
基于分形插值核函数的支持向量机算法
2021-08-12 08:55梁礼明盛校棋
计算机应用与软件 2021年8期
梁礼明 郭 凯 盛校棋
(江西理工大学电气工程与自动化学院 江西 赣州 341000)
0 引 言
分形理论[1]是1973年由Mandelbrot为研究复杂无序而又具有某种规律的事物提出的。1986年,Bamsley提出了分形插值的概念,为分形的具体化提供了新的思想。分形插值理论将处理数据的复杂性与数据本身可规律化结合起来,来预测数据的走向、数据实值与区间值,已经获得较多成果并得到应用[2]。数据的这些属性具有不确定性和复杂性,分形插值利用已知数据点之间的关系,学习分析出潜在规律进行自相似性延拓,经过多次仿射系统迭代,可大大缩小样本数据预测值与真实数据值之间的差距[3],从而避免固定形式函数图像偏离真实数据而引起的较大误差。
对于分形插值的研究内容主要是分形插值方法与分形维数。分形插值方法[1,3]不像传统的数学插值函数或拟合函数是通过一组基函数的线性组合来表示,常用的基函数有多项式、有理函数和三角函数等初等函数,常用的分形插值方法是利用迭代函数系统[1,3](Iteration Function System,IFS)来实现的。摆脱传统函数具有固定函数公式与图像的形式,使得函数形式与图像更加逼近数据的真实值,同时函数及图像的形式具有较强的可塑性,有利于其在数据处理和拟合中的应用。
核方法[4]利用内积运算将通过非线性映射到高维空间的低维线性不可分特征向量,转化为低维输入空间的核函数问题,巧妙避免了低维数据线性不可分与高维空间计算复杂度高的问题。随着核方法研究的不断深入,核方法不再局限于固定的核函数,核函数也被引入插值函数来拟合对象间的相似关系[5]。文献[6]研究了核函数与插值函数的关系,Mercer定理要求核矩阵的半正定性,Shepard插值[7]利用距离倒数与统计学的原理确定核矩阵大大缩短了真实值与函数值的差距。对于插值拟合方法,训练样本数据越大通过该方法确定的函数值越准确。插值函数[8-10]在核方法中的应用得到持续研究,通过插值的方法不断拟合出与数据特性相近的核函数,但是这些方法局限性大。将初等函数设为基函数,其组合方式变化性太大,并且当数据复杂度过大时,计算难度加大。然而分形插值利用数据间的自相似性,通过对已知数据训练得到迭代系统进行经验数据拟合。当已知数据越多获得的数据的自相似性越贴近事实,同时分形插值在函数拟合中对于越复杂的数据拟合效果越好[1]。小样本数据由于特征的多样性具有较高的复杂性,利用分形插值拟合出来的核函数可以最大限度贴合数据本身属性。但是由于分形插值具有对数据的依赖性,每一个训练样本需要确定一个分形函数,能够使用满足自身数据集要求的核函数。
1 理论基础
1.1 支持向量机
定理1Mercer[4]定理。函数K是Rn×Rn→R的映射,且训练样本{x1,x2,…,xn}通过函数K得到的核函数矩阵为对称半正定矩阵,则函数K为有效核函数。
对于数据集D={(x1,y1),(x2,y2),…,(xn,yn)},其中xn∈RN为输入特征向量;yn为数据标签,即算法的评判指标。
将上述数据集特征向量通过非线性函数φ由低维特征向量空间映射到高维空间。在高维空间中利用风险最小化原理与分类间隔最大化思想,通过二次规划对高维空间特征向量进行处理可表示为:
(1)
s.t.yi·(ω·φ(xi)+b)≥1-ζi
(2)
ζi≥0i=1,2,…,n
(3)
式中:ω为分类超平面的权值;b为分类超平面的偏值;ζi为非负松弛变量;C为惩罚参数。
通过求解上述问题的拉格朗日对偶,问题简化为:
(4)
(5)
0≤ci≤Ci=1,2,…,n
式中:K(xi·xj)为满足Mercer条件的核函数。因此可得最优分类面的决策函数为:
