
基于自然语言处理的长期护理保险政策舆情研究
2021-08-11 07:39郑文渊西南财经大学
上海保险 2021年7期
卢 浩 郑文渊 西南财经大学
2020年9月,国家医保局会同财政部印发《关于扩大长期护理保险制度试点的指导意见》,随即在社交媒体平台上引发网民广泛讨论。本研究将以网民关于长期护理保险(以下简称“长护险”)政策的评论为研究对象,采用TF-IDF特征抽取、K-means聚类等方法,建立长护险舆情分布模型。结果显示,长护险政策舆情根据语义可分为五大主题,且舆情主题分布在地区上存在明显差异。本文在上述研究基础上进行深入分析,为我国长护险发展提出相关建议。
一、引言及文献评述
截至2019年底,我国60岁及以上人口达2.54亿,失能人数超4000万,失能人员长期护理保障问题成为社会亟待解决的问题。中共十八届五中全会公报提出“积极开展应对人口老龄化行动”,中共中央“十三五”规划纲要更明确指出“探索建立长期护理保险制度”。2020年9月10日,国家医保局会同财政部印发《关于扩大长期护理保险制度试点的指导意见》,拟在初步试点的成果之上进一步完善我国长护险政策框架。在我国人口老龄化加快的社会背景下,探索建立长护险制度成为解决失能人员长期护理问题、健全我国社会保障体系的重要途径。
目前,已有不少学者对长护险实施效果进行客观分析,并取得了一定的成果。陈鹤(2020)基于江西省上饶市调查数据,以描述性统计和定序Logistic回归分析受益人的满意程度及影响因素,结果表明,待遇水平、居家上门护理待遇给付方式显著影响长护险满意度;李元、陈立行(2019)选取长春市长护险制度实践数据,采用模糊综合评价法分析长护险制度实施效果,发现保障对象、资金来源、服务传递机制和照护人力资源等方面有待提高完善;胡蕊(2020)则抽取安庆市参加长护险的人员进行问卷调查,通过单因素分析和多因素分析,发现安庆市长护险实施存在护理费用昂贵、失能评估标准不科学、养老院护工短缺等问题。以上研究采用量化分析方法客观评估了长护险实施效果,但目前还没有文献针对长护险政策舆情进行评估。
