
农业车辆双目视觉障碍物感知系统设计与试验
2021-08-04 05:48魏建胜潘树国田光兆孙迎春
农业工程学报 2021年9期
魏建胜,潘树国※,田光兆,高 旺,孙迎春
(1. 东南大学仪器科学与工程学院,南京 210096;2. 南京农业大学工学院,南京 210031)
0 引言
由于农业环境的复杂多样性,农业机械为实现其自主导航[1-5]需要可靠的障碍物感知系统。障碍物感知系统主要包括障碍物检测[6-7]和深度估计[8-9]2部分。传统的障碍物检测是基于人为设计的浅层目标特征[10-12],如SIFT特征、HOG特征、局部二值特征等。由于农业环境结构复杂,光照强度不均匀等,此类特征的检测效果不够稳定。随着人工智能的发展,农业机械的自主导航逐渐应用深度卷积神经网络[13-16](Convolutional Neural Network,CNN)来完成检测任务。相比于原有基于人为设计特征的检测方式,深度卷积神经网络对环境特征的检测更加丰富和多层次,且能够从大规模数据集中不断学习当前任务的特征表达,从而获得更优的检测效果。在障碍物的深度估计中,普遍采用激光雷达[17-18]、深度相机[19-20]和双目相机[21-22]等作为测距传感器。激光雷达测距范围广、精度高,但二维激光雷达无法检测扫描线以外的障碍物,不能适应农田等颠簸路面的情况,而三维激光雷达造价昂贵,严重制约了其在农业障碍物检测中的应用[23];深度相机能够获得图像中每个像素的深度信息,但测量结果受外界环境干扰较大,难以在室外环境中应用;双目相机能够独立完成对目标的深度估计,但窄基线的双目相机测距范围有限,需不断提高基线的宽度以适应大规模的场景。
为适应农业环境的复杂多样性,选用双目相机作为系统的视觉感知传感器,并采用深度卷积神经网络进行障碍物的检测。由于深度卷积神经网络对图像处理的计算量巨大,需要图形处理器(Graphics Processing Unit,GPU)来加速处理,仅中央处理器(Central Processing Unit,CPU)配置的工控机已不能满足计算要求,而工作站等高计算量设备体积和质量过大,严重占用机械空间资源,因而本文选用NVIDIA Jetson TX2[24-27]型嵌入式人工智能(Intelligent Artificial,AI)计算机作为深度卷积神经网络的计算载体。
在传统的障碍物感知中,通常将障碍物检测和深度估计作为2个独立的任务进行处理,2个任务之间信息不能共享,造成了计算资源的浪费。基于此,本文提出一种基于改进YOLOv3的深度估计方法,将传统障碍物感知任务中的障碍物检测和深度估计2个任务进行融合,利用障碍物检测中的部分信息进行深度估计,实现系统对障碍物检测和深度估计端到端处理。
1 视觉感知系统设计
1.1 硬件组成
系统选用东方红SG250型拖拉机作为移动载体,Jetson TX2作为运算核心,搭载本文所设计的障碍物视觉感知系统。系统硬件由拖拉机、导航控制模块和视觉感知模块组成。
视觉传感器选用MYNTAI公司S1030-120型双目相机,基线120 mm,焦距2.1 mm,分辨率752×480像素。主控制器Jetson Tx2的GPU配有256个NVIDIA CUDA核心,其CPU为双核Denver 2 64位CPU和四核ARM A57 Complex的组合。视觉感知模块如图1所示。
