
Personalized Query Recommendation Using Semantic Factor Model
2021-08-21 09:36JinXieFuxiZhuHuanmeiGuanJiangqingWangHaoFengLinZheng
China Communications 2021年8期
Jin Xie,Fuxi Zhu,Huanmei Guan,Jiangqing Wang,Hao Feng,Lin Zheng
1 Computer School,Wuhan University,Wuhan 430072,China
2 College of Computer Science,South-Central University for Nationalities,Wuhan 430074,China
3 Information department,Wuhan College,Wuhan 430058,China
4 Department of Computer Science,College of Engineering,Shantou University,Shantou 515063,China
5 Hubei Provincial Engineering Research Center for Intelligent Management of Manufacturing Enterprises,Wuhan 430074,China
Abstract:In the field of query recommendation,the current techniques for semantic analysis technology can’t meet the demands of users.In order to meet diverse needs,we improved the LDA model and designed a new query recommendation model based on collaborative filtering-Semantic Factor Model(SFM),which combines text information,user interest information and web source.First,we improved the LDA model from bag-of-word to bag-of-phrase to understand the topics expressed by users’ frequently used sentences.The phrase bag model treats phrases as a whole and can capture more accurate query intent.Second,we use collaborative filtering to build an evaluation matrix between user interests and personalized expressions.Third,we designed a new scoring function that can recommend the top n resources to users.Finally,we conduct experiments on the AOL data set.The experimental results show that compared with other latest query recommendation techniques,SFM has higher recommendation quality.
Keywords:query recommendation;topic mining;text analysis;recommender system;LDA
I.INTRODUCTION
Query recommendation mainly analyzes users’queries and deduces user search intent to recommend a set of queries that are more expressive and selective than the original query.With the exponential growth in information,users are increasingly reliant on the results of query recommendations.The performance of keyword-based search engines such as Google and Bing is strongly dependent on the ability of the user to formulate proper queries that are both expressive and selective.An expressive query can describe user’s search intent unambiguously.However,it is difficult task to paraphrase human thoughts into concise keywords in a query[1],as users always use natural language queries without deep consideration.Search engines tend to find a list of directly related web resources according to the keywords of original query without further explore its semantic content of the query,leading to misinterpretations and poor performance.Moreover,query recommendation is always focused on the original query in user’ history list,thus there is no prediction for queries that users have never used.
In recent years,researchers began to focus on the semantics of queries.But most of the methods are to get recommended words similar to the original query from the log,and do not dig out the user’s potential intent[2,3].At present,the search performance based on semantic content has enhanced by introducing topics into query process.Query recommendation based on topic research,such as topic initiator detection[4],topic-driven PageRank[5],categorize query terms into different topics to improve the performance in query recommendation,query reformulation,query quality,and other information retrieval fields.However,the referenced topic is classified by a site such as Wikipedia or Delicious without considering latent topics in queries.In information retrieval,the latent topic cannot be easily described only in one keyword,but probably in a sequence of words containing implicit information.Latent Dirichlet Allocation(LDA)[6]is a typical topic model based on the probabilistic unigram language model with the assumption that information is represented as bag-of-words and that word order is irrelevant.LDA uses unsupervised learning to find the latent semantic dimension of the text.This method can help search engines to obtain semantic consistency of the query in text background independence.Traditional information retrieval models are based on keywords usually,assuming that words are independent.However,statements expressed in natural language are different.Therefore,the unigram language model expresses the individual intention vaguely,and even causes topic drift.Moreover,using the unigram language model and the bag-of-words models,text analysis of big data will be imposed certain constraints.If a unigram dataset is turned into a phrase set,it can have rich information for better reveal real world entities,such as people,locations,and organizations.Therefore,the basic idea is to create a heterogeneous information network,construct datasets that are rich in conceptualization and topics,and provide a strict organizational structure for people to explore and understand.This method can be applied to information retrieval,information summarization,knowledge-based construction and broader application fields[7].Inspired by the above strategy,this study integrates bag-of-phrases theory,which considers phrase as a whole rather than the individual words,into recommendation.
In addition to semantics abstraction,another problem of query parsing is user expression.Almost every language has many sayings,aphorisms,and other idiomatic expressions,for example,Chinese idioms(idioms for short)which have been widely used in written and spoken language[8].Based on their different levels of knowledge backgrounds,users usually use their own idioms; however a search engine cannot directly resolve natural language expressions in this situation.The differences between a keyword query language corpus and the corpus of standard natural language are as follows:(1)Length of the corpus:due to the simplicity of keyword query language,sufficient content cannot be provided to label information accurately by using standard natural language processing tools[9].(2)Grammatical structure:some queries are combinations of key words and some others are incomplete phrases or sentences.Conventional natural language tools are incompetent at handling query directly.However,LDA uses Bayesian network to find the similarity among words by using probability.If expressions or idioms have the same topic,we can term them as synonyms.Meanwhile,we use the bag-of-phrases instead of bag-of-words to maintain semantic integrity.This study aims to find a list of latent topics and a list of key phrases for a query through an improved phrase topic model.This method makes an attempt to capture latent topics on the basis of semantic consistency.
Traditional query recommendation technology only focuses on helping users formulate better queries with high relevancy[10].But the ultimate goal of query recommendation is to improve the accuracy of query results.Using an LDA based on bag-of-phrases model could only recommend query phrase with similar semantics,yet it can’t predict query that users might use in future.One of the most successful techniques in recommender systems,Collaborative Filtering(CF),which has made significant contributions by exploiting user-item relations[11],can solve this problem.CF is the recommendation of items through similar user/item groups.Using this idea,we can establish the interaction between a user and idiomatic expressions,so as to obtain the idiomatic expressions that the user may use in the future.LFM uses automatic clustering based on user behavior statistics for solving the difficult tasks of item classification and unification of users’ interest standards.We use the extracted hidden topics as hidden classes between users and phrases of interest in the LFM model.According to the LFM model formula,the user’s score for the phrase of interest is obtained,and the score is used as an important score in the query phrase recommendation.Although the implicit class calculated by LFM is a semantic representation of interest and a classification of objects,it is difficult to describe in natural language and generate interpretable content for the user.This study uses predict rating function to express interest classification between users and idiomatic expressions that come from queries.The query is divided into phrases that have obviously higher ability than the words in a semantic expression.At the same time,we can establish the user’s interest in the resource based on the probability of the phrase appearing in the web source under the same topic.Therefore,the phrase can also be used to visualize users’language interests and set a comprehensive score from the user to the web resource so that web sources with high priority can be selected and recommended.
The main contributions of this study are as follows:
(1)We point out the limitations of bag-of-words based approaches and develop a novel semantic query recommendation model called the semantic factor model(SFM).