在微博评论舆情研究方面,不少学者运用不同的自然语言处理算法研究了多个领域的政策舆情。汪芸霞(2019)通过微博平台上有关美团打车进入市场的评论数据,选择支持向量机和卷积神经网络对数据进行情感分类,得出总体评论以及不同情感类别评论的关注热点;刘虎(2020)对网民评论数据构建潜在狄利克雷分配(LDA)主题聚类模型,通过识别与“套现”共现的关键词找出导致后疫情时代消费券“套现”泛滥的主要原因;鲁雨晴(2021)则对新型冠状肺炎疫情期间关于复工复学的评论数据进行情感分析,计算用户的情感倾向性、情感强度等,并使用K-均值聚类算法进行聚类,通过方差分析验证了三类地区文本数据中的负面评价比例存在显著差异。
综上所述,目前国内外学者已经在长护险的多个方面取得成果,且微博评论舆情研究也已经在多个政策舆情分析上进行了应用。但在梳理文献的过程中,我们发现,从长护险政策舆情的角度分析长护险制度构建的研究还存在空白。新浪微博是目前国内最大的社交媒体平台,该平台实时产生的社会热点话题能引发广大网民的广泛讨论,大量的评论数据比较具有代表性。因此,本研究将以网民在新浪微博中关于长护险政策的评论为研究对象,采用TF-IDF特征抽取、K-means聚类等自然语言处理方法建立舆情分布模型,并探究舆情分布在地区上的差异,为建立并完善长护险制度提供参考。
二、模型基础介绍
(一)TF-IDF模型
TF-IDF(Term Frequency-Inverse Document Frequency)模型,是一种用于评估某一词语在语料库中的某一条语料中的重要程度的特征抽取算法。该模型的核心思想为:如果某个词语在一条语料中出现的频率很高,而在其他语料中出现的频率较低,则该词语可以反映该条语料的主题特征。
词频(Term Frequency,TF),指语料库中某条指定文本中某个词语在该文本中出现的频率。某个词语在指定文本中出现的频率越高,则该词语与该文本主题越相关。TF值可表示为如下公式:
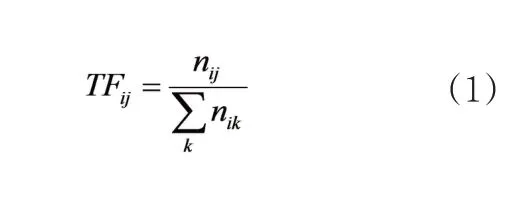
式(1)中,nij表示语料库中第j个词语在di这条文本中出现的次数。
