
A Novel Robust Zero-Watermarking Algorithm for Audio Based on Sparse Representation
2021-08-21 09:36LongtingXuDaiyuHuangXingGuoWeiRaoYunyunJiRuoyiLiXiaochenLu
China Communications 2021年8期
Longting Xu,Daiyu Huang,Xing Guo,Wei Rao,Yunyun Ji,Ruoyi Li,Xiaochen Lu,*
1 College of Information Science and Technology,Donghua University,Shanghai 200000,China
2 Tencent Ethereal Audio Lab,China
Abstract:Behind the prevalence of multimedia technology,digital copyright disputes are becoming increasingly serious.The digital watermarking prevention technique against the copyright infringement needs to be improved urgently.Among the proposed technologies,zero-watermarking has been favored recently.In order to improve the robustness of the zero-watermarking,a novel robust audio zerowatermarking method based on sparse representation is proposed.The proposed scheme is mainly based on the K-singular value decomposition(K-SVD)algorithm to construct an optimal over complete dictionary from the background audio signal.After that,the orthogonal matching pursuit(OMP)algorithm is used to calculate the sparse coefficient of the segmented test audio and generate the corresponding sparse coefficient matrix.Then,the mean value of absolute sparse coefficients in the sparse matrix of segmented speech is calculated and selected,and then comparing the mean absolute coefficient of segmented speech with the average value of the selected coefficients to realize the embedding of zero-watermarking.Experimental results show that the proposed audio zerowatermarking algorithm based on sparse representation performs effectively in resisting various common attacks.Compared with the baseline works,the proposed method has better robustness.
Keywords:zero-watermarking; K-singular value decomposition;dictionary learning;sparse representtion
I.INTRODUCTION
With the rapid development of digital media technology,the interaction of audio,image,video[1,2]and other data information[3]has become increasingly extensive.At the same time,the threat of digital copyright is also exposed to the public.Based on this background,many researchers put the development of digital copyright security protection measures on the agenda.Various and excellent digital watermarking technologies have been proposed and widely used in recent years[4,5].Robustness and imperceptibility are two important metrics to evaluate the performance of those watermarking technologies[1].However,the traditional watermarking technologies introduce inherent conflicts when embedding the watermark,which reduces the imperceptibility and robustness of the host signal[1].
In contrast to the conventional methods,the emerging zero-watermarking technology[6]does not modify the data of original audio signal,but constructs the watermark information through the content based characteristic of the original signal.So the zerowatermarking attracts much attention rely on its excellent imperceptibility.However,robustness is always the flaw of zero watermark[1,7].Robustness means that the watermarking technology can resist tremendous attacks,such as noise,filtering and frame asynchrony,etc[8,9].
Recently,the application of zero-watermarking in images has been enthusiastic.The state-of-the-art zero-watermarking technology in the image field is mainly based on the fusion of transform domain including discrete wavelet transform(DWT),discrete cosine transform(DCT)and singular value decomposition(SVD)[1,5,8–11],other based on machine learning method[12].Compared with zerowatermarking’s fiery research on images,in this paper we mainly focus on its robustness in processing audio signal.
So far,research on audio zero-watermarking technology has been carried out and these methods can be simply divided into time domain and transform domain[12].The time domain methods are mainly based on the vector quantization(VD)technique[13],that is,the stable characteristic after linear prediction is vector quantized into watermark information.However,there is a shortcoming behind this technique,that is,when different audio signals use the same quantization codebook,it will inevitably reduce the quality of quantization[13].
Furthermore,methods in transform domain have been favored by researchers due to their simplicity and ease of use.In the early,fast Fourier transform(FFT)and lifting wavelet transform(LWT)were used in the audio zero-watermarking respectively[14,15].Then,Yu et al.[16,17]proposed an audio zero-watermarking scheme based on DWT.A zero-watermarking algorithm for audio based on the correlation of linear prediction cepstrum coefficients(LPCC)with adaptive factors was proposed in paper[18].After that,work[19]presented an audio zero-watermarking method based on DCT coefficients to complete the watermark embedding.Of late,researcher explored the phase spectrum of short time Fourier transform(STFT)to generate the watermark[20].Generally speaking,these methods in the transform domain have achieved good performance in audio zero-watermarking,but the transform coefficients in these methods are often more susceptible to interference,which may lead to a decrease in robustness[19].
To address the problems presented above,recent audio zero-watermarking technology is similar to the zero-watermarking technology in the image field,based on the fusion of various transform domain methods,such as DCT,DWT and SVD.In[21],the watermark is registered by performing SVD on the coefficients generated through DWT and DCT to avoid data modification and host signal degradation.In addition,DWT and DCT are done on the host audio and then a logical key is generated in[22].Different from the work[22],work[23]proposed to register zerowatermark by comparing the mean absolute values of the adjacent frame coefficients with DWT and DCT applied on the frames of the host signal.In short,these methods can meet the needs of zero-watermark security,but they cannot resist destructive attacks well.For example,in work[21],the value of normalized crosscorrelation coefficient(NC)used to evaluate robustness is less than 0.96 when suffer low-pass filtering attack,and in work[22],the NC is less than 0.93 when suffering noise attack.
