
热连轧机板厚预测综述
2021-08-03 08:26孙丽杰黎建华朱俊飞
台州学院学报 2021年3期
孙丽杰,李 静,黎建华,朱俊飞
(1.台州学院 电子与信息工程学院,浙江 临海 317000;2.辽宁大学 信息学院,辽宁 沈阳 110036;3.国网浙江玉环市供电有限公司,浙江 玉环 317600)
0 引言
厚度是板带钢最主要的尺寸质量指标之一[1],热连轧机厚度精度分为两种:一批同规格带钢的厚度异板差和每一条带钢厚度同板差,本文研究内容为后者,以下简称板厚精度。板厚精度直接影响产品的使用性能,并且对节约金属成本产生巨大作用。带钢连轧机生产效率高、轧制过程连续、易于实现机械化和自动化,对热连轧生产过程进行精确的板厚控制可以大幅度提高产量、改善产品质量,具有显著经济效益。
带钢热连轧机由粗轧和精轧两个轧区构成,由如图1所示的唐山国丰620 mm热连轧生产线轧线布置[2]可知钢板轧制过程。精轧机是热连轧机生产过程中的重要组成部分,是影响出口产品质量的主要工序,为了获得优良产品,在精轧机组大量采用新设备、新技术、新工艺以及高精度的检测仪表。因此,本文以热连轧精轧机组为研究对象,分析带钢在精轧机组部分的厚度预测问题。

图1 国丰620 mm热连轧生产线轧线布置
带钢轧制过程中,各个机架出口处的板厚是十分重要的参数[3],但出于成本等因素的考虑,并非每个机架都配备测厚仪,中间机架通常未安装测厚仪,这时需要对该机架的出口板厚进行预测,通过分析板厚参数来达到提高厚度自动控制精度的目的;在轧机入口和出口通常安装测厚仪,但测厚仪的安置点与轧制点存在一定距离,导致实测的板厚波动与液压压下位置的控制量之间存在一定的时间延迟,这种时滞的存在势必影响板厚预控和监控控制的作用效果,尤其是现在的工业产品对板厚精度的要求越来越高,时滞问题的解决对控制薄而宽的钢板厚度精度效果更加显著。因此,利用预测模型来预估板厚未来值对于缓解板厚时滞带来的影响具有重要的意义。
1 板厚预测方法分类
国内外学者在板厚精度控制方面进行了大量的研究工作,从20世纪60年代兴起的传统机理建模预测到20世纪90年代人工智能在轧制过程中的应用,再到现在盛行的预测控制策略,带钢参数预测行为因其复杂、波动、非线性的本质已经成为一个具有挑战性的任务[4]。本文以新的视角,根据应用背景和方法性质将现有板厚预测方法分为“一劳永逸”的软测量和动态滚动的趋势预测两类方法,其分类结构如图2所示。

