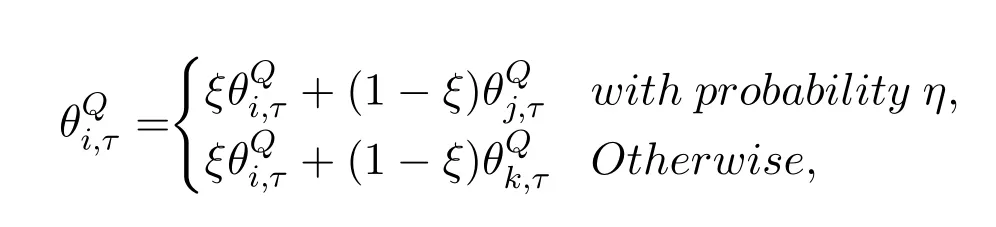
whereξ∈[0,1]is the learning rate.Finally,DC3 sends allto their learners which will update their parameters for better scheduling.The main process of distributed learning in DC3 is shown in algorithm 2.When DC3 receives a learning request,it will make a judgment and call the corresponding process(line 16-22).The scheduling learning process is to find a learner with the most stable network performance for global parameters learning(line 3-6).The fitting acceleration process is to find a leaner,who is in the same group of request learner and has better feedback than other learners,for neural network parameters learning(line 7-15).

Algorithm 2.The distributed scheduling learning and neural fitting acceleration algorithm(DSNA).1:Input:Learning request with fi(reward,θQ)or{θQ,hij,τ}.2:Output:Global parameters fi(reward,θQ)or neural network parameters θQ.3:///scheduling learning process///4:DC3 calls all learners for their fi(reward,θQ)and jitτ.5:Chooses the the most stable learner i by jitτ.6:Sends the fi(reward,θQ)of learner i for the request learner.7:///fitting acceleration process///8:DC3 calls all learners for their neural network parameters θQ and feedback hij,τ.9:Updates weight matrix table lij,τ based on hij,τ.10:if Request learner is in G then 11:Chooses one learner for learning based on θQimages/BZ_76_1510_1897_1546_1942.pngξθQ i,τ +(1 −ξ)θQ j,τ with probability η,i,τ=ξθQ i,τ +(1 −ξ)θQk,τ Otherwise,12:Sends neural network parameters θQ for the request learner.13:else 14:Break.15:end if 16:Main process 17:Learner calls DC3 for learning.18:if the request is scheduling learning then 19:Calls for scheduling learning process.20:else 21:Calls for fitting acceleration process.22:end if
V.EXPERIMENTS AND ANALYSIS
5.1 Experiments Setup
To verify the validity and performance of our framework and algorithm,we implement a multipath data transmission system by high-level language for programming protocol-independent packet processors(P4),which works like OpenFlow(https://p4.org/).Experiments systematically make comparing simulations over the Random weight method(RANDOM),Round-Robin(RR),and DADF.
Settings and Network Parameters:The experiments are performed on a Linux machine(CPU:Intel i5-8265 3.2GHz;Memory:4GB;OS:64-bit Ubuntu 16.04).Multipath is made by WiFi and LTE networks respectively using Linux etc.Such as LTE:bandwidth 8Mbps,RTT 50ms; WiFi:bandwidth 16Mbps,RTT 70ms.The values of the notations of our framework and algorithm are shown in Table 1.
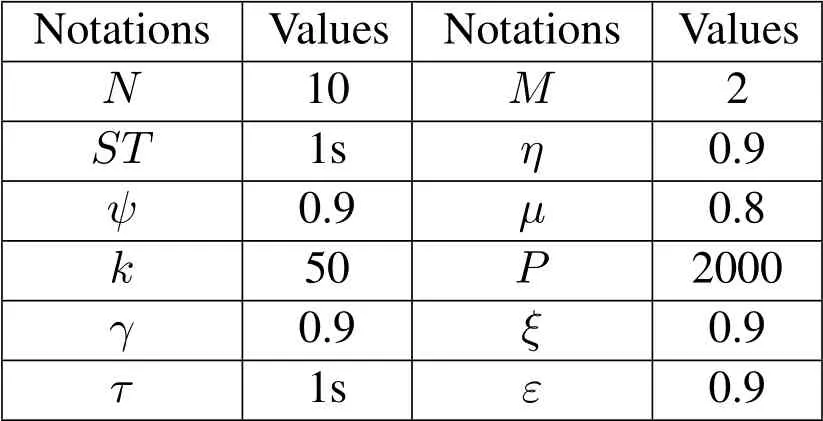
Table 1.The settings of notations in experiments.
