
面向低延时目标检测的FPGA神经网络加速器设计
2021-08-06 08:25郑思杰李杰贺光辉
现代计算机 2021年18期
郑思杰,李杰,贺光辉
(1.上海交通大学电子信息与电气工程学院,上海200240;2.上海航天测控通信研究所,上海201109)
0 引言
随着大量可信数据的积累,以数据为研究基础的深度神经网络在目标检测分类领域获得了巨大成功[1],在智能驾驶和目标追踪等领域得到了广泛应用。然而,随着检测性能的提升,检测网络的层数,参数规模和计算复杂度大幅增加。这对硬件的计算性能和存储开销提出了新的挑战。在实时性要求更高的应用中,传统中央处理器的计算架构无法满足实时计算的需求,需要硬件加速器加速计算,从而降低延时。
图形处理器具有更高吞吐性能[2],但功耗较大甚至达到100 W以上[3]。专用集成电路具有更高的能效,例如寒武纪Cambricon-x[4]芯片只需954 mW就能实现544 GOPS的性能。但专用集成电路研发成本高,研发周期长,实现后难以修改,难以适应快速更新的神经网络算法。而现场可编程门阵列(Field Programmable Gate Array,FPGA)则以其可重构、较高的能效比、较低的开发成本成为神经网络加速器的最佳选择[5-6]。
现有神经网路硬件加速器主要从网络模型和硬件结构设计等方面进行优化设计。定点量化是网络模型设计的常用方法[7],但对YOLO等新颖的复杂深度网络算法而言,过小的位宽量化容易造成较大的性能损失[8]。在硬件设计方面,采用稀疏计算结构的STICKER[9]架构能够支持多种稀疏度的自动匹配,从而实现高能效的电路设计。然而该架构采用编码的结构实现零值过滤,具有较大的分布式存储开销,限制了数据的并行计算。DNNBuilder[10]则是采用了一种多计算引擎的架构设计,并通过设计空间探索优化FPGA的资源分配,但这种多计算引擎架构的延时会随着网络层数的增加而增加,更适合小规模网络实现。
尽管现有设计通过降低计算复杂度和提高硬件利用率等方式提高了神经网络加速器的能效,但当前研究对延时的关注较少。然而对于实时性要求高的应用,低延时也是需要考量的重要指标。为此本文提出了一种基于高并行卷积稀疏计算的低延时神经网络加速器架构,能够以更高的面积效率实现低延时的目标检测网络加速。
1 目标检测网络及卷积稀疏计算分析
1.1 目标检测网络
目标检测对系统实时性和算法检测的准确性都具有更高要求。为了达到更好的检测分类效果,YOLOv3采用了DarkNet-53网络作为基准网络,整体架构如图1所示。相比传统的目标检测网络结构,YOLOv3增加了残差结构加强其特征提取能力,并引入跨层连接结构加强深层网络与浅层网络的数据依赖关系。
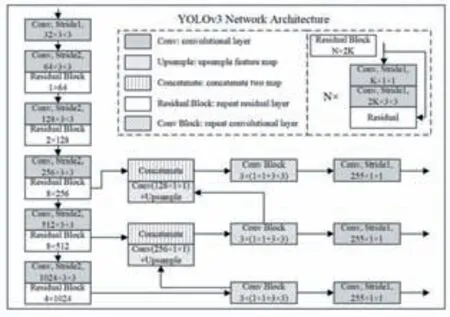
图1 YOLOv3网络结构
YOLOv3是一个全卷积网络,采用了步长不为1的卷积网络来代替池化层,既起到降采样的效果,又降低了池化层带来的梯度负面影响。而且,YOLOv3实现了多尺度融合的类别预测,通过上采样和特征图拼接等方法,共进行了三次不同尺度的检测。在网络中使用上采样的原因是网络越深,特征提取和表达效果越好,进而能够有效解决小目标识别准确度低的问题。YOLOv3整个网络包括75个卷积层,2次上采样,2次张量拼接,2次跨层连接,23个残差结构,激活层、归一化层和检测层,最终输出分别对应小尺寸目标、中尺寸目标、大尺寸目标,三级输出之间通过跨层张量拼接和上采样层进行连接。
1.2 卷积稀疏计算的资源平衡问题
为了实现卷积的稀疏计算,很多额外的硬件单元会配合乘法器进行零值的过滤以及有导向性的数据传输。表1展示了现有支持卷积稀疏计算的硬件加速器实现结果,从中可以看出单纯的乘法计算单元并不是现有加速器实现的主要组成,反而是稀疏数据的判断分发以及存储单元占据了核心处理单元(Processing Element,PE)的主要开销。