逆文本频率(Inverse Document Frequency,IDF),指语料库中某个指定词语在整个语料库中出现的频率。为了平衡常用词语的频率,需要通过IDF降低常用词在指定文本中的权重。IDF计算公式可表示为:

在式(2)中,│D│表示语料库中的文本总量,│{j:ti∈dj}│表示语料库中包含词语ti的文本数量。为了避免分母出现等于0的情况,分母通常使用1+│{j:ti∈dj}│。
TF-IDF的值等于TF值与IDF值的乘积,如式(3):

(二)PCA模型
上文提到的TF-IDF模型得到的向量空间存在一定的缺陷:随着文本数量的增加,向量空间维数增大将造成向量空间维度过高的问题;同时,某一特定文本中不会出现的词语也会不断增多,导致矩阵稀疏。为了解决向量空间的高维数和稀疏性问题,需要对向量空间进行降维处理。
主成分分析法(Principal Component Analysis,PCA),是一种使用最为广泛的数据降维算法。主成分分析法将高纬度的变量转化为低纬度的主成分,低纬度的主成分由多个多维度变量线性表示,能够保留变量中的有用信息,用少量数据反映原始数据的特征。
(三)K-means聚类算法
K-means聚类算法是机器学习领域一种典型的无监督学习算法,其主要思想是两个目标的欧式距离越近,则相似度越大。K-means的算法步骤如下:
1.确定聚类类别数目K;
2.初始化k个样本作为聚类中心c=c1,c2,...ck;
3.分别计算每个样本1到k个聚类中心的欧式距离,并将其分到距离最小的聚类中心所对应的类中;
4.重复步骤2、3,直至达到设定的终止条件。
K-means聚类算法使用场景广泛,包括文本分类、客户分类、保险欺诈监测等。文本分类是K-means算法分类的典型使用场景,根据文本向量化后的向量空间,K-means算法可以有效地将文本分为多个不同类别。
三、实验过程与结果分析
(一)研究对象及数据预处理
1.研究对象
2020年9月27日,微博话题#社保第六险要来了#成为新浪微博热搜榜第二名。网民在该话题下的大量评论为长护险政策舆情研究提供了数据基础,因此,本研究的研究对象为网民在#社保第六险要来了#话题微博中的评论。
2.数据获取