5.2 Performance Analysis
To verify the validity of packet scheduling,we make a comparison of DDQN,prioritized replay DDQN(PDDQN),and ADPS(Algorithm 1+fitting acceleration learning in DC3).Figure 3 shows the converge comparison of ADPS,P-DDQN,DDQN.The training of algorithms uses the same samples.The Loss in the figure means the training loss of every step.For ADPS,samples are randomly divided intoMparts for learners.The loss is the average of all learners over steps.The smaller the Loss is,the better the algorithm approaches the pattern hidden in samples.In Figure 3,the loss of the training process has a downtrend of three algorithms.Besides,the loss of PDDQN and ADPS approach to 0.01 after 1000 training steps.However,DDQN needs 100000 training steps to make the loss close to 0.01.In short,the training delays of P-DDQN and ADPS are 10 times shorter than DDQN,which means P-DDQN and ADPS have a better capacity facing the dynamic nature of the network.The average loss of them is ADPS:0.0412,P-DDQN:0.0515,DDQN:0.1667.Therefore,ADPS has a shorter loss and faster training process.Comparing with P-DDQN,our distributed learning framework(DC3)is also helpful for ADPS.
In the following,we use the P4 system to make performance comparisons on RTT,packet loss ratio,and throughput of RANDOM,RR,and DADF(our framework)respectively.In the experiment,the client continuously sends packets over two paths.The scheduling ratio of packets over paths controlled by methods.At the beginning of every 1 second,the scheduling ratio will be changed by methods over 1 second.The experiment will be working for 1000 seconds for data accuracy.However,for better readability,figures will show the data for the first 100 seconds.Figure 4 shows the throughput throughout work.Specifically,the average and standard deviation of throughput by RANDOM are 645.027 and 245.985.That of RR are 812.660 and 221.132.However,that of DADF are 898.594 and 168.486.Therefore,DADF outperforms RANDOM and RR by 28.17%,9.57% on throughput,respectively.The stability of DADF outperforms RANDOM and RR by 31.42% and 23.98%,respectively.DADF has better performance on throughput and stability.
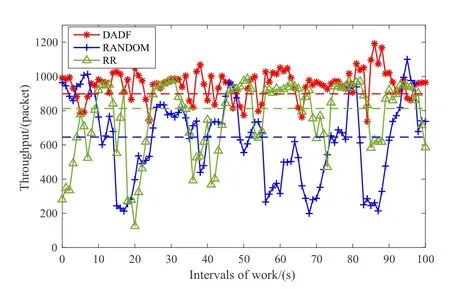
Figure 4.The throughput comparison of DADF,RR and RANDOM.
Figure 5 shows the RTT comparison of these methods throughout work.In Figure 5,the average and standard deviation of RTTs by RANDOM are 61.64ms and 0.0084.That of RR are 70.71ms and 0.014.However,that of DADF is 62.9ms and 0.0055.Making an overall comparison on RTT,the packet transmission speeds of RANDOM and DADF are 7.81–9.07 milliseconds faster than RR.RANDOM has the lowest average RTT for all packets.DADF is the second lower among these comparisons of RTT.In addition,we use the standard deviation of RTTs to measure the performance of stability.Exactly DADF improves the stability of packet scheduling by 34.52%,60.71%than RANDOM and RR,respectively.The stability of DADF has significant advantages on RTT.
