
基于文本挖掘的微博舆情主题图谱可视化研究
2021-08-05 06:54:54邢云菲李玉海
农业图书情报学刊 2021年7期
邢云菲,李玉海,2
(1.华中师范大学信息管理学院,武汉 430079;2.湖北省数据治理与智能决策研究中心,武汉 430079)
1 引言
微博是基于用户关系的舆情传播、信息共享的社交媒体平台。微博凭借其终端移动性、内容精简性、用户交互便捷性以及动态内容聚类方式,成为中国最受欢迎的社交媒体平台之一[1]。微博舆情是指公众在某些社会热点事件发生后通过微博平台表达其态度、观点和意见,具有动态性、复杂性和群体极化性等特征[2]。2019 年12 月湖北省武汉市发现多起病毒性肺炎病例,诊断为新型冠状病毒。在该事件的信息传播与交流过程中,微博成为公众获得相关报道和讨论的主要平台之一。由于新冠状病毒事件的突发性和高影响力,使微博平台日均发布微博和评论数量达到百万级,为政府和微博舆情监管部门的管理工作带来巨大挑战。如何针对海量微博用户评论信息快速挖掘用户关注内容,分析用户评论信息中的隐性关联,帮助政府和舆情管理者掌握舆情走势,及时定位发布网络谣言的用户群体并进行监管是本文的主要研究意义。目前学术界对微博舆情的研究主要关注舆情传播主题挖掘、意见领袖识别、用户关系挖掘等方面[3-6],较少学者针对微博用户评论文本进行文本聚类研究并构建主题图谱通过可视化的形式挖掘微博用户关注主题。
本文基于文本挖掘中的聚类技术,结合主题图谱理论和构建方法,以新浪微博平台为例,构建微博用户评论文本的主题图谱,通过聚类分析和剖析图谱结构特征,为微博舆情文本挖掘研究提供了新的研究视角。在实践层面,本研究能够指导微博舆情管理部门进行舆情管控、防止不良舆论扩散、维护微博平台和谐健康发展。同时,本研究也对帮助政府及时了解民情、维护社会秩序、避免引发恐慌具有重要作用。
2 相关研究工作
微博舆情将网络舆情赋予一个特定的平台,公众对与其自身利益密切相关的热点话题在微博平台发表主观性意见和观点,并互相讨论形成传播力场[7]。根据微博舆情用户发布文本内容挖掘舆情传播特征具有重要研究价值,国内学者纷纷开展对微博舆情文本挖掘的研究。吴青林[8]通过话题聚类及情感强度分析中文微博舆情对舆情演进趋势进行预测;周鹏[9]提出基于特征词抽取技术的微博事件内容聚合方法;廖海涵[10]基于生命周期理论结合文档主题生成模型(LDA)方法进行舆情主题观点发现以及语义分析等。
