
基于Gecko浏览器内核的谷歌翻译爬虫
2021-08-06 08:25李健
现代计算机 2021年18期
李健
(战略支援部队信息工程大学,洛阳471003)
0 引言
网络爬虫是按照一定规则自动获取Web信息资源的计算机程序[1-2]。根据目标资源的位置不同,网络爬虫可以分为浅层爬虫和深层爬虫。通过超链接能够直接到达的为浅层数据,需要用户登录、提交表单、异步加载等操作才能获得的为深层数据[3-4]。研究发现,Web中的深层数据量远远超过浅层数据[5-6],因此深层爬虫就显得十分重要。目前,异步加载技术广泛使用,这给网络爬虫的开发带来一些困难。对此,可采用模拟浏览器的方法进行采集——让浏览器内核去处理那些复杂的技术细节,爬虫只需要模拟用户操作,等待目标数据返回[7-9]。在爬取过程中,可通过DOM路径实现对元素的定位和数据的抽取[10-12]。
随着人工智能技术的发展,机器翻译的准确率也不断提高,很多互联网公司(如谷歌、百度、微软等)都提供了在线翻译服务。对于普通用户来说,网页翻译是最主要的服务形式,而且是完全免费的。网页翻译虽然免费,但是往往会限制单次翻译的字数。对于少量翻译任务,我们可将原文复制到翻译页面就可以获取翻译结果;但对于较大规模的翻译任务,若仍采用手动方式(逐段复制粘贴)则显得十分低效。对此,可以采用“多次少取”的方式解决大规模语料的自动翻译问题。本文将设计并实现一个基于Gecko浏览器内核的翻译爬虫——借助“谷歌翻译页面”实现自动批量翻译。
1 相关技术
1.1 浏览器工作原理
网页浏览器(Web Browser)简称浏览器,是一种用于检索并展示万维网信息资源的应用程序。用户所看到的网页都是经过浏览器解析、渲染后呈现出的结果,而并非原始网页数据。浏览器的核心功能就是解析网页,解析对象主要包括HTML、CSS和JavaScript,分别对应网页的内容、样式和行为。浏览器解析网页的基本过程如图1所示[13]。
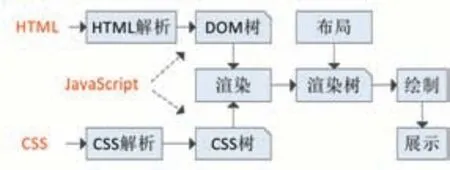
图1 浏览器解析网页的过程
资源加载后,浏览器会将HTML数据解析成DOM树,将CSS数据解析成CSS规则树,还可以通过执行JavaScript代码对它们进行操作。解析完成以上对象,浏览器引擎通过DOM树和CSS规则树来构造渲染树(Render Tree),结合其他资源最终生成页面展示效果。
1.2 常见浏览器内核
浏览器内核是指浏览器的核心部件,主要包括页面渲染器和JS解析器。页面渲染器负责把数据转换为用户在屏幕所看到的样式,JS解析器负责解释和执行网页中的JS代码[14]。表1列出了常见浏览器内核[15-18]。

表1 常见浏览器内核
Trident是由微软公司开发的浏览器内核,随Internet Explorer 4.0首次发布(也称IE内核)。Trident目前仍然是主流的浏览器内核之一,并被广范应用于其他非IE浏览器。WebKit是由苹果公司开发维护的开源浏览器内核,所包含的WebCore引擎和JSCore引擎都是从自由软件衍生而来。Chrome和Opera浏览器早期也曾采用WebKit内核,由于某些原因Google公司从WebKit中分支出自己的Blink内核,随后Opera公司也宣布将转向Blink内核。Gecko是一个能够跨平台使用开源项目,该内核最早由Netscape公司开发,现在由Mozilla基金会维护[19]。
1.3 使用Gecko内核
GeckoFx是对Gecko内核的.NET封装,提供完善的编程接口,这使得.NET程序员可以在WinForm或WFP程序中方便地使用Gecko内核。在Visual Studio中通过NuGet包管理器可直接安装GeckoFx。
在DOM标准下,HTML文档中的每个成分都是节点:大到整个HTML文档,小到每个HTML标签,甚至底层的纯文本都被看作一个结点[20]。GeckoFx核心类之间的关系如图2所示。其中实线表示继承关系,虚线表示包含关系。
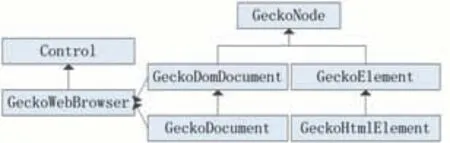
图2 GeckoFx核心类
在GeckoFx框架中,GeckoNode表示所有DOM结点的基类,GeckoDomDocument用于描述DOM文档,GeckoDocument用于描述Html文档,Gecko Element用于描述DOM元素,Gecko Html Element用于描述HTML标签元素。Gecko Web Browser是一个Web浏览器控件(可直接显示在WinForm窗体中),其DomDocument和Document属性分别属于GeckoDomDocument和Gecko Document类型。通过上述对象,可以实现页面的加载和导航,元素的查询和修改。
2 爬虫设计
2.1 系统框架
为了便于描述,我们将任务简化为对中文词表的翻译,每次提交一个词条进行翻译,翻译完成后可导出双语词表。并具体规定如下:中文词表按行存放于文本文件中(对应全部翻译任务),每次提交一行文本进行翻译(对应单次翻译任务),翻译结果以Excel格式导出。翻译爬虫的总体架构如图3所示。
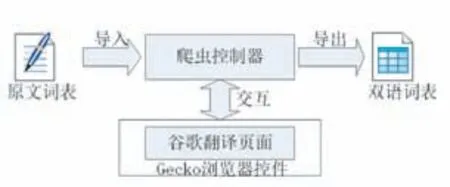
图3 翻译爬虫架构
2.2 工作流程
根据上述思路,爬虫工作流程如图4所示:首先使用浏览器控件加载翻译页面;然后提示用户选择并导入中文词表;每次从待翻译词表中取出一个词条,复制到翻译网页的原文输入框,等待翻译结果返回,从译文输出框读取结果;若翻译任务全部完成则导出结果,否则继续翻译下一词条。

图4 翻译爬虫工作流程
2.3 爬虫界面
爬虫界面如图5所示:使用分隔容器(SplitContain⁃er)将主窗体分为左右两个区域,左侧为用户操作区,包括两个按钮(导入、导出)和一个DataGridView控件;右侧是翻译页面加载区,GeckoWebBrowser控件充满整个区域。

图5 翻译爬虫主界面
3 爬虫实现
我们在.NET平台下使用C#语言编写程序,实现了谷歌翻译爬虫的全部功能。下面将介绍关键模块的实现。
3.1 加载页面
爬虫启动后,首先需要初始化Gecko运行环境,才能使用GeckoWebBrowser控件加载页面。其主要代码如下:

上述代码定义了一个GeckoWebBrowser类型的成员变量(browser),表示Gecko浏览器控件;页面跳转后为浏览器控件添加Document Completed事件,以保证网页加载完毕才能导入词表。
3.2 单次翻译
翻译爬虫的关键步骤就是要模拟用户操作,在浏览器页面中完成原文的输入和译文的读取。通过Firefox开发者工具箱查看页面元素(如图6图所示),可以发现Google翻译页面的原文输入框为一个