
融合卷积神经网络与视觉注意机制的苹果幼果高效检测方法
2021-08-04 05:55宋怀波王云飞
农业工程学报 2021年9期
宋怀波,江 梅,王云飞,宋 磊
(1. 西北农林科技大学机械与电子工程学院,杨凌 712100; 2. 农业农村部农业物联网重点实验室,杨凌 712100; 3. 陕西省农业信息感知与智能服务重点实验室,杨凌 712100)
0 引言
幼果期果实表型数据获取是优良果树品种选育研究的重要基础。复杂环境下的幼果精准检测是获取该阶段果实生长指标数据的前提。幼果期果实因其较为微小且与叶片颜色高度一致,同时,受到不同环境因素的影响,会产生阴影、高光和振荡等干扰,进一步加大了近景色果实目标检测的难度[1-3]。卷积神经网络(Convolutional Neural Network, CNN)虽具有鲁棒性强的优点,但其网络层数多,结构通常较为复杂。在CNN中融合视觉注意机制可有效提高网络特征提取能力而不明显增加复杂度,避免训练发散。
国内外众多学者已将CNN应用于果实检测、分割和估产等研究之中并取得了较好的结果[4-5]。针对自然环境下的绿色柑橘检测问题,熊俊涛等[6]提出了一种基于Faster R-CNN模型的柑橘检测方法。经过模型训练与参数调优,该模型在测试集上的平均精度为85.5%,检测一幅图像平均耗时0.4 s。针对自然环境下未成熟芒果的准确识别问题,薛月菊等[7]提出了一种改进的YOLOv2网络模型,该模型基于密集连接的Tiny-YOLO-dense网络结构,通过利用图像多层特征提高目标识别准确度。结果表明,该方法识别准确率为97.0%,为开放环境中的未成熟果实识别提供了借鉴。Kang等[8]针对苹果园中果实检测问题,提出了基于深度学习的实时检测框架,该框架包含自动标签生成模块和名为“LedNet”的果实检测器。结果表明,基于轻量级主干的LedNet的准确率为85.3%,召回率为82.1%。该模型大小仅为7.4 M,平均运行时间为28 ms,可兼顾速度与精度。Yu等[9]提出了基于Mask R-CNN的草莓检测与采摘定位方法,测试结果表明该方法的平均检测准确率、召回率分别为95.8%和95.4%,采摘点平均误差为±1.2 mm。为了实现开放果园中绿色芒果的精准检测,Koirala等[10]基于YOLOv3和YOLOv2(tiny)网络结构提出了 MangoYOLO-s、MangoYOLO-pt和MangoYOLO-bu模型,经过训练,MangoYOLO-pt在测试集上的平均精确度为98.3%,处理一幅512×512 pixels图像平均耗时8 ms,可有效实现自然场景中绿色芒果目标的实时检测。