(6)
上述分析可知,支持向量机利用核函数来表示数据集通过非线性函数φ将低维空间向量映射到高维空间向量之间的关系,进而得到最优分类面与决策函数并产生影响。
1.2 分形插值
分形插值函数同初等函数一样,是具有几何特征与科学的“公式”,但是与初等函数相比,分形插值关注的是集合,而不是单纯的点。分形插值的整体思想更能切合数据本身特性。该方法摆脱了初等函数的固定形式,能够更好地拟合出与数据特征相近的函数。对于分形插值的定义及分形插值的确认方法如下。
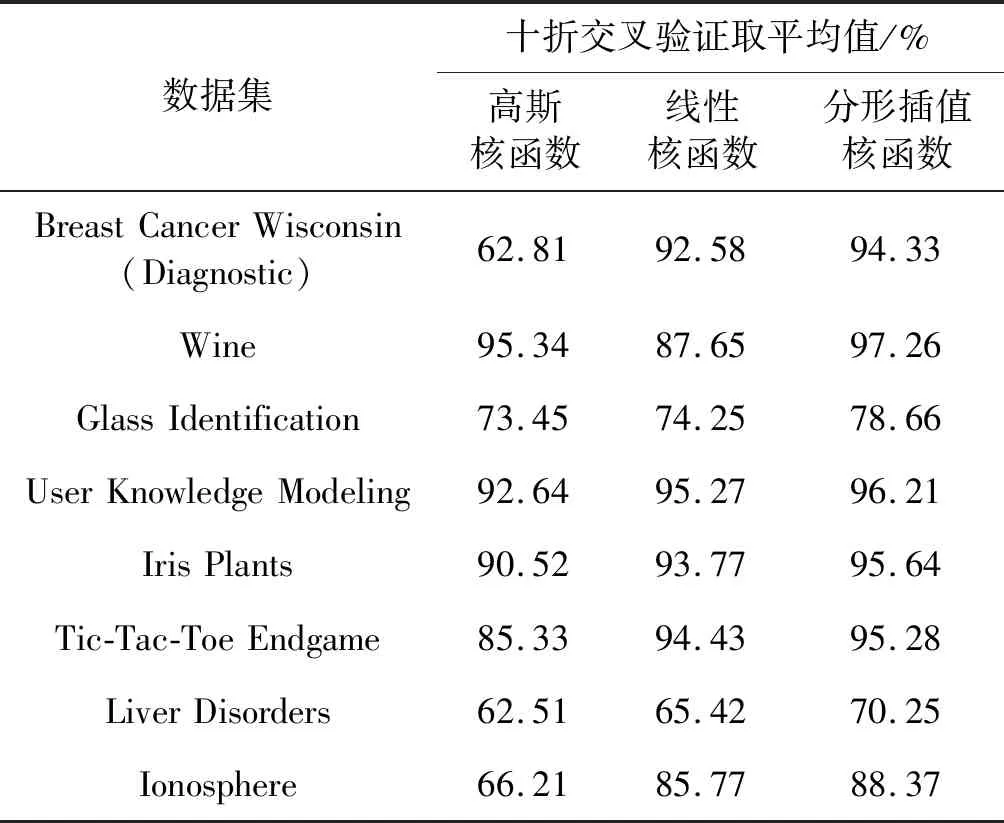
定义1任意数据集{(xi,yi)∈R2|i=1,2,…,N},其中x0 定理2对于给定数据集{(xi,yi)|i=0,1,…,N}建立迭代函数系统IFS。IFS={R2;Wn,n=1,2,…,N},其中Wn的仿射变换如下: (7) 并且 (8) 即: (9) 式(9)有四个方程五个参数,依据文献[1]可设dn为自由参量,|dn|<1,令L=xN-x0,则: (10) 定理3设{N>1|N∈N*},{R2;Wn,n=1,2,…,N}是数据集{(xn,yn)|n=0,1,…,N}的IFS,垂直定比因子dn满足0≤dn<1(n=1,2,…,N),则存在R2上等价于Euclid的度量d,使得这个IFS对应于d是压缩的。特别地,存在唯一一个非空紧集G⊂R2,使得: (11) 式中:f:[x0,xN]→R是连续函数且满足: f(xn)=ynn=0,1,…,N (12) 对于二维数据分形插值通过对已知点的分析建立迭代系统,利用迭代系统建立连续函数f。该方法通过已知点找到数据集的相似关系通过扩展迭代找到集合内其他点的值,充分发挥已知点的作用并能够更好地找到符合条件的分形曲线。 1.3.1训练样本内积的确定 训练样本内积值在保障能够反映同类样本与异类样本间的区别的同时要满足Mercer性质。文献[6]证明了训练样本的内积值确定的矩阵K只需满足半正定的要求即可,并且训练样本间内积值的大小对实验结果的影响并不大。因此本文选用1-0原则来区分同异类样本,即同类样本间的内积标记为1,异类样本间的内积标记为0。该方法能够有效地区分同异类样本同时将同异类差距最大化。在分类超平面的角度分析,理论上可以将两类超平面间的距离最大化进而保证分类的准确性。训练样本间的内积公式如下: (13) 根据子空间原理与矩阵的基本原则,任意由训练样本获得的训练样本内积值矩阵K均可变成如下形式: 很明显该矩阵为半正定矩阵,满足Mercer性质。传统的核方法利用核函数确定核矩阵,例如线性核函数:K(x,y)=xTy+c,它是利用向量间的内积及近邻原则来确定向量间关系的。在理论上分析,该方法会因为存在较大的交叉区域导致错分的可能性。而利用本文内积值确定方法大大缩短了同类样本的距离,同时拉大了异类样本的距离,可以最大限度地避免错分的可能性。 核方法从本质上是利用统计学的原理、近邻原则与概率事件的结合。核方法通过核函数的形式对向量间的内积进行不定比例的缩放(即相似性度量)达到放大问题区域、缩小稳定空间的目的,以更好地使用近邻原则,再通过概率事件(即每一个训练样本前的系数ω)与统计学原理对向量的类别进行预测分类。因此如何选择合适的核函数以达到预期目的至关重要。 1.3.2分形插值核函数 核函数在一定层面可以看作两个数据点的相似度量[11]。核函数本质是表达低维空间的数据映射到高维空间后的数据点之间的关系,而支持向量机通过计算已知数据点之间的关系建立分类面,再对未知数据点进行预测。核函数主要是通过改变数据点之间关系来增大预测的准确度。常用的核函数[12]有线性核函数、高斯核函数、多项式核函数和Sigmoid函数等,均通过扩大局部数据点关系差,缩短另一部分数据点关系差。