
多算法结合的船舶交通流框架提取
2021-08-09 06:19王震李伟峰高邈
上海海事大学学报 2021年2期
王震 李伟峰 高邈

摘要:為提高船舶进出交通流密集区域的安全性、解决数据挖掘不充分的问题,基于AIS数据,将多种算法相结合,提出一种多元化的船舶交通流框架提取方法。利用Douglas-Peucker压缩算法和航迹交会算法分别提取交通流中的船舶转向点和航迹交会点。利用密度聚类算法对包括船位点在内的3种特征点进行数据挖掘,提取出更有代表性的特征点。将3种特征点进行加权融合,得到新的多元特征点,以点的大小表示其重要程度,最终生成某水域的船舶交通流框架。实验结果表明,通过以上方法能够获得老铁山水道附近水域船舶交通流框架。该框架融合了多种航迹特征点,能够显示附近水域的重要航迹分布,充分体现船舶交通流的总体态势和密集区域;该框架从统计学角度凝结了该水域船舶行驶的习惯航线,这些航线具有较好的适航度,既可用于航路规划,还能为海事部门选取推荐航道提供参考。
关键词:
数据挖掘; 船舶交通流; 特征点; 船舶自动识别系统(AIS)
中图分类号: U692.37
文献标志码: A
收稿日期: 2020-09-07
修回日期: 2020-12-16
基金项目:
中央高校基本科研业务费专项资金(3132020134,3132020139)
作者简介:
王震(1996—),男,山东聊城人,硕士研究生,研究方向为AIS大数据挖掘,(E-mail)1506216436@qq.com;
李伟峰(1983—),男,山东菏泽人,副教授,硕士,研究方向为船舶智能避碰,(E-mail)sddmlwf@163.com
Framework extraction of ship traffic flow with
multi-algorithm combination
WANG Zhen, LI Weifeng, GAO Miao
(
Navigation College, Dalian Maritime University, Dalian 116026, Liaoning, China)
Abstract:
In order to improve the safety of ships entering and leaving traffic-intensive waters and to solve the problem of insufficient data mining, a diversified method for extracting the framework of ship traffic flow is proposed based on AIS data and with the combination of multiple algorithms. The Douglas-Peucker compression algorithm and the trajectory crossing algorithm are used to extract the ship turning points and the trajectory crossing points in the traffic flow. The density clustering algorithm is used to conduct data mining on the three types of characteristic points including the ship position points, so as to extract more representative characteristic points. The three types of characteristic points are weighted and fused to obtain new multivariate characteristic points, and the framework of ship traffic flow in a certain waters is generated, in which the size of a point represents the importance. The experimental results show that the framework of ship traffic flow in the local waters of Laotieshan channel can be obtained through the above method. The framework integrates a variety of trajectory characteristic points, which can display the distribution of important trajectories nearby and fully reflects the overall situation and dense areas of ship traffic flow. It also condenses the customary routes of ships in the waters statistically, and the customary routes have good seaworthiness and can be used for route planning and reference for maritime departments to select recommended channels.