本文在requests库、json库等第三方库的基础上,自主开发了基于模拟登录的网络爬虫程序。通过该程序共获取了1471条关于“社保第六险”的微博评论,其中792条为一级评论,即对微博内容的评论;679条为二级评论,即对一级评论的评论。
3.数据预处理
(1)数据去重
对数据进行去重,删除原始数据中出现两次及以上的评论,仅保留其中一条。
(2)删除表情、转发、回复、网址、图片等无关内容。
通过正则表达式对评论中的无关内容进行匹配,用空字符代替匹配到的无关内容。
(3)分词
本文在jieba第三方中文分词库的基础上,加入了“长期护理险”“五险一金”“延迟退休”等与长护险相关的特殊词汇,提高了微博评论文本分词的精确度。
(4)去除停用词
为了提高文本量化和文本聚类的准确度和效率,本文采用《哈工大停用词表》,去除了文本中如“万一”“不仅”“可是”等停用词。
4.预处理结果
经过数据预处理后,剔除评论内容预处理后变为空值的评论数据,并人工剔除评论中与长护险明显不相关的评论内容,最终共保留867条评论数据,可初步绘制评论数据词云,如图1。

图1 评论数据词云
(二)实验过程及结果分析
1.特征抽取
将预处理后的评论数据形成语料库并建模,得到语料库的向量空间D867×2738,向量空间D867×2738包含了语料库中所有词语分布情况的信息。
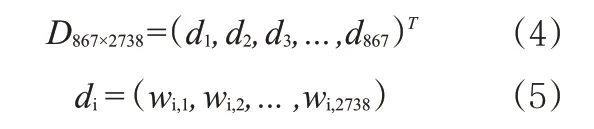
其中,di表示向量空间中第i条评论的向量;wi,j表示第i条评论中第ij个特征项的权重。
TF-IDF平均值最大的10个热词如表1所示。

表1 TF-IDF平均值前十大热词
2.向量空间降维
通过PCA模型将原始向量空间D867×2738降维至指定维度m,从而得到新的向量空间D'867×m。由于向量空间的高维度和稀疏性,传统的方差贡献率法在选择向量空间维度m上失效。考虑到PCA模型主要是为了提高K-means算法的精度和效率,本研究中采用通过观察K-means聚类效果选择向量空间维度的方法,经过不断试验,最终选择m=27作为向量空间维度,降维后得到的前五大主成分与权重最高的前十大特征项的线性关系如表2。
3.评论聚类分析