(2)To exploit both users’ idiomatic phrases and clicked URLs,we seamlessly integrate LDA into the concept of collaborative filtering in recommendation to design the predicted rating function.
(3)We extensively demonstrate the superiority of SFM even in long queries.
II.RELATED WORKS
With a focus on query characterization,experts have conducted multi-channel research.Although[12–14]can improve user satisfaction with the search list to some extent,they do not fundamentally solve the existing problems of web search:semantics and expression.At present,the topic model,this involves investigating the semantics in queries to solve the existing problems of web searching,such as[15–18].Jianyong Duan present a method based on local documents to extract terminology documents,then model topics of the terminology documents to bring better recommendation results[19].Lidong Bing aimed at uncovering a unified hidden space of web search that uniformly captures the hidden semantics of search queries[20].This method uses hidden semantics to find search intent,but it also has the problem of not being able to visualize the semantics.So far,most methods that have been generated on topic construction follow the unigram language model,which cannot smoothly parse natural language used as search statements by more and more people.And single word can’t exactly describe query instant as well.JiPeng Qiang compared the generated summary of the methods(Random,LSA,NMF,LDA)are shown from the news reports.Thus,LDA cannot work very well for short texts due to limited word co-occurrence patterns in short texts[21].After comparing LDA with Biterm-LDA,Pan Liu found that assigning topics to word pairs can avoid the lack of obvious topics caused by short text sparseness in LDA[22].It can be seen that LDA has no obvious effect on topic extraction of sparse text and long text.However,the advantages of LDA extracting topics are very prominent.Ziyang Liao also proposed to use phrase to realize expanded queries suggestion to disambiguate the original web query which has multiple interpretations.This method is to use words in the corpus to connect the given query phrase to generate the query,but this method ignores the user’s idiomatic expressions[23].As a result,we aim to transform unigram to multi-gram and introduce n-gram and bag-of-phrases into text data.N-Gram is an algorithm based on statistical language models.Its basic idea is to perform a sliding window operation of size N on the content of the text according to bytes,forming a sequence of byte fragments of length N.The skip-gram uses the central word to infer the probability of the existence of words in a certain window of context.And generally,given the center word,the background words are independent of each other.These two different models are currently used more language models.The N-gram model is mostly used to evaluate whether a sentence is reasonable,and the most widely used skipgram is word2vec.In these two language models,the basic part is still based on a single word.The problem considered in this article is that the range of semantic expression of a single word is too wide,and the phrase can narrow this range and further understand the user’s query intention.Therefore,this article uses frequently-occurring word collocations as phrases and becomes a basic part of the topic model.
Four typical topic models:Bigram Topic Model[24],TNG[25],PF-LDA[26],which are based on phrases,show that the research on topic models has moved from unigram stage to the phrase stage.Although the discovery technology for phrases is integrated into the process of topic clustering,the complexity of these methods is often high and cannot be extended to big data.After all,in the field of information retrieval,the data set of the query log is larger,sparser,and lacks overall context compared to an ordinary text corpus.If we only use the above topic phrase models,we will not achieve satisfactory results.Therefore,this study uses a data-driven approach to divide phrases and improve the phrase model to resolve the previously mentioned problems.
For user expression,a new generation of search technology is shifting from short keyword searches to lengthy natural language searches; examples include Q&A systems,conversational systems,mobile terminal voice searches,and entity search engines[27].Yulia handled lengthy queries in combination with a variety of natural language processing tools[28].Kumaran was able to deal with long queries in an interactive way.These works are helpful to query results,but the overall effect is not very good[29].Bonchi used Markov chains and graphs to solve long tail queries[30].Although these methods can solve natural language queries and also improve the effectiveness of the query recommendation.However,they do not fully consider the personal idiomatic expressions of users.
In recent years,many experts and scholars have introduced LDA into the recommendation field.Use LDA to extract the user’s hidden preference.San-Hao Xing proposed an LDA topic modeling based recommendation method which an discover topics of user’s Weibo contents and recommend celebrities that users are interest in[31].Rania Albalawi proposed ChatWithRec for improving the accuracy of recommendations by analyzing the user’s contextual conversation.They used LDA to analyze the user’s conversation and perceive topics[32].In the recommender system,the neighborhood based recommendation algorithms include user-based collaborative filtering(UserCF)and object-based collaborative filtering(ItemCF).The recommendation result of UserCF reflects the interest of a small group,and that of ItemCF gives recommendations based on historical interest.Although both of them have their own characteristics,they do not subdivide the interests of users.Besides,user interests cannot determine a unified classification standard,so an implicit class is introduced.LFM is such a model which uses latent semantic analysis technology and automatic clustering based on user behavior statistics.It is a machine learning method based on optimization of a set of indicators to establish an optimal model.LFM can be represented as the following model:
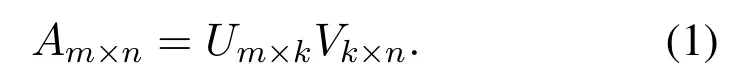
In this model,the evaluation matrixAm×nreflects each user’s preference for each item.The matrix A is decomposed into the product of the evaluation matrixUm×kof commodity-commodity attribute and the matrixVk×nof commodity attribute-user preference.
III.SEMANTIC FACTOR MODEL
In this section,we introduce our Semantic Factor Model(SFM).First,we present the general architecture of the SFM.Then we show the process of phrase mining.These phrases will be introduced into LDA as individuals to form LDA-Phrase.Finally,we use the phrase distribution obtained by LDA-Phrase in the topic and the distribution of the topic in the document,combined with web resources to get the recommendation score.The framework of the SFM is shown in Figure 1.
Figure 1.Graphical model of SFM.
3.1 Model of SMF
Assume a corpusQcomposed of queries.The user list is denotedU.The first stage of this model was to mine phrases from queries.We have definitions as follows:
Definition 1.A sequence of successive words.phr={wq,i,...wq,i+n,}(n>0,wq,i,i=1,...,Nq),wq,i represents word i in query q,Nq represents word numbers in query q.
Definition 2.Each query q consists of different query statements corresponding to the same web resource.qh,1...qh,m,(m>0),h is the corresponding web resource.
In the second stage,we modify the original LDA model into bag-of-phrase model.In this part we can obtainϕkwhich is defined as the probability distribution of words in topick.ϕk=p(x|k)∈[0,1]represents the probability of wordxoccurring in topickand[0,1]represents probability of topickin the document.The reason is that in the unigram language model,a single word cannot accurately describe the topic intent.For example,“stars” can be attributed to both astronomy and entertainment.The semantic ambiguity of the language model can be resolved by using phrases as the basic unit.