Key words:
data mining; ship traffic flow; characteristic point; automatic identification system (AIS)
0 引 言
随着船舶自动识别系统(automatic identification system,AIS)的广泛使用,海事系统及船公司接收了大量包括船舶航迹及海上交通环境等多种信息在内的AIS数据。为获取AIS数据中蕴藏的船舶交通流和航行环境的特征及规律,运用大数据算法对其进行数据挖掘已成为一个重要研究方向。近年来,国内外专家学者通过各种方法对船舶交通流进行深入研究,并取得了一定的成果。然而,船舶航迹分布复杂、交通流特征多种多样,当前对AIS数据的挖掘仍然不够全面;AIS数据挖掘结果的可视化效果仍不够理想,不能更直观地体现船舶交通流的航迹特征和宏观态势。本文针对以上问题进行研究。
LV[1]设计了大型AIS数据挖掘平台,并利用大数据对船舶航迹进行分析,验证了运用大数据技术对AIS数据进行挖掘的可行性。聚类是数据挖掘中必不可少的一环,魏照坤[2]通过基于轨迹结构距离的聚类方法,实现了对船舶轨迹的聚类;HAN等[3]利用基于轨迹密度的聚类方法,得到了不同的航迹矢量簇;郭乃琨等[4]讨论了数据挖掘的关键技术与基本流程,并表明利用传统的聚类分析方法无法达到理想的聚类效果。张树凯等[5]利用Douglas-Peucker压缩算法,设定不同阈值提取关键特征点对AIS航迹数据进行压缩,该算法的稳定性和处理效率都较高。刘敦伟[6]基于经典的Douglas-Peucker压缩算法,结合船舶航线设计的偏航极限和船舶领域知识压缩阈值,提出基于速度和航向约束的船舶轨迹数据压缩方法,该方法能够挖掘曲率和速度变化率较大的点,提高轨迹数据的利用率和价值。高邈等[7-8]利用改进的滑动窗口(sliding window)算法提取关键特征点,在降低压缩风险的同时大幅提高了压缩效率。刘虎等[9]在轨迹聚类的基础上,运用核密度估计(kernel density estimation,KDE)推算聚类航迹的概率密度,自动识别交通流区域,进行精准数据挖掘。与上述提取船舶交通流的主要特征不同,RONG等[10]使用多种轨迹压缩和聚类算法,对船舶航行行为的异常特征进行数据挖掘:在观察到船舶航行行为发生重大变化(例如航向变化)的路线上识别相关航路点,根据轨迹的航向分布和速度分布,可以概率性地表征沿着特定路线航行的一类船舶的典型行为。LEI[11]将冲突轨迹视为接近碰撞的情况进行分析,通过开发出的CCT Discovery框架,从大量的AIS数据中提取冲突轨迹数据,用于避碰行为建模和海上交通管理的重点区域监控。ZHOU等[12]从AIS数据中挖掘所有的船舶位置、速度、航向等多种行为属性,对船舶行为进行聚类并确定聚类特征,并根据特征将船舶分类为行为集群,但并未进一步对船舶交通流的多种特征进行挖掘和分析。当前对船舶轨迹的研究中,通过数据挖掘得到的船舶交通流特征相对单一,不能充分体现交通流的复杂特征,而且其可视化效果也有待提高。
针对当前研究的不足,本文综合考虑船位点、船舶转向点和航迹交会点(下文分别简称转向点和交会点),结合船舶运动特性,运用密度聚类算法、Douglas-Peucker压缩算法和航迹交会算法,提出一种多算法联合的船舶交通流框架提取方法。该方法吸取了诸多算法的优点,最终提取出实验水域的船舶交通流框架,并将交通流中的多种重要特征可视化,具有重要的理论意义和应用价值。
