
基于改进SMOTE算法和位置编码的漏洞检测模型优化研究
2021-08-06 08:24张铁耀杜晔黎妹红
现代计算机 2021年18期
张铁耀,杜晔,黎妹红
(北京交通大学计算机与信息技术学院,北京100044)
0 引言
传统的漏洞检测方法通常分为三大类:静态分析、动态分析和混合分析[1]。然而传统的漏洞检测的方法在漏洞覆盖率、准确率、运行效率等方面总是存在一些弊端,越来越多的研究者不断尝试把人工智能领域的技术应用到漏洞分析和检测上来。其中机器学习技术已经被证明应用在计算机安全和隐私领域中是有效的,包括恶意域名挖掘、入侵检测、垃圾邮件过滤等,而近些年机器学习在漏洞挖掘上的应用也取得了不错的进展。Harer[2]为了检测C和C++代码中的漏洞,考虑两种互补的方法,一个是利用程序中间表示(IR)提取特征,另一种是直接提取源代码的特征(字符串、数字、操作符等),并在三种不同的模型上比较了训练结果。Russell[3]首次从Debian和Github库中建立了大规模的C++源代码数据集,利用静态检测工具对代码进行标注,利用词法分析器对源代码进行表示,分别使用CNN和RNN进行模型训练。HUANG[4]提出了基于TFIDNN的自动分类模型,提取了词频逆文档频率(TF-IDF)、信息增益(IG)等特征,在DNN神经网络模型中构造了一个自动脆弱性分类器,实现了有效的漏洞检测。Chernis[5]从C的源代码中提取包括函数长度、字符串熵等文本特征,利用支持向量机、决策树和随机森林等分类器对样本进行分类。李元诚等人[6]提出一种基于深度聚类算法,使用AE-KNN模型并进行聚类分析,根据聚类结果计算异常值,从而定位漏洞所在位置。Li[7]是率先在切片的粒度上利用深度学习对源代码进行漏洞检测,通过提取包含数据依赖的codegad⁃get,训练BLSTM网络进行漏洞检测。Li[8]引入了控制依赖关系提取codegadget,并且对比了其他不同的网络模型,证明同时提取数据依赖和控制依赖关系对漏洞检测有着一定的作用。Lin[9]运用函数的抽象语法树进行函数表示,运用LSTM进行学习,证明了在功能层面上对跨项目的漏洞检测是有效的。
然而近期的工作存在以下几点不足:①只能检测一段代码是否含有漏洞,无法进行更加细致的划分;②使用的深度学习网络模型还局限于传统的CNN、RNN及其变形;③在数据集的处理上,没有考虑数据集的不平衡分布。
在上述工作的基础上,本文首先在软件担保参考数据集(Software Assurance Reference Dataset,SARD))中收集了大量的C/C++源代码,并根据漏洞产生的原因对漏洞类型划分为9大类;其次提出了一种针对多分类的基于邻域划分的加权SMOTE算法,用于处理类间分布不平衡的数据集;最后提出了一种混合的深度学习模型Transformer-CNN模型,并且对Transformer模型中的位置编码进行了改进,可以更好适应源代码的漏洞检测。
1 基于TF-CNN的漏洞检测模型
CNN模型最初用于计算机视觉中,现在也广泛的应用在自然语言处理中,通过卷积的方式对文本的词向量表示进行处理,卷积核通常覆盖了上下几行的词,可以捕捉文本的局部特征,但是忽略了上下文对当前文本的影响。Transformer模型作为谷歌提出的一种新型的模型,通过Attention机制实现整个架构,在运行时并不像RNN一样需要依赖前一时刻的计算结果,因此可以并行计算,提高运行的效率,通过一次性遍历整个文本,可以更好地提取文本的全局特征,但是忽视了局部特征对分类结果的影响。
本文融合了两种模型各自的优点,设计了TFCNN混合模型进行系统构建,Transformer编码器通过Self-Attention机制学习源代码的全局特征,CNN编码器通过卷积和池化等操作,可以准确地学习源代码的局部信息。基于TF-CNN模型的漏洞检测模型包括以下六个部分:数据处理、向量表示、加权SMOTE算法、模型训练、特征集成以及漏洞分类,本文提出的模型如图1所示。