(1)聚类数目的选择及K-means聚类—人工语义分类过程
由于向量空间的高维度和稀疏性,且TF-IDF模型具有无法处理一词多义与多词一义情况的缺陷,本研究提出基于K-means聚类—人工语义分类过程的聚类数目选择方法,经过反复试验,最终选择聚类数目n=20较为合适,聚类可视化结果如图2。
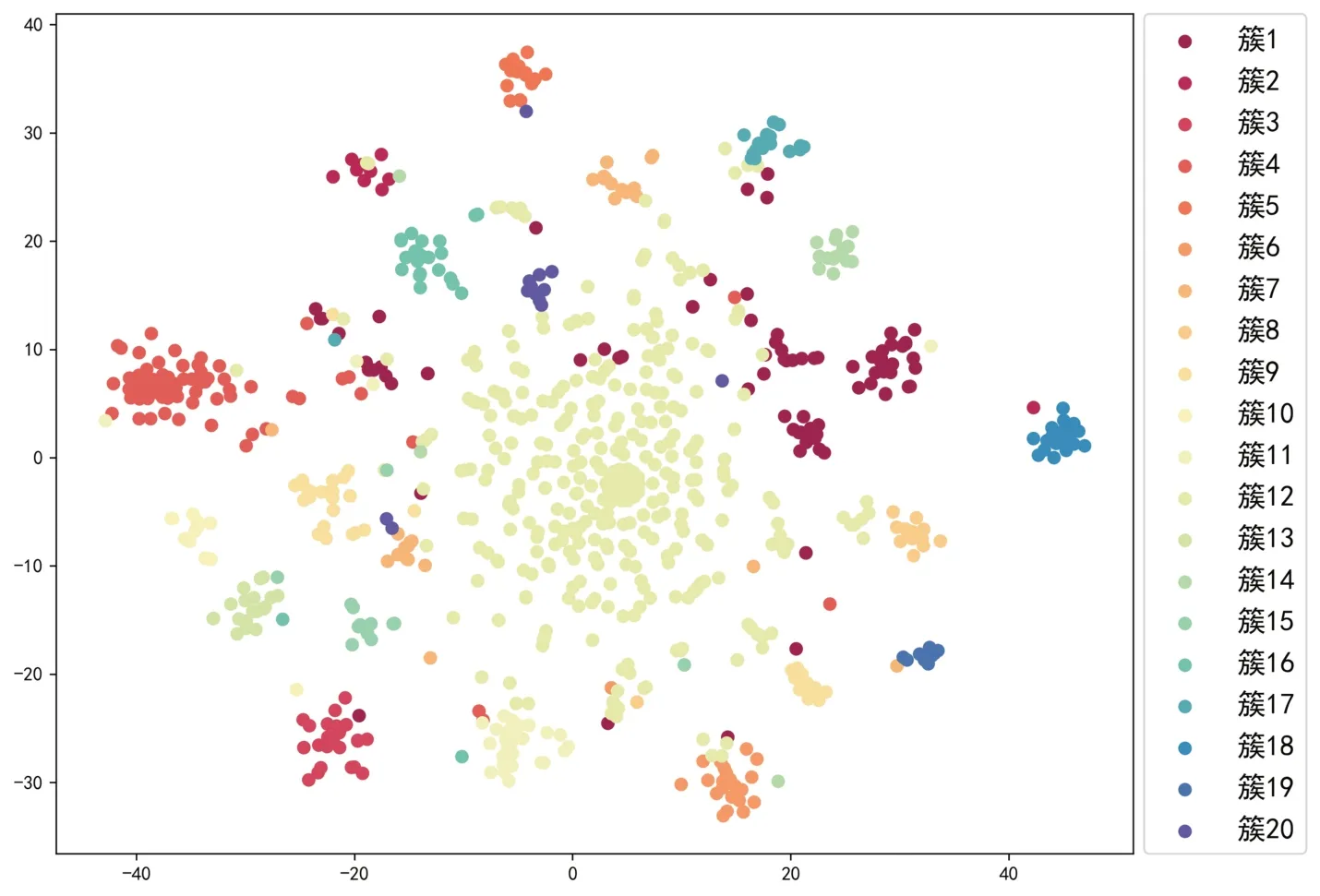
图2 K-means聚类可视化结果
基于K-means聚类结果进行人工语义判断,20个簇群中有8个簇群为与长护险弱相关的数据;剩余12个簇群的强相关评论可根据语义分为5类,其主题可分别概括为护理质量、缴费负担、普及程度、实用价值和享受期限。
(2)强相关评论聚类结果分析
剔除聚类结果中不能提供有关长护险政策舆情信息的弱相关评论,主要分析强相关评论聚类结果,聚类可视化结果如图3。
从图3中可以看出,普及程度是长护险舆情中最突出的主题,该主题共包括了7个簇群。其次,实用价值是长护险舆情中的第二大主题,并且该主题下评论数据分布相比于其他主题更加分散。各主题在长护险舆情中的具体占比如图5。

图3 强相关评论主题分布
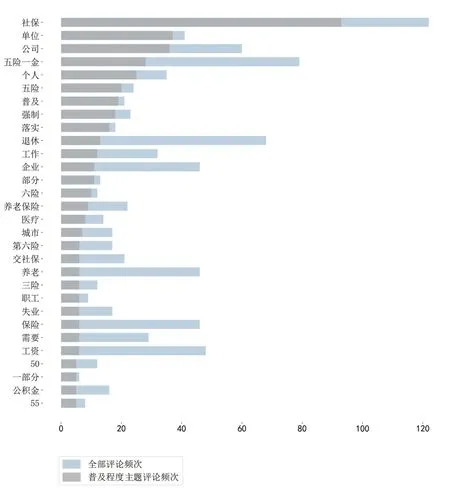
图4 全部评论及普及程度主题评论词频分布
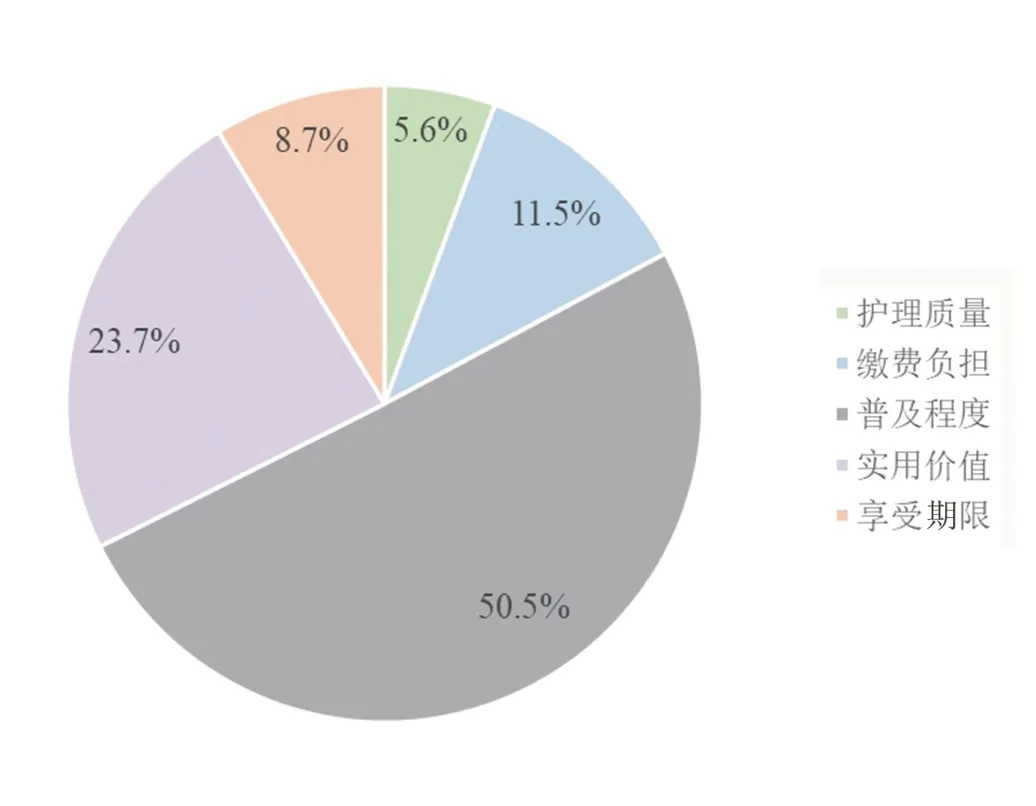
图5 各主题占所有评论数据比重
接下来分析各主题的词频分布情况,各主题的关键词各不相同,词频分布反映了各主题语义层面的信息,各主题的关键词和该主题下的代表性评论如表3。
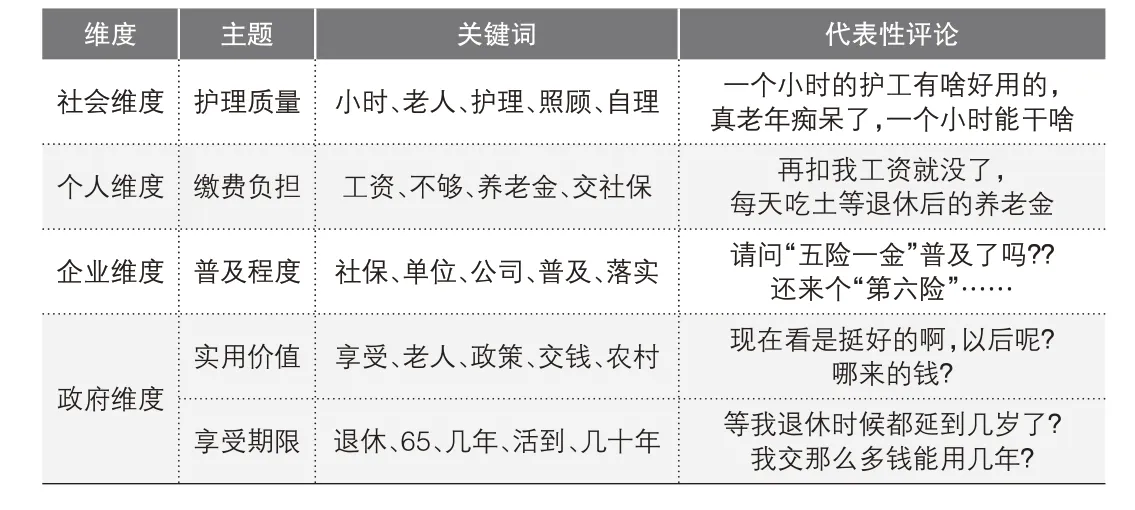
表3 各主题维度、关键词及代表性评论
根据各主题语义层面的信息,结合各主题下的具体评论内容,下面对长护险政策舆情五大主题进行详细分析。
护理质量主题下的评论主要反映了舆情中对于护理方式、护理人员专业水平、护理服务质量等方面的问题。其中,针对上海市“每周服务7次,每次服务1个小时”的长期护理方式,网民普遍认为每天一个小时的护理时间难以有效解决老年人长期护理问题。