The third stage is the part of recommending web resources.After the first two steps,we can find the scores of phrasesru,jin the query that characterize user interests under the same topic.And the distribution of phrases in the recommended web resources under the same topic.Finally,the user’s scoring functionscore(u,h)for the recommended resources is obtained.
3.2 Phrase Mining of SFM
Algorithm 1:The main concept is that if the phrasepis a frequent phrase,thenp −1 is most likely a frequent phrase.This algorithm mines frequent item sets through generation of candidate sets and downward closed detection.This algorithm uses a sliding window to search for candidate phrases.The pseudo-code of the algorithm is given below.
In algorithm 1,lines 6-8 are mainly used to iterate over the corpus to find a potential frequent phrase candidate set,as well as to determine the initial sequence number of the phrase.This study uses a query corpus with sparse data,so algorithm 1 does not set a threshold when looking for frequent statements,moreover the algorithm looks for a maximum frequency candidate set,while considering the feasibility of its existence.Lines 10-14 are used to determine whether a phrase occurs frequently.If a phrase is a frequent one then it will be stored in the setP,and the frequencyC[P]is added by 1.
The candidate sets generated by traditional frequent pattern mining algorithms are usually exponential ofHowever,algorithm 1 uses consecutive words to form a phrase to eliminate the redundant phrase caused by different sequences in the disordered state.The same word cannot be repeated in two consecutive phrases,so the number of frequent candidate phrases can be reduced to a complexity ofO(N).The complexity of algorithm 1 is determined by the length of the search sentence,and the number of words in each search sentence is relatively small,so the complexity of generating frequent candidate sets is not high.And the time and space complexities areO(|c|),|c|is the size of corpus.

Algorithm 1.Finding frequent phrases.Input:Corpus Q Output:Frequent phrase and its frequency{P,C[P]}1: Iq,l ←{Index of phrase length is 1∈q}∀q∈Q 2: C ←counter(numbers of length-1 phrase)3:Initializes the word order n in query as 2 4:while Q is not empty do 5:for any query q in corpus Q do 6:Iq,n ←{i∈Iq,n−1|C[{wq,i...wq,in−2}]≥0}7:if Iq,n=∅then 8:remove q from the corpus 9:else 10:for i∈Iq,n do 11:if i+1∈Iq,n then 12:take the phrase into P.13:Phrase counter plus 1.14:end if 15:end for 16:end if 17:end for 18:n++19:end while 20:return{P,C[P])}
Algorithm 2:Phrase construction.This algorithm combines the ideas of max heap with Huffman coding.The word in the query is taken as the basic unit to form a phrase candidate unit according to the combination of adjacent words.The most numerous candidate phrases construct max heapSaccording to the output of algorithm 1.This algorithm uses an iterative method to find strongly correlated phrases.
In algorithm 2,the thresholdαis the lowest frequency of phrase occurrence,and it is set according to the different corpus and the experience value.In this algorithm,line 6 represents when the phrase composed by nodeiand nodei+1 appears with the highest frequency,the words corresponding to the two nodes are formed into the new nodei.This line realizes the combination of the strongly correlated adjacent parts.In line 7,we remove the original nodei+1 from the heap S.The multi-layer iteration is implemented in lines 3.The algorithm uses max heap as a data structure,so the time complexity of the algorithm isO(log(Nq)).

Algorithm 2.Phrase construction.Input:query statement,threshold Output:phrase segmentation 1: n ←size(query)2:Build heap S 3:while size(S)≥1 do 4:Find the maximum value of two consecutive nodes if merge.5:if max>α then 6:merge two nodes with maximum value in S 7:remove redundant nodes 8:else 9:Break 10:end if 11:end while
3.3 LDA Model of SFM
This section introduces the improved topic model LDA-Phrase.This model holds that each word in the same topic phrase shares the semantic of topic.Based on the original model,the new model changes the basic elements of corpus from single word to phrase,forming a bag-of-phrase and using the occurrence frequency of phrases to construct a probability model.The bag-of-phrase model is based on the assumption that all phrases in a query are order independent,and that all words in a phrase form a phrase topic.We divided the query into phrases as the basic unit.We believe that there is a strong correlation among words that appear in high frequency phrases,so we ignore the individual words in a phrase and use the phrase as a whole.
The LDA-Phrase model is also a Bayesian model of three layers,which assumes that documents are represented as random mixtures of latent topics.Each topic is composed of a discrete distribution of different phrases,and individual words within a phrase are ignored.In the model shown in Figure 2,there are multiple wordswq,j,1...wq,j,nin the phrasephrj;the latent topictq,jis based on the phrasephrjdirectly,and the polynomial distributionon the topic is not directly related to the words.Therefore,the joint probability of the model is expressed as follows:
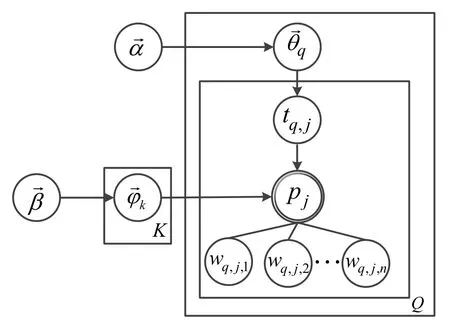
Figure 2.LDA model based on bag-of-phrase.
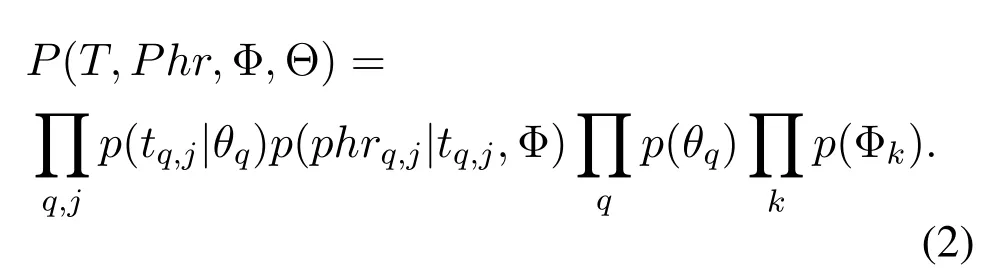
Eq.(2)represents joint probability distribution of the phrase model.The probability distribution of the phrase is only affected by the topic and the polynomial distributionϕin the topic.Table 1 shows the significance of variables in the LDA model based on bag-of-phrase.After the joint distribution is obtained
Of what colours are they? If that s all, said the first tailor, they are most likely black and white, like the kind of cloth we call pepper-and-salt

Table 1.Variables in the model.
by Eq.(2),it is sampled with the Gibbs sampling algorithm.Because the phrasecan be observed and latent topicis latent variable,the distribution that needs sampling isWe infer Gibbs Sampling formula based on the Dirichlet-Multinomial conjugate property.It is to exclude the topic assignment of the current phrase,and calculate the probability formula of the topic of the current phrase based on the topic assignment of other phrases and the observed phrases in Eq.(3).The probabilistic physical meaning of the derivation:ti=k,phri=mis only associated with two conjugate structures;andare parameter estimations according to two Dirichlet posterior distributions under the Bayesian framework.Therefore,the Gibbs sampling formula of the LDA model based on bag-of-phrase is obtained.