1 多算法联合的船舶交通流框架模型
1.1 密度聚类算法
聚类指将数据对象分成多个类或簇,使得同一簇中的对象具有较高的相似度,而不同簇中的对象差别较大。传统的密度聚类算法是在一个给定的区域内使数据点的数量不小于设定值,常用的有DBSCAN、OPTICS以及谱聚类等[13]。
本文的密度聚类算法以各数据点为中心,计算其邻域内的点数,设定不同阈值控制各点邻域大小。在各点邻域所共同构成的局部区域内,若某点邻域内包含的点最多,则该点为密度吸引点(以下简称密度点),其将吸收邻域内所有数据点,完成一次聚类。随着阈值不断增大,交通流中各航迹线通过共有密度点联系起来,组成该水域交通流的密集点网络[14]。
密度聚类流程见图1。通过预处理AIS数据,获得各航迹线上数据点的坐标,
如点Pi。设两点之间的距离为d,邻域阈值为ε,若d≤ε,则这两点属于同一类。以Pi为圆心,ε为半径,统计该(圆形)邻域内的点,得到包含u个点的点集A;统计A中各点(除点Pi外)邻域内的点数,记最大值为v,v对应的点为Qm。若u>v,则说明在点Pi附近,点Pi邻域内的密度最大,点Pi为该区域的密度点,保存点Pi;若u≤v,则说明在点Pi附近,点Qm邻域内的密度最大,点Qm为该区域的密度点,则包含点Pi在内的Qm邻域内的所有数据点都将被聚类到点Qm,保存点Qm。然后依次遍历所有数据点,即完成一次聚类。
以上一次聚类得到的密度点为基础,增大阈值,再进行聚类;随着迭代次数的增加,被聚类的数据点越来越多,密度点逐渐成为全局密度的局部最大点;当取到最终阈值时,密度聚类完成。密度聚类示意图见图2。用密度点吸收的点数表示其权重,点数越多,权重就越大,该点附近的点密度就越大。为直观显示密度点权重大小,权重越大的密度点在图中显示的尺寸越大。
1.2 Douglas-Peucker压缩算法
1973年,Douglas 等提出一種简化二维曲线的算法,其核心思想是从构成曲线的点集中提取出能反映曲线总体和局部形态主要特征的另一个点集。该算法步骤如下:将一段航迹线上首
点P1与尾点P2之间的连线称为基线,依次计算这段航迹线上各点到基线的距离,并找出最大距离D对应的点P3。设定阈值δ,若D≤δ,则表示该段航迹线向两舷偏离的距离小于D,即该段航迹线没有明显转折,则用基线代替原航迹线,只保留P1、P2两点即可;若D>δ,则将最大距离D对应的点P3作为分裂点(转向点),并分别与初始点P1、P2连接,得到两组新的首点、尾点和基线。依次递归选取分裂点和分段航迹线,直到整条航迹线上不再出现新的分裂点[5]。
图3为Douglas-Peucker压缩示意图。
设点P1、P2和P3的坐标分别为(x1,y1)、(x2,y2)和(x3,y3),则有D=(y2-y1)x3+(x1-x2)y3+x2y1-x1y2(y2-y1)2+(x2-x1)2
1.3 航迹交会算法
船舶航迹密集交会处通常是海上交通情况比较复杂的地方,在这一区域,各船航向、航速往往不同,通航情况复杂,因此交会点也是船舶交通流的重要特征点之一。
航迹交会算法原理:取某条航迹线上相