图2 板厚预测方法分类
1.1 “一劳永逸”的软测量
软测量建模本质上是构建一种映射关系,不考虑时间划分问题,具有低成本、响应速度快和易于实现等优点,属于静态预测。一旦建立了变量之间的映射关系,只需提供对应时刻的轧制参数即可获得板厚预测值,这也是称这类方法“一劳永逸”的原因。文中通过分析现有软测量预测方法,以预测模型的使用数量作为划分依据,将其分为单一建模和混合预测两类,其中,单一建模方法又细分为弹跳方程和参数映射两类。
1.1.1 单一建模
(1)弹跳方程
轧机弹跳现象如图3所示,在热连轧机生产过程中,轧件在轧制力的作用下会发生塑性变形,与此同时,轧辊承受着一个同轧制力大小相等但方向相反的作用力,从而使得轧机的机座各零件同样产生塑性变形,如图4所示,经过塑性变形的不断累积,辊缝会逐渐变大,这种现象称为弹跳。
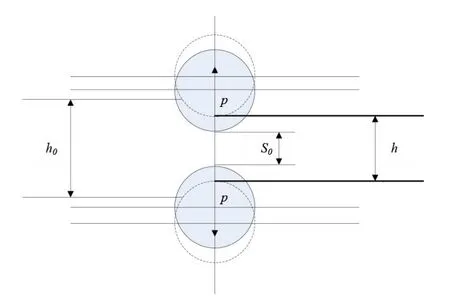
图3 轧机弹跳现象
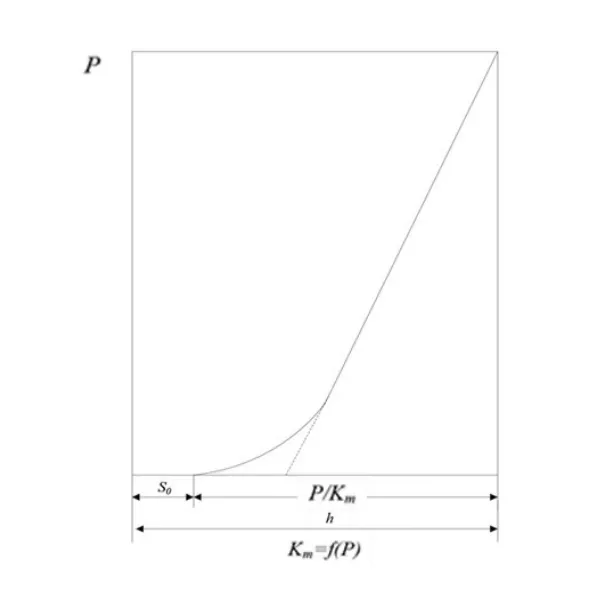
图4 弹跳变形特征
弹跳方程是板厚控制的理论基础,是由B.R.Sims等人在1950年提出的,公式(1)描述了轧制过程中的弹跳现象[5]。

其中,h指钢板出口厚度,Sp指有载辊缝,S0指空载辊缝,P指轧制力,Km指轧机刚度系数。
通过公式(1)进行板厚预测的方法称为机理建模方法,运用这种方式进行板厚预测时需事先明确S0、Km和P三个参数;此外由于出口板厚受到轧制力的影响巨大,所有影响轧制力变化的因素最终都将对出口板厚造成影响,从而导致应用弹跳方程预测板厚不能取得较好的预测效果。
(2)参数映射
轧制过程会受到众多因素的影响,并且现场环境复杂,通过机理建模进行板厚预测误差较大,由此,基于数据驱动的板厚预测方法应运而生。应用参数映射方法进行板厚预测主要包括六个环节,依次是采集数据、去噪处理(可选)、筛选参数、确定预测模型、训练建模和测试建模。
