
基于VPU加速的嵌入式实时人脸检测系统设计与实现
2021-08-19 02:01张跃麟邓昌健
重庆大学学报 2021年7期
闫 嘉,张跃麟,邓昌健
(1.西南大学 a.人工智能学院; b.西塔学院,重庆 400715;2.电子科技大学 信息与通信工程学院,成都 611731)
近年来,计算机视觉不断蓬勃发展,卷积神经网络(CNN)[1-2]作为深度学习算法中重要组成部分,在图像分类[3],物体检测[4-5]以及图像重建[6-7]中已经大显身手,例如,活体检测、自动驾驶、无人超市等[8-10]。目前,计算机视觉的应用,例如,人脸检测和人脸关键点提取,主要运行于具有强大计算能力的图形处理器(GPU)[11]的云端服务器,即先将图片上传到服务器,运算之后再传回本次图片检测的结果,但这种方法需要大量的计算资源和高昂的设计费用;由于网络带宽的限制,上传图像和下载响应结果都有很高的时延,在实现本地视频流中实时检测人脸和关键点提取就变得尤为困难。此外,上传到云端的数据存在个人隐私被泄漏的安全风险;或当使用场景在地下停车库、穿山隧道等信号盲区时,云端计算的方式的就显得力不从心。
在实时目标检测方面,Ren等[12]提出Faster R-CNN,第一次提出使用“锚框”选择候选框,并结合边框回归、特征图共享的思想,采用非极大值抑制(NMS)、感兴趣区域(RoI)池化的方式识别物体,在GPU上实现了实时的物体检测;此后,Redmon等[13-15]提出了yolo网络,其检测速度相较于Faster R-CNN成倍增长。作者在此后又提出了改进后的yolo v2和yolo v3网络,提高了准确度,减少了检测用时。在实际应用中,Faster R-CNN虽然性能比较稳定,但是其非端到端的“两步”网络结构需要消耗大量的计算资源,增加了检测耗时;而yolo网络虽然更快,但在一些比较严苛复杂的环境中,并不能达到产品需求。为了能够结合这2种网络的优点,扬长避短,Wei等[16]提出了SSD网络,在不同尺度的特征图上,同时实现物体识别检测和物体边界框回归。其端到端和多特征图的网络结构,使其检测精度媲美Faster R-CNN,检测速度几乎和yolo相当。即使是在图像比较分辨率小的情况下,SSD都能够达到更高的检测精度。随着卷积层的增多,计算的时间也会更长,不利于便携式设备的实时应用。此后,谷歌大脑(Google Brain)团队提出了efficient net的网络模型,并以此提出了一种多维度混合的模型放缩方法,同时兼顾模型的速度与精度[17],然而这种方法需要针对特定的使用场景进行针对性的参数调整,极大延长了实际应用的开发周期。
在卷积神经网络实现人脸关键点提取方向上,Sun等[18]提出了基于级联卷积神经网络的人脸特征点定位方法,使用多个级联的CNN网络,根据“由粗到精”的思想逐步实现左右眼、鼻尖和左右嘴角的精确定位。Face++研究者以这篇文章为基础,采用四级级联网络结构,结合“由粗到精”的思想,实现包含眉毛、眼睛、鼻子、嘴巴共计51个内部关键点,人脸轮廓共计17个外部关键点,总计68个关键点的精确检测[19]。此外,Zhang等[20]提出一种多任务级联卷积神经网络(MTCNN),同时解决人脸检测和5个人脸关键点定位问题。而使用神经网络实现人脸特征点提取的科研者,大多使用“由粗到精”的思想,采用的多级网络结果也大大增加了计算时间的训练成本。Feng等[21]则在2017年提出了一种人脸特征点提取专用的loss方程:Wing loss,这是第一篇在人脸关键点检测任务上对损失函数进行分析的文章,使其对小误差更加“友好”,实验结果也表明,相比于传统的L1,L2以及smooth L1方程,Wing loss误差更小。
在嵌入式硬件平台上,树莓派作为一种基于ARM架构的开发板,能够支持运行Linux操作系统,支持1 080 P高清视频解码,CPU可以稳定工作在1 GHz,已经广泛用于教育[22]、智能遥控设备[23]、物联网开发以及智能家居[24-25]等领域。1 GHz的CPU运算频率并不能满足深度学习应用的计算资源需求,需要借助专用的视觉加速模块,如现场可编程门阵列(FPGA)或通用加速模块。