文本聚类分析是指利用集合中文本之间的相似性对文本进行团簇识别。目前在社交媒体分析中,文本聚类的分析技术应用十分广泛。黄微[11]以文本聚类结果和文本聚类有效性为依据,提出网络舆情衍进的判别标准和舆情衍进指数的构建过程;张颖怡[12]分析聚类集成在学术文本聚类中的有效性的基础上,展开了基于特征词的学术文本聚类研究。如何基于微博舆情的用户评论内容进行文本聚类的研究则较少;朱晓峰[13]使用K-Means 算法通过计算文本平均相似度进行微博聚类中心簇研究;陈雪刚[14]同样使用改进的文本相似度计算模型,使文本能够自主聚类,为微博舆情监测提供指导。然而当前较少有研究将微博舆情传播的用户评论文本聚类结果以可视化的形式展现出来。
针对主题图谱的研究,国外学者GOLD 等[15]采用点匹配和图匹配距离度量聚类的方法学习二维点聚合图,通过图谱显示知识的优化聚类结果。CHUNG 等[16]在2005 年提出一个网络知识发现视觉架构,集成了Web 挖掘、集群和可视化技术以进行知识管理。国内学者潘东华[17]基于专利文献分类码,结合领域本体中的语义相似度构建主题图谱;尚小溥[18]对自然语言处理技术在超声文本环境下的应用进行改进,建立其结构化知识网络。当前学者从微博用户关系角度以及话题演进角度构建微博舆情用户关系图谱和话题图谱。王丹[19]从微博主体(用户)、客体(信息)以及主体客体相结合形成的全景3 个维度,进行微博舆情图谱的构建;刘雅姝[20]利用LDA 方法,以多维特征融合分析视角构建舆情话题图谱。主题图谱已经成为知识管理过程中揭示知识关联的重要手段,是情报领域的一大研究热点。然而,基于文本聚类方法,构建微博舆情传播过程中用户评论文本的聚类主题图谱的相关研究则较少。本文选择重大突发公共卫生事件舆情话题传播具有较强代表性,通过对微博舆情用户评论文本进行文本聚类的图谱可视化研究能够揭示如何快速识别海量文本主题内容,为微博舆情文本主题图谱构建研究提供了新的挑战。
3 微博舆情主题图谱构建
本文提出的微博舆情主题图谱构建流程如图1 所示。①数据采集及处理。使用Python 采集人民日报发布的“武汉加油”话题下微博用户评论内容,形成文本数据库。②实体抽取。通过数据清洗和分词构建特征词实体数据库。③实体关系抽取。以特征词的关联关系为实体间关系绘制图谱并进行对比分析。通过使用不同文本相似度计算方法、网络优化算法以及聚类标签生成方法获得实体关系。④聚类可视化分析。对图谱进行聚类簇分析、实体中心度分析并挖掘舆情演化机制。