为了提高模型检测精度,现有网络的深度、宽度和模块数不断增加[11-13]。但网络结构加深会带来网络训练发散等问题,将CNN与视觉注意机制相结合,可在不明显加深网络结构的前提下加强网络性能[14]。Wang等[15]提出了一种非局部操作方法,并基于非局部块(Non-Local block, NL block)构建了非局部神经网络(Non-Local Neural Network),在视频分类和目标检测任务上性能优越。在Mask R-CNN主干网络ResNet-50中加入非局部块,在MS COCO数据集上平均精度为39.0%。Woo等[16]提出了卷积块注意模型(Convolutional Block Attention Module, CBAM),可针对输入特征从空间与通道两方面自适应调整并提取有意义的深层特征信息。该模块可以插入到现有的网络架构中,Faster R-CNN骨干网络ResNet-50中加入CBAM与未加入该模块相比,在MS COCO数据集上平均精度可提高2.0%。Hu等[17]提出了挤压激发块(Squeeze-and-Excitation block, SE block),可以从通道维度自适应细化和提取特征。在MS COCO数据集上,主干为SE-ResNet-50的Faster R-CNN网络平均精度为46.8%,表明该模块可有效提高网络分类和检测性能。Zhang等[18]提出了分支注意块(Split-Attention block),并基于此模块与ResNet架构构造了ResNeSt。在ImageNet上,ResNeSt-101的top-1精度为82.3%。为了更好地利用通道信息,Wang等[19]提出了高效通道注意模块(Efficient Channel Attention Module, ECAM)。在MS COCO数据集上,以ResNet-101为主干网络并添加ECAM的Faster R-CNN平均精度为40.3%。研究表明,将视觉注意机制融入到网络模型中,能够以较小的额外计算量为代价显著提高网络表现。本研究以视觉注意机制与深度神经网络为重点,解决复杂场景下的果实检测难题。
为实现自然场景下苹果幼果的高效检测,本研究拟提出一种苹果幼果检测网络YOLOv4-SENL。基于YOLOv4模型[20],并在模型中融入SE block和NL block两种视觉注意机制,以在不明显增加网络深度的前提下,避免网络收敛困难的问题,并改善CNN特征提取能力。通过加强骨干网络的特征提取能力和网络瓶颈中融合视觉特征的信息,网络可从相似背景中准确分离近景色苹果幼果,为幼果目标横纵径和着色度等幼果期果实表型数据的高效获取提供参考。
1 材料与方法
1.1 材料
试验图像拍摄于西北农林科技大学园艺学院实验站,采集对象为嘎啦和红富士幼果目标图像,种植方式为矮砧密植,行间距为3 m。试验选用iPhone 8Plus手机进行拍摄。为保证试验结果的可靠性,拍摄角度涵盖东南西北4个方向。由于光线变化会对图像成像造成较大影响从而影响试验结果,因此本研究分别在顺光和逆光条件下,以人距离树干0.4~1.5 m的拍摄距离在全天不同时间段进行图像采集。图1a是拍摄示意图,图1b~d分别是多云、逆光和顺光条件采集的图像。将采集的3 000幅原始图像(4 032×3 024像素)随机裁剪为不同分辨率(150×131像素~4 032×3 024像素)并利用LabelImg进行人工标注。