在近年来FPGA实现加速的研究中,为使FPGA针对特定的网络进行优化设计[26],达到高速运算的需求,刘谦让等[27]在2018年利用CNN卷积神经网络中存在着较多稀疏特征的特性,充分挖掘CNN卷积运算稀疏性的特点,结合FPGA并行矩阵乘法器的实现方法,能够实现相比于传统CNN加速器19%的提速。而张榜等[28]再次提出使用数据量化的方式将浮点数转为定点,降低运算开销,并提出从FPGA发起数据访问的架构,避免FPGA性能下降的问题,在实际实验中,性能功耗比达到了6.81 GOPS/W。使用FPGA进行定制开发,需要了解整个算法的流程以及数据的输入输出形式,结合FPGA的特点设计相应的加速结构[29];由于高端FPGA价格昂贵,研发需要大量的人力物力进行支撑,因而在成本预算和研发时间上,并不适合快速的开发和应用场景。为能实现使用神经网络加速模块的快速开发和使用,Intel公司自行研发了MYRIAD加速芯片,芯片的核心部件是向量计算单元,其小于1块硬币的尺寸使其可以容纳在1个类似于U盘的加速棒中,并兼容Window以及Linux操作系统。作为一种通用图形处理加速模块,最新研发的MYRIAD X图形处理芯片能够提供大约1 TFlops的计算能力,搭建该芯片的视觉计算棒NCS2平均功耗仅约为1 W,同时,结合Intel发布的OpenVINO视觉处理包,开发者能够快速构建神经网络加速器,推动嵌入式人工智能产品的开发和应用。
基于上述分析基础,设计采用以树莓派4B为系统平台,结合Intel的视觉神经棒,采用基于残差模块搭建的卷积神经网络模型,在树莓派上实现实时检测人脸位置以及提取83个人脸关键点,并额外训练了另外3个网络模型作为对比。首次提出了以树莓派4B为平台使用视觉神经棒对基于残差模块的卷积神经网络进行加速的方法,并对其运行效果与另外3个网络模型进行了对比分析。基于低功耗的加速模块和嵌入式的开发平台,可以为当前在嵌入式设备中应用在线深度学习提供一种可行的方案,也可应用于无人机的自动避障导航设计、无人车的行为规划、关键场所的人脸识别等,具有较大的发展空间和商业价值。
1 人脸检测和关键点提取网络
为验证设计方案的可行性,总共设计了2个卷积神经网络:一个为人脸检测网络,用于实时检测人脸的位置和大小;另一个为人脸关键点提取网络,在实时检测出人脸位置后,提取出该人脸的人脸关键点,并计算出这些关键点在原图中的位置。
1.1 人脸关键点网络
鉴于SSD既结合了Faster R-CNN锚框的思想,即先验框[30],也结合了yolo采用“端到端”的网络结构。文中对该网络加以改进,提出基于残差模块提取特征的SSD。该网络使用残差模块进行特征提取,利用多个不同尺度的特征图产生多种不同的特征映射,并对应每一个特征映射到原图的位置,使用一个卷积过滤器来评估人脸的边界框和人脸的得分。
文中所设计的SSD网络不使用全连接层,而是使用由多个卷积层堆叠而成的特征提取骨架产生不同尺度的特征图,而后直接使用过滤器来过滤特征图产生的候选框。由于使用的VPU所搭载的图形处理芯片针对卷积运算进行了优化,所以部署以卷积层为主要结构的网络至VPU可更好地体现VPU对图像处理的加速效果。因在网络设计时,卷积层过多可能出现梯度弥散的问题,文中引入了残差模块[29],其主要思想是在网络中增加了“直连通道”,相比于以往的网络大多是对输入做非线性变换得到输出,残差模块则通过直接将输入信息直连到输出,保护信息的完整性,整个网络只需要学习输入、输出相差的那一部分,进而简化学习目标和难度,如图1(a)所示。根据实际需求,设计采用了2种残差模块,如图1(b)所示。其中,conv1,2S表示卷积核大小为1x1,步长为2,卷积类型为SAME的二维卷积。
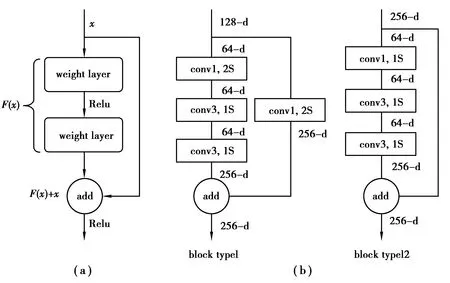
图1 残差模块
残差模块的设计原则为:
1)当残差模块输出特征相比于输入特征的大小减半时(即在残差支路和同等映射支路同时存在一个卷积步长为2或者存在一个2×2的池化层),输出特征的通道数相比于输入特征数量翻倍。在这种情况下,同等映射的方式为:使用卷积核大小为1×1,卷积步长为2的卷积核对输入特征进行卷积运算,使同等映射的输出特征的通道数量为输入特征的2倍,如block type1所示;
2)对于残差模块输出特征和输入特征的大小相同的层(即模块中所有的卷积步长为1),输出特征相比于输入特征具有相同通道数,如block type2所示。
在此基础上,根据SSD网络的实际需求,使用残差模块搭建的特征提取单元,如图2所示。每一个特征提取单元输出一个不同尺度的特征图,用于预测人脸的位置和每个人脸预测框的得分。