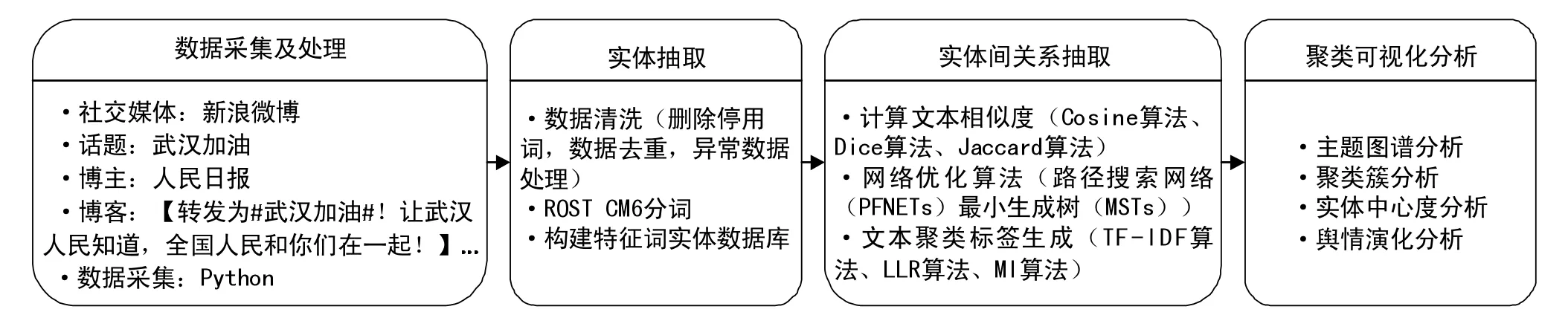
图1 微博舆情用户评论文本的主题图谱构建方法Fig.1 Construction method of topic graph for Weibo public opinion
3.1 数据采集
2020 年初,新型冠状病毒肺炎疫情发生,微博迅速成为民众了解疫情动态和走向的重要平台。面对疫情,微博用户为疫情防治积极贡献力量,其规模大幅增长。据Questmobile 报道[21],微博日活跃用户规模于1 月27 日达到2.39 亿,相比疫情前平日上涨37.5%。自疫情发生以来,超过5 000 万用户已累计发布3.5 亿条与疫情相关的微博;平均每天超过2 亿网友通过微博关注最新疫情、获取防治服务、参与公益捐助。数据的持续增长,印证了微博在重大突发事件网络舆情传播过程中的独特价值。
本文选取“新冠病毒”话题作为数据源,该突发事件网络舆情是互联网信息流的集中体现,一方面反映着大众的关注所在,另一方面也发挥着舆情的导向发酵作用。本文以“新冠病毒”为关键词,分析疫情在该阶段发展过程中国内舆论焦点的变化,关注度的高低,以及各时间点的标志性事件。本文最终选取“武汉加油”话题,其相关话题图谱如下图2 所示,涉及重要关键词包括“抗击疫情”“中国加油”“白衣天使”“公关软文”等。本文使用Python 采集人民日报于1 月23 日7:17 发布的“【转发为# 武汉加油#!让武汉人民知道,全国人民和你们在一起!】 ...打赢这场防疫战!”。获取的字段包括用户昵称、ID、评论内容、时间和工具端等。本文共采集到37 845 条微博用户评论信息,存入文本数据库。
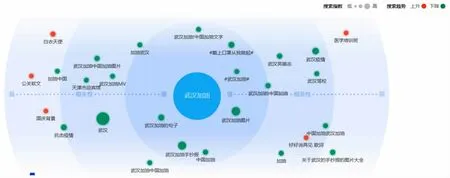
图2 “武汉加油”事件相关话题图谱Fig.2 Related topic graph of“Wuhan refueling”event
3.2 数据处理
在实体关键词抽取阶段,首先检查文本数据库中的数据一致性,处理无效值和缺失值,以进行数据清洗。包括删除停用词、缺失值、空字符串和乱码数据、异常数据等,最终得到32 688 条有效数据。然后基于清华大学开发的THUOCL 词库,使用ROST CM6 进行分词,人工添加网络热门词语和话题相关词语,如大数据、淘宝、热干面、封城等。然后启动归并词群表、保留词表和过滤词表,比对带分词数据库中和分词词库进行分词,抽取到实体保存在数据库中。最后过滤停用词,计算特征词的词频并转换为词向量。