To further improve robustness,in this paper we adopt a sparse domain-based method to generate watermarks.Sparse representation has proven to be an extremely powerful tool for analyzing and processing audio signals[24].It has two substantial advantages,one is that the original data becomes sparse and retains information as much as possible,and the other is that the largest coefficient represents the most significant speech characteristics[25].What is more worth mentioning is that compared with commonly used transform domain such as DCT,DWT,etc,sparse representation can better represent the characteristics of audio signal[26].Besides,These works[27,28]all show that sparse representation to process audio signals yields good performance.In work[27],its experimental results showed that the robustness to MP3 compression attacks is high,the bit error rate(BER)is kept less than 0.1,and checked the source separation performance of music data with sparse representation.Work[28]presented a method based on sparse decomposition for detection and elimination of impulsive noise from audio signal,and experimental results demonstrated that the methond can improve the perceptual audio quality.Recent work[29]proposed a sparse domain-based information hiding framework,which attach the watermarking signal to the most significant sparse components of the host signal over the pre-defined over complete dictionary.Over complete dictionary is also used in this paper,but the difference from work[29]is that the over complete dictionary is used to find the optimal sparsity coefficient of the host signal to realize the embedding of zero-watermarking.
Specifically,the novel method based on sparse representation proposed in this paper,K-singular value decomposition(K-SVD)algorithm[30]is used to construct over complete dictionary which is a well-known dictionary learning algorithm and has superior convergence speed.The orthogonal matching pursuit(OMP)[31]algorithm is used to generate the sparse coefficient matrix.Then,the average value of absolute coefficients are calculated and selected from the sparse matrix of segmented speech,after that the watermark is registered by comparing the mean coefficient of the absolute value of the segmented speech with the average value of the selected coefficients.Correspondingly,the extraction of zero-watermarking is the reverse process of zero-watermarking embedding.The experimental results show that the proposed method has strong robustness.
The remainder of this paper is organized as follows.In Section II,how to sparsely represent speech signal is introduced.Section III proceeds to describe the process of embedding and extracting zero watermark for audio in detail.The experimental setup and evaluation are given in Section IV and Section V respectively.Finally,our work is concluded in Section VI.
II.SPARSE REPRESENTATION OF AUDIO SIGNAL
2.1 K-SVD Algorithm for Constructing Over Complete Dictionary
K-SVD algorithm can efficiently train a general dictionary for sparse representation of signals.The goal of K-SVD is to construct an over complete matrix.Then select the most sparse coefficient solution,so that the overcomplete matrix can be sparse representation of the training set.Objective equation of K-SVD algorithm is:
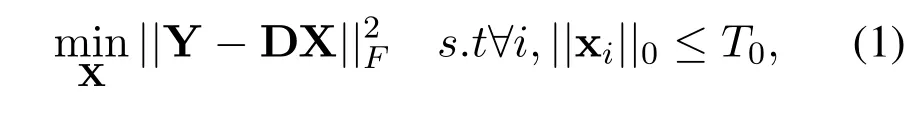

Algorithm 1.Orthogonal Matching Pursuit.Superscript †means the pseudo inverse of a matrix.Input:Target vector y,dictionary D,sparsity T0 Output:Sparsity representation x Initialize set I=[],r=y,x=0 while(stopping criterion not met)do k=arg maxk〈Dk,rT〉I=[I,k]x(I)=D†(I)y r=y −D(I)x(I)end while
In K-SVD algorithm,the expression in(1)is minimized iteratively with two steps:sparse representation and dictionary update.
In detail,the solution of formula(1)is an iterative process.First,assuming that dictionary D is fixed,the sparse representation X of Y can be obtained by using Orthogonal Matching Pursuit(OMP)[31].Second,according to the sparse representation X,find a better dictionary D.Dictionary updates are column by column.The coefficient matrix X and dictionary D are fixed.Update thek-th column of the dictionarydk,and select the corresponding vector in the coefficient matrix X,which isin rowkof the matrix X.The objective fuctions is:
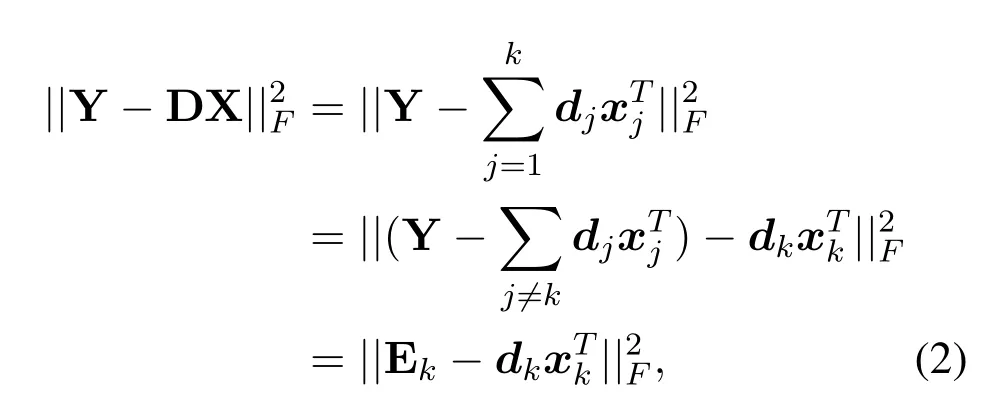
wheredkis thekcolumn of the dictionary,is thekrow corresponding todkin the coefficient matrix X.The matrix Ekrepresents the error in all samples by removing the component ofdk.Ekcan not be decomposed by SVD directly,otherwise theis not sparse.It is necessary to extract the correspondingposition inwhich is not 0 to get a newwas decomposed by SVD.Apply SVD decompositionUpdate:

In the above,we show that a total variability matrix could be represented with a sparse matrix X on a common dictionary D.Using sparse representation,our aim is to capture the essence of the speech signal with as sparse data as possible,and make it easy to be parsed by machines and/or humans.