邻两点Mi和Mi+1,取另一条航迹线上相邻两点Nj和Nj+1,连接Mi、Mi+1得线段MiMi+1,连接Nj、Nj+1得线段NjNj+1,分别设这两条线段的斜率为k1、k2。若k1、k2都不存在,则两直线竖直平行;若k1=k2=0,则两直线水平平行。两直线平行,不存在交点。若k1≠0或k2≠0,则在二维平面内两直线必相交,此时先求得两直线交点E,再判断该交点是否在线段MiMi+1和NjNj+1上,若在,则点E即为所求的交会点。对于每条航迹线上相邻两点之间的线段,均按上述方法判断其与其余所有航迹线有无交点,逐个遍历所有航迹线,即可得到该组AIS数据的所有交会点。图4为交会点提取示意图。
设点Mi、Mi+1、Nj、Nj+1和E的坐标分别为(x6,y6)、(x7,y7)、(x8,y8)、(x9,y9)和(x10,y10),则相关公式如下:
k1=y7-y6x7-x6, k2=y9-y8x9-x8
x10=(x7-x6)(x8y9-x9y8)-(x9-x8)(x6y7-x7y6)(y6-y7)(x9-x8)-(y8-y9)(x7-x6)y10=(y8-y9)(x6y7-x7y6)-(y6-y7)(x8y9-x9y8)(y6-y7)(x9-x8)-(y8-y9)(x7-x6)k1≠0, k2≠0
x10=((x8-x9)y6+x9y8-x8y9)/(y8-y9)
y10=y6k1=0, k2≠0
x10=((x6-x7)y8+x7y6-x6y7)/(y8-y9)
y10=y8k1≠0, k2=0
x10=x8, y10=y6k1=0, k2不存在
x10=x8y10=((y7-y6)x8+x7y6-x6y7)/(y7-y6)
k1≠0, k2不存在
x10=x6, y10=y8k1不存在, k2=0
x10=x6y10=((y9-y8)x6+x9y8-x8y9)/(x9-x8)
k1不存在, k2≠0
1.4 加权融合算法
通过Douglas-Peucker压缩算法得到的转向点、通过航迹交会算法得到的交会点和原有的船位点分别为船舶交通流的3种特征点,对这3种特征点分别进行密度聚类,得到相应的密度点,然后将这3种特征密度点集中显示。由于转向点和交会点是基于算法从船位點中提取出来的,其数据量远小于船位点的初始数据量,若直接按权重显示,则转向点和交会点的聚类密度相较于船位点的聚类密度几乎可以忽略不计,这违背了本文的初衷;此外,由于最终密度点的权重很大,直接显示可能会使各点难以区分,影响视觉效果。鉴于以上原因,对不同类型特征点进行加权显示。具体来说,就是分别成比例地放大或缩小3种特征点的权重值,放大或缩小比例的设置需要考虑原始船位点的数据量、特征点在交通流框架中的重要程度和最终的可视化效果。例如:10 000个船位点经过Douglas-Peucker压缩算法得到200个转向点,其整体权重值相当于缩小为原来的1/50,考虑本文的交通流框架是以船位密度点为主体的,转向点权重的放大倍数可先取50的60%~80%,如30,然后统一调整使可视化效果最佳。这样充分考虑了3种特征点的影响,显示了不同类型特征点之间的位置关系,可更直观地判断船舶交通流的整体航迹特征和宏观态势,达到更好的视觉效果,如图5所示。
对交通流网络中位置相近的3种特征点进行加权融合(见图6),提取出4种新的融合特征点,即“船位+转向+交会点”、“船位+转向点”、“船位+交会点”和“转向+交会点”。它们能够表现该点附近的多种航迹特征,与原有的3种特征点一起共同作为该交通流框架的重要节点。
设共有ω个被融合点,融合后点的总权重为W;被融合点坐标为(xτ,yτ),权重为wτ,τ=1,2,…,ω。第τ个被融合点的权重占比rτ=wτ/W,各点加权可得融合点的坐标(X,Y)。