理论上数据的亲疏关系越明确则数据的分类精度越高,因此核函数主要是扩大易错分空间的数据点的关系,核函数的选择与参数的调节都是为了调节交叉空间数据与核函数坡度较大区域的关系[13]。本文针对交叉空间易错分构建使用分形插值函数的分形插值核函数。 文献[6]指出核矩阵的构建只要满足核矩阵半正定即可,不需要有固定的核函数。因此本文的分形插值核函数没有固定的核函数,属于隐性核函数。 在疾病诊断技术逐渐发展的形势下,临床针对胃部疾病检查患者在进行诊断期间,口服速溶胃肠超声助显剂超声造影方法获得广泛应用,其凭借无痛苦、无创以及便捷有效的优点,使得临床应用接受度以及满意度极为显著,并且在应用后通常可以获得显著胃部疾病诊断效果。胃部疾病检查患者在选择超声助显剂进行口服后,于其胃肠道内部会表现出点状中等回声的现象,并且形态分布均匀,从而可以将胃肠道超声伪像显著减少,针对胃壁病变具体程度、范围、生长方式、肿物大小以及内部结构等可以进行清晰显示,并且同附近脏器表现出的系列关系可以进行充分明确,此外针对胃肠功能加以动态观察后,最终可以就患者病情表现展开评估工作[4]。 对于给定的数据集{(x1,y1),(x2,y2),…,(xn,yn)}随机选取一定量的训练样本,要保证训练样本中不同类别样本的数量,进而保证构建的分形插值函数的准确性。具体分段分形插值[14-15]公式如下: (14) 式中:r为待测数据点与训练数据点的距离;rφ为异类标签对应的最短距离;rφ′为同类标签对应的最长距离;fIFS为通过训练样本建立的分形插值函数。 分形插值函数的建立,训练样本中任意数据点(xk,yk)与其他数据点建立距离同异类关系(ri,fi),其中: (15) ri为数据点xi与数据点xk的距离。 以ri的大小值对距离关系进行排序,找出rφ、rφ′的值对处于rφ、rφ′之间的距离关系利用式(7)-式(12)为每一个训练样本构建分形插值函数。 (16) 式中:r表示数据点x到数据点xj的距离。 (17) 本节对本文算法的性能与有效性进行验证,实验仿真环境为MATLAB R2018a,运行于Intel(R) Core(TM) i5-700/2.50 GHz、8 GB内存,Windows 2007。本文实验随机选取每组样本的80%为训练样本,其余为测试样本。 本节利用高斯核函数、线性核函数与本文算法通过UCI数据集进行实验,验证本文算法的有效性。用于验证算法的数据集包括Breast Cancer Wisconsin(Diagnostic) Data Set、Wine Data Set、Glass Identification Data Set、User Knowledge Modeling Data Set、Iris Plants Data Set、Tic-Tac-Toe Endgame Data Set、Liver Disorders Data Set和Ionosphere Data Set八组数据集。实验结果均采用十折交叉验证,高斯核函数[16]和线性核函数[17]的公式分别为: K(x,xi)=e(-‖x-xi‖2/2σ2) (18) K(x,xi)=xTxi+c (19) 实验数据集信息如表1所示。本文算法与两种对比方法的比较结果如表2所示。图1所示为不同算法在八个数据集上的分类效果,其中x轴的1-8分别代表数据集Breast Cancer Wisconsin(Diagnostic)、Wine、Glass Identification、User Knowledge Modeling、Iris Plants、Tic-Tac-Toe Endgame、Liver Disorders和Ionosphere。 