2.2 OMP Algorithm for Constructing the Target Sparse Coefficient Matrix
Let the over complete dictionary D obtained by the K-SVD algorithm be aK-by-Mmatrix,whereKis equal to the fixed number of frames of training audio.The number of rows of the matrix D should be smaller than the number of columns.In sparse coding terminology,we refer to D as the dictionary while each column of D is called an atom.Given a target vector y,the aim of sparse representation is to find a sparse vector x that gives the solution to the following optimization problem[34].
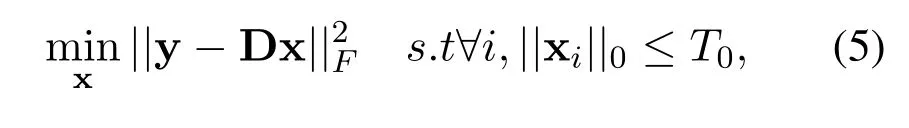
where the operator‖·‖0returns the number of nonzero elements in its argument andT0≥1 denotes the level of sparsity.We refer to the vector y asT0-sparse since the number of non-zero elements in y is limited toT0.There are a myriad of techniques available for solving the sparse coding problem,for instance,orthogonal matching pursuit(OMP)[31],basis pursuit(BP)[35],and focal underdetermined system solver(FOCUSS)[36].Algorithm 1 summarizes the OMP used in the current paper.In the above,we have defined the vectors y and x to be column vectors ofM-by-1 andK-by-1,respectively.Let each column of the taget framed audio y be denoted as yl,forl=1,2,··· ,M.We find the sparse representation for each with respect to the same dictionary.This is done by applying the OMP for each target vector yl.Stacking the resulting sparse vectors xlraw wise we form a sparse matrix X.
III.ROBUST AUDIO ZERO WATERMARKING ALGORITHM BASED ON SPARSE REPRESENTATION
In the above,we showed that audio signals could be represented with a sparse matrix X on a common dictionary D.In this section,we propose an audio zerowatermarking method based on the sparse representation,which includes watermark embedding and watermark extraction process.In the following subsections,we give a detailed description of these two processes one by one.
3.1 Watermark Image Preprocess
Suppose the original watermark is a binary imageP,which can be expressed as:
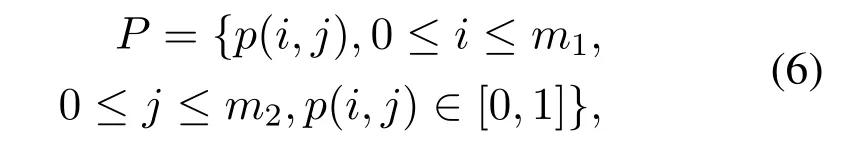
wherem1andm2are the height and width of the binary image,respectively.In order to realize the zerowatermark embedding of audio,the following binary sequence can be obtained after dimensionality reduction and binarization of the binary image,also known as the watermark key.
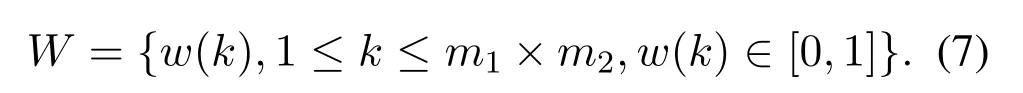
3.2 Audio Signal Preprocess
Suppose the original audio signal asY,and the total number of pixel points of watermark imagePto be embedded ism=m1× m2.According to the pixel points of watermark image,the audio signalYis evenly divided into several non-overlapping frames by using equation(8).Therefore,the frame length of each frame is expressed asflen.
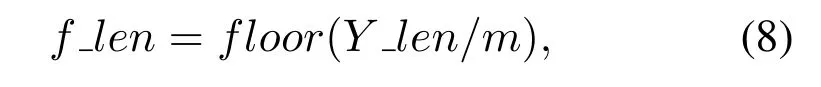
whereY_lendenotes the length of the audio signalY.Different from the speech preprocessing of watermark extraction,the speechY ′needs to be aligned with the original speechYbefore framing in the watermark embedding process,and the operation of zeropadding is performed.