X=ωτ=1(xτrτ), Y=ωτ=1(yτrτ)
2 实例验证与分析
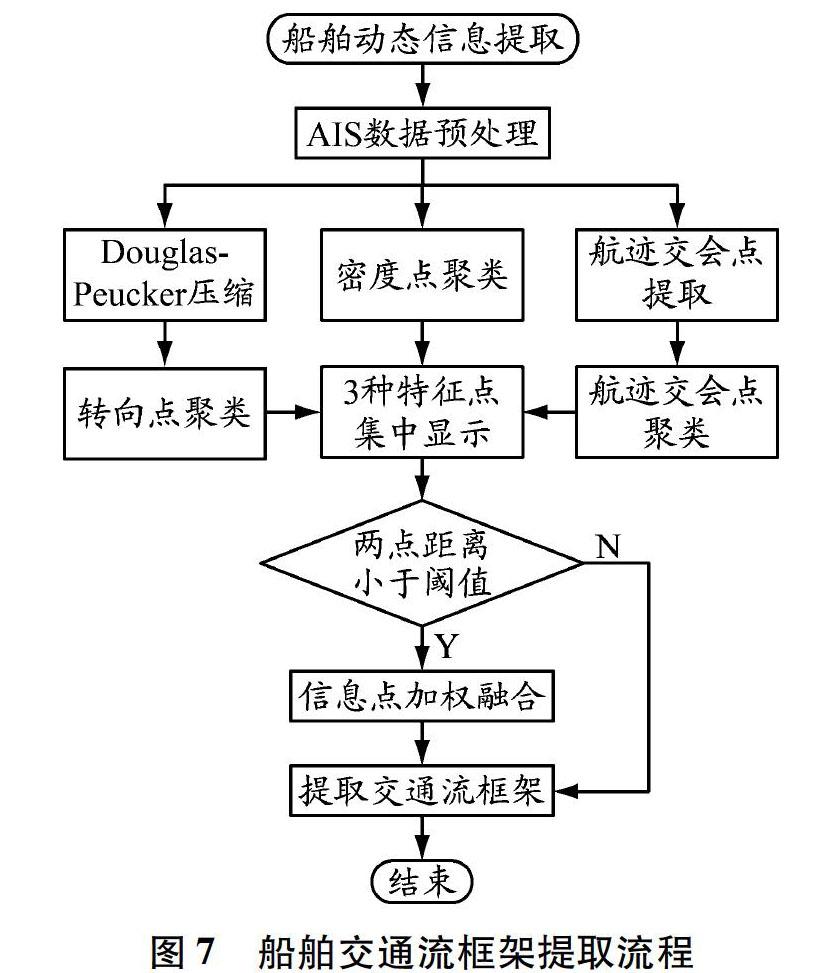
选定老铁山水道附近水域(38.321 7~38.747 1°N,120.431 9~121.431 9°E),从AIS数据中提取2017年3月11日至3月14日过往船舶的动态信息,并对其进行解码,共得到126 408个船位点数据。对解码的AIS信息进行预处理,主要包括数据清理和数据转换。数据清理主要是为了将数据挖掘过程中的异常点、错误信息以及无用信息去除;数据转换是为了修正原始数据以更有利于数据挖掘。对不同航行状态船舶的AIS数据进行时间等距差分,统一初始时间和船载信息更新时间间隔,以及等比例转换各船舶信息的时间戳和船位,在时空上保证AIS船位点数据的一致性。经过数据预处理,将212条航迹线上共计126 193个船位点数据作为实验对象,将其经纬度坐标转换为墨卡托坐标,以便在海图上显示。整体实现流程见图7。
2.1 船位点密度聚类
为使最终聚类得到的船位点坐标更加准确,采用逐渐增大阈值的方法,以上一层的输出数据作为
下一层的输入数据,依次聚类。随着阈值的不断增
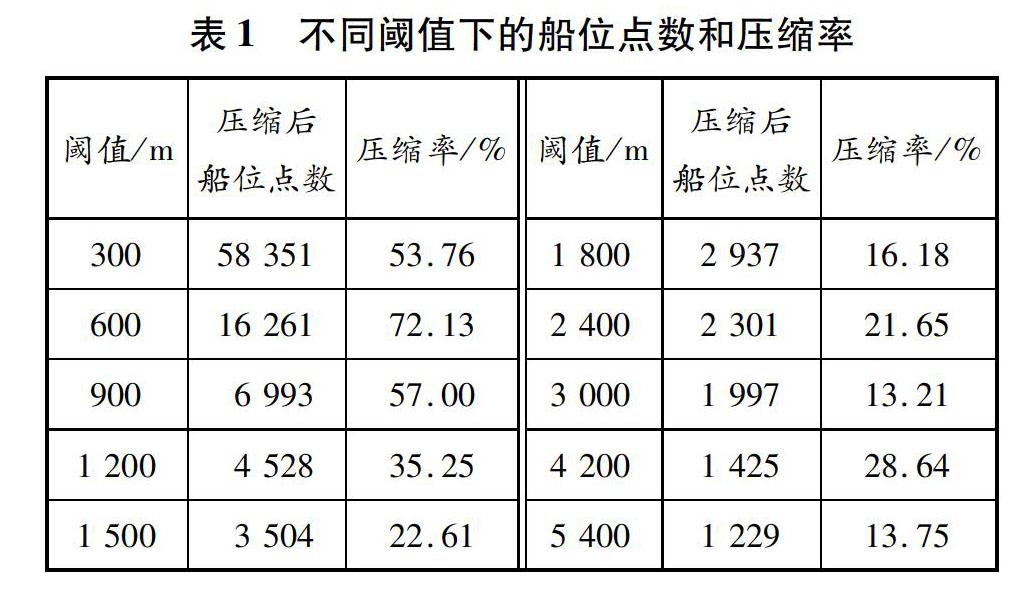
大,等差增大阈值的聚类效果会逐渐变差,需逐渐增大阈值差:阈值最初取300, 600, …, 1 800 m,每次增加300 m;而后取2 400, 3 000 m,每次增加600 m;最后取4 200, 5 400 m,每次增加1 200 m。聚类过程中,不同阈值下的船位点数和压缩率如表1所示,这里的压缩率是根据上一层数据(而非初始数据)计算得出的。
从表1可以看出,在阈值差相等的情况下,除首次压缩外,其他各次的压缩率随阀值增大逐渐减小,至阈值取1 800 m和3 000 m时,对上一层的压缩率已不足20%,因此可增大阈值差以获得更好的聚类效果。截止到最终阈值5 400 m时,对初始数据的压缩率已经达到99%以上。
由于密度聚类不限于单条航迹线,聚类后同一船位点可能位于多条航迹线上,压缩后的船位点数为各条航迹线上船位点数之和,因此最终1 229个船位点会包含许多点的多次计量,实际船位点数远小于此。此外,聚类完成后,删除船位点网络中权重小于600的低密度点,最终得到33个船位点。图8为部分不同阈值下船位点密度聚类效果图,图8f为在图8e的基础上删掉权重小于600的船位点所得的最终效果图。
从图8可以看出:聚类后的船位点几乎都在交通流最密集的区域,而且该船位点网络两头宽、中间窄,很好地反映了航迹线的实际分布情况;在老铁山水道及其进出口附近,密度点大且分布较为密集,表示水道附近船位点密度大且较为密集;船位点网络并未延伸到右上水域的一些航迹线上,表示右上水域的船位点密度小,这与航迹线在老铁山水道较为密集而在东北方向较为稀疏的实际情况相符;在老铁山水道的相向交通流中,水道右侧密度点大而密集,水道左侧密度点小而稀疏,这与当时老铁山水道航迹线右侧多、左侧少的实际情况一致。
2.2 转向点的提取及聚类
为验证Douglas-Peucker压缩算法的有效性,对212条航迹线上的126 193个船位点进行Douglas-Peucker压缩,阈值为120 m,压缩后转向点数减为1 979(压缩率达98.43%)。压缩后的数据量虽然大幅减少,但很好地保留了原始航迹的特征,可以清楚地看出船舶交通流的宏观态势,见图9。