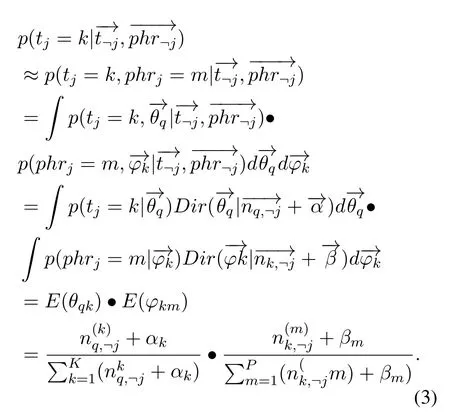
3.4 Predict Rating Function of SFM
After we have obtained the phrases and the distribution of each phrase in the topic and document,we need to use these characteristics to establish the association between users and resources,so as to realize resource recommendation.Commonly used rating recommendation methods such as MF,LMF,etc.are based on the existing rating matrix training to obtain the best value of each parameter,and then infer the predicted score of the unrated item.But in the research of this article,there is no rating matrix.Therefore,we can modify the LMF rating prediction model to get a new rating function.
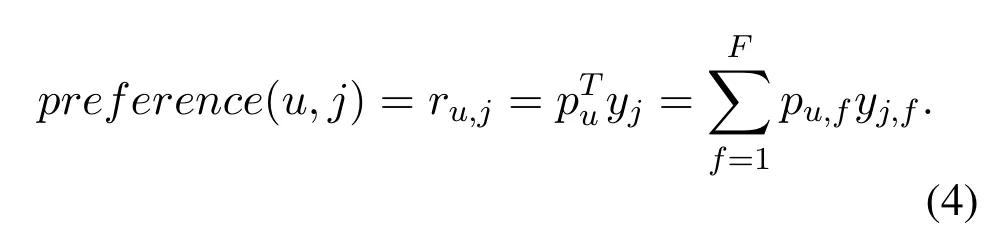
Using Eq.(4),the interest of useruin phrasejcan be calculated.pu,fmeasures the relationship between the interest of useruand latent classf.yj,fmeasures the relationship between latent classfand phrasej.Eq.(4)is obtained according to the LFM model,which uses hidden classes to dig out the relationship matrix of users and hidden classes,items and hidden classes.This kind of thinking coincides with us.Let’s think about it in reverse.If we can get the relationship matrix between user and hidden class,and item and hidden class,we can get the user’s interest score for item.The LDA-Phrase we designed can get exactly two matricesandThese two parameters represent parameter estimations according to two Dirichlet posterior distributions under the Bayesian framework.However,in the model,represents the distribution of thekthtopic on the query sentenceq,andrepresents the distribution of the phrase m on thekthtopic.The query sentence is an important basis for most intuitively reflecting the user’s interest selection,so it can also be considered as the distribution of user interests and expression habits on topics.After analyzing the user’s language habits,this study use Eq.(5)to calculate user’s interesting score for a web source,according to the probability of phrase occurrence in different topics and the probability of a topic appearing in a document.
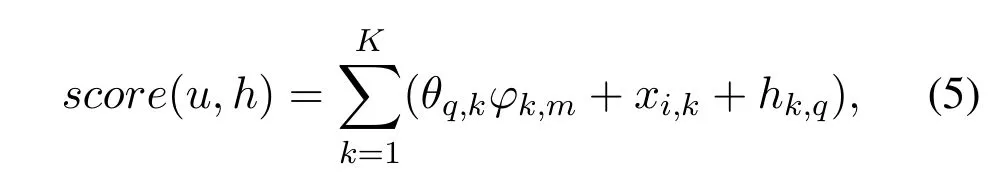
xi,kdenotes scoring of the phraseiin topickandhk,qdenotes scoring of the topickin documentqin resourceh.Therefore,the comprehensive score of interest to the final recommended resources is completed.Thetop −nphrases in every topic are high frequency phrases,and the user language interest matrix established with these high frequency phrases can reduce the dimension and reduce the sparsity of the data.Using LDA-Phrase to obtain the semantic relevance of the topic phrase,the resources retrieved by the topic phrase should also be relevant.In the situation where a phrase is used in a query,relevant websites in the same latent topic of the phrase can also be recommended to increase expansion of resources.
Meanwhile,in the LDA-Phrase model,the parametersθqdenote the distribution of the topic on queryq.As in query corpusQ,we design all queries that correspond to the same web resource as a pseudo document,θqalso denotes the topic distribution for each web resource.In this study,the information expressed by this parameter which can be learned from the topic of this web resource is also integrated in Eq.(5).
IV.EXPERIMENTS AND RESULTS
The experiment is divided into three parts:(1)After preprocessing the experimental data of AOL,We divide the queries into phrases,which is the basis of following experiments.(2)Verify the feasibility of LDA model based on bag-of-phrase.Compared with the result from the output of the LDA model,we can see that the topic based on the phrase is more recognizable.Subsequently,the perplexity of the two models was compared,and the LDA-phrase model is more generalized and applied more widely.(3)Verify the recommendation effect of the SFM.In this part,we design three experiments:First,determine the impact of two parameters on the recommended effect:the number of topics and value of n phrases under each topic; Second,use the recall rate of different length query statements in different topics to verify that the model applies to long query statements;Finally,NDCG is used to compare the accuracy of the recommended list of four models.
4.1 Preprocessing and Phrase Mining
The main dataset used in this study is the AOL log file,which is considered to be the most reliable public data set in the current work[33,34].The dataset captures the query records on AOL’s website from 1 March 2006 to 31 May 2006.The log files contain 5 properties:{AnonID,Query,QueryTime,Item-Rank,ClickURL}.There are 10,154,742 independent standardized queries,and 657,426 independent user ids,as shown in Table 2.However,there is a large amount of noise in the dataset which needs to be preprocessed.The following methods are used to deal with the original data:(1)Remove the queries containing“.com”and“WWW.”and search engine websites like “google”.This part of the data is directly related to the specific website or search engine,which is not directly,related the topic of query in this study.At the same time,some comprehensive websites,such as “www.amazon.com”,“www.youtube.com”,contain too much semantic classification and are deleted during the data preprocessing.(2)Delete the query that is “NULL” in the clickURL in the log file.This part of the query found no resources in user satisfaction,therefore it is considered as invalid.(3)Remove repeated log files.The log files contain ID,Query,clickURL,and duplicate records are removed.(4)Keep the last query record in each user session.For a single query,there are multiple resource links on the search list.Suppose the user is satisfied with the click-URL,and then the query session will be terminated.Otherwise,the user will click on another clickURL until the satisfied resource is found.