After the audio is framed,the time domain to frequency domain transformation is performed on each frame.In this paper,we use short time Fourier transform(STFT)to extract the characteristics of audio signal,and then sparsely represent each frame of signal based on dictionary learning.
3.3 Zero Watermark Embedding
When the above basic processing of the audio signal is completed,the specific steps for generating a zero-watermarking on the audio signal are as follows.The concise and clear watermark extraction process is shown in Figure 1(a).
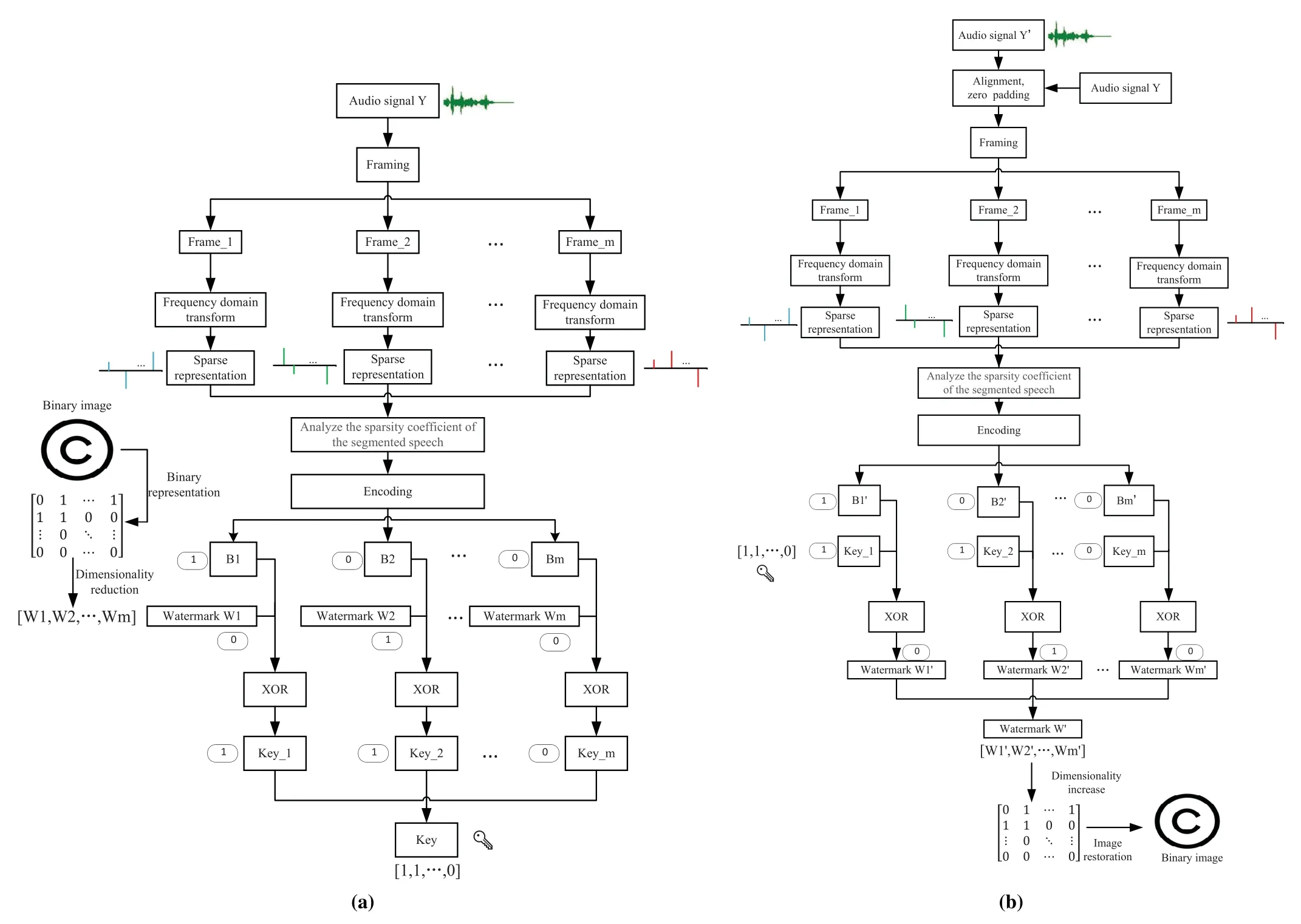
Figure 1.From left to right:(a)Watermark embedding process;(b)Watermark extraction process.