从轧制现场采集的数据带有大量噪声,需要进行去噪处理,目前常用并且有效的去噪方法是傅里叶变换和小波变换,此外,小波包、S变换等在工程数据去噪处理中也取得了丰硕的研究成果[6]。轧制数据具有大数据的特征,数量大、维度高,在预测建模前需以较强的适应性和泛化能力为目标,筛选一些更加完整、全面和覆盖轧制情况最多的数据。参数筛选能够减少预测模型的输入维度,改善预测模型的性能,常用的方法有主元成分分析、关联度分析(如灰色关联度、距离相关性)、随机森林和粗糙集等。
目前,主流的参数映射方法是基于机器学习的板厚预测,如人工神经网络、支持向量机等[7]。人工神经网络板厚预测(如图5所示)是将通过相关性分析得到的轧制力、辊缝和电机功率三个敏感轧制参数作为输入层,以两层隐含层为例,输出层为板厚,展示了应用人工神经网络进行板厚预测的实现策略。

图5 人工神经网络板厚预测结构图
1.1.2 混合预测
高精确和稳定的板厚预测是研究追求的最终目标,在大多数情况下,单一建模方法的预测性能并不能满足板厚控制的要求。混合预测是将多个单一模型加权融合进行板厚预测,主要包括两个步骤:(1)选择若干可信预测模型并取得多个板厚预测值;(2)利用加权算法对多个板厚预测值进行加权融合求得最终板厚预测值。混合预测策略的关键是寻求有效的加权算法获取单一预测模型的加权权重,以获取更加精确的板厚预测结果,其预测流程如图6所示。目前常用的加权手段有平均加权、寻优算法确定、证据理论融合等[8]。
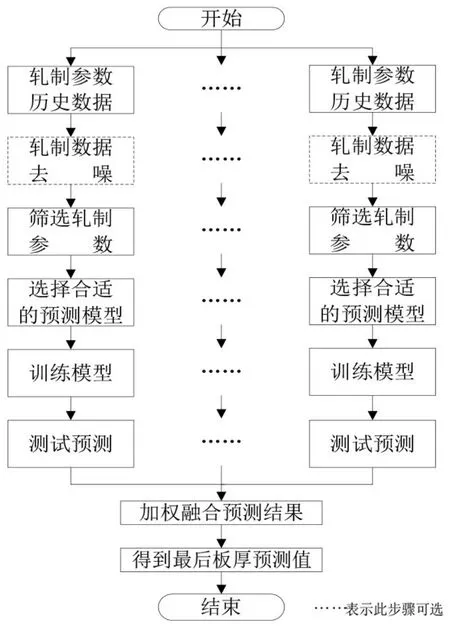
图6 混合预测模型流程图
显然,软测量是一种离线建模方式,是建立虚拟测厚仪的理论依据。这种建模方法需要考虑大量轧制过程因素,而且建立和理解各种因素之间的关系比较困难。
1.2 动态滚动的趋势预测
尽管基于软测量的间接测厚方法考虑了轧制过程中的各种补偿因素,但其预测精度总是低于应用射线测厚仪直接测量的板厚精度。因此,在轧制过程中,仍需以基于射线测厚仪的监控厚度控制系统来保证热连轧机的出口板厚精度。这时,必须解决因测厚仪安置点和测试点之间的距离产生的时滞给板厚控制带来的超调和震荡等问题。