图2 特征提取单元
根据上述设计的残差模块以及特征提取单元,设定人脸检测网络的图片大小为384×512像素,设计基于SSD网络框架的人脸检测网络,如图3所示。残差模块的数量越多,得到的特征图能够反映原始图片中更加深入的细节,例如,物体的边、角、形状等信息[30]。但考虑到嵌入式系统的实时性和可用性,只需要经过5个block type 1和4个block type 2残差模块得到初始的feature map即可;再次经过2个特征提取单元feature extractor提取更加深层次的特征,最后将有3个不同尺度的特征图用于人脸位置和得分的预测。

图3 人脸检测网络结构
1.2 关键点提取网络
使用SSD结构搭建人脸检测网络后,可以继续对检测到的人脸进行关键点提取,检测关键点分别包括脸部、眼睛、眉毛、嘴唇、鼻子轮廓共计83个关键点。人脸关键点提取网络在卷积特征图后连接的是全连接层,即内积层,并非在卷积特征图后连接的卷积层,即卷积过滤器。因为卷积层输出特征的一个点对应的感受野是原图上的一个区域,而全连接层每一个输出节点所对应的感受野则是整个图像,能够更好地学习到人脸关键点的特征和该人脸关键点输出位置之间的联系。而人脸关键点提取网络的搭建依旧采用节1.1中所述的残差模块,其网络结构示意图,如图4所示,其中fc表示全连接层(full connection layers),设定该网络的输入图片的大小为128×128像素。

图4 人脸关键点提取网络结构
2 系统设计
为了能够合理调用软件和硬件资源,充分发挥视觉神经棒的功能,文中基于python设计了一套整体系统用于实现实时人脸检测和人脸关键点提取。根据人脸实时检测的功能需求分析,进行人脸检测的每一帧可以从3个渠道获取:摄像头、本地视频和本地图片。而进行推理运算的设备可以分为2类:CPU和视频处理器(VPU);此外,人脸关键点提取需要在一张图片数据中首先找到人脸的位置,因此,人脸检测是人脸关键点提取的必要条件,系统界面如图5所示。