Step 1:Sparsely represent each frame of signal,and take the absolute value of all the non-zero value in the sparse representation.Then we can get the coefficient ofmgroup as follows:
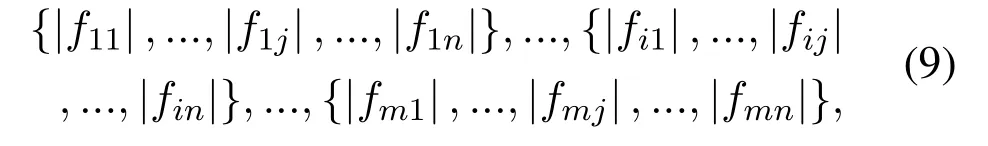
wherenis the number of non-zero values in the sparse representation and 1≤i ≤m,1≤j ≤n.
Step 2:Take the mean valueA(i)of each set of coefficients and calculate the averageMeof all selected mean values:
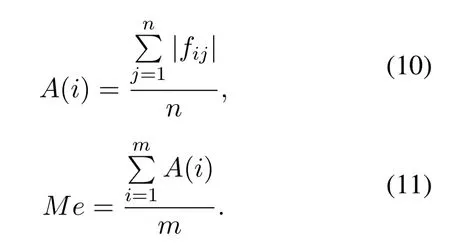
The characteristic sequenceB(i)of each frame of signal can be defined as
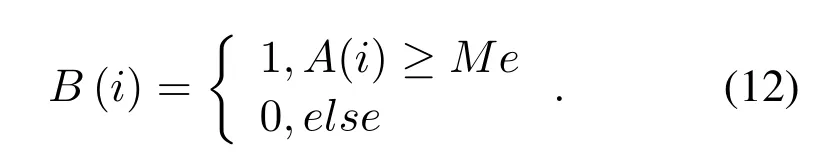
Step 3:XOR the obtained signal feature sequence with the watermark sequence,and then the watermark keyKcan be obtained.
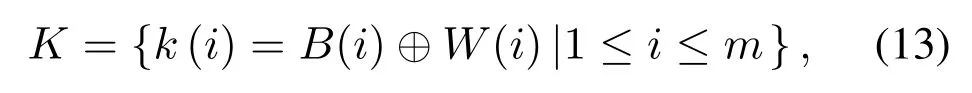
whereW(i)is the pixel point value of the binary image.
3.4 Zero Watermark Extraction
Assuming the audio signal to be detected isY ′.The watermark extraction process is as follows.To get a clear picture of the watermark extraction process,see Figure 1(b).
Step 1:Repeat steps 1 and 2 of embedding the watermark process,and obtain sequenceW′according to the same rule(12).
Step 2:Extracted watermark imageW′:
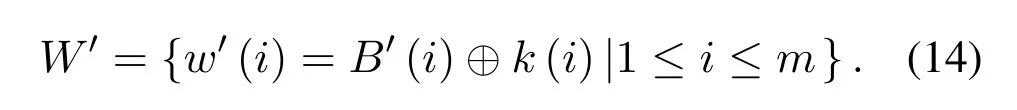
Finally,the binary image of watermark can be obtained by increasing the binary sequence dimension and restoring.
IV.EXPERIMENTAL SETUP
4.1 Datasets and Parameter Settings
The LibriTTS corpus[37]is used in the experiment,which was derived from the original audio and text materials of the LibriSpeech corpus.It consists of 585 hours of real speech data at 24kHz sampling rate from 2,456 speakers and the corresponding texts.In our experiment,the sampling point of the speech signal is set to 256.In order to verify the effectiveness of the proposed method,we constructed several different conditions from Dev-clean dataset.During the training process,250 sentences about 20 minutes from three randomly selected people were used to form training set.In this paper,we divide test data into two situations,indomain and out-of-domain,for experimentation.Each test set contains 50 sentences about 3 minutes.See Table 1 for details of the test data.In addition,a recognizable binary gray image with the pixel of 32×32 was selected as watermark images in our experiments,the specific image is shown in(a)in Figure 4.
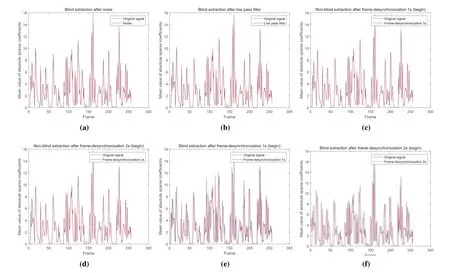
Figure 2.The mean value of absolute sparse coefficients under different attacks:(a)blind extraction after noise;(b)blind extraction after low pass filter;(c)non-blind extraction after frame-desynchronous 1s(begin);(d)non-blind extraction after frame-desynchronous 2s(begin);(e)blind extraction after frame-desynchronous 1s(begin);(f)blind extraction after framedesynchronous 2s(begin).

Figure 3.Extracted watermark images of the proposed method based on blind extraction under different framedesynchronization attacks:(a)original watermark image;(b)0.2s(begin);(c)0.5s(begin);(d)1s(begin);(e)2s(begin).

Figure 4.Extracted watermark images of the proposed method in various situations:(a)original watermark image;(b)image after additive white Gaussian noise;(c)image after low pass filter;(d)image after resampling;(e)image after MP3 compressor;(f)image after re-quantization;(g)image after frame-desynchronization 2s(begin);(h)image after framedesynchronization 2s(end).