表1 不同稀疏计算架构的面积比较
针对片上存储,为了满足稀疏计算的计算需求,现有设计通常会为每个乘法器设置分布式的缓存结构。这种分布式存储结构并不利于FPGA的硬件实现。因为FPGA使用BRAM这种块状存储结构,而BRAM数量有限且有位宽限制,这造成了传统稀疏计算实现中,单一乘法器甚至需要多块BRAM支持其稀疏计算。以VCU118开发板为例,该开发板仅含有6840个DSP计算资源和2160个36 Kb的BRAM存储,两者数量并不匹配,这限制了稀疏计算在FPGA上的高并行设计。
1.3 稀疏计算的硬件结构和数据复用分析
现有稀疏计算实现大多都是基于编码的数据方式,然而编码的数据方式并不利于高并行的硬件设计。首先,编码的结构导致了PE存储中开销较大的分布式存储结构。其次,编码结构所需的PE辅助电路更加复杂。PE计算结构在进行稀疏计算时,除了输入非零数据还需要输入数据对应坐标,用于计算乘法输出的数据对应坐标。而且,编码结构需要实时的对输出结果做非零值编码,且编解码的电路开销随乘法器数目增多而增多,这并不利于提高计算并行性。还有,编码的方式对于步长不为1的卷积计算并不友好。最后,编码的方式因为存在随机性和网络特异性,在存储和数据传递上不一定存在优势。例如YOLOv3网络的权重参数在剪枝后有30%稀疏度。假设采用神经网络常用的8 bit量化以及4 bit坐标,原来数据需要8N bit存储,N为数据数目;编码后需要( )
8+4×0.7N=8.4N bit存储,存储甚至有所增大,实际编码开销只会更大。
不同的卷积数据复用方式,对应不同的卷积循环展开方式,最终决定了计算PE阵列的结构。本文设计的数据复用包括权重复用,特征图行方向数据复用以及特征图列方向数据复用。尤其是特征图的复用更能够匹配不同规模的网络层结构,利于数据并行。除此之外,还设置了输入通道方向的计算并行。计算阵列的形式和数据复用方式如图2所示。

图2 本文采用的数据复用和计算阵列排布
综上,本文不会采用编码的方式作为特征图输入及权重在存储、数据传输以及卷积计算时的数据形式。该方式能够简化PE结构,支持更高并行的稀疏计算,并且通过设置大量数据复用,降低高并行数据计算所需要的高访存位宽。
2 面向低延时目标检测的加速器架构设计
2.1 基于稀疏计算的低延时加速器整体架构
本文设计的低延时神经网络加速器如图3所示。其中,计算阵列是核心计算单元,由一系列能够支持稀疏计算的PE基本单元组成。每个PE单元都会包含零值检测单元,非零数据的先进先出存储器(First Input First Output,FIFO),稀疏计算的负载平衡单元,卷积乘累加单元,数据截断单元以及激活函数等硬件结构。片上存储分为特征图和权重两部分,都采用了多缓存块的结构,从而保证能够同时访问计算阵列所需的并行数据。对内数据交互单元和对外交互单元会控制数据的读写和搬运,根据卷积步长,卷积核尺寸,不同计算顺序等因素对网络计算进行控制。
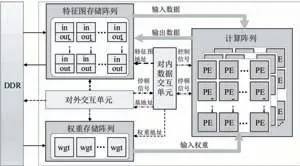
图3 神经网络加速器顶层架构
上述电路能够支持不同尺寸,不同步长的卷积网络运算。同时能够支持残差网络,特征图拼接的跨层结构、升采样、激活函数、高并行稀疏计算等结构。另外,模块存在一定扩展性,可以根据算法需求增加和减少部分结构,从而适应不同网络结构。
2.2 低存储开销的稀疏计算PE设计
设计的PE主要包含用于支持稀疏计算的零值检测,替代分布式存储结构的小规模FIFO存储以及计算单元,如图4展示了沿着输入特征图单通道方向上计算PE。图中输入数据的数量是特征图通道方向上并行传递数据的数量,同时也是PE中对应输入通道上设置并行乘法器数量的两倍。在FIFO写一侧,每个周期至少会有一个FIFO被写入该周期接受到的非零值,如果非零值较多则会存储多余的非零值等待下次传递的输入,当非零值数量累计达到或超过两个FIFO位宽时会一个周期同时写两个FIFO。如果FIFO满则会暂停从存储阵列中取数。通过以上结构实现了非零元素的检测和过滤,进而实现稀疏计算。

图4 支持稀疏计算的PE结构
在FIFO数据读取侧,每两个FIFO交替提供一个计算单元所需的非零数据。因为稀疏计算,不同计算单元在同一批次计算中,计算次数不同,主要体现在前置FIFO排空数据的时间不同。为了更高效地利用这些计算单元,当计算单元前置FIFO为空时,会自动从相邻计算单元的前置FIFO取数,帮助加速计算,如图5所示。