图5 设计系统界面
图5中的标注分别为:①图像显示区域。实时显示每一帧的图像以及检测结果。②状态显示区域。显示当前程序运行状态,如初始化UI、加载模型、切换设备等。③设备选择。选择推理模型运行的设备,即选择基于CPU或者VPU运行。④选择图像帧来源。每一帧图像获取的来源,支持使用摄像头或者本地媒体文件。⑤选择人脸检测和人脸关键点提取。在勾选后执行检测任务。⑥选择本地媒体文件。当使用本地媒体文件作为图像数据来源时,用于选择待检测的媒体文件。⑦检测开始或检测停止。切换“开始检测”和“停止检测”的状态。
设计的人脸检测软件系统的整体工作流程,如图6所示。为3个主要步骤:第一,初始化UI界面和各个控件的功能;第二,将训练好的人脸检测网络和人脸关键点提取网络分别加载到CPU运行环境和VPU运行环境;第三,打开摄像头后获取视频流,读取每一帧图像,实时检测人脸的位置并提取相应的人脸关键点,并显示检测结果。

图6 软件系统整体流程
3 训练和实际测试
系统涉及的卷积网络模型由tensorflow(python)深度学习框架进行搭建,使用GPU(GTX 960M)进行并行加速训练,得到的网络模型使用OpenVINO工具包转换为视觉神经棒可加载的推理模型,并将整个系统部署到树莓派linux系统运行。为了能够体现出残差模块的引入对文中神经网络SSD的改进效果,使用相同数据集训练了未经改动的使用VGG网络作为骨架的原版SSD300网络,通过对比SSD300与文中SSD网络的运行效果即可得出残差模块的作用。此外,为了使实验现象更具说服力和代表性,还使用相同数据集额外训练了yolo v4和yolo v4-tiny 2个较为新颖的网络模型与文中SSD网络进行对比实验。额外选取的2个网络输入图大小为416×416,与SSD网络的输入图(512×384)大小相近,均不使用全连接层,且均采用多尺度预测的结构,与SSD网络具有一定的相似性。
3.1 数据集
训练样本数据来自2 000人的175 700张包含了亚洲人脸的样本图片,而验证样本数据来自于其他200人的18 025张相同大小的人脸图片。每一张图片大小为400×400像素,每个人有从50张到100张不等的不同场景,不同姿态的图片样本,人脸位置和关键点由Face++标注。每一张人脸图片有且仅有一个人脸数据文件,其中包含了所有的人脸框和其对应的83点人脸关键点的数据。
此外,假如训练的样本过于单一,例如,在样本中人脸的位置始终处于图像的中间部分,这样的样本训练出来的模型,也只能在图像的中间部分能够比较准确地检测人脸,这种网络便失去了泛性。本次模型的训练过程中,使用数据增强的方式,一来增加训练的数据量,从而提高网络的泛化能力;二来也可以增加噪声数据,提高模型的鲁棒性。数据增强的方式采用了:随机水平翻转;随机顺时针-20°~20°;随机等比缩放0.5~1.2倍;在保证人脸不超出图像范围的情况下随机平移,以及随机图像背景,如图7所示。