图1 系统框架图
(1)数据处理:首先将源代码去除注释与宏定义等语句,然后针对可能产生漏洞的库函数,利用Frama-C工具提取代码切片,将冗长的源代码转化成精简的富含语音信息的切片表示。
(2)向量表示:使用Word2Vec模型对代码切片进行向量表示,将其映射为300维的词向量矩阵。
(3)加权SMOTE算法:对于少数类样本进行加权过采样,将合成样本点加入到原始数据集中作为用于训练的数据集。
(4)模型训练:将词向量矩阵分别送入CNN编码器和Transformer编码器进行训练,其中CNN编码器包括卷积层,池化层和全连接层,其中卷积层采用TextCNN模型提取局部特征,使用3×300、4×300和5×300的卷积核做卷积运算,池化层做最大池化操作将不同尺寸的卷积核提取的特征拼接在一起,最后通过全连接层得到源代码的局部特征表示;Transformer编码器主要通过位置编码、自注意力机制、前馈连接、残差连接、归一化等操作实现,通过层叠的自注意力机制,可以更好地捕获全局信息,在运行时可以并行处理而不用依赖其他结果。
(5)特征集成:Transformer模型利用自注意力机制对整个源代码进行遍历,提取源代码的全局特征;CNN模型通过卷积运算,提取源代码的局部特征。TF-CNN模型分别将Transformer模型与CNN模型学习到的特征表示进行concat拼接,得到代码的综合特征表示。
(6)漏洞分类:通过MLP层将集成特征输入到分类器中,分类器选取Softmax分类器用来计算每个类别的概率值;TF-CNN模型框架采用双通道的形式对源代码进行特征学习,训练时CNN模型和Transformer模型可以并行计算,加快了训练效率。
2 基于对数的位置编码
2.1 常见的位置编码简介
(1)one-hot编码
one-hot编码,主要是采用N维的矩阵来对N个词汇进行编码,每个词汇都由其索引表示,并且只有该索引位对应的矩阵中的表示为1,其他都为0。
one-hot编码维度是整个词汇表的大小,维度非常巨大,编码稀疏,会使得计算代价变大,而且one-hot编码时假设单词与单词之间是独立的,无法体现单词与单词的关系,更无法表示代码的位置信息。
(2)绝对位置编码
绝对位置编码直接对不同的位置的词汇随机初始化一个位置编码,加到词向量表示中作为模型的输入。尽管不同位置对应的位置编码不同,可以包含一定的位置信息,但是绝对位置编码无法捕获位置间的相对关系。
(3)相对位置编码
最常见的相对位置编码是通过正余弦函数进行表示,计算公式如下:

其中,pos表示词汇在序列中的位置,i表示向量的某个维度,dmodel表示向量维度的大小。三角函数的性质如下:

对于位置pos+k则有如下计算公式:

可以看出,任意位置pos+k的位置编码均可以转化成位置pos的线性表示,因此公式(1)(2)既可以表示词汇的绝对位置,也可以表示词汇的相对位置。
2.2 基于对数的位置编码
上述三种编码方式并不适合漏洞检测模型,同样的代码语句在不同人编写的代码中出现的位置可能不同,但是代码整体的逻辑却是相似的。如果单纯地使用相对位置编码或绝对位置编码,语句出现顺序的不同会对应不同的位置编码,但是这种情况并不影响整个代码的语音信息。本文设计了基于对数表示的位置编码,在公式(1)(2)的基础上,对pos的表示进行修改,允许每一条代码语句出现的顺序有所不同,同时保留了代码逻辑层次上位置信息。
基于对数表示的相对位置编码以可能出现漏洞的库函数对应的词汇为位置原点(假设位置为P,pos=1),计算每个词汇(假设位置为l)到库函数的距离,再计算以2为底该距离的对数,并向上取整数;对于距离小于0的词汇(位于库函数之前的词汇),先对距离取绝对值,再计算对数,并对结果取负数,计算公式如下:


利用公式(6)、公式(7)可以证明,基于对数表示的位置编码,同样可以表示词汇的相对位置和绝对位置。对于距离库函数较远的词汇,在一定距离内的位置编码保持一致,但是如果词汇距离跨度较大,也对应了不同的位置编码。
3 基于邻域划分的加权SMOTE算法
3.1 SMOTE算法简介
SMOTE算法是经典的过采样算法,通过人工合成少数类样本,减少类间分布不平衡的现象,从而改善模型的训练结果。SMOTE算法首先在少数类样本中选择一个作为种子样本,然后随机选择k近邻中的一个进行线性插值,从而合成少数类样本。合成公式如式(11)所示:

其中,x代表种子样本在欧氏空间的坐标,y代表随机选取的k近邻的坐标,β是一个随机值,介于0到1之间。
SMOTE算法通过线性插值合成少数类样本,使得模型能更好地学习少数类样本的特征,减少了过拟合现象的发生。但是SMOTE算法仍有可能在线性插值时离多数类样本过近,带来噪声样本,或者生成的样本离种子样本过近,没有增加少数类样本的多样性。如图2所示,SMOTE算法仍可能会引入噪声数据或者发生过拟合的现象。

图2 SMOTE算法
3.2 基于邻域划分的加权SMOTE算法(WSMOTE)
在W-SMOTE算法中,在对于少数类样本a,N(a)表示a的k近邻,称为a的邻域。如果N(a)中的所有样本都是多数类,则a为孤立样本;如果N(a)中的所有样本都是少数类,则a为内部样本;如果N(a)中既包含少数类样本也包含多数类样本,则a为边界点,如图3所示。
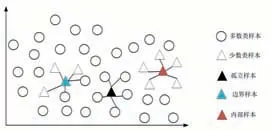
图3 基于邻域划分的加权SMOTE算法
因此,根据样本邻域种类的不同,可以将样本划分为三种不同的子集:
Aiso:孤立样本集合
Ain:内部样本集合
Abor:边界样本集合
按照邻域的不同对所有的少数类样本进行划分,每一个少数类样本仅被划分到一个子集中,并且所有子集的并集构成了整个少数类样本。
将少数类进行划分后,根据少数类所属子集的不同,采取不同的权重计算方法,并且根据不同的权重,合成不同数目的少数类样本,从而在解决类间分布不均衡问题的同时,尽可能避免生成噪声数据。
(1)基于邻域划分的采样率计算
不同的子集划分具有不同的采样价值,根据不同的划分,分配不同的采样率。由于使用的是针对检测多种漏洞类型设计的数据集,对于孤立样本点,即使在训练过程中可能会带来噪声影响,但由于该样本是真实包含漏洞信息的,因此在合成少数类样本时,不移除任何孤立样本点,也不将孤立样本点作为种子样本合成少数类样本;为了更好地区别不同类型漏洞,在合成少数类样本时,需要更加重视利用边界样本作为种子样本合成少数类样本。边界样本集合与内部样本集合的采样率不同,会引起不同的性能,通过多次实验,选取7:3为最终的采样率。
(2)基于位置信息的采样权重计算
对于内部样本点,如果它越靠近少数类样本中心或者样本边界,则认为样本价值越大。根据每个少数类样本相对于边界样本的欧氏距离确定每个样本的相对位置,每个少数类样本根据相对位置的不同被分配不同的权重。少数类样本越靠近样本中心或样本边界就拥有更大的权重,在生成新样本时,每个样本根据权重确定合成样本的数量,权重越大,合成的数量越多。
基于位置权重的采样率计算公式如下:
①计算种子样本与边界样本的距离之和