对压缩后获得的转向点进行密度聚类,同样采用阈值逐渐增大的方法。不同阈值下的转向点数和压缩率见表2。由表2可知,每经过一次聚类,转向点数就减少一次,阈值取4 200 m和4 800 m时转向点数已差别不大。
与船位点密度聚类一样,表2中所示的转向点数为各条航迹线上转向点数之和,存在多条航迹线上的转向点被重复计数问题,阈值取4 800 m时的实际转向点数远远小于930,删除权重小于30的转向点,最终得到的转向点数为24。图10为部分不同阈值下的转向点密度聚类效果图,图10e为在图10d的基础上删掉权重小于30的转向点所得的最终效果图。
从图10可以看出,聚类后的转向点网络与船位点网络有很大不同:在航迹线最为密集的老铁山水道内,转向点很少且密度较小;在水道进出口附近,有许多密度较大的转向点。实际航行中,船舶在水道内大多定向行驶,航迹偏转很小;而在水道进出口附近,船舶进出水道需频繁动舵,因此航迹线转折较多,与实验数据相符。在图10中左上区域航迹线很多,但大多比较平直或整体弯曲度较低,转向点相对较少,最终导致该水域在转向点网络中的转向点少且密度小;图10e中C1、C2两点不在航迹线密集的区域,但其附近航迹线转折颇多,转向点并不少,最终成为转向点网络中相对突出、孤立的两点。
2.3 交会点的提取及聚类
根据航迹交会算法,对212条航迹线上的126 193个船位点进行编程计算,最终得到5 200个交会点,見图11。
从图11可以看出,在老铁山水道及其进出口附近交会点密集。图11中左上区域(进出口邻近的警戒区)和右下区域交会点也很多,与右下区域相比左上区域交会点较少且分布比较零散,与航迹线进水道时汇集、出水道后发散的实际情况一致。对提取的交会点进行密度聚类,阈值逐渐增大,阈值差也逐渐增大(依次取300、600、900、1 200 m)。不同阈值下的交会点数和压缩率见表3。
与船位点和转向点不同,交会点是散点,并未引入航迹线中,因此表3中压缩后的交会点数和压缩率均为实际值。为得到最有代表性的交会点,最终的压缩率很高。在阈值逐渐增大的过程中,最初采用300 m的阈值差,在阈值取1 800 m与2 100 m时其整体压缩率很相近,因此加大阈值差至600 m。阈值越大,数据量减少率越低。阈值取3 000 m后改用900 m阈值差,阈值取4 800 m后改用1 200 m阈值差,阈值差改变的区间内往往存在数据阶跃。
图12为不同阈值下的交会点密度聚类效果图,图12f为在图12e的基础上删掉权重小于50的交会点所得的最终效果图。
2.4 加权融合提取船舶交通流框架
经数据清洗后共获得126 193个船位点数据,利用密度聚类算法、Douglas-Peucker压缩算法和航迹交
会算法等对该AIS数据进行处理,获取密度聚类后的3种交通流特征点。关于特征点聚类过程中最终阈值的选取,主要考虑以下两个方面。一是聚类效果:随着阈值的不断增大,船位点数的下降幅度会越来越小,阈值取到4 800 m和6 000 m时,交通流框架的主要节点已基本形成,继续加大阈值后所聚类的点基本是主框架之外的散点,这些点绝大部分属于之后会被删除的低密度点,其对主框架的影响基本可以忽略不计。例如在对交会点进行聚类时,当阈值取6 000 m时,删除低密度点后剩余点数为16,该数值一直保持不变,直到阈值取8 000 m时出现阶跃。