图7 随机数据增强示例
3.2 训练网络模型
在网络模型的训练过程中采用了指数衰减学习率方法,将SSD网络及关键点提取网络的初始学习率设置为0.000 1,衰减因子设置为0.95,每批次输入样本数量分别设置为1和20,使用GPU分别训练60 000次和50 000次。作为对比组的其他3个网络,将yolo v4和yolo v4-tiny的初始学习率分别设置为0.001和0.002 6,在每批次输入32个样本的条件下均训练5 000次;将SSD300的初始学习率设置为0.000 01,每批次输入16个样本,进行10 000次训练。
为了客观表示并评价设计的有效性和实用性,首先建立了模型需要的人脸数据集,以查准率和召回率作为人脸检测模型的评价指标,见式(1)和式(2);并以平均像素误差作为人脸关键点提取的评价指标,其中,precision和recall分别为查准率和查全率,TF和NF分别表示检测出人脸中,检测正确和检测错误的数量,而GT表示真实的人脸数量。
(1)
(2)
在人脸检测网络中,设定检测到人脸框相比于真实框的最大交并比大于0.8时,认定该预测框检测到了正确的人脸结果,否则检测到的是错误的结果或者预测人脸框的偏移量较大,人脸检测网络及对比实验网络在测试集中的表现结果如表1所示,其中,SSD网络的查准率为90.41%,查全率为89.0%;SSD300的查准率为73.42%,查全率为72.52%;yolo v4和yolo v4-tiny的查准率分别为94.93%和84.03%,查全率分别为93.90%和81.96%,人脸检测网络表现良好。此外,对比文中SSD网络与原版SSD300网络的测试效果可发现,残差模块的引入极大地改进了性能,查准率和查全率均提高了近17个百分点。
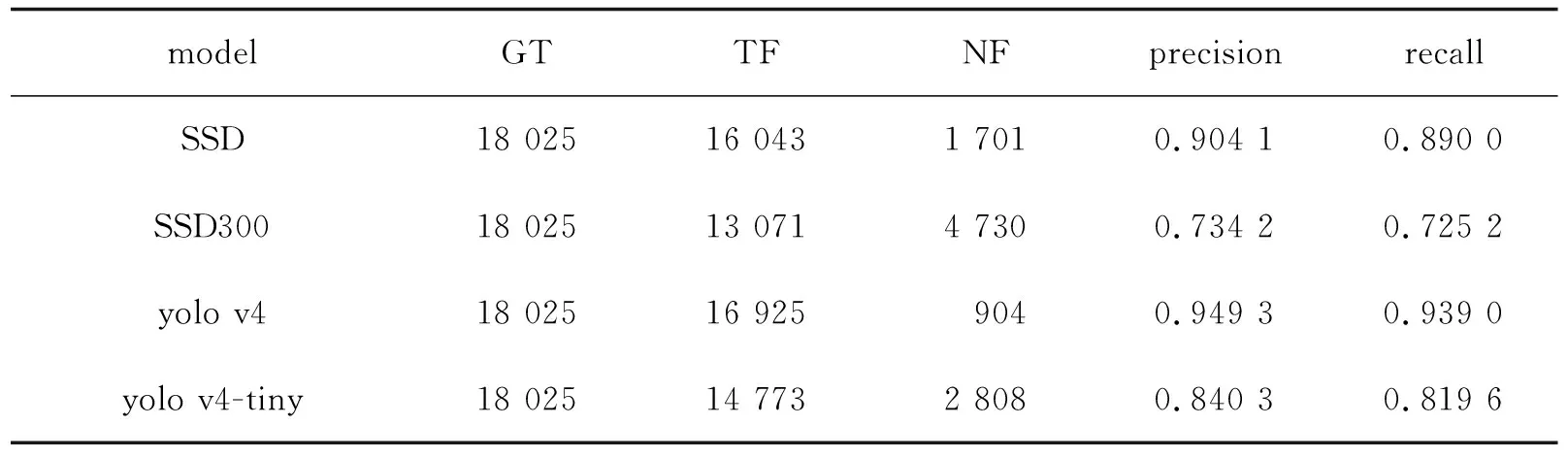
表1 人脸检测网络测试效果
为分析人脸关键点网络的性能,使用包含200人,18 025张图的验证集上,对每一张图片随机顺时针旋转-20°~20°,再次进行20 000次关键点的提取测试,统计了误差大小和误差场次之间的关系。如图8所示,N(errori)表示在像素误差为error条件下的图片数量,其条件概率为p(N|errori),mean value表示验证集上所有图片的像素误差的加权均值为