缴费负担主题下的评论反映了长护险缴费带来的经济压力。发表此类评论的网民认为,目前的“五险一金”已经在一定程度上压缩了实际到手工资,缴纳长护险保费无疑会增加他们的经济负担。
普及程度是公众反映最为强烈的主题,由于目前部分企业或单位甚至还未做到为员工缴纳“五险一金”,公众对于作为社保“第六险”的长护险政策能否在企业层面落实存有疑虑。
实用价值主题下的评论具有一定分散性,反映了长护险实用价值的多方面因素。首先,长护险的缴费期间与给付期间存在较大的时间滞后,政策变动风险可能降低退休后长护险的实用价值;其次,由于目前社会养老保险基金不足及个人账户“空账”问题,公众对长护险的收益性缺乏信心;最后,长护险给付条件为达到失能状态,老年后若没有发生失能的情况,则已缴保费将失去价值,且公众对于失能老人界定标准也存有疑虑。
享受期限主题下的评论反映了长护险享受期限具有不确定性的问题。长护险在参保人退休后达到失能状态才能给付,在当前逐步实施延迟退休的社会背景下,公众对退休后的生存期限预期降低,随着退休年龄延后,长护险的实用价值也随之下降。
(3)分地区强相关评论聚类结果分析
为了进一步挖掘长护险舆情信息,接下来分析长护险舆情主题在地区上的分布差异。将聚类结果根据经济发展水平划分为中、东、西部三大经济分区,用各地区下的主题权重wi,j来反映各主题在三大经济分区上的分布情况。
第i个地区的第j个主题在该地区的权重可被定义为:
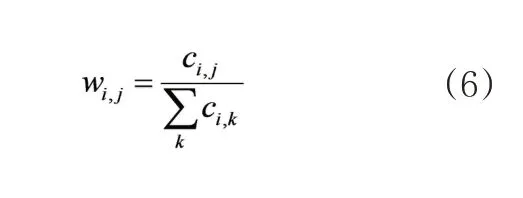
其中,ci,j表示第i个地区的第j个主题的评论数量。
对各主题下的地区权重进行均值归一化处理,各地区主题分布权重归一化结果如表4,根据权重绘制各地区主题分布结果如图6。

表4 各地区主题分布权重归一化结果
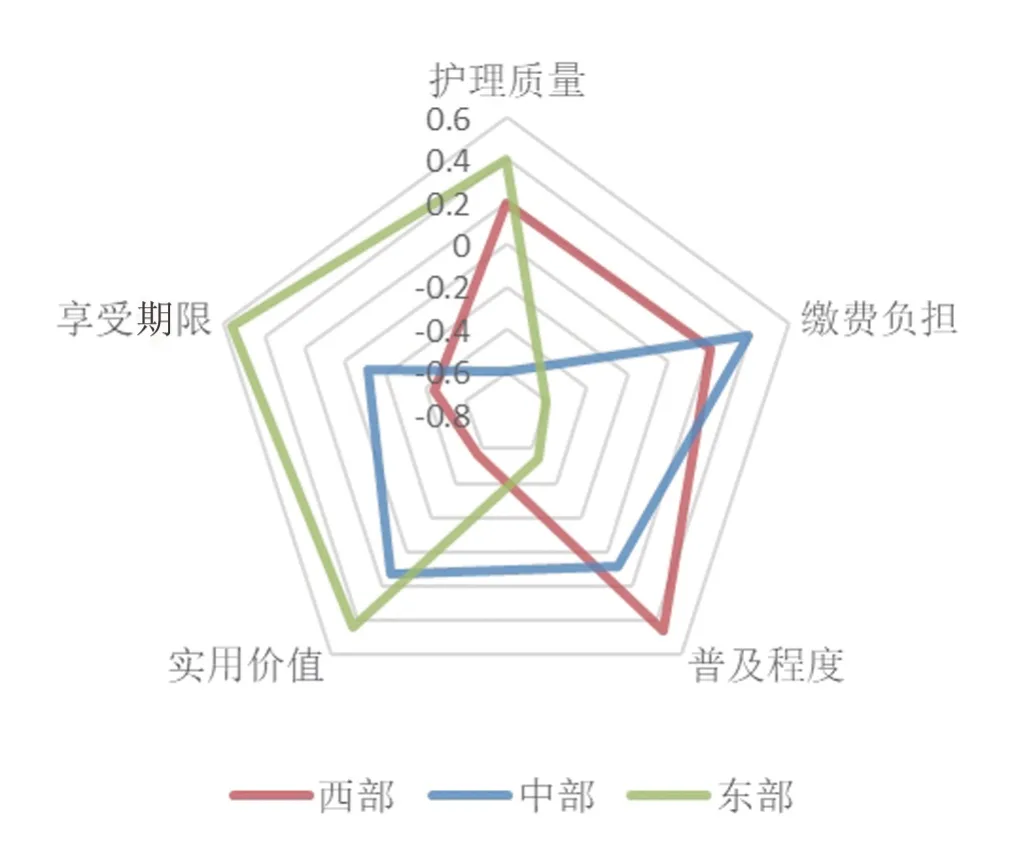
图6 各地区主题分布雷达图
从雷达图中可以看出,三个经济分区的长护险舆情主题分布存在明显差异。东部地区经济较发达,相比于经济负担,民众更注重长护险的实用价值和护理质量,故舆情主题倾向于享受期限、实用价值和护理质量;中部地区人均收入水平中等,缴费负担相对更大,且对于长护险普及缺乏信心,主题分布倾向于缴费负担、实用价值和普及程度;西部地区主题分布则倾向于普及程度、缴费负担和护理质量,西部地区经济欠发达,缴费负担自然成为重要影响因素,同时也可能存在基本社会保险普及不足的情况。