具体拍摄信息如表1所示,拍摄天气包括晴天、多云和阴天。数据集中包括枝叶遮挡的果实、运动模糊及过度曝光造成的模糊果实、重叠果实、不同光照程度的果实和被钢丝、栅栏遮挡的果实。每幅图像大多包括一个或多个干扰因素,用于验证本研究模型对不同背景的检测鲁棒性。3 000幅图像中包含互不重复的训练集1 920幅,验证集480幅和测试集600幅。
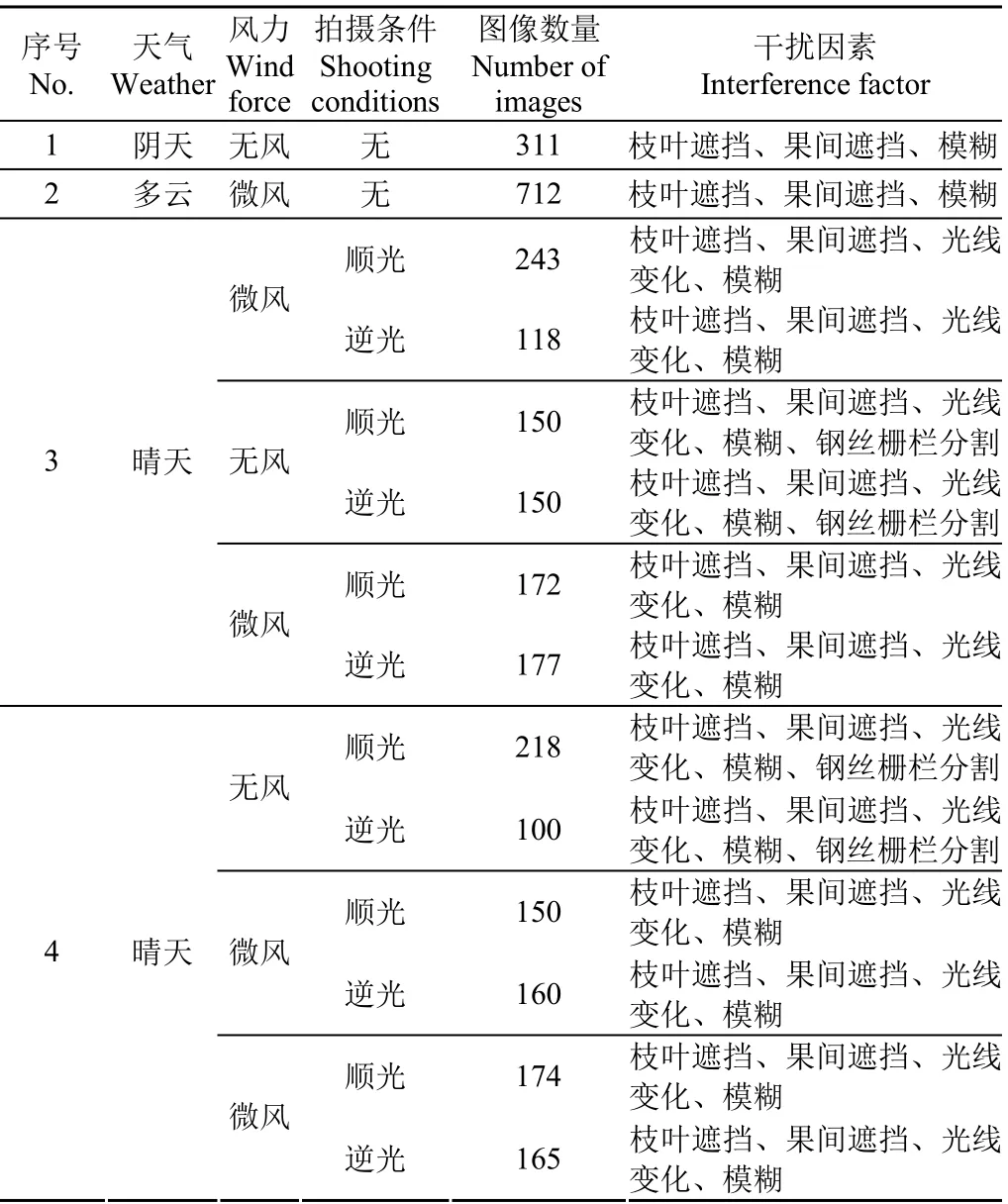
表1 数据集图像详细信息 Table 1 Data set images details
1.2 试验平台
试验过程在Windows 10操作系统下进行,处理器型号为英特尔 Xeon E5-1620,内存32 GB,显卡Nvidia GeForce RTX 2080Ti。深度学习框架采用PyTorch 1.5.1,Python 3.8。
1.3 方法
1.3.1 挤压激发块
CNN关注特定局部区域,通过滤波器提取特征信息。为了建立像素间的深层联系,CNN通常会堆叠多个滤波器提取信息,网络层数较深。SE block则从通道维度作为突破,通过模拟特征的通道维度依赖性提高网络分类、检测的准确度。SE block是一个高效的构造模块,可以插入到现有的主流网络结构中,以较小的参数增加实现网络性能的提升。
本研究提出的YOLOv4-SENL模型在骨干网络结尾处应用了SE block。SE block的网络结构如图2所示。输入特征经过自适应平均池化操作得到通道维度统计值。通道维度统计值输入至两层结构的全连接层,自适应计算和调整各通道的权重,得到通道注意力结果。第一层全连接层的输出单元数量是输入单元数量的1/16,第二层输出单元数量与第一层全连接的输入单元数量一致。两层全连接层的设计既有效降低了计算量,又能较好地实现注意力分配。最后,将通道注意力结果通过Python广播机制与输入特征元素相乘得到输出特征。
1.3.2 非局部块
非局部操作受非局部均值运算启发,将不同坐标的像素、不同时序帧联系起来,捕捉长程依赖。卷积操作和非局部操作相结合,能高效地捕捉局部信息和远程依赖中的上下文信息,以此增强网络对关键视觉信息的表征能力。
与非局部均值算法定义类似,非局部操作的定义如式(1)~(3)所示:
式中x表示输入特征,i为输出位置索引,j为i的所有关联位置索引。输出信号y由归一化参数C(x)、对应关系函数f和线性嵌入函数g计算得到。对应关系函数f形式多样,嵌入高斯形式如式(2)所示,其中。线性嵌入函数g由1×1卷积实现,Wg为可学习权重。
非局部操作由四组1×1卷积块和残差链接组成为更丰富的层次结构NL block,如式(4)所示。
式中zi为输出特征。
本研究提出的方法在YOLOv4模型网络瓶颈的3个聚合路径中分别加入了NL block,以尺寸[bs, 1024, 19, 19]的输入特征为例,NL block的结构流程图如图3所示。在θ、φ和g3条路径中,通道数由1024降至512。在w路径中,通道数由512升至1 024,并与输入特征进行元素相加。通道数改变和最大池化操作都可以减少计算量,使模型轻便。