图8 人脸关键点提取网络测试效果
(3)
3.3 CPU和VPU性能对比
设计中,树莓派CPU的运算精度为32位浮点数,而视觉神经棒VPU的运算精度为16位浮点数,为对比运算精度对设计的影响,给出了树莓派CPU和视觉神经棒VPU的SSD网络人脸检测和人脸特征点提取的效果对比,如图9所示,其中的(a)和(b)、(c)和(d)分别为使用树莓派CPU、视觉神经棒VPU的推理预测结果。图10和图11分别为SSD300网络、yolo v4和yolo v4-tiny网络的人脸检测和人脸特征点提取效果。其中,图10的(a)和(b)、(c)和(d)分别为SSD300网络使用树莓派CPU、视觉神经棒VPU的推理预测结果,图11的(a)和(b)、(c)和(d)分别为yolo v4-tiny网络使用树莓派CPU和视觉神经棒VPU的推理预测结果。由于yolo v4网络结构复杂且规模较大,使用树莓派CPU运行会因内存不足而失败,因此yolo v4只使用VPU进行人脸检测和人脸特征点提取,如图11(e)和(f)所示。在人脸位置检测和人脸关键点提取的实际测试中,使用CPU和VPU的预测结果受到计算精度的影响很小,预测的位置基本相同。

图9 CPU和VPU对比(SSD)

图10 CPU和VPU对比(SSD300)

图11 CPU和VPU对比(yolo v4 & yolo v4-tiny)
在此基础上,为体现使用视觉神经棒VPU进行加速运算对实时检测的重要性,在效果对比的基础上也增加了运算性能的对比。根据图9~图11的表现结果,总结为表2所示,其中T1、T2分别表示同时执行人脸检测、人脸关键点提取耗时和仅执行人脸检测耗时。从表2可以明显看出,在便携式低功耗终端设备的实际计算应用中,不管是同时进行人脸检测和人脸关键点提取,还是单独进行人脸检测或人脸关键点提取,VPU相比于CPU来说运行不同人脸检测网络模型的速度都取得较大的提高。