In the experiment,the AOL query log dataset is divided into training set and test set according to the time interval.The training set includes all query data in March and April.We construct a pseudo-document as q with all the queries in the clickURL that are related to the same host.
After data preprocessing is completed,we will mine phrases.According to algorithm 1 and 2,the query can be divided into semantic phrases directly.Specific examples of phrase segmentation are shown in Table 3.In this table that our phrase mining algorithm can segment common phrases in sentences.At the same time,prepositions and verbs in English can also be distinguished separately.Moreover,this method of clustering phrases based on the frequency of word collocations cannot be limited to the length of the phrase.From the Table 3,we can see that the phrase length is not fixed,which also reflects the advantage of our algorithm to mine phrases in an adaptive manner.
4.2 Bag-of-word and Bag-of-phrase Comparison
LDA is a topic model based on unigram.After improving to the phrase-based topic model,the AOL query dataset run on the LDA-phrase model,and the latent topics are shown in Table 4.This table also indicates:(1)In LDA-Phrase,the phrase corresponding to the topic can have one or more words,while LDA is limited to one word;(2)Because of the randomness of the user’s input,there are often short or irregular descriptions,but in LDA-phrase,it can be directly attributed to the same topic;(3)LDA-Phrase can express the main intention of the topic more intuitively thanLDA model.

Table 2.Example of AOL.
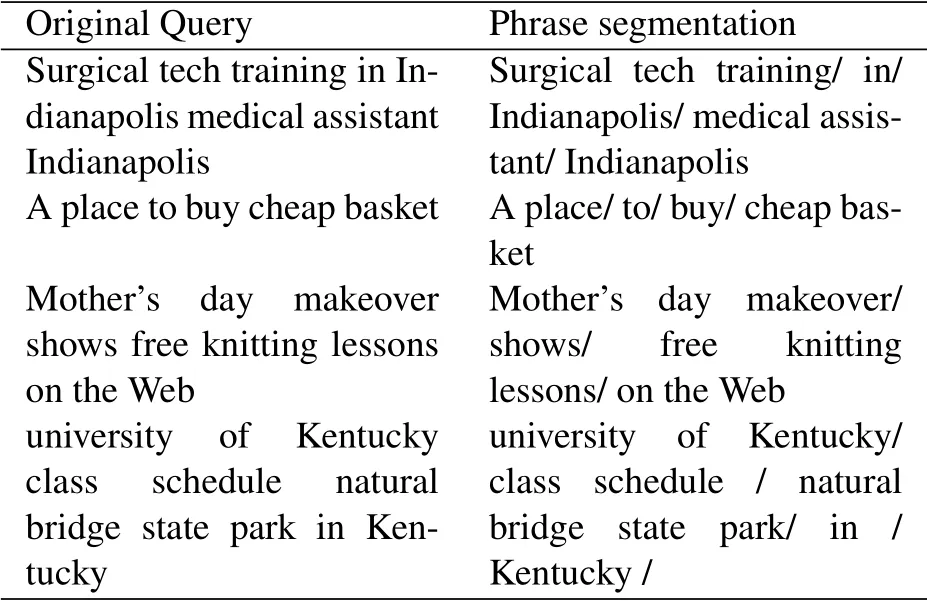
Table 3.Phrase segmentation of Query statement.
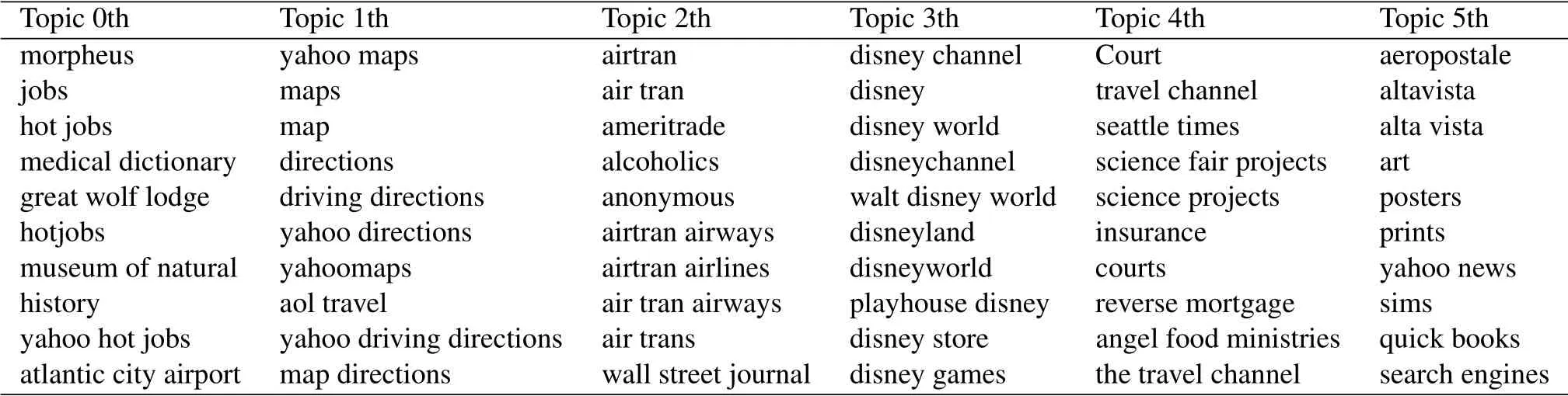
Table 4.LDA-Phrase latent topics.
Let’s take topic 3th as an example,which can fully confirm the above points.First of all,the length of the word under this topic varies,and it can be one or more words.But we can intuitively see that all contents are around “Disney”.But in the LDA,the two words “Disney” and “game” are separated under two topics,so that user intentions cannot be confined in a relatively small range.
Perplexity is the criterion which is used to evaluate the performance of the model and determine parameters or algorithm modeling capabilities[6].Low perplexity indicates better generalization.The specific calculation formula is shown below:
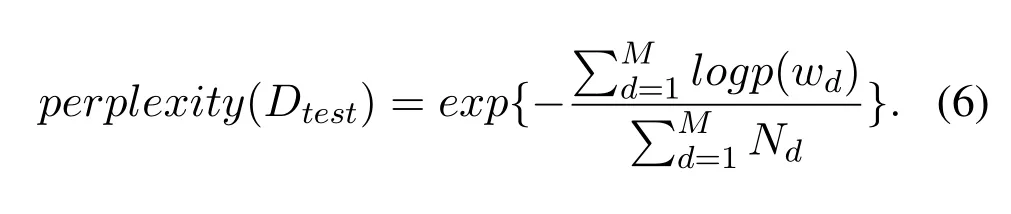
Since the generation processes of LDA-phrase and LDA are similar,we can directly compare the perplexity of the two models to evaluate the performance of our method.The dataset is used after preprocessing,10% of which is extracted as test data,while the remainder is used to train two models in the range of topics 0-100.The model perplexity is calculated respectively.As shown in Figure 3,LDA based on phrase model has lower perplexity than LDA model,indicating that generalization of the improved model is better than that of the original model.