四、结论与政策建议
本文通过TF-IDF模型、PCA特征降维和K-means聚类算法对网民关于长护险的评论进行文本挖掘和主题建模,研究长护险政策舆情主题分布情况。结论显示,长护险政策舆情根据语义可分为五大主题。在此基础上,本研究还发现长护险舆情主题在地区分布上存在明显差异。
根据以上研究结论,对我国建立完善长护险制度提出如下建议:
通过本文的研究结果可知,民众对于基本社会保险普及不足的问题反映强烈。“五险一金”在企业层面的落实不到位降低了人民群众对于基本社会保险的信心。作为社保“第六险”的长护险被群众自然地与“五险一金”联系在一起,因此,全面推行长护险政策首先要解决“五险一金”中存在的问题,并切实保证长护险在企业层面落实。
根据分地区强相关评论聚类结果分析,长护险政策舆情主题在地区分布上存在明显差异。在构建长护险制度时,可在制度定性、筹资方式和给付方式等方面结合地区经济发展水平做差异化设计。东部经济发达地区可考虑商业长护险模式,采取自愿缴费的筹资方式,给付时侧重服务给付,增加老年失能人员照料陪护时间;中、西部经济欠发达地区可考虑社会长护险模式,采取“个人缴付+企业缴付+政府财政补贴”的三方筹资方式,给付时侧重现金给付,缓解扶养老年失能人员的经济压力。
猜你喜欢
文化创新比较研究(2020年13期)2021-01-14
天津外国语大学学报(2020年1期)2020-03-25
中国集体经济(2019年35期)2019-12-16
食品与生活(2019年10期)2019-12-10
中国集体经济(2019年23期)2019-09-24
经理人·中国保险家(2019年3期)2019-09-10
领导决策信息(2017年13期)2017-06-21
领导决策信息(2017年9期)2017-05-04
消费电子(2016年12期)2017-01-19
外语教学理论与实践(2014年4期)2014-06-13
