
一种用于推荐系统的分类训练方法
2021-08-19 08:25周雕郝胜男
现代计算机 2021年21期
周雕,郝胜男
(华北理工大学人工智能学院,唐山063210)
0 引言
在数据爆炸式增长的时代,如何从海量数据中获取关键有效的数据是人们所面临的一个难题,而推荐系统的出现为这个难题提供了有效解决方案。过去,常用的推荐算法主要有基于用户的协同过滤、基于物品的协同过滤、基于内容的推荐、基于知识的推荐等,其中协同过滤是推荐系统中应用最为广泛的算法。
但是近年来,许多学者已经不再局限于研究传统算法,越来越多的推荐系统研究工作基于深度学习展开。例如,He X等人[1]提出了一种神经协同过滤框架,该框架结合协同过滤的思想,并使用神经网络代替传统的内积操作,是一种推荐系统通用框架。Cheng H T等人[2]提出了Wide&Deep模型,该模型由Wide部分和Deep部分组成,兼具较好的记忆能力与泛化能力。而在实际应用中,YouTube提出了一种基于DNN的视频推荐模型[3],该模型能够从百万视频数据中迅速生成候选集,并实现Top-K推荐。阿里巴巴提出了一种深度兴趣网络[4],该网络能够高效地利用用户行为数据并准确地捕捉用户的偏好特征。上述工作给推荐系统的研究提供了很好的建议。
一个良好的推荐系统往往需要高精度的数据支撑,然而现实中,用于模型训练的数据往往具有庞大、稀疏、噪声大等问题,这些问题给推荐模型的准确度、鲁棒性带来了极大的挑战。因此,提出一种分类训练方法,通过K-means[5]将训练集中的用户按照历史行为聚类成不同的簇,然后将各簇数据输入神经网络进行并行训练。由于各簇之间的相互独立性与簇内用户的相似性,神经网络模型能够更快地学习到用户特征与项目特征从而迅速收敛,另外,并行训练的方式也能进一步加快训练速度,且不影响准确性。
1 总架构
所提方法的总架构简化图如图1所示。
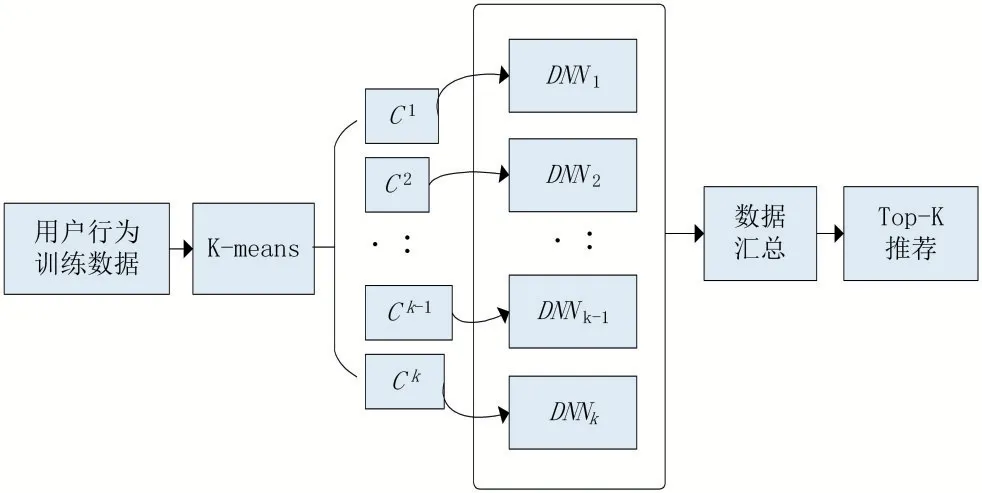
图1 模型基本架构
架构的核心组成部分为K-means聚类模块以及神经网络模块。其中K-means聚类模块的主要作用是将用户训练数据分为k个簇,而神经网络模块的作用则是对k个簇中的数据进行并行训练,最后将训练模型保存即可直接用于推荐场景。
2 基于K-means的用户聚类
在庞大的用户-项目行为稀疏矩阵中,由于用户数量与项目数量太多,用户与用户之间的偏好差异存在太大的不确定性,如果使用同一模型来对这些用户进行训练,那么模型很难“照顾”到所有用户的偏好规律,也就是说,模型难以较好地拟合所有用户。因此,在进行神经模型的正式训练之前,对所有用户进行分类,使得同类别中的用户在偏好上有着更高的相似度。而同类用户的聚类是进行用户分类的前提。
在K-means聚类步骤中,设定簇中心(或称质心)的个数为k,即训练数据将被划分为k个类别,所有训练数据的集合表示为Dtrain={C1,C2,…,Ck-1,Ck}。初始簇中心为随机生成,在聚类过程中,簇内用户紧靠簇中心,而簇与簇之间的距离较大,由此,用户按所属不同的簇中心而被区分开来,达到用户分类的目的。
进行正式聚类前,首先对训练数据进行预处理。训练数据中包含了用户的评分行为数据,但这些评分分值往往并不分布在0到1的区间内,为了减缓奇异样本带来的负面影响,因此需对所有评分数据进行归一化操作,使得所有分值分布于区间[0,1]内,对于评分记录i,归一化的变换公式为:

其中,xi为原始评分,xmin为所有评分记录中的最小分值,xmax为所有评分记录中的最大分值,为归一化后的分值。
聚类过程中,为了使用户找到合适的簇中心,采用欧氏距离来度量用户与各个簇中心的距离。并通过迭代使簇内用户之间的欧氏距离尽量小,而簇与簇之间的欧氏距离尽量大。设簇中心的特征向量维度为n,则簇中心u1与u2的欧氏距离通过以下公式计算:

如何达到良好的聚类效果是问题核心所在。在迭代过程中,需要站在全局角度来评估聚类性能,具体做法是通过反复计算所有用户与簇中心的距离之和来判断聚类效果的好坏。因此,K-means的最终目的是优化距离,优化过程公式为:

3 神经网络预测模型
在评分预测过程,使用DNN神经网络回归实现。DNN又称多层感知机,是一种典型的全连接神经网络,即上层的每一个神经元与下层的每一个神经元一一相连。全连接结构使得模型具有更强的特征表达能力以及泛化能力。图2为全连接结构示意图。

图2 全连接层结构
在本文所提方法中,由于采用并行训练的方式,因此需要同时构建多个神经网络模型,这些模型之间相互独立,且具有完全相同的结构和训练参数,被用来同时训练不同类别的用户簇。其中任意一个神经网络结构可以概括为图3所示。

图3 神经网络结构
该网络结构主要由用户与项目特征学习模块、全连接模块以及评分预测模块组成。
在用户特征学习中,为了更准确地学习到用户特征,不仅利用用户ID、年龄、性别等用户注册信息,而且还充分利用用户的行为序列。用户的行为序列中包含了许多用户的历史交互行为,其显性行为一般以评分形式呈现,而在实际推荐场景,用户行为还包括诸如点击、浏览等隐性行为,充分地利用行为数据可以使模型性能更好。而在项目特征学习中,主要使用项目ID、项目名称、项目类别等项目参数进行特征生成。
然而,用户与项目的初始特征往往以one-hot向量形式存在,one-hot向量非常稀疏,如果在整个神经网络中直接用one-hot向量进行训练,则会消耗巨大的计算成本。因此,用户与项目信息在进入神经网络的第一步就是进行Embedding嵌入操作。Embedding的作用是将用户与项目的高维one-hot向量映射成低维稠密向量,稠密向量经过两个全连接层即可得到完整的用户特征向量与项目特征向量。得到特征向量后并不能直接获得评分,接下来,将用户与项目特征向量进行特征拼接,再次经过两个全连接层,即可将高维拼接特征映射成一维预测评分。
在整个神经网络的训练过程中,包含向前传播与向后传播两部分。向前传播过程中,主要实现用户与项目特征学习以及用户对项目的评分预测,该过程中,采用ReLu激活函数,该函数具有易求导,能缓解梯度消失等特点,能够加快模型的收敛速度。对于第t个隐层,设输入为Xt=(x1,x2,…,xj-1,xj),输出为Yt=(y1,y2,…,yk-1,yk),则输入与输出之间满足以下公式:

其中,Wt为权重矩阵,Bt为偏置矩阵。在整个网络中,几乎所有层都是类似的计算方法,但是在Em⁃bedding层与最后的预测输出层并不设置激活函数。
在模型的反向传播过程中,使用MSE损失函数计算预测值与真实值的误差,并进行各层矩阵与偏置的更新。另外,使用L2正则化防止模型的过拟合。本文所提方法中使用的损失函数表达式为:

其中,n为单批次训练的样本数量,yi、y'i分别为真实值与预测值,T为总的网络层数。
4 实验与评估
4.1 数据集
实验中,选择使用公开的电影评分数据集Movie-Lens 1M和MovieLens 100K(https://grouplens.org/datas⁃ets/movielens/)对算法模型进行评估验证。其中MovieLens 1M中包含了大约6000用户对4000部电影的一百万个评分;MovieLens 100K中包含了大约950个用户对1600余部电影的十万个评分。其中,每个用户至少包含有20个电影评分记录。在实验过程中,随机选取80%的数据作为训练集,其余为测试集。
4.2 评估方法
由于本文所提方法最终实现评分预测,因此,在本文中,计算预测分与实际分之间的偏差是一种有效的性能评估方法,这类常见的方法有RMSE、MSE、MAE等。这些评估方法没有太大的本质上的差别,在本文实验中,选用RMSE和MAE作为评估标准,并且与经典的矩阵分解算法进行比较,验证模型的性能。
RMSE的计算公式如下式所示:
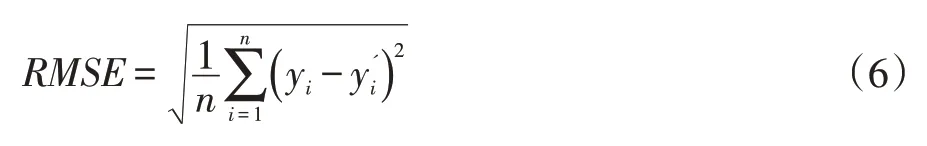
MAE的计算公式如下式所示:

4.3 实验结果
实验的训练与测试均在PyTorch深度学习框架下进行。为了验证所提方法的有效性,在模型性能测试环节,将所有分类训练的模型在测试集上进行了15次测试,并取平均值作为最终的测试结果。表1为所提方法与SVD[6]、AutoSVD++[7]、NNMF[8]等矩阵分解算法的RMSE、MAE结果对比,其中本文方法取所有分类训练的平均值。

表1 实验结果比较
从实验结果可以看出,本文方法相比传统的矩阵分解算法有着较大的性能提升,这是因为本文模型采用了神经网络进行评分预测,保证了模型的泛化能力的提升,其次,由于K-means聚类算法的引入,使得模型对于不同类型用户具有更好的适应性。
猜你喜欢
现代消化及介入诊疗(2022年2期)2022-11-22
北京航空航天大学学报(2022年8期)2022-08-31
舰船科学技术(2022年11期)2022-07-15
汽车实用技术(2022年10期)2022-06-09
中国教育信息化·高教职教(2022年4期)2022-05-13
南京理工大学学报(2022年1期)2022-03-17
煤气与热力(2022年2期)2022-03-09
汽车实用技术(2022年4期)2022-03-07
无线互联科技(2021年18期)2021-11-02
中国药学药品知识仓库(2021年18期)2021-02-28