目前,轧制生产实践中主要通过以精确数学模型为基础的Smith预估器来解决时滞问题[9],但建立精确数学模型难度较大,由此基于数据驱动的动态滚动的多步板厚预测模型便应运而生。对板厚时间序列数据建立预测模型,解决了板厚控制系统对预估模型的依赖问题。文中通过总结现有基于数据驱动的板厚预测方法,依据使用的预测模型数量将其分为单一建模和混杂预测方法两类,并且将单一建模细化分为拟合预测和插值预测两类方法,混杂预测细化分为残差混杂和多频预测两类方法。
1.2.1 单一建模
单一建模,即只利用板厚时间序列建模,应用板厚历史数据,根据数据建模方式不同,利用拟合或插值等手段建立模型。
(1)拟合预测
拟合预测方法是通过建立模型去逼近实际时间序列数据,在建立拟合模型时,通常要指定一个具有明确意义的时间原点和时间单位,主要包括自回归、线形回归、同态线形回归拟合、多项式曲线拟合等方法[10],本文以应用最广泛的灰色模型和ARMA族模型为例展开介绍。
灰色预测方法是通过少量且不完全的数据信息,构建灰色微分模型来实现事物发展规律模糊性的长期描述。这种方法需要的样本数据少,对波动性较小的短期预测具有较好的预测效果,但其对非线性信息处理能力弱、缺乏自学习和误差校正反馈能力,通常需要与其他方法综合使用,扬长避短。
ARMA族模型,即自回归模型(AR)、自回归滑动平均模型(ARMA)和差分自回归移动平均模(ARIMA)的总称,这类模型是把时间序列数据看作随机序列,并用数学模型去近似描述这个随机序列。这类方法首先需要应用自相关和偏自相关函数来检验轧制数据是否符合应用ARMA族模型,并且还需验证其是否为非平稳时间序列。如果是,需要将非平稳时间序列转化为平稳时间序列,这一操作需要重复进行,直到其为平稳时间序列为止,在得到预测结果后还需要反差分才可获得板厚最终预测结果。
拟合预测方法主要应用线性拟合,对于高度复杂和非线性的系统其应用具有局限性,目前解决的方案是将其与其他非线性方法结合应用。
(2)插值预测
插值预测方法适合具有周期性的预测行为,如线性插值、牛顿插值、拉格朗日插值、样条插值和分形插值等。根据预测性质的不同,本文将插值预测方法细分为区间内插值和外推插值两类方法。