实体关系抽取为计算实体间关联度的过程。通过CiteSpace 软件计算实体的文本相似度,使用不同网络优化算法以及文本聚类标签得到实体间关联关系。本文使用的文本相似度算法包括Cosine 相似度算法、Dice 相似度算法以及Jaccard 相似度算法;在网络优化方面,本文使用两种网络优化算法分别为路径搜索网络(PFNETs)算法和最小生成树(MSTs)算法;在文本聚类方面,分别基于TF-IDF 算法、LLR 算法和MI 算法标注聚类标签。
4 讨论与分析
4.1 微博舆情主题图谱分析
通过对数据进行处理,分别基于3 种文本相似度计算方法和两种网络优化处理方法构建微博舆情文本的主题图谱如图3 所示。在处理该话题下微博用户评论文本可视化上,使用Cosine 函数和Dice 函数(图3(a)~(d))进行文本相似度处理比Jaccard 函数效果更好。使用Jaccard 函数处理得到的图谱(图3(e)、(f))具有相对较高的分散程度和延展性。使用Cosine函数处理得到的图谱有多个中心或星形节点,而Dice函数处理得到的图谱聚类簇更明显。
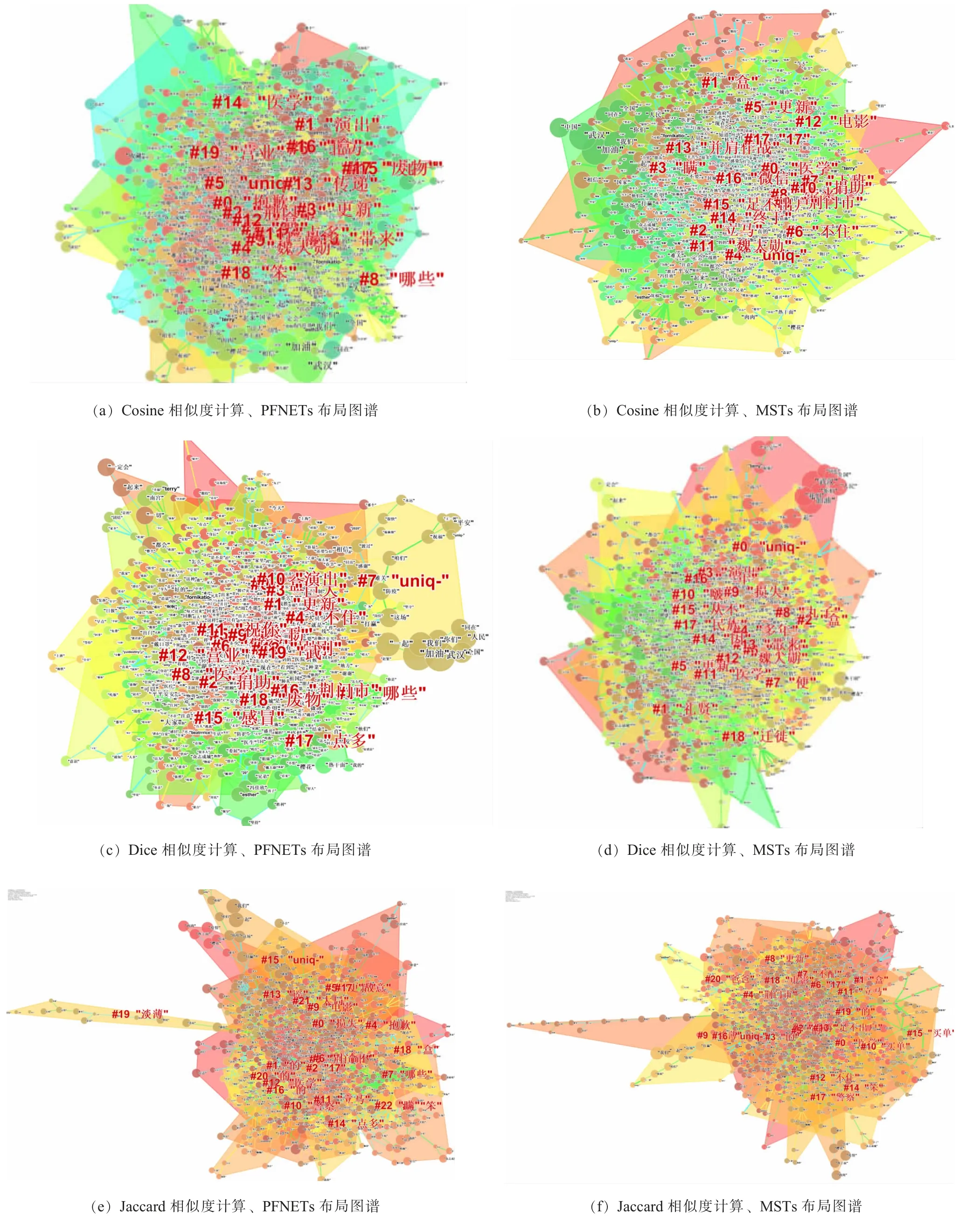
图3 微博舆情用户评论文本的主题图谱Fig.3 Topic graph of Weibo users'comments
在网络优化处理算法上,路径搜索网络(PFNETs)显示出比最小生成树(MSTs)更优越的优化特征。尽管中心度较高的节点主导了MSTs 模型的结构,但由于MSTs 从高中心度节点的最短路径中删除了潜在的重要连接,因此MSTs 结构不能很好地描述网络分布的特征。相比之下,PFNET 模型能够清楚地展示高中心度节点在保持一些最关键路径的内聚性方面的优势,这反过来又使特征词聚类更加具有可预测和可解释性。在本文采集的关于“武汉加油”话题的文本数据中,使用PENETs 算法得到的网络优化效果更好。
使用Jaccard 函数进行文本相似度计算、PFNETs进行网络优化以及Jaccard 算法和MSTs 算法组合得到的图谱能够得到最多聚类簇,均为21 个。说明相比较Cosine 和Dice 函数,Jaccard 函数处理得到的图谱能够得到最多聚类簇。使用Cosine 函数进行文本相似度计算得到的聚类簇数量最少。从数据结果来看,使用Dice 函数进行文本相似度计算,PFNETs 进行网络优化得到的聚类效果更好。该算法聚类中得到的“捐助”“医学”“感冒”均为该话题下正确聚类集合。