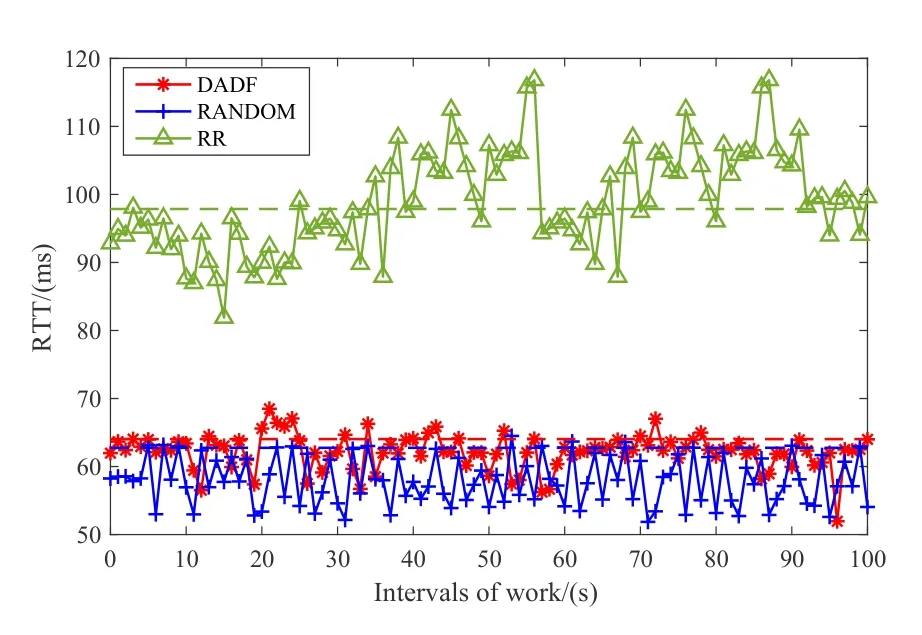
Figure 5.The RTT comparison of DADF,RR and RANDOM.
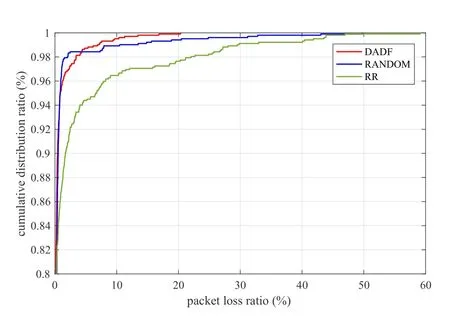
Figure 6.The packets loss ratio comparison of DADF,RR and RANDOM.
Due to the large fluctuation range of the packet loss rate,we use the cumulative distribution diagram to analyze the packet loss rate of each algorithm.Figure 6 shows a cumulative distribution chart of the packet loss rate.From the specific experimental data,the average and standard deviation of loss ratio by RANDOM are 0.4% and 0.029.That of RR are 1.28%and 0.054.However,that of DADF are 0.27% and 0.013.Therefore,DADF has the lowest packet loss ratio and DADF is reduced by 32.5%and 78.9%compared with RANDOM and RR,respectively.In Figure 6,these three algorithms have no packet loss in 80%of the packet scheduling process.But compared with 98% of the packet scheduling process,RANDOM has the smallest packet loss range of 0–2.19%.That of DADF and RR are 0–3.21%and 0–22.84%respectively.Consider the biggest packet loss ratio of the overall scheduling process,DADF is 20.16%,RANDOM is 49.83%,RR is 58.76%.Therefore,making an overall comparison,DADF and RANDOM have had a similar and stable data packet scheduling process.
Finally,experimental data show that DADF has better performance on RTT,packet loss ratio,and throughput than RANDOM and RR.Combining the standard deviation of these three aspects,DADF has 1.32 times and 1.54 times better than RANDOM and RR on the stability of data transmission,respectively.Therefore,taking all the factors together,DADF has different degrees of an advantage than RANDOM and RR on the performance of throughput,RTT,and packet loss ratio.
VI.CONCLUSION
This paper proposed a distributed asynchronous deep reinforcement learning framework for multiple packet scheduling.Firstly,we designed a dynamic adaptive packet scheduling algorithm to make precise multipath packet scheduling according to the analysis of path transmission capacity.Secondly,we proposed distributed scheduling learning and neural fitting acceleration algorithm to perform global long-term optimization of packet scheduling.In future work,we will optimize the combination of packet forwarding process and neural network algorithm in the P4-based software switch,and make a better balance of algorithms’accuracy and calculation delay.
ACKNOWLEDGMENT
This work is supported by the National Key Research and Development Program of China under Grant No.2018YFE0206800,by the National Natural Science Foundation of Beijing,China,under Grant No.4212010,and by the National Natural Science Foundation of China,under Grant No.61971028.

- China Communications的其它文章
- Two-Timescale Online Learning of Joint User Association and Resource Scheduling in Dynamic Mobile EdgeComputing
- SHFuzz:A Hybrid Fuzzing Method Assisted by Static Analysis for Binary Programs
- SecIngress:An API Gateway Framework to Secure Cloud Applications Based on N-Variant System
- Generative Trapdoors for Public Key Cryptography Based on Automatic Entropy Optimization
- A Safe and Reliable Heterogeneous Controller Deployment Approach in SDN
- A Fast Physical Layer Security-Based Location Privacy Parameter Recommendation Algorithm in 5G IoT