对拖拉机进行并联电控液压油路改造,控制器选用STM32,与模拟量输出模块、电液比例控制器和比例换向阀等共同构成系统的导航控制模块,如图2所示。
1.2 技术流程
障碍物视觉感知系统的运行环境为Ubuntu16.04 LTS,基于ROS(Robot Operating System)完成信息的传递和通信,实现拖拉机对其导航控制路径上障碍物的准确识别、定位和深度估计,并将结果传给决策中心,系统的技术流程如图3所示。
拖拉机点火并切换至电控转向状态,然后视觉感知模块开启进行左右相机的抓图,接着将左右图像分别输入至改进的障碍物检测模型进行检测。检测到障碍物类别、定位信息后进行目标匹配和视差计算,并估计出深度值,若其超过预警深度值则会触发电控转向。
2 基于改进YOLOv3的深度估计
为了准确估计障碍物到拖拉机的实时深度,本文提出一种基于改进YOLOv3的深度估计方法,将障碍物检测和深度估计进行融合,一次性完成对障碍物类别、定位和深度信息的全部输出。首先将双目相机抓取的左右图像分别输入改进的YOLOv3模型中进行障碍物检测,输出农业环境下障碍物的类别和定位信息并进行目标匹配,得到障碍物在左右图像中的对应关系。最后根据障碍物的对应关系计算像素视差,并输入至双目成像模型进行深度估计,算法流程如图4所示。
2.1 改进YOLOv3模型
本文选用YOLOv3模型[28-30]作为深度估计的前端框架,并针对双目成像模型和农业环境目标的特殊性进行锚框聚类和边界框损失函数的改进。
2.1.1 YOLOv3
YOLOv3是目前为止最先进的目标检测算法之一,其在YOLOv2的基础之上进一步融合多尺度检测和多尺度训练等改进措施,使用更深的darkNet53作为特征提取网络,并加入残差模块解决深层网络梯度问题。图5是YOLOv3的网络结构,它从3个不同的尺度(32×32、16×16和8×8)提取特征至YOLO层进行检测。
2.1.2 数据集聚类
由于没有公开的农业障碍物数据集,本文在农业环境中设置人、农具和树桩等作为障碍物,从2020年开始通过网络爬虫和相机抓图自建数据集开展研究工作,并利用LabelImg进行类别和检测框标注,包括训练集2 400张和测试集270张。由于农业环境中的障碍物形态多变,原COCO数据集中的先验框尺寸难以满足该数据集。为获得合适的先验框,本文采用K-means算法对农业障碍物数据集进行聚类分析,并针对特征金字塔在52×52、26×26和13×13特征图上分别应用先验框(16,28)、(25,42)、(39,43),(69,75)、(99,80)、(88,113),(92,123)、(155,149)、(199,236)。
2.1.3 lossD损失函数
原始YOLOv3模型的损失函数中,针对检测框x、y、w和h坐标的误差权值是相同的,但在双目成像模型中深度估计的精度取决于视差,即左右图像目标检测框质心的u轴坐标差,使得YOLOv3模型对检测框的横向偏差特别敏感。因此,在深度估计的边界框损失函数lossD中独立出x坐标的误差权值项并提高,同时降低其他3项的权值。