依据网络结构和聚类的清晰度,图谱的密度、模块化系数和平均轮廓值结果如表1 所示。模块值(Q值)大于0.3 说明社团结构显著,Q 值大于0.5 聚类平均轮廓值平均轮廓值(S 值)能够衡量图谱紧密性和分离性。S 值大于0.5 则聚类结果合理;S 值大于0.7则聚类结果较标准。数据结构显示,使用不同文本相似度和网络优化算法得到的图谱密度较接近,使用PFNETs算法比MSTs 算法得到的图谱密度、模块值以及平均轮廓值都稍高,基于Jaccard 相似度算法得到的图谱模块值高于Cosine 和Dice 相似度处理得到的图谱模块值,而图谱的平均轮廓值则相反。说明使用Jaccard 相似度算法的图谱模块化程度更高,社团结构更显著,但聚类效果不如使用Cosine 和Dice 相似度算法得到的图谱。
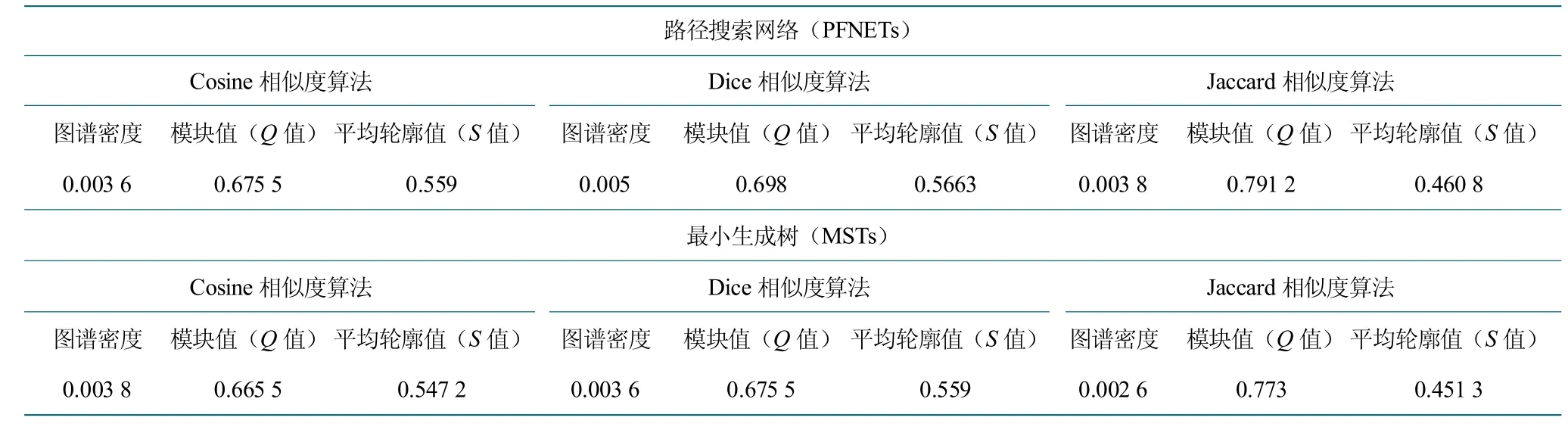
表1 基于不同文本相似度和网络优化算法的图谱指标统计Table 1 Index statistics based on different text similarity and network optimization algorithms
4.2 微博舆情文本聚类分析
3 种相似度计算方法下和两种网络优化算法下的聚类表如表2 所示。表中统计了每种组合下得到聚类结果中节点数量排在前7 的聚类簇,节点数量、聚类平均轮廓值(Silhouette)、以及在3 种聚类方法(TFIDF、LLR 和MI)下的标签内容。使用Dice 相似度计算、MSTs 进行网络优化得到的聚类簇中节点数量最多,cluster#0 包含66 个特征词。Jaccard 算法和PFNETs 算法组合、Cosine 算法和MSTs 算法组合以及Jaccard 算法和MSTs 组合得到的聚类簇中节点数量相对较少,最多的簇仅包含52 个节点。从聚类簇的S 值结果来看,使用Jaccard 算法得到的结果相对更标准,其中和PFNETs 算法组合的图谱聚类效果最好,S 值均达到0.73 以上。Dice 算法和PFNETs 算法组合的图谱聚类结果准确率较低,S 值均低于0.7,但聚类结果较接近舆情现实情况。3 种(TFIDF、LLR 和MI)标签显示结果来看,TFIDF 产生的聚类标签更符合“武汉加油”话题下的实际评论情况,LLR 和MI 算法仅在单一情况下能够产生比TFIDF 更准确的聚类标签。