阈值的过大和数值的阶跃,会导致原有的交通流框架发生严重变形,不符合最初的设想,因此阈值取到6 000 m已完全符合实验需要;转向点的情况也与此类似,阈值取到4 800 m即可。二是实际情况需要:对于特征密度点的聚类,除考虑交通流框架外,还要考虑具体情况。实验数据中两股反向的交通流在老铁山水道聚集进行分道通航,当阈值取到6 000 m以上时,南下交通流的个别密度点由于权重相对较小,会被聚类到北上一侧,这显然不符合实际航行情况,必须保证通航分道的两侧都有对应的密度点保留,因此阈值取到5 400 m即可。关于删除较小密度点的权重阈值选择,以最终保留的特征点不过多为原则:若船位点数多且权重大,则权重阈值选用其最大点权重的5%左右;若转向点和交会点的数量和权重都相对较小,则在选取权重阈值时要保留其数据总量的30%~40%。具体地,取船位点的最大聚类阈值为5 400 m,聚类完成后删除权重600以下的点;对船舶轨迹进行Douglas-Peucker压缩,阈值取600 m,得到1 979个转向点,再经过密度聚类,取最大聚类阈值为4 800 m,聚类完成后删除权重30以下的点;船舶轨迹经航迹交会算法提取到5 200个交会点,再经过密度聚类,取最大聚类阈值为6 000 m,聚类完成后删除权重50以下的散点。权重调整后的结果见表4和图13。
在以上实验数据的基础上,利用加权融合算法进行计算。首先以阈值4 200 m对船位点进行加权融合,以防后续出现同一转向点或交会点被融合多次的情况。然后以船位点为基础,融合其邻域内的转向点和交会点,分别取阈值4 200 m和3 000 m,进而得到“船位+转向点”“船位+交会点”“船位+转向+交会点”等3种新的特征点的数量。再以剩余转向点为基础,融合其邻域内剩余的交会点,取阈值3 600 m,得到“转向+交会点”的数量,实验结果见表5。
最后以原有的3种特征点和融合后的4种特征点作为交通流的重要节点,提取该水域的船舶交通流框架,该框架具有混合表现船舶位置、船舶转向、航迹交会3种航迹特征的属性。图14为最终提取的老铁山水道附近水域的交通流框架。
3 结 论
为提高船舶进出交通流密集区域的安全性,以提取船舶交通流特征为切入点,对监控水域的船舶航迹线进行数据挖掘,利用密度聚类算法、Douglas-Peucker压缩算法和航迹交会算法,分别提取聚类后的船位点、船舶轉向点和航迹交会点等特征点,组成该水域的交通流网络。对集成交通流网络中的多种特征点进行优化和加权融合,提取具有多元特征点的船舶交通流框架,采用老铁山水道附近水域的AIS数据验证了该方法的可行性。该方法能够弥补以往船舶交通流网络特征和可视化效果的不足,有利于增强值班驾驶人员对交通流多样化特征和整体态势的了解,提供操纵决策支持,还能为海事管理机关的航道建设和锚地规划提供参考。后续将继续挖掘航迹特征和外界环境信息,使船舶交通流框架的内涵更加丰富。
参考文献:
[1]LV S M. Construction of marine ship automatic identification system data mining platform based on big data[J]. Journal of Intelligent & Fuzzy Systems, 2020, 38(2): 1249-1255. DOI: 10.3233/JIFS-179487.