1.3.3 YOLOv4-SENL模型构建
YOLOv4网络是改进和融合众多优越训练策略的高效网络,包括空间金字塔池化[21]、Mish激活函数[22]、交叉迷你批归一化[20]和改进PAN[23]等。由于YOLOv4网络是深度复杂CNN,网络深度对训练收敛影响较大。因此,本研究以视觉注意机制为出发点,提出了基于YOLOv4-SENL网络的近景色幼果检测方法。
YOLOv4-SENL的结构如图4所示,本研究引入了两种注意力构造块:1)SE block:放置在YOLOv4网络的特征骨干CSPDarknet53后。模拟骨干网络提取的特征通道维度依赖性,自适应调整特征通道维度的权重响应;2)NL block:嵌入在改进PAN结构的3个路径中。深层卷积特征与浅层卷积特征在通道维度进行连结后,通过NL blocks提取融合特征的长程依赖性,获取非局部信息。
SE block和NL block分别对高级视觉特征进行通道维度调整和提取非局部依赖性。改进PAN结构融合不同阶段视觉特征后,经过卷积操作得出3个针对不同尺度目标的输出层。输出结果包含检测目标的类别和位置坐标信息。SE block和NL block组成丰富结构,有效提高了网络的特征捕捉能力。
1.4 评价指标
试验通过准确率P、召回率R、F1值和AP值指标评价模型的检测效果,计算公式如式(5)~(8)所示。P、R、F1和AP值越高,表明网络检测精准度越高。
式中TP表示网络检测出的目标数量,FP表示将背景误识别为目标的数量,FN表示未检出目标的数量。
2 结果与分析
2.1 试验结果
网络训练过程中,加载骨干网络在MS COCO数据集的预训练权重并采用随机梯度下降法更新参数。初始学习率为0.01,训练轮次为350,权重衰减率设为0.000 484,动量因子设为0.937。YOLOv4-SENL与YOLOv4模型以相同方式训练以对比模型效果。图5是YOLOv4和YOLOv4-SENL模型在训练集和验证集上的损失曲线。由损失曲线可以看出,两个模型损失值均可快速收敛。
为了评价YOLOv4-SENL模型的鲁棒性和精度,利用测试集进行测试,并与SSD[24]、Faster R-CNN[25]和YOLOv4模型进行了比较,结果如表2所示。
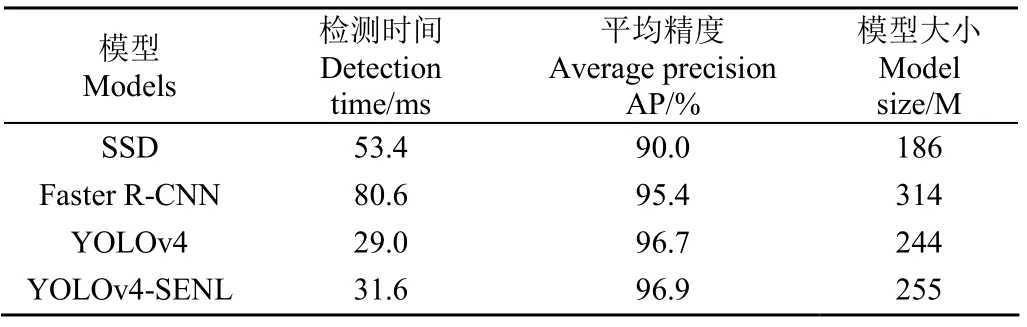
表2 3种模型的测试集检测结果 Table 2 Detection results of three models on test set
经过训练,YOLOv4-SENL模型在测试集上的平均精度比SSD、Faster R-CNN和YOLOv4模型分别提高了6.9个百分点、1.5个百分点和0.2个百分点。YOLOv4-SENL模型检测一幅测试集图像平均耗时31.6 ms。同时,YOLOv4-SENL模型大小比SSD大69 M,比Faster R-CNN小59 M,比YOLOv4模型大11 M,具备向便携式系统移植的基础。