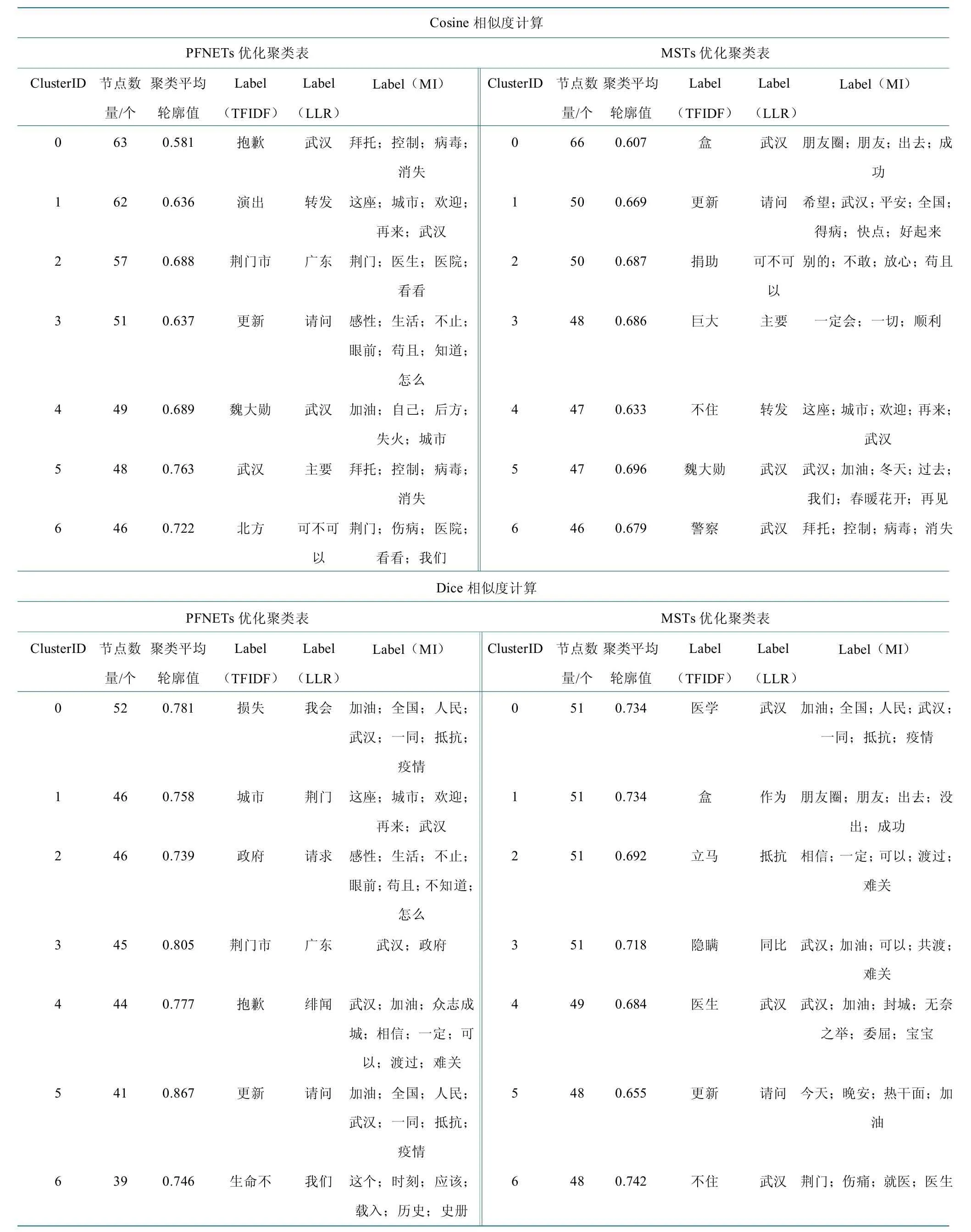
表2 基于不同文本相似度和网络优化算法的文本聚类表Table 2 Text clustering based on different text similarity and network optimization algorithms
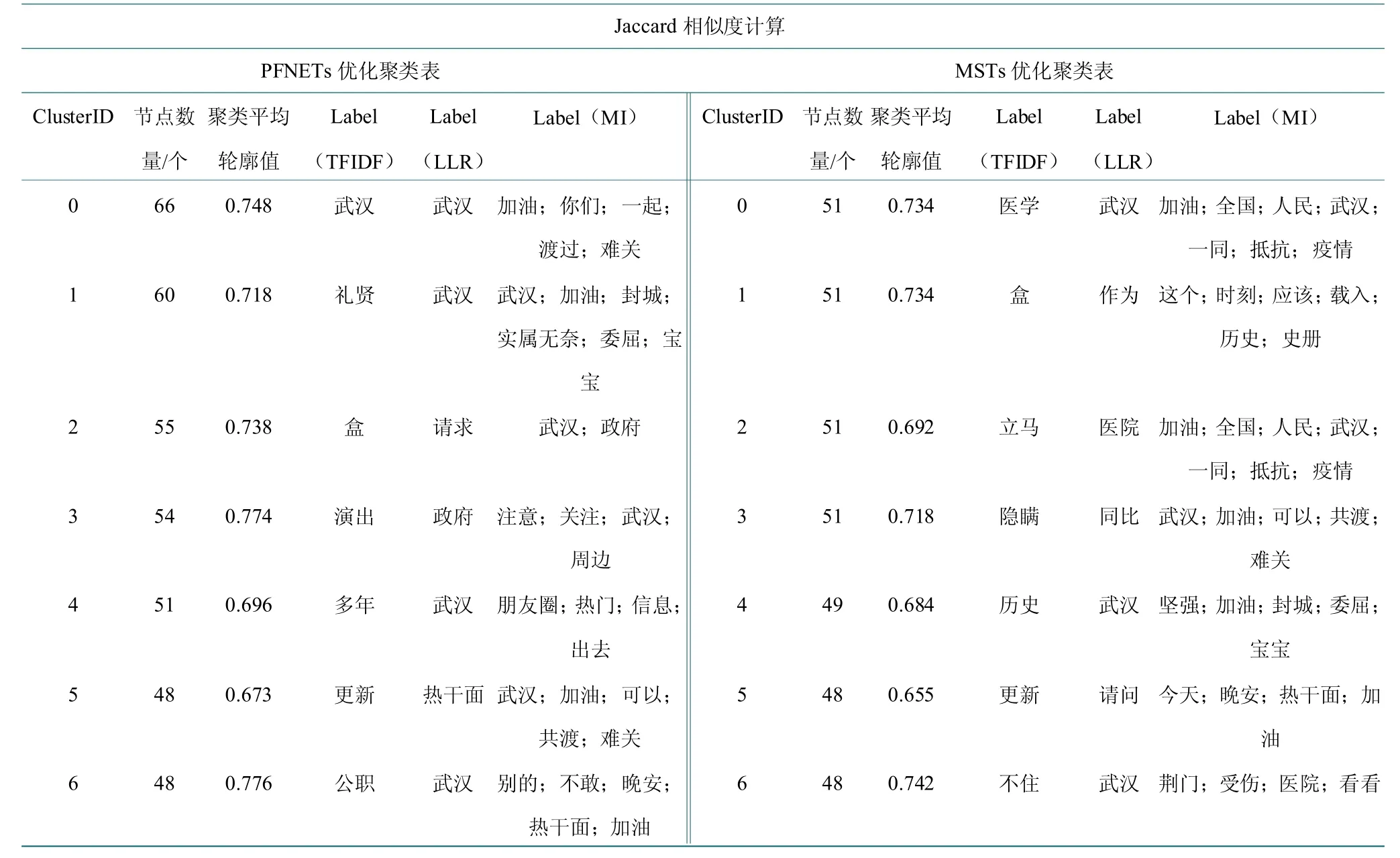
表2 (续)Table 2 (continued)
相关舆情管理部门在使用本文构建的主题图谱分析微博用户评论内容时,使用Cosine 或Dice 算法进行文本相似度计算,PFNETs 算法进行网络优化,TFIDF绘制聚类标签,能够快速了解用户关注主题,在保证聚类准确度的基础上提高工作效率。
4.3 特征词中心度分析
本文对微博舆情文本聚类特征词的中心度进行分析,分别分析该6 个图谱中中心度值排在前10 的特征词,如表3 所示。结果显示,不论使用哪种文本相似度计算方法,使用MSTs 算法进行网络优化处理得到的图谱中特征词的中心度都比PENETs 算法高。而使用Jaccard 算法进行文本相似度计算得到的特征词中心度比Dice 算法高,Cosine 算法处理得到的特征词中心度最低。因此,使用Jaccard 算法和MSTs 算法组合得到的特征词点度中心度是6 个图谱中最高的。
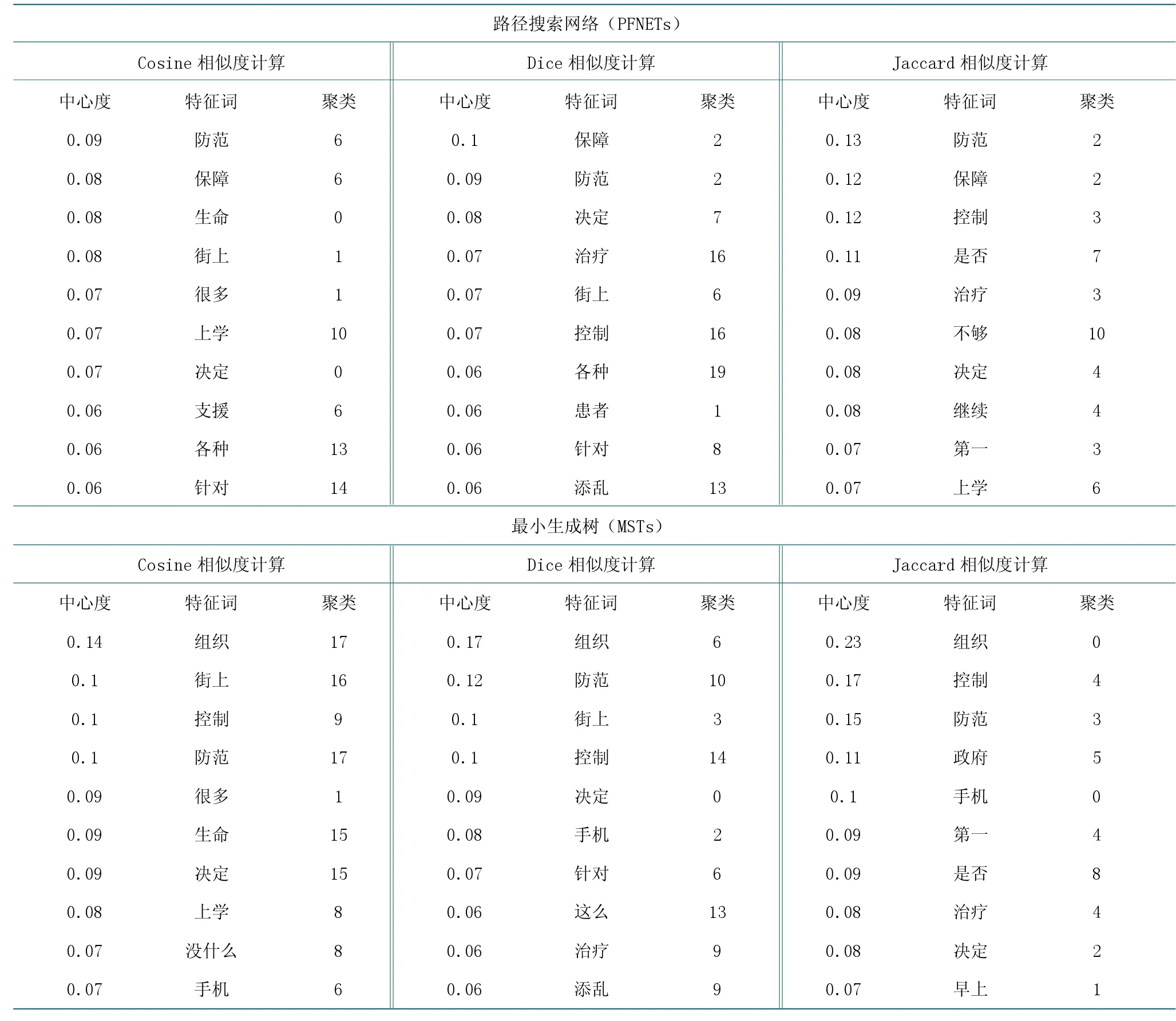
表3 基于不同文本相似度和网络优化算法的特征词中心度统计表Table 3 Statistics of word centrality based on different text similarity and network optimization algorithms
在Cosine 算法和PENETs 算法组合的图谱中,特征词“防范”“保障”和“支援”均属于第6 聚类簇;在Jaccard 算法和PENETs 算法组合的图谱中,特征词“控制”“治疗”和“第一”均属于第3 聚类簇;在Jaccard 算法和MSTs 算法组合的图谱中着3 个特征词均属于第4 聚类簇。在中心度排名前10 的节点中,有3 个节点来自一个聚类簇,说明该簇是图谱中的核心聚类簇,在图谱中具有重要位置。微博舆情管控主体通过本文提出的文本聚类可视化方法能够快速定位图谱中具有较多高中心度特征词的聚类簇,这些高中心度值得特征词能够代表该话题下微博用户的最主要观点。同样,单一中心度高的特征词所在簇也需要引起管理者的重视,因为即使该簇中仅有一个特征词具有高中心度,这个特征词也能极大代表该簇中用户评论内容的核心观点。