图5 负载平衡模块
2.3 高并行的存储阵列结构设计
高并行稀疏计算的另一重要组成部分是集中式片上存储阵列结构。存储阵列结构的设计是,高并行稀疏计算所需的高存储位宽和FPGA相对集中式的BRAM存储结构,两者折中的结果。图6展示了特征图数据和权重参数在存储阵列中的排布顺序。
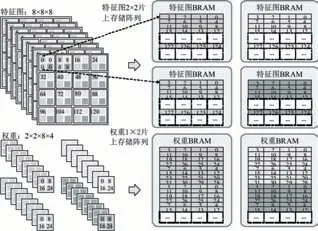
图6 特征图和权重在存储阵列中的数据排布
在这种存储形式下,数据交互需要提取出每个周期用到的特征图数据并传递到指定位置的PE。图7展示了3×3二维卷积网络的实现,设定网络输入10×10的特征图,片上存储阵列规模为5×5,每个存储单元都存储了4个数据。当卷积窗在滑动时,提供各PE所需数据的存储地址,从存储阵列中不同存储地址取出对应数据,并按照PE计算的累加需求进行数据的重新排列和发送。利用存储阵列的结构能够高效地对特征图进行卷积窗滑动的计算。

图7 输入特征图数据的提取和重新排布示意图
3 实验结果
3.1 稀疏计算PE的资源开销分析
为了验证本文设计的稀疏计算PE资源开销,利用文献[13]FPGA归一化资源开销(Normalized Resource Consumption,NRC)评估方法,归一化面积如(1)所示。

本设计PE的综合结果如表2所示。表中FIFO采用分布式LUT存储实现。可以看出,计算单元占据了设计PE的主要组成,比例达到了45.4%,存储开销仅有12.8%。这是因为在PE设计中大幅减小了分布式存储开销,更有利于FPGA资源调用和并行设计。

表2 本文提出的稀疏计算PE资源开销
对比不同稀疏卷积设计实现的PE单元,结果如表3所示。其中,乘法占PE面积比例仅仅考虑了计算单元中的乘法单元面积,不考虑加法树累加等结构。相比其他稀疏架构,本文提出的PE单元有效提升了乘法的面积比例,缩小了PE使用的分布式存储开销,更有利于FPGA实现高并行的稀疏计算。

表3 稀疏计算PE的资源开销对比
3.2 面向目标检测网络的实现和对比
考虑16bits×16bits的有符号数乘法器实现需要280个LUT[13]

表4 YOLO网络的FPGA实现对比

续表
本文基于Xilinx VCU118开发板实现YOLOv3网络,并配合软件提取的权重以及每层网络的指令进行测试。测试结果和权威会议及期刊上发表设计的对例如表4所示。从表中可以看出,多数设计采用了深度不深,结构更为简单的YOLO、YOLOv2甚至简化的YOLO-tiny系列网络,而本设计针对深度更深,结构更复杂,准确率更高的YOLOv3网络进行了实现。相比其他设计,本设计提出的加速器硬件架构,能够有效支持更大规模的卷积数据并行计算以及稀疏计算,也因此获得了更高的吞吐性能和面积效率。通过增加数据复用以及稀疏计算有效提升了单DSP的吞吐性能。在归一化面积效率方面,本设计相比文献[10,15,16]分别有2.32、2.01、1.27倍增益。而文献[10]采用的量化比特是16比特,当网络量化为8比特时,其吞吐性能会有所提升。但是文献[10]采用的是批处理的方式来提升其吞吐性能,对于8比特量化结果其延时性能不会有所提升。且文献[10]采用的是多引擎加速架构,难以支持更多的层数和跨层连接的结构。
4 结语
本文提出了一种面向低延时目标检测的FPGA神经网络加速器架构。通过更多的数据复用和优化的高并行卷积稀疏计算,降低了稀疏计算PE中的分布式存储开销,提高计算的并行。通过设计集中式存储阵列结构,支持高并行的卷积计算,能够实现存储阵列和计算阵列之间非一一对应的数据交互。FPGA实现结果显示,与当前目标检测的神经网络加速器设计相比,本文的加速器架构能够支持更复杂的YOLOv3网络,且具有1.27-2.32的归一化面积效率提升以及更好的延时特性。
猜你喜欢
现代装饰(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
现代仪器与医疗(2022年3期)2022-08-12
现代仪器与医疗(2022年2期)2022-08-11
快乐作文(1.2年级)(2022年5期)2022-05-31
计算技术与自动化(2022年1期)2022-04-15
三悦文摘·教育学刊(2021年52期)2021-04-27
上海师范大学学报·自然科学版(2019年5期)2019-12-13
软件导刊(2016年7期)2016-05-14
对联(2015年22期)2015-06-11