针对大小目标对目标检测框精度的影响不一致,YOLOv3原文采用反向赋权的方式来控制精度,即目标越大x、y、w和h坐标的误差权值越小。针对机械在农业环境下自主导航的需求,要求远处目标深度估计误差偏大而近处误差偏小,在损失函数lossD中对x误差项正向赋值,其余项固定赋值。改进后的损失函数如式(1)所示。
式中K为输入层网格数;M为单个网格预测的锚框数;为目标的判断标志;w、h、(x,y)和分别为目标检测框宽、高、质心坐标的真值和预测值,像素;n目标类别数;r为当前类别索引;truthclass、truthconf和predictclassr、predictconf分别为类别和置信度的真值和预测值;(·)?1:0表示括号内判断条件为真则为1,反之为0。
2.2 深度估计过程
2.2.1 目标匹配
相机抓取的图像中有些物体是拖拉机的作业目标,如:果实、庄稼和果蔬等;另一些物体是障碍物,如:行人、农具、树桩等。目标匹配是改进模型检测出选定的障碍物后,进一步在左右图像中确定同一障碍物的对应关系,具体过程如下:1)将左右相机图像PL、PR输入改进YOLOv3模型,输出各自的目标检测框BBOXL、BBOXR及其类别CLASSL、CLASSR;2)计算目标检测框的像素面积SL、SR和目标检测框质心的像素坐标CL、CR;3)得到目标检测框的像素面积之差SE和目标检测框质心的v轴坐标之差VE;4)判断CLASSL、CLASSR是否相同,且SE、VE是否小于阈值A、B;若同时满足,则匹配成功,反之匹配失败。
2.2.2 像素视差计算
若左右图像中2个目标检测框匹配成功,即表示其为某一障碍物在左右相机的成像位置,反之则继续抓图进行目标匹配。如图6所示,目标检测框BBOXL、BBOXR为某一障碍物在左右相机的像素平面成像位置,选用目标检测框的质心代表障碍物,左右质心的坐标分别为(uL,vL)、(uR,vR),则障碍物在左右相机的像素视差D为
式中uL、uR分别为像素平面上左右质心的u轴坐标。
2.2.3 深度估计
立体视觉中,记OL、OR为左右相机光圈中心;XL、XR为成像平面的坐标;f为焦距,m;z为深度,m;b为左右相机的基线,m;空间点P在左右相机中各成一像,记PL、PR,左右图像横坐标之差(XL-XR)为视差d,m;根据三角相似关系有:
目标边界框质心在左右视图中的像素坐标uL、uR分别为
式中α为物理成像平面坐标系的横向缩放系数,像素/m;cx为原点横向平移量,像素。
进一步得视差d为
将式(5)代入式(3)得深度z为
3 视觉感知系统试验
3.1 模型训练与测试试验
针对训练集,本文选用DELL T7920型图形工作站(12G内存TITAN V型显卡)对YOLOv3模型和改进YOLOv3模型分别进行相同的迭代训练,2种模型的训练损失函数如图7所示。
表1是YOLOv3模型和改进YOLOv3模型结果。由表1可知,相较于YOLOv3模型,改进YOLOv3模型的准确率和召回率分别下降0.5%和0.4%。原因是本文对模型的改进侧重于目标检测框x轴上的精度,而适当降低对y轴和宽高的精度,提高了目标的深度估计精度。同时,模型改进前后在深度学习工作站和嵌入式终端TX2上的速度测试结果基本一致。
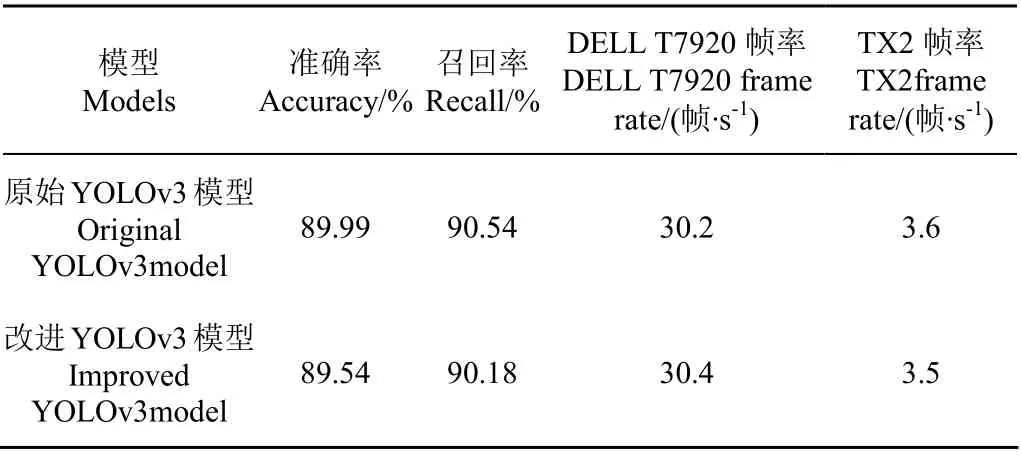
表1 训练集测试结果 Table 1 Test results on training set
3.2 深度估计试验
3.2.1 参数标定与评价指标