4.4 微博舆情演化分析
将微博舆情用户评论内容按照事件发展时序划分为突发期、蔓延期和消散期。网络舆情话题热度与信息数量呈正相关。假设网络舆情信息传播数量是关于时间的连续可微函数,N=N(t)。N 表示舆情信息传播数量。设t=0 时N 的初始值为N0。N 的上限为T,r 为固有增长率[22,23],则:
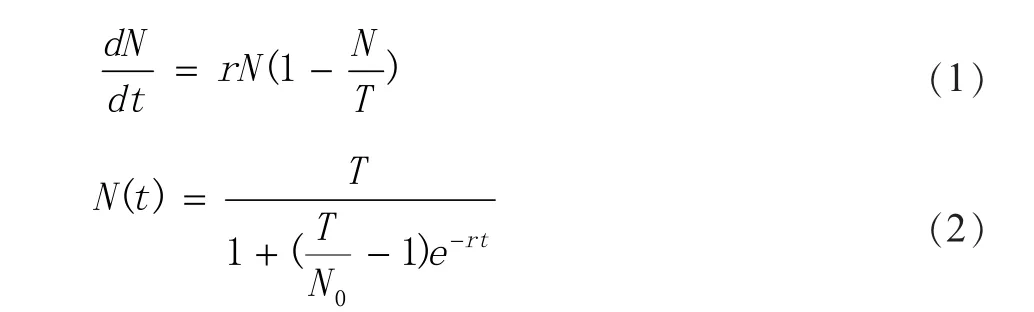
则将舆情传播过程划分为突发期、蔓延期和消散期的两个关键时间点为:
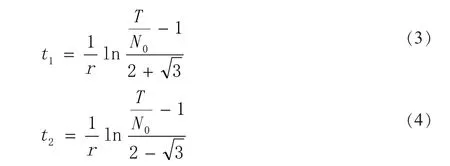
经计算两个关键时间点分别在1 月23 日11:23 和1 月26 日14:40。将文本数据使用CiteSpace 时间演化序列图按照不同时期进行布局得到微博舆情演化图谱如图4 所示。图谱中的实体为用户评论特征词,实体间关系为用户评论特征词关联关系,实体间连线数字代表这两个实体的关联强度值。如上文论述,使用Dice 算法计算文本相似度,Pathfinder 算法进行网络布局得到的图谱的模块化值和平均轮廓值最高,各聚类簇的平均轮廓值也最高,并且经过TF-IDF 计算得到的聚类结果相对更合理,因此基于该算法组合计算实体间关联强度值。关联强度值主要在0.2~0.5 之间,值越高代表这两个特征词关联次数较多。数据结果显示,在该事件的爆发期,用户评论主要集中在对武汉疫情的关注和对武汉人民的鼓励,希望武汉人民能够平安度过困难;在蔓延期主要为武汉人民的回应,包括感谢来自各地的网民的支持,以及对感染群众的安慰和祝福;在消散期主要为网民对疫情发展严重程度的讨论以及战胜疫情的决心。
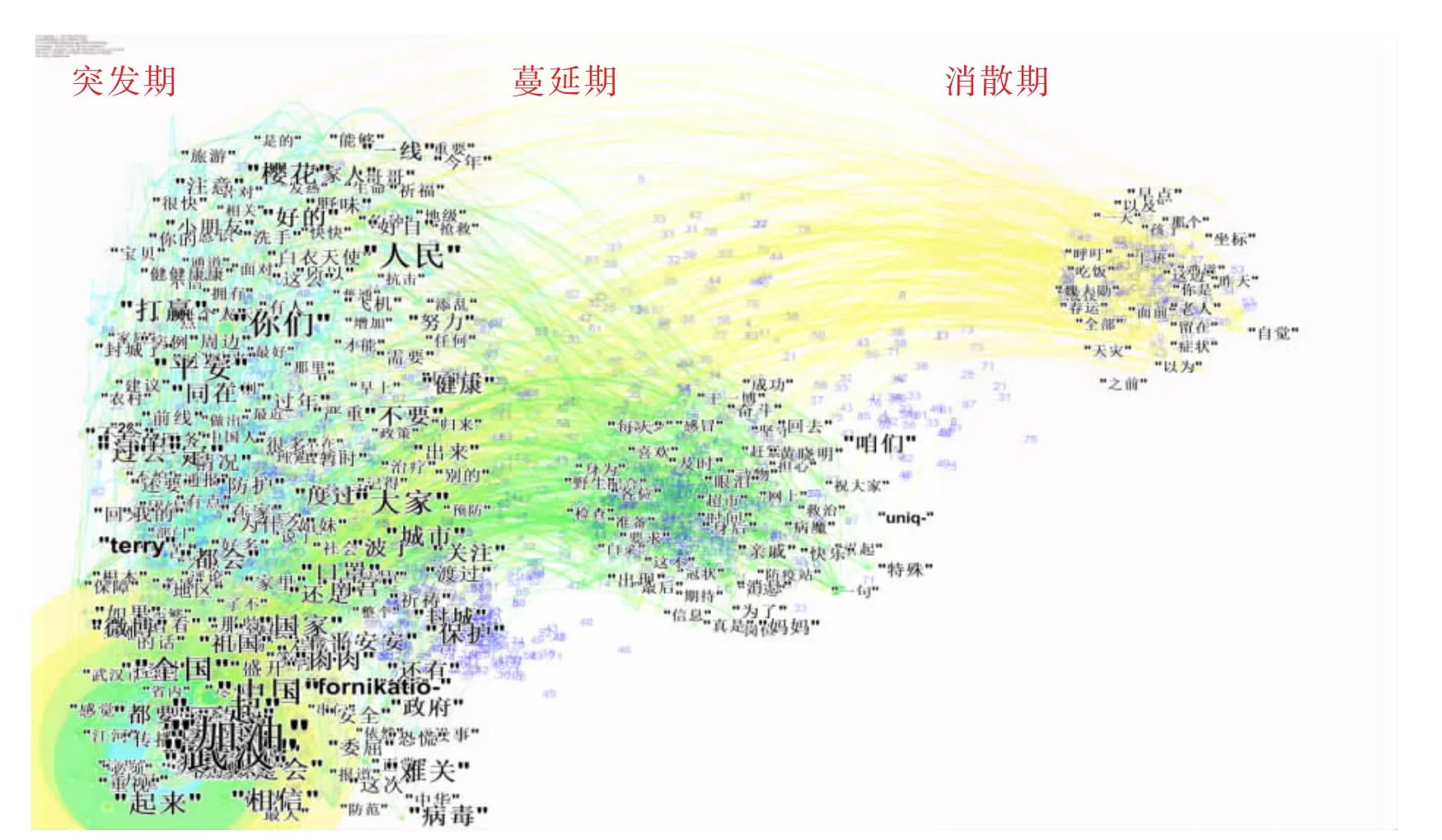
图4 微博舆情用户评论的主题演化图谱Fig.4 Thematic evolution graph of Weibo users'comments
当出现其他爆发力强的衍生舆情时,往往在舆情传播末期则会相应显示。舆情管理者即可从舆情演化分析中提前得到预警,及时对舆情传播进行合理引导和管控。舆情管理者可以通过舆情演化分析方法了解舆情传播中用户评论信息随时间和事件发展趋势的变化过程,对舆情走势预测、网民情绪波动分析、舆情预警都具有重要的实践意义。