[2]魏照坤. 基于AIS的船舶轨迹聚类与应用[D]. 大连: 大连海事大学, 2015.
[3]HAN Peng, YANG Xiaoxia. Big data-driven automatic generation of ship route planning in complex maritime environments[J]. Acta Oceanologica Sinica, 2020, 39(8): 113-120. DOI: 10.1007/s13131-020-1638-5.
[4]郭乃琨, 马壮壮, 岳明桥. 船舶轨迹挖掘与可视化技术分析研究[J]. 电子元器件与信息技术, 2020, 4(3): 141-142. DOI: 10.19772/j.cnki.2096-4455.2020.3.057.
[5]张树凯, 刘正江, 张显库, 等. 基于Douglas-Peucker算法的船舶AIS航迹数据压缩[J]. 哈尔滨工程大学学报, 2015, 36(5): 595-599.DOI: 10.3969/j.issn.1006-7043.201401013.
[6]刘敦伟. 基于AIS数据的船舶航线挖掘[D]. 大连: 大连海事大学, 2017.
[7]高邈, 史国友, 李伟峰. 改进的Sliding Window在线船舶AIS轨迹数据压缩算法[J]. 交通运输工程学报, 2018, 18(3): 218-227.
[8]GAO Miao, SHI Guoyou. Ship spatiotemporal key feature point online extraction based on AIS multi-sensor data using an improved sliding window algorithm[J]. Sensors, 2019, 19(12): 2706. DOI: 10.3390/s19122706.
[9]刘虎, 李伟峰. 基于AIS数据的海上交通流区域自动识别[J]. 中国航海, 2016, 39(4): 87-90, 132.
[10]RONG H, TEIXEIRA A P, SOARES C G. Data mining approach to shipping route characterization and anomaly detection based on AIS data[J]. Ocean Engineering, 2020, 198: 106936. DOI: 10.1016/j.oceaneng.2020.106936.
[11]LEI P R. Mining maritime traffic conflict trajectories from a massive AIS data[J]. Knowledge and Information Systems, 2020, 62(1): 259-285. DOI: 10.1007/s10115-019-01355-0.
[12]ZHOU Yang, DAAMEN W, VELLINGA T, et al. Ship classification based on ship behavior clustering from AIS data[J]. Ocean Engineering, 2019, 175: 176-187. DOI: 10.1016/j.oceaneng.2019.02.005.
[13]赵梁滨. 船舶轨迹的数据挖掘框架及应用[D]. 大连: 大连海事大学, 2016.
[14]周世波, 熊振南. 基于局部密度的成山角船舶交通流特征分析[J]. 大连海事大学学报, 2019, 45(3): 100-105. DOI: 10.16411/j.cnki.issn1006-7736.2019.03.014.
(编辑 赵勉)
猜你喜欢
科技研究(2021年15期)2021-09-10
中国新通信(2021年8期)2021-08-04
电子乐园·中旬刊(2021年7期)2021-07-13
中国计算机报(2020年15期)2020-05-13
科学大众·小诺贝尔(2019年6期)2019-08-24
分析化学(2017年12期)2017-12-25
珠江水运(2016年23期)2017-01-04
现代商贸工业(2016年22期)2016-12-27
考试周刊(2016年62期)2016-08-15
珠江水运(2015年11期)2015-07-24