①区间内插值预测。对于同一规格的钢板,通过一块钢板的板厚数据插值构建轧制运动行为,即可获取下一块钢板同等时刻的板厚预测值。因为插值通常都是线性插值,并且每种插值都存在不可调和的缺点,因此,对于具有高度复杂性和非线性的板厚控制系统,不能期望单独使用这一种插值方法得到较好的预测性能。
②外推插值预测。这类预测方法具有动态性、实时跟踪特性。近年来兴起的分形外推插值算法是把分形的自相似和标度不变特性在内区间进行延拓,即可构造具有外推功能的分形插值算法。该算法具有较高预测性能,在预测精度、计算效率和收敛性方面都表现了良好特性。
1.2.2 混杂预测
混杂预测方法是将实际时间序列数据分解,并对分解部分逐一预测,将预测结果叠加求和作为最终目标参数预测值。本文根据应用分解方法的种类不同和分解后呈现的内容不同,将混杂预测方法细分为残差混杂预测和多频混杂预测两类方法。
(1)残差混杂预测
追根溯源,残差混杂预测方法的预测原理来源于席裕庚的误差补偿模型,这是预测控制领域最常用的混杂预测策略。模型预测能够反映预测对象能够确定的动态因果关系,而误差补偿模型可以描述不确定的并且在预测模型中没有被包含的部分,两者综合起来进行分层预测能够克服不确定因素对模型预测的影响,从而提高预测性能,并且降低了对单层预测建模的要求,拓宽了基础算法的应用范围,适用于处理动态、复杂、目标多样、有不确定性又难以参数化的复杂系统的控制。以两层预测建模为例,设计了残差混杂预测方法的实施方案,流程如图7所示。
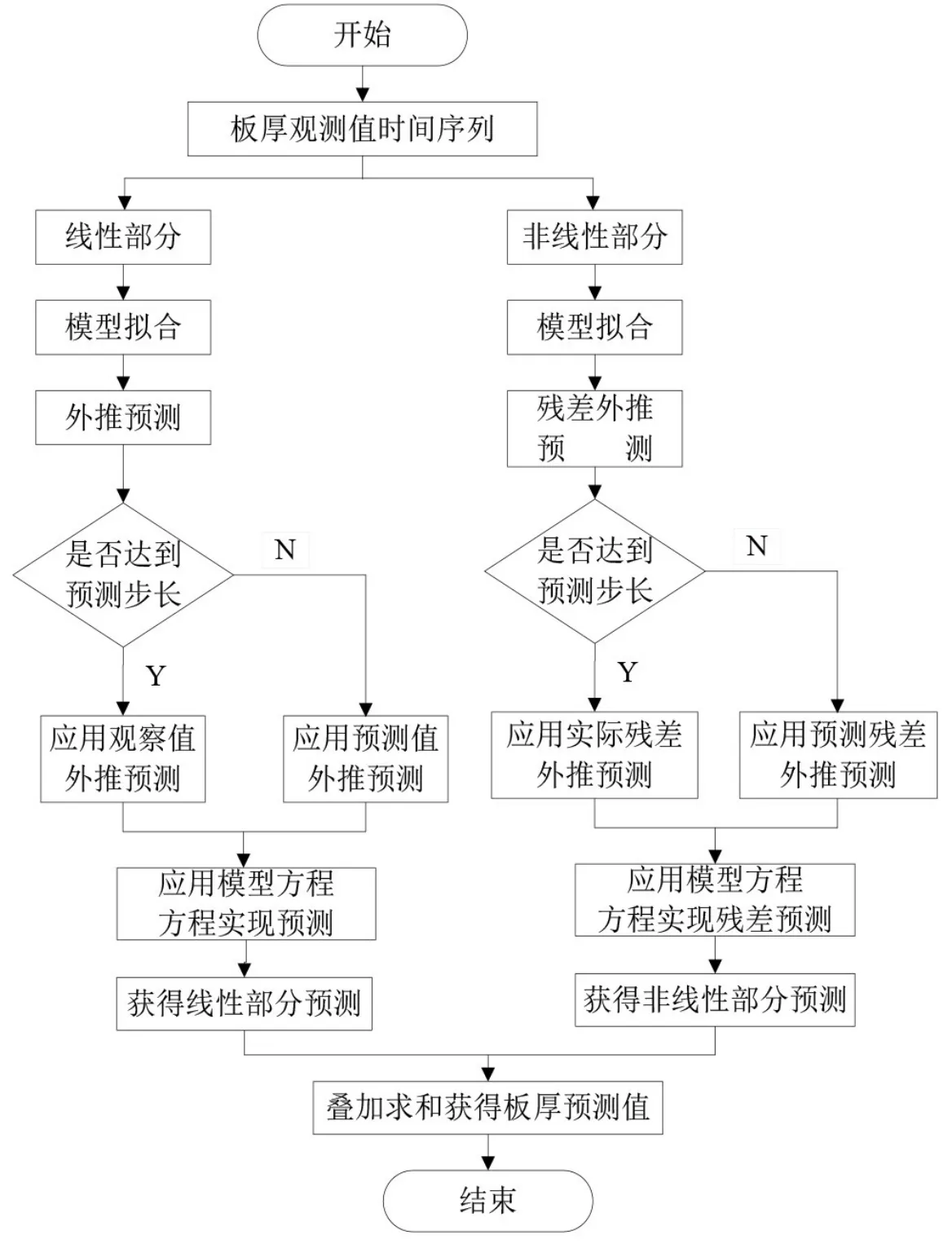
图7 残差混杂预测流程图
目前,残差预测方法典型的实施方案是结合ARIMA线性拟合与非线性部分预测的方式,神经网络、支持向量机等方法在此发挥着残差预测的作用。此时,神经网络等非线性映射方法的应用与参数映射类方法不同,以神经网络为例,此时的输入不再是轧机的多个轧制参数,而是时间序列的历史数据和前M-1个板厚预测值。这种残差混杂预测方法具有动态跟踪系统特性的能力,预测精度较高。
(2)多频混杂预测
多频混杂预测方法是将实际时间序列数据分解为子序列,对子序列分别进行预测并通过重构叠加获得最终预测结果。傅里叶变换、小波分解和经验模态分解等方法都可以将时间序列数据分解为多个高频和低频子序列[11],多频混杂预测方法的流程如图8所示,从图中可以了解到这类方法的实施方案。