表1 数据集 表2 3种算法的分类比较 图1 不同算法分类效果比较 对表1和表2分析可知,当数据的特征数量越多时,本实验的精度提升越大,相反特征数量越少精度提升越不明显,由此论证了本文之前提到的分形插值的特点:数据的复杂度越高,分形插值函数越逼近真实函数。由图1可以明显地看出,本文算法相较于高斯核函数和线性核函数有较大的精度优势,并且不同类型的核函数,其度量特征各异,本文算法可克服核函数选择与参数设置的影响。 本实验通过对同一数据下不同数量的训练样本进行实验。比较不同数量的训练样本对实验结果的影响。本实验数据来自UCI的Iris Plants Data Set,本实验将鸢尾花的训练样本数量分别设为10、20、30、40和50,测试数量为100,通过5次实验取平均值的方法来测试比较本文算法与高斯核函数、线性核函数在同等的条件下,随着训练样本数量变化,分类准确率的变化,结果如表3和图2所示。 表3 鸢尾花分类准确率结果 图2 鸢尾花不同数量训练样本分类精度 由图2可以看出,随着训练样本的增多,高斯核函数与线性核函数先增长后逐渐持平,而本文算法缓慢增长且精度高于另两个算法。该实验的结果表明,随着训练样本数据的增多,通过分形插值方法拟合的数据集的分形插值函数与数据本身特性更贴切。因此本文算法优于传统核函数算法。 本实验在近几年支持向量机核函数文献中随机选取文献的数据集及实验结果。选取文献[18-19]的部分数据集并利用本文算法进行仿真实验。其中使用的数据集有Haberman Data Set、Ionosphere Data Set、Energy Efficiency、Sonar Data Set、Cancer Data Set,通过本文算法为各个样本数据建立分段分形插值,然后得到分类结果。本文算法与其他文献方法的分类结果比较见表4。 表4 算法分类精度比较 可以看出,在上述五组数据集中本文算法的实验结果皆优于文献[18-19]的分类精度,故本文算法有很好的参考意义。 本文利用分形插值思想、分段函数和概率分布,并结合相似度量特性充分发挥数据集本身度量特性,提出了一种基于分形插值的支持向量机核函数构造的方法。通过每个训练样本与其他样本之间的关系,为每一个训练样本建立合适的核函数,打破了固定核函数的模式与Shepard插值核函数大数统计学概率的模式。通过建立数据间的关系拟合出合适的函数关系图像,摆脱了核函数选择与参数设置的繁琐与影响。通过对UCI数据的仿真实验对比,论证了本文算法的可行性。但是本文算法仍有不足之处,由于没有固定函数公式,训练样本时需要确定每个样本的迭代系统,在确定测试样本值时需要通过IFS迭代仿射确定,因此本文算法计算的复杂度较高,运行时间较长。此外,本文利用特征向量间的距离为相似度量关系,在传统核函数中线性核函数和多项式核函数是通过对特征向量内积的度量方式来衡量数据间的关系。同时多核核函数多是以线性核函数、高斯核函数和多项式核函数为基核函数。因此使用不同的特征向量间的相似度量关系进行核函数分类实验及多种度量关系结合在一起的方式进行仿真实验是未来研究的主要任务。1.3 基于分形插值核函数的构造

2 实 验
2.1 算法比较


2.2 同数据对比实验


2.3 与相关文献比较

3 结 语
猜你喜欢
导航定位学报(2022年3期)2022-06-10
全球定位系统(2022年2期)2022-05-19
课堂内外(初中版)(2019年8期)2019-09-03
科学Fans(2019年2期)2019-04-11
领导决策信息(2018年16期)2018-09-27
城市地理(2017年9期)2017-11-02
科学Fans(2017年3期)2017-04-13
数学学习与研究(2017年3期)2017-03-09
新高考·高二数学(2015年8期)2015-10-23
计算技术与自动化(2014年1期)2014-12-12