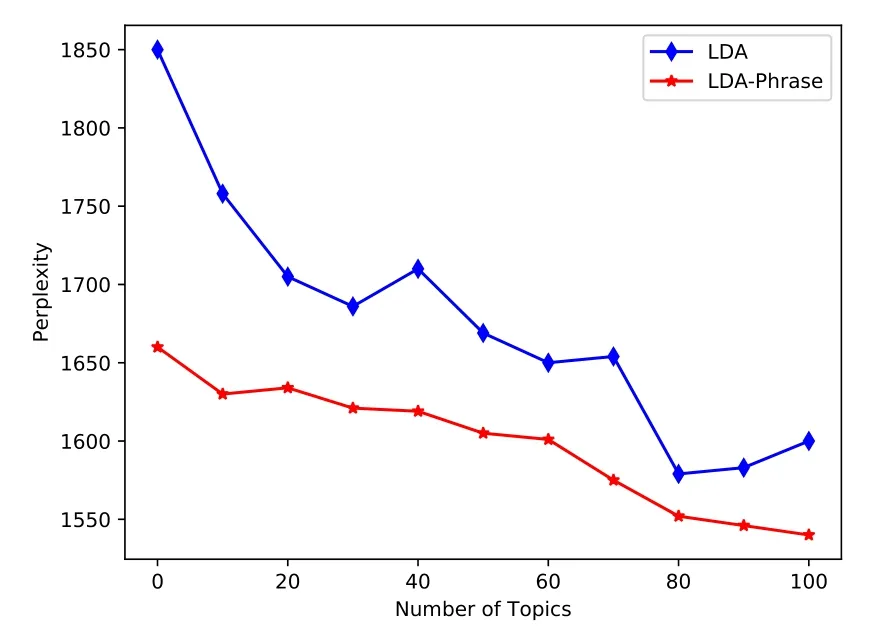
Figure 3.Comparison of LDA and LDA based on Phrase perplexity.
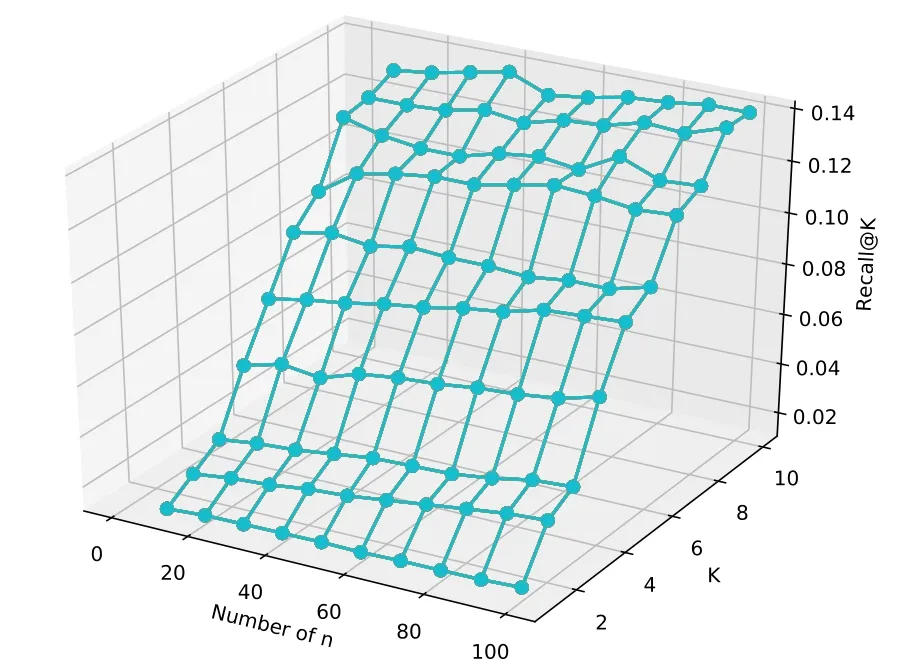
Figure 4.the recall of different number of topics under top-20.
4.3 Impact of Parameters
This study designs the personalized evaluation model in Eq.(5),and there are two parameters that influence the final score:numbers of topic and n phrases under each topic.These two parameters directly affect the dimension of user interest matrix and recommendations.This study first compare recall changes in the case of top-20,the number of topics ranges from 10 to 100,increasing by 10 each time.As shown in Figure 4,with the increase of topic number andK,theRecall@kpresents an increasing trend.It indicates that the performance of model recall is enhanced with increase of topic number.Figure 4 shows the change of the recall is relative to the average recall when theKvalue is the same.On the other hand,as the number of topics increases,the growth of recall also increases,and number of topic is 90 or 100 it is the maximum increase.The number of topics indicates its granularity.In this way,the semantic range of the phrases under this topic is smaller and the user’s intention can be expressed more accurately.Therefore,the recall will also increase.As seen from Figure 4 and Figure 5,the selection of topic number is directly influential to the recall of the model.In the impact ofnphrases under each topic on the recall,the default number of topic is 100,and the interval of eachnchange is 5.As shown in Figure 6,as the number ofnincreases,the overall recall also shows a trend of growth.However,it can be seen from Figure 7 that when n<=15,the overall recall is relatively low and the change is small,but when n>=20,the recall is increasing,but changes little.Moreover,when n<=10 and k>=5,the recall is reduced.Because the given top-n is not high,the user can extract fewer phrases,so the corresponding amount of resources cannot be found eventually.Therefore,the test experiment in the later is based on the parameters that the number of topic is 100 and n=20.
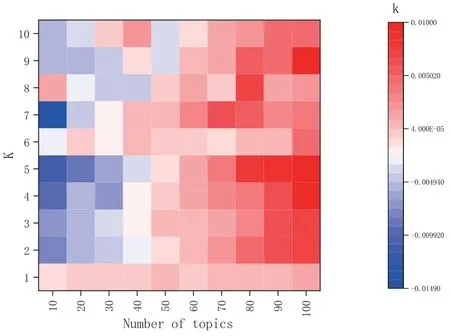
Figure 5.the increase of recall in different Topic numbers.