Figure 5.Extracted watermark images of the method based on DCT[19]in various situations:(a)original watermark image;(b)image after additive white Gaussian noise;(c)image after low pass filter;(d)image after resampling;(e)image after MP3 compressor;(f)image after re-quantization;(g)image after frame-desynchronization 1s(begin);(h)image after frame-desynchronization 1s(end).

Table 1.Details of the test data.
In our experiment,the K-SVD algorithm is used to construct the over-complete dictionary.According to the experimental experience,the size of the dictionary is set toM×4MandM=256[38,39].Additionally,the sparsityT0=10%of the size of the input dataset is used to determine the most suitable cluster size to achieve excellent classification accuracy[38,40].
4.2 Evaluation Metrics
In the experimental simulation,in order to judge the performance better,the method of watermark generation is consistent in the process of watermark extraction and embedding.The generated key is then used to calculate the bit error rate(BER)and the normalized cross-correlation coefficient(NC).Generally speaking,BER and NC are used to estimate the reliability of the method and measure the anti-attack ability of zero-watermarking,respectively[11,18,21–23,41].Their calculation formula is as follows:
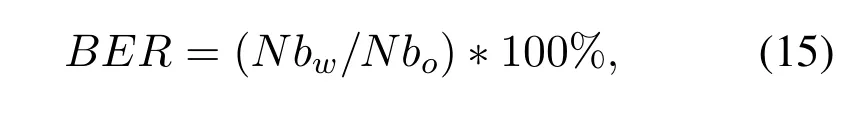
whereNbwmeans the number of bits in error andNborepresents the total number of bits of the original watermark signal.The smaller BER value,the better system performance.
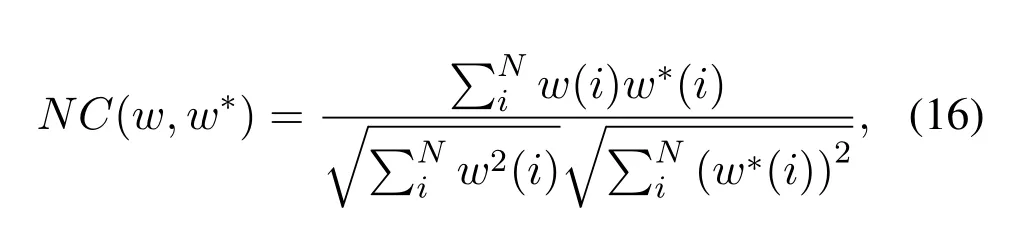
wherewandw∗represent the embedded watermark and the extracted watermark respectively,1≤i ≤NandNis the length of the watermark.The closerNC(w,w∗)is to 1,the higher correlation betweenwandw∗,which indicates the better the similarity.The closerNC(w,w∗)is to 0,the lower correlation between them.
V.EXPERIMENTAL RESULTS AND EVALUATION
5.1 Imperceptibility Test
In this imperceptibility test experiment,SNR is used to evaluate the imperceptibility of watermark signal.Since the method adopts the zero-watermarking embedding,the embedding of watermark does not bring the change of the original audio sampling point coefficient.Therefore,the quality of the audio is not affected,that is,the SNR is infinite,SNR=inf.
5.2 Robustness Test
In order to study the robustness of the method proposed in this paper,the following classic attack scenarios were studied.
•Noise:The SNR of additive white Gaussian noise(AWGN)is 20 dB.
•Low pass filter:Tested audio is filtered through a low-pass filter with a cut-off frequency of 6kHz.
•Resampling:Change the sampling frequency to 12kHz,and then resample to 24kHz.
•Re-quantization:The number of bits is reduced from 16 bits to 8 bits,and then increased from 8 bits to 16 bits.
•Frame-desynchronization:Compared with the original signal,the audio signal with watermark will be cropped for 0.5 second,1 second and 1.5 seconds at the beginning and end.The experimental evaluation part of the cropping attack defaults to crop 1 second at the beginning.
•Compressor:The signal is compressed in MP3 format(128kbps).
5.2.1 Feasibility analysis of proposed methods to resist attacks
We selected a speech signal for 36 seconds and divided it into 1024 frames without overlap for experimentation.Figure 2 shows the average value of the absolute sparse coefficient of each frame under the Gaussian noise,low pass filter and frame asynchronous 0.5 second and 1 second attack for the first 256 frames of the test speech.For common attacks,such as noise,low-pass filtering and other attacks,the watermark is extracted blindly.For the watermark extraction of synchronization attacks,blind extraction and extraction based on original speech are adopted.The latter processing method is to compare the speech with the original speech before the speech is divided into frames,and the unaligned part is set to 0.It can be clearly seen that the value after the noise and low pass filter attacks has only a slight change compared with the original speech.After the frame asynchronous attack,the mean value is extracted based on the original speech,except for the asynchronous part,other parts have undergone minor changes.However,under the frame asynchronous attack,the mean value based on blind extraction changes greatly.Therefore,our proposed method can resist common attacks and mild frame asynchrony attacks,but it cannot resist severe frame asynchrony attacks.The following robustness evaluation experiments will also verify this statement.