(3)基于密度大小的采样权重计算
对于边界样本点,如果种子样本与其他边界样本之间的距离较近,会导致合成的样本与边界样本依然较近,相似度较高,虽然增加了少数类样本的数量,但少数类样本的多样性没有增加,仍会出现过拟合的情况。因此对于边界集合的样本点,基于种子样本的密度大小计算采样权重,对密度大的样本设置较低的采样权重,对密度低样本设置较高的采样权重。
样本的密集程度可以用种子样本与其他样本的欧氏距离之和来表示,距离之和越大表示样本越稀疏,距离之和越小,表示样本越密集。基于密度权重的采样率公式计算如下:
①计算种子样本与其他边界样本的距离
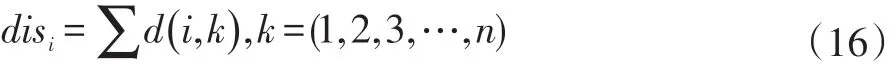
②距离越大表示密度越低,根据距离的倒数计算权重
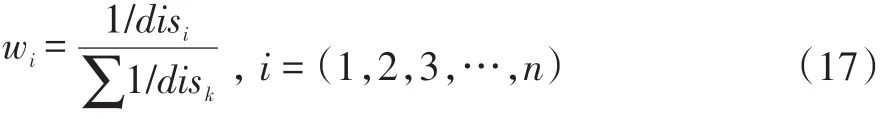
3.3 W-SMOTE算法计算步骤
在合成少数类样本时,将其他所有样本(不含漏洞的样本和其他漏洞类型的样本)视为多数类样本,W-SMOTE算法的实现如下:

上述算法首先计算种子样本与其他样本的距离,查找种子样本的邻域,并根据邻域的属性,将其划分到不同的子集中;接下来对于不同子集中的少数类样本计算不同的采样权重,进而计算需要合成的样本数目;最后根据采用权重与采样数目使用SMOTE算法合成少数类样本,将合成样本点加入到原始数据集中作为用于训练的数据集。
4 实验与分析
4.1 数据集
为了建立一个合理有效的模型,首先要建立一个样本足够大,覆盖漏洞种类数目足够多的数据集。本文使用的数据集来自软件担保参考数据库(Software Assurance Reference Dataset,SARD)。主要针对C/C++源码的漏洞检测,从SARD收集了64099个程序文件,涉及118种不同CWE漏洞类型。
根据漏洞产生的原因,本文将采集到的漏洞程序分类为表1中的9种类型。这种分类旨在分析漏洞产生的原因,包括它们之间的相互依赖关系,而不关心漏洞的检测方法或者漏洞在代码中的位置,主要基于对代码行为进行抽象描述,在代码逻辑上进行分类。

表1 标签与漏洞类型
4.2 代码切片
研究表明[7,10],通过对关键库函数进行代码切片,进行源代码的漏洞检测是有效的。本文利用Frama-C工具提取源代码的代码切片。以往的研究通常都对代码切片中的函数名以及变量名进行了正规化处理[12],例如对变量名统一命名为VAR1、VAR2,对函数名命名为FUN1、FUN2等。在本次实验中发现,不对代码切片进行正规化处理反而会取得更好的训练结果,分析原因如下:
(1)在实际代码的编写中,同样的名称在不同的函数里往往代表不同的含义;
(2)在不同的代码切片中,正规化会使得同样功能的函数名可能会被替换成不同的名称;
(3)在训练过程中,如果使用了正规化的命名,模型会认为这些变量代表了同样的含义,从而会影响模型训练的结果。
利用代码切片工具,共生成187692个代码切片,其中,145328个代码切片不包含漏洞,另外42364个代码切片是含有漏洞的。根据表1的划分规则,每种漏洞类型包含的代码切片数目如图4所示。

图4 漏洞类型分布
4.3 实验环境与评价指标
本文设计的所有实验均在Windows10操作系统下使用Python语言开发,使用TensorFlow框架搭建神经网络,实验环境的具体硬件配置和软件参数如表2所示。

表2 硬件配置与软件参数

表3 混淆矩阵
为了验证系统的性能,通常使用混淆矩阵计算精确率(Precision)与召回率(Recall)进行分析评价;对于漏洞挖掘系统,最佳的实验结果是在保证较高的精确率的同时,也能保证较高的召回率,保证系统既能准确地检测出不含漏洞的代码,也能检测出含有漏洞的代码。本文使用Fβ综合表示对精确率和召回率,只有当查准率和查全率均比较大时,Fβ的值才会增大。同时,为了验证W-SMOTE算法对少数类分类正确率的影响,采用特异度(Specificity)进行评价。精确率、召回率和特异度可以通过混淆矩阵进行计算,而Fβ则通过公式(21)进行计算,其中β为调节参数,代表召回率与准确率的重要性所占比例,本文中设置为1。