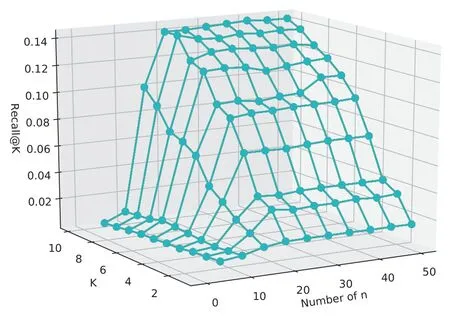
Figure 6.the recall rate under the change of n.
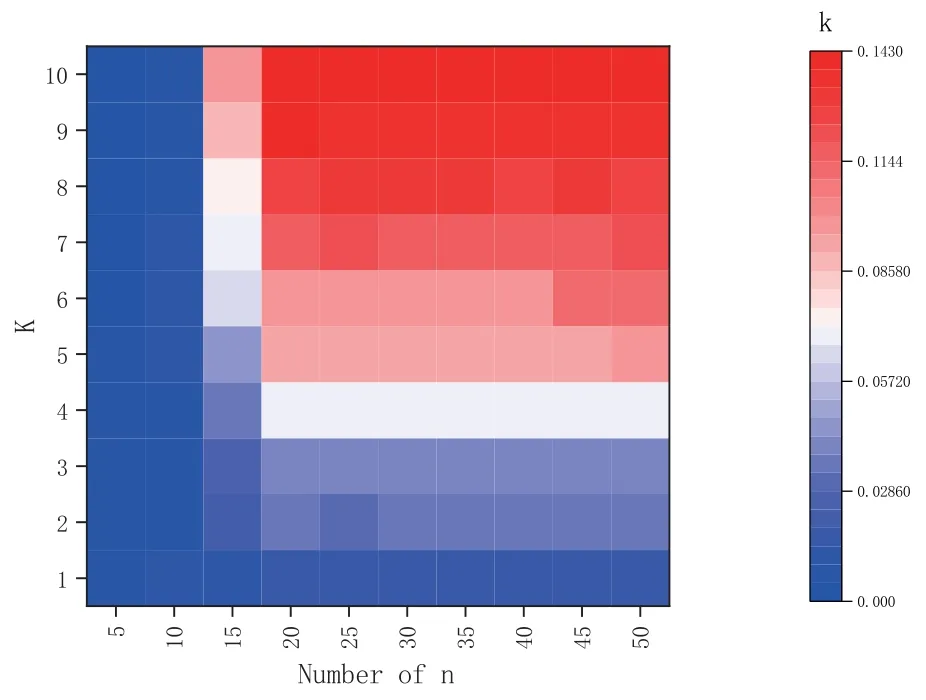
Figure 7.Heatmap of recall under change of n.
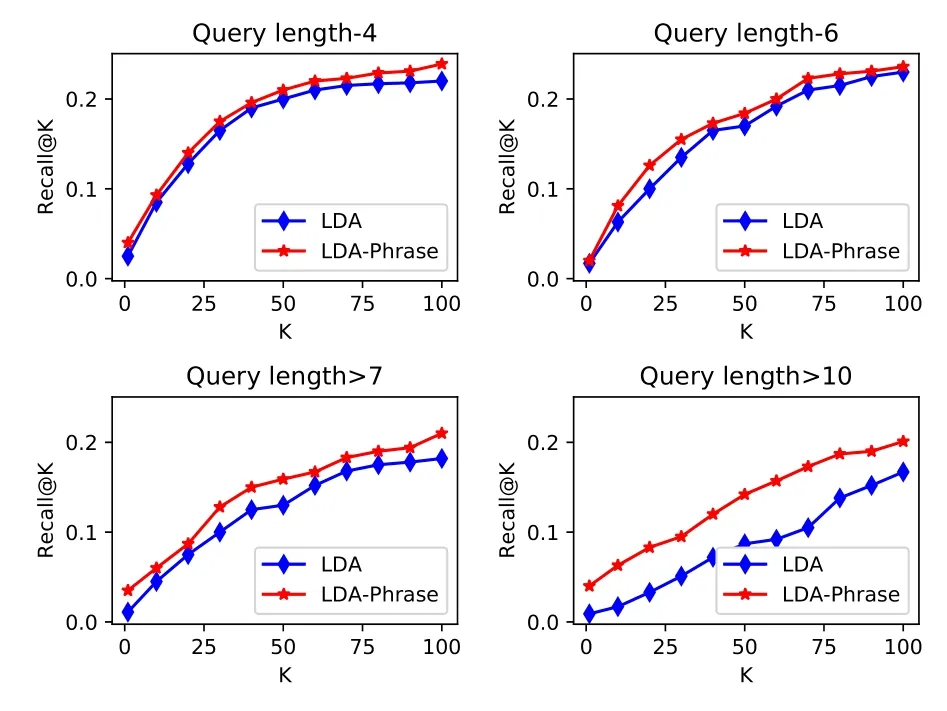
Figure 8.Comparison of recall under different query length.
In addition,this study analyzes the impact of query length on recall,as shown in Figure 8.When query length is 4,6,>7 and>10 are shown in the four diagrams,recall of recommended resources are respectively used by LDA model and LDA-Phrase model designed in this paper.Observing a large number of search sentences,we can find that if the given searches terms are relatively short,then due to the high generality and accuracy of the search terms themselves,the possibility of accurate search results relatively high.But if more than 6-7,the possibility of phrase division is more,then the range of search results is larger,and the general recall rate will also be reduced.As seen in Figure 8,when the length of the query is 4,the recalls of two models don’t change too much,but in the situation where the length is 6,>7 or>10,the recall based on LDA-Phrase model is higher than that of LDA model.In terms of phrase mining and model structure,the shorter the query length is,the less the semantic is expressed.Whenever the query length is more than 6 or 7 and the semantic range of the expression is large,the recall rate was improved by replacing phrases with highly used ones to better express the intent of the query.We can see that when the length of the query is>10,the gap between LDA and LDAPhrase is getting bigger and bigger than the other three diagrams.LDA-Phrase can basically maintain a relatively stable recall.In consequence,the experiment further illustrates that the query resource recommendation method designed in this study is more suitable for the query with relatively long.