5.2.2 Robust performance of the proposed method under frame-desynchronization attacks
Table 2 shows the proposed method’s robustness to the frame-desynchronization attacks based on non-blind extraction.In our experiments,the watermarked audio signal is removed for specified number of seconds compared to the original signal.Observing the Table 2,we can see that our method has good robustness when the number of removal seconds is small.When 2 seconds is removed from the front part or the end part of the audio,the value of NC remains above 0.98.Additionally,we found that when we increase the num-ber of seconds removed,the value of NC has a downward trend,indicating that the robustness of the algorithm has also deteriorated.The reason behind this trend can be explained by the watermark extraction process.Since watermarks are sequentially embedded in the original audio,the removal would change of the average value of removed frames,which would affect the correct extraction of the watermark.

Table 2.The impact of different frame-desynchronization attacks on the performance of the proposed method based on non-blind extraction.
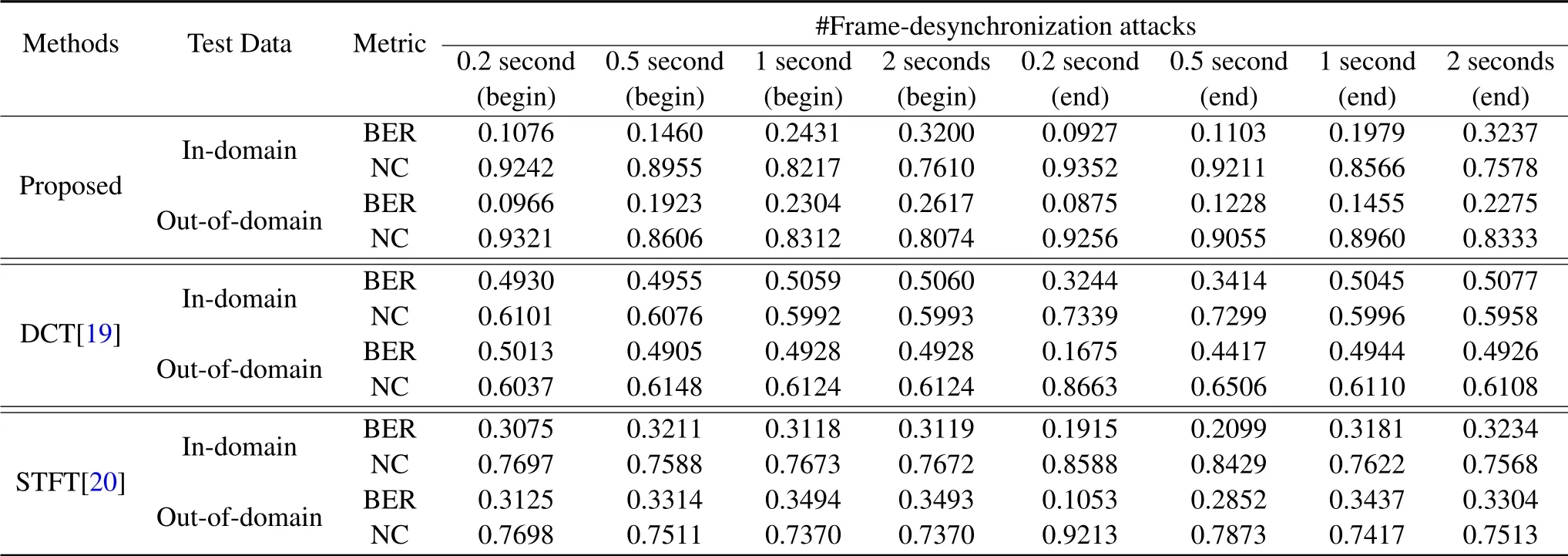
Table 3.The impact of different frame-desynchronization attacks on the performance of the proposed method and the baseline works based on blind extraction.
Observing the top half of Table 3,it can be seen that the proposed method based on blind extraction has better robustness in slight frame asynchrony attacks,but has poor robustness when frame asynchrony is severe.Specifically,when the frame shift is less than 1 second,the BER and NC values of the proposed method are lower than 0.25 and higher than 0.82,respectively.The reason behind this is that the watermark is embedded in each frame,and severe frame non-synchronization would cause serious misalignment of the watermark sequence during watermark extraction,which would lead to incorrect watermark extraction.By observing Figure 3,we can more intuitively see the robustness of the proposed method based on blind extraction under different frame-desynchronization attacks.It can be seen from the Figure 3 that when the frame shift is less than 1 second,based on blind extraction,the extracted watermark image is relatively clear,and the watermark information can be obtained.