图6是3种模型的检测结果,从图6a中SSD模型检测结果的白色虚线框中可知,由于叶片干扰,SSD模型出现错检情况。图6a中Faster R-CNN模型检测出了白色虚线框中生长期初期幼果。图6a-1中幼果面积占图像面积的比例过小,经过多次卷积操作可能造成所包含的有效特征信息的损失,3个模型均未能将幼果全部检出。图6b中大多数果实为微小果实,SSD和Faster R-CNN模型均未完全检测出图6b-2和图6b-3中的远景果实,存在不同程度的漏检与错检(如白色虚线框中的果实)。YOLOv4-SENL模型能精准检测微小近景色果实,表明其具有更好的鲁棒性。
2.2 消融试验
为了进一步分析两种视觉注意机制的有效性,本研究设计了三组消融试验并根据多个评价指标结果表明视觉注意机制对网络性能提升的影响。
为了探索SE block对网络的影响,仅保留YOLOv4-SENL模型中SE block而去除NL block,命名为YOLOv4-SE。本研究在YOLOv4模型网络瓶颈的3个分支中加入了NL block。为了探索NL block对网络性能的影响,试验仅保留YOLOv4-SENL模型的NL block,命名为YOLOv4-NL。为了分析SE block和NL block组合对网络的影响,将YOLOv4-SENL中的SE block替换为NL block,3个NL block替换为SE block,模型命名为YOLOv4-NLSE。消融试验测试结果如表3所示,5个模型在验证集上的指标结果表明,与YOLOv4模型相比,两种视觉注意机制的融合,略微增大了模型大小和检测时间,但仍能实现实时检测。改进后的模型以较小的额外计算量为代价,使测试指标得到不同程度提升,精度值提升较大。SE block和NL block两种视觉注意机制对提高模型性能起到不同程度作用,SE block的影响更明显。
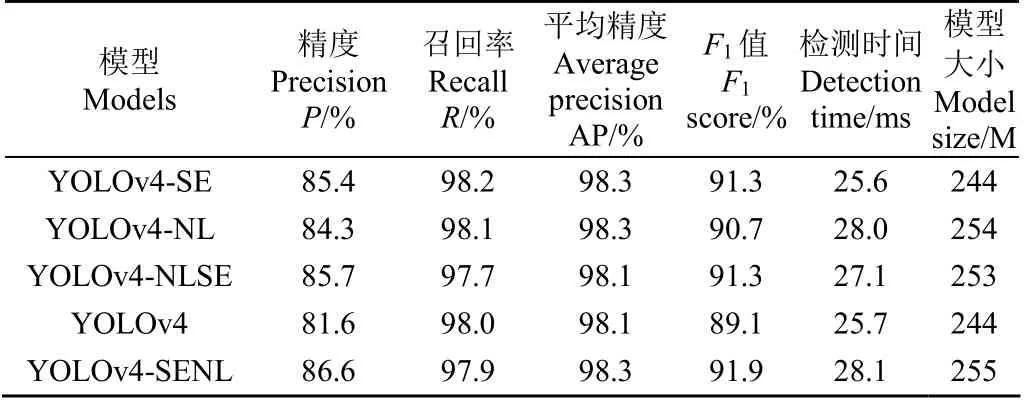
表3 5种模型的验证集测试结果 Table 3 Test results of five models on validation set
图7展示了设置相同参数训练得到的5种模型在验证集上的精度结果。从5个模型训练过程的精度曲线可以看出,融合视觉注意模块的模型精度均比YOLOv4模型高。其中,YOLOv4-SENL模型的精度值整体提升最快。
2.2.1 仅保留SE block对网络的影响
与YOLOv4模型比较,YOLOv4-SE在验证集上的P、R、AP和F1值分别提高3.8个百分点、0.2个百分点、0.2个百分点和2.2个百分点。YOLOv4-SENL模型的P、R、AP和F1值比YOLOv4模型分别提高5.0个百分点、降低0.1个百分点、提高0.2个百分点和提高2.8个百分点,表明SE block可对骨干网络提取的特征进行通道信息整合,有助于提高网络性能。由图7可知,在前200迭代轮次中,YOLOv4-SE的精度值波动较小,且YOLOv4-SE的精度值比YOLOv4模型整体提高,表明SE block的添加提高了模型的特征表征能力。
2.2.2 仅保留NL block对网络的影响