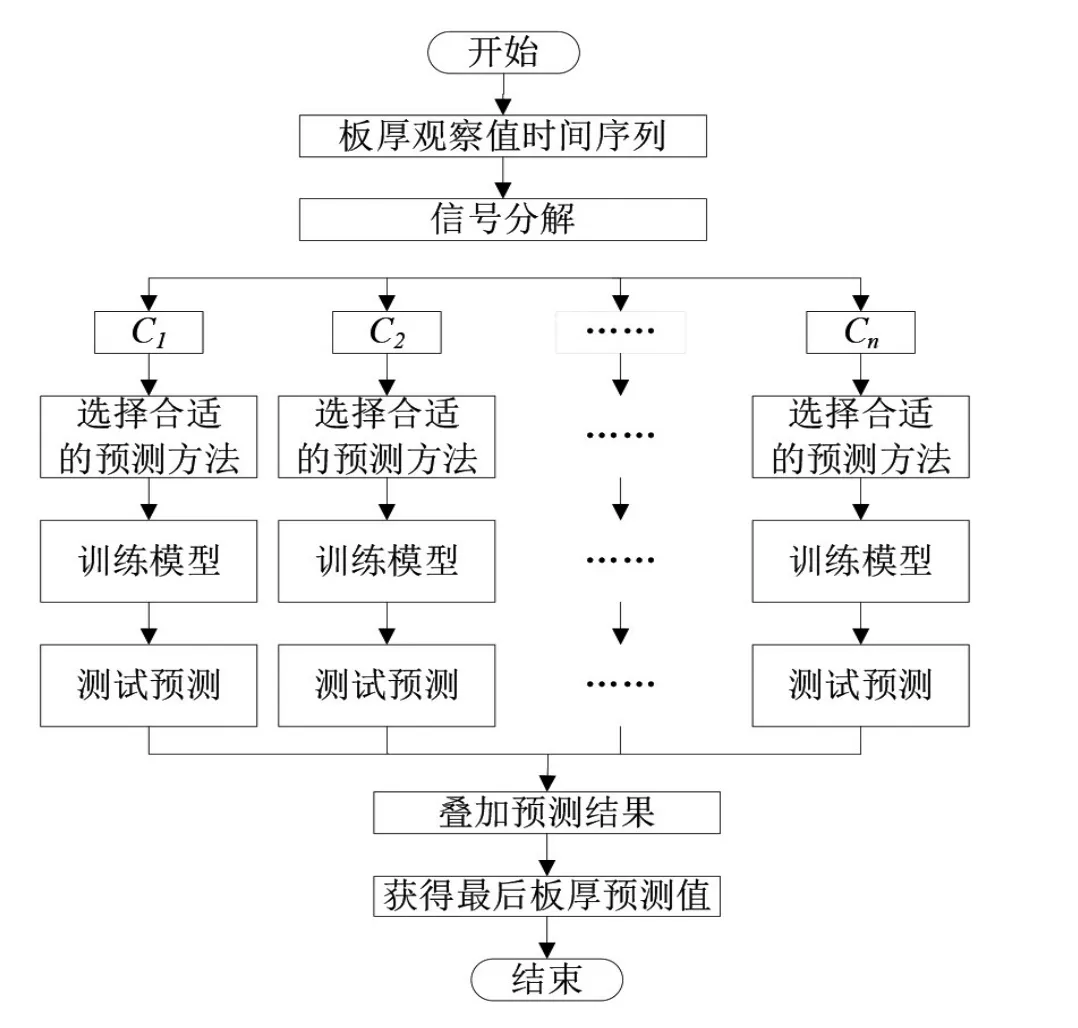
图8 多频混杂预测模型流程图
从另一个的角度分析,多频混杂预测方法也可以归属于残差混杂预测方法,被分解的低频子序列可以视为线性部分,高频子序列可以视为非线性部分。简而言之,混杂预测方法可以视为线性和非线性预测方法的综合体,这类方法已经取得成熟的研究成果,可以直接引入热连轧机板厚预测中,将会取得不错的预测性能。
2 预测性能评估指标
预测性能评估指标主要有均方误差(R)和平均绝对误差(M)[12],本文提出了稳定性评价指标,称为误差方差(E),目标是获得较高的板厚多步预测精度和预测稳定性。

板厚精度是保证钢板质量的重要指标,为了节约金属成本,在生产实践中通常要保持板厚处于负公差。随着研究的深入,虽然预测偏差越来越小,板厚精度越来越精确,但并未注意到负公差问题的偏向。因此,在未来的预测研究中应该建立基于负公差的寻优指标,可以考虑加入正负号标识手段,有针对性地进行优化,另外,在控制中对于超调量的严格要求也是对这一指标的重要贡献。
3 结语
本文结合现有研究,简要地阐明板厚预测在热连轧机板厚精度控制中的重要意义,立足于全面总结了应用于板厚预测的可行性方法。以新的视角将其分类,逐一阐述各类方法的优缺点,并列举其在板厚预测中的实施方案;通过介绍现有板厚预测的评价指标,提出新的算法稳定性指标,以全面衡量算法性能,同时提出板厚精度控制的负偏差问题应该在板厚预测和控制中得以重视,并给出了解决思路。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
导航定位学报(2022年3期)2022-06-10
网络安全与数据管理(2022年3期)2022-05-23
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
新生代(2018年16期)2018-10-21
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2017年2期)2017-11-24
华人时刊(2016年16期)2016-04-05