试验在南京农业大学农田试验场进行,分别将Hog+SVM模型、YOLOv3模型和改进YOLOv3模型部署至嵌入式终端并对点火驻车状态下拖拉机前方1.6~3.4 m距离段上的静止障碍物进行深度估计。试验过程中,保持双目相机与障碍物的图像质心在同一水平面上,且双目相机左右光心的中点与图像质心的连线垂直于相机基线方向。对障碍物进行多组深度估计试验,获得障碍物的深度估计值,并将UT393A型测距仪的测量值(精度±1.5 mm)作为距离真值进行误差分析。试验中采用误差均值em和误差比均值erm作为深度估计精度的指标,其定义分别如下:
式(7)~(8)中zi为深度估计值,n为测量次数,本文试验取n=3。
利用MYNTAI相机自带的软件开发工具包(Software Development Kit,SDK)对系统视觉感知模块中的双目相机参数进行标定,并获得去畸变的双目图像,结果如表2所示。

表2 双目相机标定结果 Table 2 Calibration result of binocular camera
3.2.2 深度估计
图8是不同障碍物(人、农具和树桩)在不同1.6~3.4 m距离段上的检测结果,其中像素面积差SE的阈值A和v轴坐标差VE的阈值B分别设为经验值60和4。图8a障碍物目标为人,目标深度真值为2.8 m,检测框质心视差为15.47像素;图8b障碍物目标为农具,目标深度真值为2.6 m,检测框质心视差为16.66像素;图8c障碍物目标类别为树桩,目标深度真值为2.9 m,检测框质心视差为14.94像素。由图8可知,YOLOv3模型和改进YOLOv3模型的检测精度高且鲁棒性强,而Hog+SVM模型的检测精度和鲁棒性均较差。
图9为不同障碍物(人、农具和树桩)在其深度估计范围内1.6~3.4 m距离段内的深度误差结果。由图9可知,3种障碍物应用改进YOLOv3模型的深度估计误差均值em和误差比均值erm相对于YOLOv3模型和Hog+SVM模型均有降低。改进YOLOv3模型对行人的误差均值em和误差比均值erm相较于YOLOv3模型分别降低38.92%、37.23%,比Hog+SVM模型分别降低53.44%、53.14%;改进YOLOv3模型对农具的误差均值em和误差比均值erm相较于YOLOv3模型分别降低26.47%、26.12%,比Hog+SVM模型分别降低41.9%、41.73%;改进YOLOv3模型对树桩的误差均值em和误差比均值erm相较于YOLOv3模型分别降低25.69%、25.65%,比Hog+SVM模型分别降低43.14%、43.01%;随着障碍物目标与相机之间距离增大,3种模型的深度估计误差均值em和误差比均值erm均无明显变化规律。
3.3 动态避障试验
试验于2020年5月在南京农业大学农机试验场进行,对动态场景下视觉感知系统的深度估计精度和避障效果进行测试。由于行驶中的拖拉机与障碍物行人之间的深度真值无法用测距仪实时测得,试验中在拖拉机车尾部署一个GPS接收机,同时行人手持一个GPS接收机,并用2个GPS定位坐标之间的距离除去拖拉机GPS接收机至车头的距离(289 cm)作为实时的深度真值,自主导航试验装置如图10所示。