In addition,the bottom half of Table 3 shows the impact of different frame-desynchronization attacks on the performance of the baseline works based on blind extraction.It can be easily found from the Table 3 that when the number of frames increases,the robustness of the baseline works decreases.On the whole,based on blind extraction,the robustness of the baseline works under the frame asynchronous attack is very poor.In addition,comparing the proposed method and the baseline works based on blind extraction,the proposed method performs better and could resist a certain degree of frame asynchronous attack.
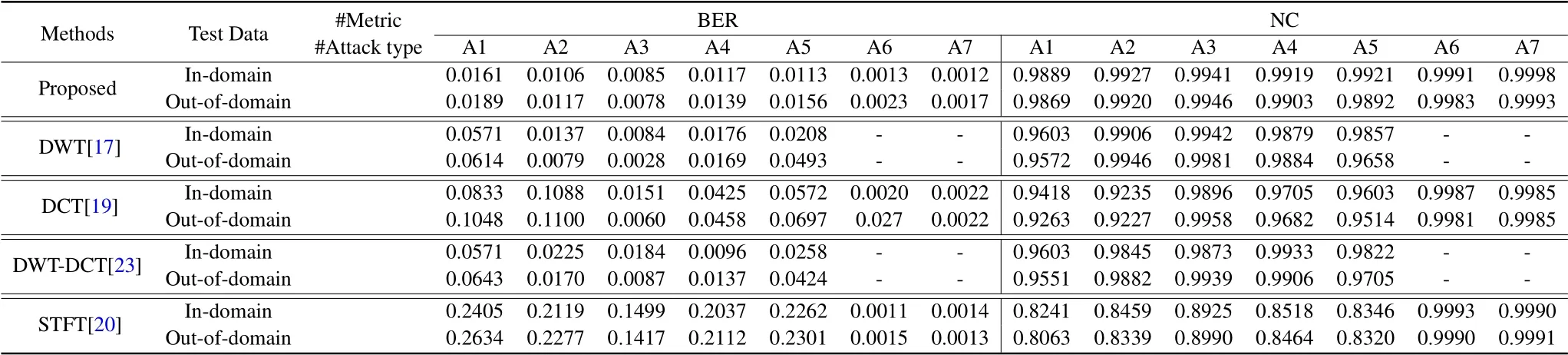
Table 4.Robustness comparison of the proposed algorithm and the baseline works.There are six attack types:Noise-A1,Low pass filter-A2,Resampling-A3,Compressor-A4,Re-quantization-A5,Frame-desynchronization 2 second(begin,nonblind extraction)-A6,Frame-desynchronization 2 second(end,non-blind extraction)-A7.
5.2.3 Robustness comparison between proposed method and the baseline works
Table 4 shows the performance comparison between the proposed method and the baseline works.According to the experimental results in the top part of the Table 4,we analyze the robustness of our proposed method.Specifically,regardless of whether the test data is in-domain or out-of-domain,except for frame asynchronous attacks,the BER under other attacks can be maintained below 0.02,and the value of NC can be maintained above 0.98.These experimental results illustrate the robustness of our method.
Then,combined with the results of the baseline work below the Table 4,it’s clear that our proposed method has better robustness than the other four algorithms especially when signal is attacked by white Gaussian noise and low pass filter.Overall,compared to baseline work,our method is relatively more reliable and robust.
Comparing Figure 4 and Figure 5,we can more intuitively see that the proposed method is more robust than the method[19].It can be seen from the two figures that the watermarked image extracted by the proposed method is basically the same as the original watermarked image,while the watermarked image extracted by the method[19]under the attack of white Gaussian noise,low pass filter appears slightly garbled and a lot of information is lost in the image.
VI.CONCLUSION
In this paper,we propose a novel robust audio zerowatermarking method based on sparse representation.In the proposed method,the K-SVD algorithm is used to construct an optimal over complete dictionary and the OMP algorithm is used to calculate the sparse coefficient of the segmented test audio.Then,by analyzing the mean value of the sparse coefficient of the segmented speech,the key generated by encoding XOR with the watermark sequence to realize the embedding of zero-watermarking.Extraction of watermark is the reverse process of watermark embeddingis.From the simulation results,the proposed method can extract a satisfactory watermark image under common attacks.In addtion,compared with the baseline works,the proposed method is more robust and can effectively resist common attacks.
ACKNOWLEDGEMENT
This work was supported by the National Natural Science Foundation of China(No.62001100),the Fundamental Research Funds for the Central Universities(No.2232019D3-52),and Shanghai Sailing Program.(No.19YF1402000).

- China Communications的其它文章
- Two-Timescale Online Learning of Joint User Association and Resource Scheduling in Dynamic Mobile EdgeComputing
- SHFuzz:A Hybrid Fuzzing Method Assisted by Static Analysis for Binary Programs
- SecIngress:An API Gateway Framework to Secure Cloud Applications Based on N-Variant System
- Generative Trapdoors for Public Key Cryptography Based on Automatic Entropy Optimization
- A Safe and Reliable Heterogeneous Controller Deployment Approach in SDN
- Distributed Asynchronous Learning for Multipath Data Transmission Based on P-DDQN