与YOLOv4模型相比,YOLOv4-NL模型的P、R、AP和F1值分别提高了2.7个百分点、0.1个百分点、0.2个百分点和1.6个百分点,表明NL block可明显增加网络精度和F1值。图7中,YOLOv4和YOLOv4-NL模型的精度值在200迭代轮次之内出现多次浮动。150迭代轮次后,YOLOv4-NL精度值整体高于YOLOv4模型,表明NL block提取高级融合特征的非局部信息,提高了网络目标检测任务的准确性。
2.2.3 互换SE block和NL block对网络的影响
与YOLOv4模型相比,YOLOv4-NLSE模型的P、R、AP和F1值分别提高4.1个百分点、降低0.3个百分点、保持不变、提高2.2个百分点,表明YOLOv4-SENL模型的指标提升程度更高,检测效果更好。从图7可以看出,YOLOv4-SENL模型的精度值整体上升较快,且最终精度值比YOLOv4-NLSE模型略高。这表明SE block和NL block在不同层均发挥了作用,模型设计合理。
由消融试验可知,SE block和NL block都有助于提升网络性能,SE block的影响更加明显。两种视觉注意机制模块SE block与NL block均使得该模型具备了更好的目标检测效果,表明YOLOv4-SENL模型结构设计合理,检测结果更精准和高效。
3 结 论
1)幼果目标检测技术是自动获取幼果期果实表型微变化信息的基础。针对近景色幼果检测问题,本研究提出了一种利用视觉注意机制改进YOLOv4网络的YOLOv4-SENL模型。600幅测试集图像的测试结果表明,本研究提出的YOLOv4-SENL模型的平均精度为96.9%,与SSD、Faster R-CNN和YOLOv4模型相比,分别提高了6.9个百分点、1.5个百分点和0.2个百分点,表明视觉注意机制模块的融入有助于提升自然环境下幼果的检测精度。
2)为了进一步探究YOLOv4-SENL模型的有效性,本研究设计了消融试验。消融试验的验证集结果表明,添加SE block和NL block使模型的大小和检测时间有所增加,但有助于提升网络检测的准确性且不影响实时检测,YOLOv4-SENL模型结构设计合理高效。
3)针对微小果实,本研究提出的YOLOv4-SENL模型检测效果仍有提升空间。未来将进行模型结构简化和改进工作,以进一步提高模型的抗干扰能力和泛化能力。下一步将研究含标定的幼果表型测定算法,结合幼果目标检测技术实现长效、高频次、精确获取果实生长期数据。
猜你喜欢
计算机研究与发展(2022年1期)2022-01-19
中国果业信息(2021年7期)2021-12-01
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
今日农业(2021年10期)2021-07-28
计算机应用(2020年12期)2020-12-31
果农之友(2020年2期)2020-04-07
电子制作(2019年11期)2019-07-04
安徽农业科学(2018年2期)2018-05-14
北京航空航天大学学报(2018年1期)2018-04-20