由于计算机处理有效数字长度有限,将坐标原点从117°E 与赤道的交点向东平移159 000 m,向北平移3 557 000 m,并以平移后的点为参考原点。试验中拖拉机按导航基线AB由A向B直线行驶,起点A坐标(227.198 6,176.401 6),平均速度0.31 m/s,障碍物行人沿导航基线由B向A行走,起点B坐标(227.173 9,182.225 8),平均速度0.18 m/s。为保证行人安全,将深度预警值设为2.4 m,相机抓图的频率设置为1 Hz,电控液压转向模块转角为18°。本次试验从拖拉机点火启动开始,至拖拉机转向避障后障碍物离开相机视角结束,共耗时9 s。拖拉机启动时深度值为5.22 m,之后每秒输出1次深度估计值,在行驶6 s后深度估计结果为2.14 m,小于试验设置的预警值并触发电控液压转向模块以固定右转角18°进行安全避障,执行避障动作3 s后障碍物离开相机视角同时系统停止深度估计,试验结果如图11所示。
表3为动态试验中深度估计精度的误差统计,深度真值用GPS坐标间的欧氏距离除去车载GPS到相机的距离289 cm进行表示,深度估计值为本文基于改进YOLOv3的深度估计结果。
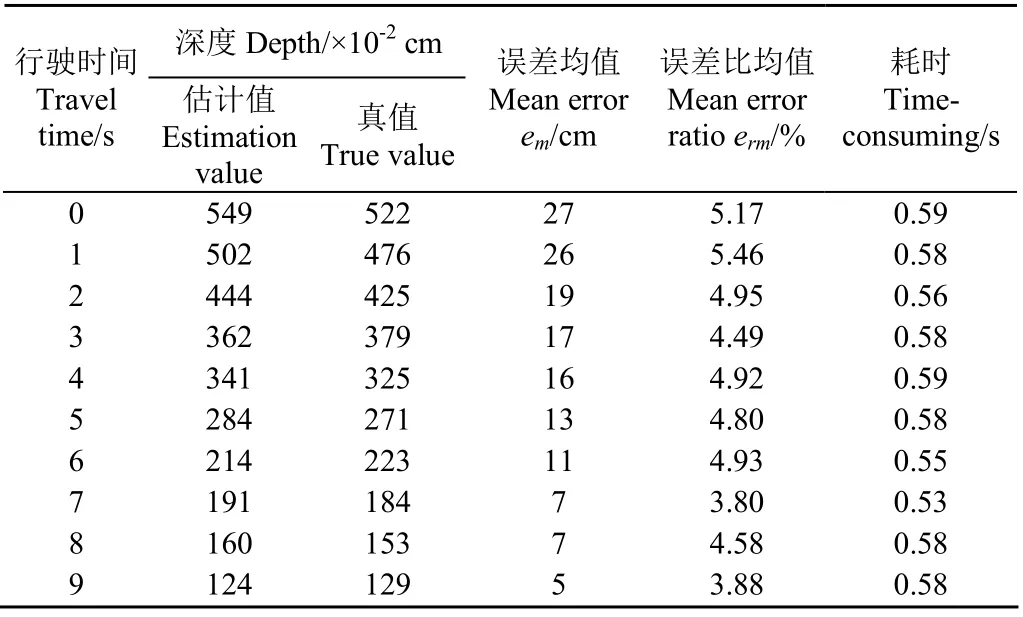
表3 动态场景深度估计 Table 3 Depth estimation in dynamic scene
由表3可知,随着自主导航时间的增加,拖拉机与障碍物之间的深度真值和深度估计值不断减小且变化趋势一致;同时,误差均值em从初始的27 cm不断减少至5 cm,但平均误差比均值erm为4.66%,无明显变化规律,维持在6%以下,比静态深度估计的误差比均值降低7.19%,算法平均耗时为0.573 s。
4 结 论
1)本文设计了一套基于农业机械的障碍物视觉感知系统,系统将嵌入式AI计算机作为控制核心,极大节省了机械的空间资源,能够对障碍物的类别和深度信息进行准确检测。
2)本文提出一种基于改进YOLOv3模型的深度估计方法,通过增大模型对图像x轴的敏感程度来提高深度估计精度,相对于YOLOv3模型和传统检测方法Hog+SVM其深度估计的误差均值、误差比均值均有较大改善。动态避障试验结果表明,随着行驶过程的进行,误差均值从初始的27 cm不断减少至5 cm,误差比均值无明显变化规律,但始终维持在6%以下,比静态深度估计的误差比均值降低7.19%,成功避障。
由于YOLOv3模型的网络结构深参数量大,在嵌入式终端的实时推理速度有限。后续研究中将选用更加轻量级的YOLOv3-tiny模型和运算力更高的终端xavier,进行动态障碍物的深度估计试验,不断提高平台的实时推理帧率。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
北京航空航天大学学报(2021年4期)2021-11-24
动漫界·幼教365(中班)(2020年3期)2020-04-20
创新作文(1-2年级)(2019年4期)2019-10-15
中学生数理化·教与学(2019年5期)2019-06-06
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
好孩子画报(2019年10期)2019-01-10
数学大世界(2018年35期)2018-02-22
汽车实用技术(2017年20期)2017-10-24