5 结语
本文基于主题图谱理论与构建方法,将微博舆情用户评论文本中特征词作为实体,结合文本聚类技术将特征词的关联关系作为实体间关系,以新浪微博热点话题“武汉加油”为例构建微博舆情用户评论文本的主题图谱。使用CiteSpace 进行可视化分析,通过应用不同文本相似度算法、网络优化算法和文本聚类算法分析图谱结构特征。研究发现,在该舆情话题下,使用Jaccard 相似度算法的图谱模块化程度更高,社团结构更显著,但聚类效果不如Cosine 和Dice 相似度算法;TFIDF 产生的聚类标签比LLR 和MI 的准确度更高;PFNETs 在网络优化处理算法上显示出比MSTs 更优越的优化特征;使用Jaccard 算法进行文本相似度计算、MSTs 算法进行网络优化得到图谱中特征词中心度较高。本文基于对比分析结果总结出构建微博舆情用户评论文本主题图谱的最优算法组合能够帮助舆情管理者快速准确识别用户关注内容。通过对微博舆情用户发布文本进行监控,预测舆情演化趋势,防止不良舆情滋生和扩散具有重要作用。在该事件下,部分网民在微博大V 下夸大实情、散布谣言、甚至引发社会动荡。针对这些用户,舆情管理者应对用户发布文本聚类,定位特征词为负向的聚类簇并进行集中管理,找到发布该簇下负面文本的用户进行警告或封号,提高舆情管理效率。
本研究也存在一定局限性,仅以微博平台为例选择“武汉加油”这一话题作为数据源对该话题下的舆情用户评论内容进行文本聚类分析,得到结果在处理相关话题时具有一定优越性,在分析其他话题下的文本时可能产生偏差。在未来研究中,本文将选取不同社交媒体平台针对更广泛的话题对社交网络舆情传播展开更深入的分析。
猜你喜欢
少先队活动(2020年12期)2021-01-14 01:47:40
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
中成药(2017年3期)2017-05-17 06:09:01
中国民政(2016年16期)2016-09-19 02:16:48
领导科学论坛(2016年9期)2016-06-05 14:59:58
中国民政(2016年10期)2016-06-05 09:04:16
中国民政(2016年24期)2016-02-11 03:34:38
中文信息学报(2015年4期)2015-04-21 08:29:12
传媒国际评论(2014年1期)2014-02-27 07:12:12