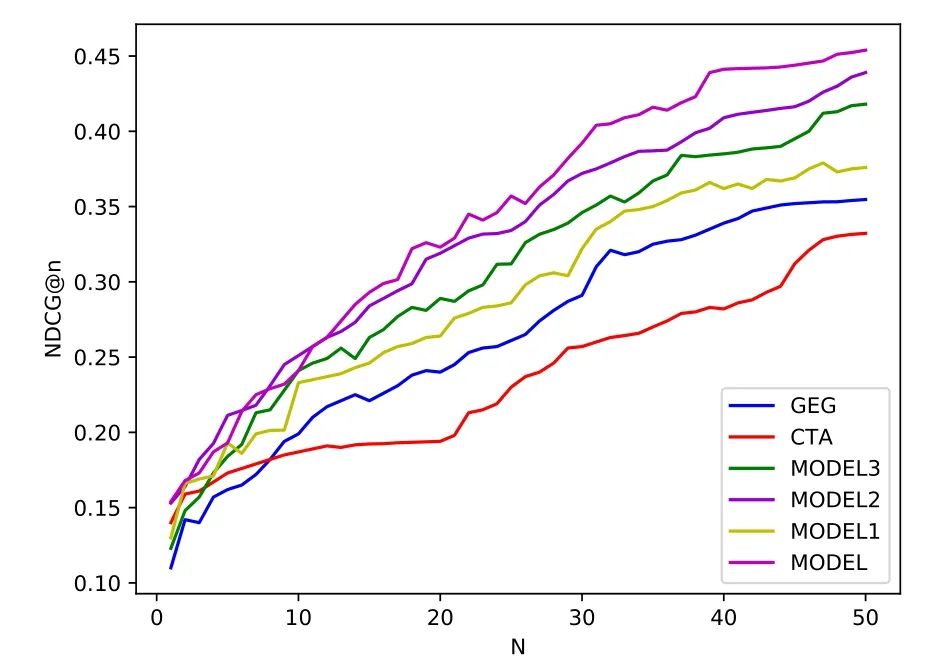
Figure 9.The NDCG@n comparison under the different models.
4.4 Query Recommendation Performance
In this section,we compare the list of query candidates recommended by methods designed in this study with the five candidate scoring models GenEdit(GEG)[35],context-based term association(CTA)[36],Model1[19]phrase query suggestion(Model2)[23]and Model3[37].The method of CTA based on observation,suggested that words with the same semantic often appear with same or similar words,and that use contextual correlation in historical queries to capture contextual similarity.GEG ranked candidates for input queries,predicting the score of each pair of input and candidate queries,and calculating the cost between the two queries as evidence of the association between the two words.Both methods were used to find candidates with strong relevance in terms of words to enhance the search performance.The LDAPhrase designed in this study can not only consider the latent semantics among words,but also find a list of words with strong relevance from the perspective of topics.Meanwhile,this model changes the basic unit of lexical expressions from words to phrases,to express the meaning more directly.The Model2 generates queries by extracting phrases connecting given query terms from the corpus.This paper believes that the use of phrase query has high accuracy,enough to express query intents.The Model1 extracts terminology documents from pseudo-related feedback documents,then models the topic of the term document,and uses recommendation strategies to infer the topic of the query[19].When extracting phrases or topics,these two models do not completely follow the user’s original expression habits,but find similar related terminology or corpus words through clustering.The Model3 was also from the perspective of words association.But when choosing the candidate words it uses the LDA model to establish the user profile,and then opts for candidate words according to scoring of user’s interest.In the design of final recommendation,this study also uses the user’s interest.The difference is that when we calculate user’s interest,we consider not only the user’s own interest classification,but also the hotspots in this interest classification.
We first use the phrase mining algorithm to divide query into multiple phrases,and then use LDA-Phrase to find a list of phrases semantically associated with each topic.After that,we use user-phrase interest matrix which connects to the user’s interest with web resources.We also compare the recommendations of above five models.The recommendation performance test will be evaluated by the measure of normalized discounted cumulative gain(NDCG)[38].For the given queryqi,the calculation formula of NDCG is as follows:
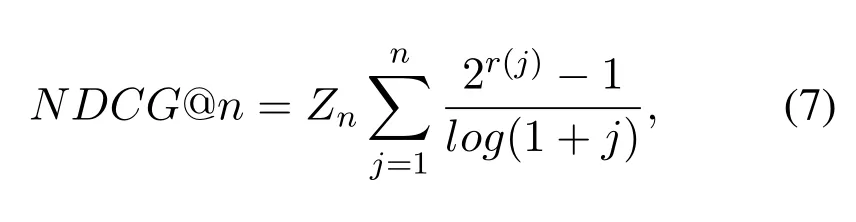
wherer(j)denote the rank of the jth query results.NDCG@n represents the evaluation score corresponding to the topnitems of the queries by the recommendation framework.If the query results are ranked higher in the recommendation list,the relevant query results contribute more to the score.In all the compared models in Figure 9,when n<30,the increase is relatively large.After n>30,each model gradually stabilized,and the change range was relatively reduced.Our model is not the best performing model in the initial range of n<10.But when n>15,the advantages of the model have begun to be reflected,and the NDCG value is higher than other models.It can also show that extracting semantics through topic models can improve recommendations.Within n<15,there is an intersection between our model and model2,which also indicates that the two models fit together.The main reason is that model2 and our model are based on topic representation,so the NDCG of these two models is higher than other models.After crossover,the NDCG value of our method is higher than model2,which further verifies that the phrase-based model is more helpful to the recommendation result than the single-word-based model.
V.CONCLUSIONS AND FUTURE WORK
This study proposes a query recommendation model based on LDA and LFM.Using phrases as a whole from the semantic level,the model can solve the situation where a single word expresses the query intention is unclearly.Moreover,the segmentation of phrases can better solve the problem of the inability to parse other natural languages such as user idiomatic expressions in queries.We find latent topics and topn phrases,and use these phrases and users to establish interest idioms matrix,so as to avoid recommending unsatisfied resources by misunderstanding users’query intention or idiomatic expressions.The experimental results also show that the proposed method is relatively low in perplexity of the model and can be applied to a large number of queries.
This study focuses on the phrase level,but there is still a lack of control over the overall query intent of the user.In future research,we will focus on the sentence level,grasping query intention for the whole sentence and combine the topics related to the context,so as to improve the satisfaction of the user’s search and predict the user’s next search field.
ACKNOWLEDGEMENT
This research is supported by the Hubei Provincial Natural Science Foundation of China[Grant Number 2019cfc880].We acknowledge the editors and other anonymous reviewers for insightful suggestions on this work.

- China Communications的其它文章
- Two-Timescale Online Learning of Joint User Association and Resource Scheduling in Dynamic Mobile EdgeComputing
- SHFuzz:A Hybrid Fuzzing Method Assisted by Static Analysis for Binary Programs
- SecIngress:An API Gateway Framework to Secure Cloud Applications Based on N-Variant System
- Generative Trapdoors for Public Key Cryptography Based on Automatic Entropy Optimization
- A Safe and Reliable Heterogeneous Controller Deployment Approach in SDN
- Distributed Asynchronous Learning for Multipath Data Transmission Based on P-DDQN