表2 CPU和VPU性能对比
具体来说,使用相同像素和大小的图片,同时进行人脸检测和人脸关键点提取,VPU相比于CPU的加速比最高可达18.40倍;在单独检测人脸位置任务时,VPU相比于CPU加速比最高可达18.62倍;除去人脸检测消耗的推理时间,单独执行83个人脸关键点提取时,对应加速比最高可达41.55倍。值得注意的是,使用VPU能够成功运行CPU无法运行的yolo v4网络,充分说明了VPU不仅能够加速网络运行,还能使资源有限的嵌入式设备得以成功部署较复杂的网络。通过分析不难发现,使用VPU进行加速,仅能使yolo v4实现较低帧数,这说明现有方法还存在网络选择不当的缺点,在下一步的实验中应选择更轻量的网络。
对表2中的结果进行横向对比可以发现,网络使用VPU运行消耗的时间与卷积层数量呈正相关关系。对比SSD网络与yolo v4-tiny网络,前者卷积层数量为后者的1.83倍,运行耗时(T2)为后者的1.53倍。对比SSD网络与yolo v4网络,后者卷积层数量为前者的2.58倍,运行耗时(T2)则为前者的8.08倍。由此可知,虽然VPU可加速神经网络的运行,但当网络规模达到一定水平时,运行耗时便会成倍增加,所以在VPU的实际使用中仍需控制模型体积。对比SSD与SSD300的表现,SSD300运行速度慢于SSD,可能与原版SSD300网络同时使用了6个不同尺度的特征图进行预测有关。进一步观察对比yolo v4-tiny和SSD网络使用VPU运行的加速比(T2)可知,加速比大致随网络层数增加而提高。由于yolo v4网络的层数比SSD网络的层数要多,虽然其加速比无法直接通过测量得出,但可大致猜测yolo v4使用VPU运行能够获得比SSD网络更高的加速比,即VPU对神经网络的加速效果随网络规模的增加而提升。
此外,使用树莓派CPU进行推理运算时,树莓派需要满载运行,运行功耗约为3.37 W,而使用VPU的运算功耗为1 W,仅为树莓派满载功耗的29.7%。通过对比可知,视觉神经棒VPU在视觉加速处理上有着较大的优势,而且功耗更低,速度更快,更适合在便携式低功耗终端设备的计算应用。
综合表1和表2可知,设计的基于残差模块的SSD网络无论是在耗时还是在准确度上相比原版SSD300网络都有了较大的提升,证明了残差模块的引入极大地改进了SSD300网络的性能。比较SSD与yolo v4-tiny可以发现,SSD以较复杂的网络结构实现了更高的精度,并且只带来了耗时的小幅度增加。此外,对比SSD与yolo v4的表现可以发现,虽然SSD在准确度上稍差于yolo v4,但其运行速度却显著快于后者,可见SSD在速度和精度上达到了更好的平衡,能以更短的耗时实现较好的效果。充分说明了文中设计方法的优越性以及创新性,在综合考虑运行速度和准确度的情况下能达到优于现有网络的效果。
3.4 实际场景测试
根据3.3节的结论,因嵌入式CPU受到计算资源的限制,使用视觉神经棒进行加速运算是一种可行的方案。在上述结论的基础上,进一步给出了在实际场景下,使用视觉神经棒进行加速运算的表现效果,图12为视频流中提取每一帧并使用SSD网络进行检测的结果。图12(a)所展示的是同时检测2个人脸并分别提取人脸关键点,耗时109.75 ms,检测耗时并没有因为人脸的增多而增加过大,且人脸预测框的大小、位置和关键点的位置都很符合实际;图12(b)展示了当有遮挡物遮挡了人脸后,该网络模型仍然能够检测出人脸的位置,但是提取的部分关键点因为遮挡的原因和实际关键点有部分误差;图12(c)中,当人处于侧脸时,依旧能够检测人脸位置,并较为准确地提取人脸关键点;图12(d)中则展示了人在张嘴,人脸拉长的情况下,依旧能够准确判断人脸位置,较为准确地表现出人脸关键点的位置,并没有因为一些复杂表情而受到影响。图13为使用SSD300网络进行实时检测的结果,使用与图12相同的姿势,图13的(a)、(b)、(c)、(d)分别为多脸、遮挡、侧脸和张嘴的检测结果,可见其运行效果良好。图14为使用yolo v4和yolo v4-tiny进行视频流检测对比实验的结果,使用了与图12相同的姿势进行检测,图14(a)和图14(e)为分别使用2个网络同时检测2个人脸并分别提取人脸关键点,图14(b)和图14(f)为2个网络在人脸被遮挡时的表现情况,图14(c)和图14(g)展示了2个网络存在一定误差的情况下分别成功检测出侧脸,图14(d)和图14(h)则展示了当人在张嘴时的检测情况,这2个网络在不同的帧率下同样实现了较好的效果,充分证明了VPU加速功能的普适性。

图12 实际场景测试(SSD)

图13 实际场景测试(SSD300)

图14 实际场景测试(yolo v4 & yolo v4-tiny)
4 结 论
使用视觉神经棒VPU加速计算模块,对于嵌入式系统中部署计算机视觉应用有着重要的作用和价值。文中设计并训练了2种网络:人脸检测网络和人脸关键点提取网络,额外选取了其他3种网络作为对比。经过优化训练部署到树莓派后,使用视觉神经棒VPU,在同时执行人脸检测和关键点提取、单独执行人脸检测和单独执行关键点提取任务时,相比于单独使用嵌入式CPU进行运算,加速比分别可达18.40,18.62,17.46倍,说明了设计方案的可行性和有效性,在此基础上,可以进一步在嵌入式系统上实现情绪分析、情绪识别、人物核验等功能,具有广阔的应用前景。此外,树莓派系统使用的是内存卡,其读写速度在一定程度上限制了树莓派和视觉神经棒的数据传输速率。下一步的研究重点包括:1)进一步实现基于嵌入式系统的在线情绪识别、情绪分析等功能;2)使用一种内存读写速度更快的嵌入式平台,以充分发挥视觉神经棒的性能;3)优化视频流中对每一帧图像的人脸和人脸关键点的预测和跟踪,利用当前帧的结果预测下一帧,加快检测速度和效率。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
电子制作(2017年17期)2017-12-18
中国酿造(2016年12期)2016-03-01
中国卫生(2014年2期)2014-11-12
奇闻怪事(2014年5期)2014-05-13