4.4 实验结果与分析
在训练阶段,使用Adam优化器对模型参数进行优化,参数设置如下:β1=0.9,β2=0.999,ε=10-8,学习率α=0.001。
基于W-SMOTE的TF-CNN模型的召回率为92.70%,精确率为98.45%,Fβ值为95.49%。对于不同漏洞类型的特异度,如图5所示。可以看出,基于W-SMOTE算法的TF-CNN模型可以很好地检测出源代码是否含有漏洞,尤其在没有漏洞的源代码检测上性能最佳;从图5可以看出,对于含有漏洞的源代码,系统可以较好地对检测出的漏洞进行分类,方便开发人员定位漏洞产生的位置。

图5 不同漏洞类型的特异度
(1)位置编码对模型性能的影响
为了验证本文提出的基于对数的位置编码算法的有效性,在Transformer编码器中分别使用one-hot编码、绝对位置编码、相对位置编码和基于对数的位置编码进行实验,精确率、召回率、特异度和Fβ值如表4所示。可以看出,基于对数的位置编码更加适应漏洞检测系统,既能对代码整体的位置信息进行表示,也减少了代码语句出现的不同位置带来的影响。

表4 不同位置编码的测试结果
(2)不同神经网络对模型性能的影响
为了进一步验证TF-CNN模型能准确的学习源代码的局部特征与全局特征,相对于其他模型能更准确地挖掘源代码的漏洞,本文设计了TF-CNN模型与单一的Transformer模型以及文献[11]设计的BLSTM模型在同样没有进行过采样的数据集上进行训练,实验结果如表5所示。

表5 原始数据集的测试结果
从表5中可以看出,本文设计的TF-CNN模型是切实可行的,与其他模型相比,TF-CNN模型通过提取源代码的局部特征与全局特征,对比其他模型可以更充分地学习源代码的语义信息,准确检测出不含漏洞的源代码的同时,也能更加准确的检测出含有漏洞的源代码。TF-CNN模型的特异度达到了93.53%,优于Transformer模型和BLSTM模型,也就是说TF-CNN模型通过提取源代码的局部特征,能更好地检测出源代码的漏洞。
(3)W-SMOTE算法对模型性能的影响
为了验证W-SMOTE算法在源代码漏洞挖掘上的有效性,将W-SMOTE算法应用在上述三种模型中进行对比,实验结果如表6所示。

表6 合成数据集的测试结果
表5和表6综合对比,模型的召回率得到明显提高,也就是说基于邻域划分的加权SMOTE算法能极大减少类间分布不均衡带来的影响,通过合成少数类样本减少过拟合的发生,模型可以对不含漏洞的源代码进行准确的分类。除此之外,基于邻域划分的加权SMOTE算法不仅可以应用在TF-CNN模型上,应用与其他的模型时,同样可以提高模型的性能。
5 结语
为了优化漏洞检测模型,本文提出了基于邻域划分的加权SMOTE算法;同时设计了TF-CNN混合模型,改进了位置编码,更加适配漏洞检测系统。从实验结果来看,改进的位置编码更加适合漏洞检测系统,减少了由于代码语句出现顺序的不同带来的影响;W-SMOTE算法可以很好地应用在多种模型中,有效地解决了类间分布不均衡的问题;TF-CNN模型相对于其他模型,在准确率、召回率、特异值、Fβ值等方面均优于其他模型。综合看来,使用基于W-SMOTE算法的TF-CNN模型,能够很好地检测出源代码是否含有漏洞以及漏洞类型,可以广泛地应用到漏洞检测中。
猜你喜欢
农业工程学报(2022年7期)2022-07-09
现代信息科技(2021年21期)2021-05-07
电子技术与软件工程(2019年8期)2019-07-16
新高考·高二数学(2016年7期)2017-01-23
农家书屋(2016年11期)2016-12-23
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年17期)2016-10-20
世界汽车(2016年9期)2016-09-29
股市动态分析(2015年16期)2015-09-10
知识力量·教育理论与教学研究(2013年11期)2013-11-11
