
基于深度神经网络和多特征融合的语音端点检测
2021-08-03 08:26陈爱华张石清
台州学院学报 2021年3期
陈爱华,张石清
(台州学院 电子与信息工程学院,浙江 台州 318000)
0 引言
语音端点检测(Voice Activity Detection)是语音识别领域一个重要内容,是语音信号处理的第一步,它主要是从音频文件中确定语音片段的起止点,进而分辨出语音信号和非语音信号区域[1]。研究表明,即使是在理想条件下,语音识别技术的错误大部分都是由语音端点检测不准确造成的[2],因此语音端点检测在语音信号处理中具有重要的意义。
当前,语音端点检测的方法很多,早期算法主要是基于时域特征进行检测[3],如最早的语音端点检测是以语音的短时能量和过零率特征来实现的[4],后来人们又将语音信号从时域转换到频域,并将熵特征引入到语音端点检测中[5],提出了基于频带方差的检测[6]、基于共振谐波的检测[7]、基于倒谱域特征的检测[8]等等。随着人工智能的不断发展,新的算法不断涌现,小波分析、人工神经网络、支持向量机等技术也应用到了语音端点检测中[9-11],取得了较好的效果。但在实际语言环境中,由于语音背景环境复杂,单一的语音端点检测算法难以适应各种环境,算法的鲁棒性和准确性不高。近年来,新发展起来的深度神经网络(Deep Neural Network,DNN)通过采用多层网络结构进行层次化特征学习,表现出强大的非线性学习能力和预测能力[12],特别是在语音信号识别和增强方面表现出了优越的性能[13-15][16]211。音频文件的耳蜗特征具有较好的语音识别能力和噪声鲁棒性[17]168;短时特征可以有效地区分音频信号的清音段和浊音段[18]755;长时变化特征在非平稳噪声的环境下,具有更好的分辨率和更高的检测率[19]。本文融合这三种语音信号特征,作为DNN的输入计算信号属于语音/非语音的概率,然后根据阈值判定语音端点。仿真实验结果表明,该算法可以在复杂语言环境下实现语音端点检测,适应能力强,具有较高的准确性和鲁棒性。
1 语音信号特征提取
1.1 Gammatone滤波
Gammatone(GT)滤波器是一种耳蜗听觉滤波器,滤波器低频段信息丰富,高频段信息简单,与人耳听觉特性较符合,中心频率的分布和每个频率子带的特性都与人耳基底膜的特性对应,可用于音频信号的分解及特征提取[17]169。GT滤波器组的表达式是从冲激响应的测量中得出的,具有完整的幅度和相位信息。它的脉冲响应公式如下所示:
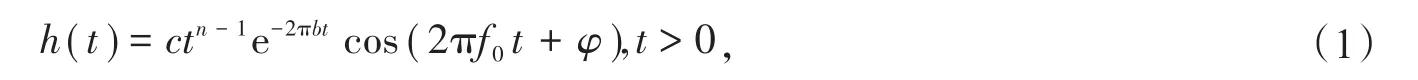
其中,c为调节比例的常数;n为滤波器的阶数,通常标定为4.0;b为衰减速率,值越大衰减越快,脉冲反应时间就越少;f0为滤波器组的中间频率,f0取值为0时的GT滤波器称为基带GT;φ为滤波器相位。
1.2 Gabor滤波
Gabor变换是加窗傅里叶变换的一种,它可以抽取空间局部频域特征,具有较好的频率选择和方向选择的性质[18]756。Gabor滤波器是一个二维滤波器,它的表达式如下所示:
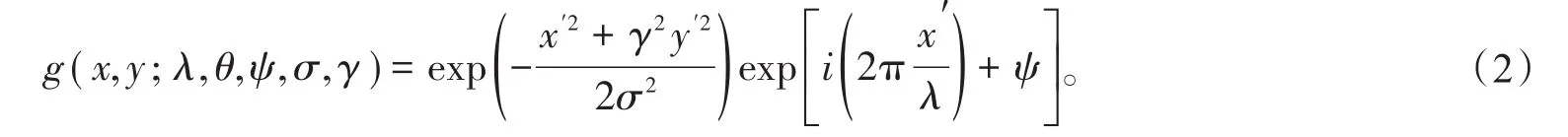
其中,实部部分的表达式为
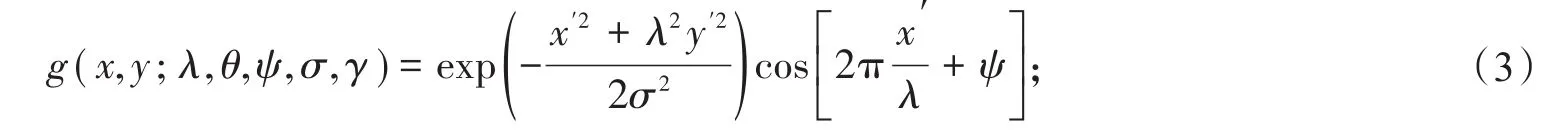
虚部部分的表达式为

其中,波长(λ)以像素为单位,通常不会小于2;方向(θ)用于指定Gabor函数并行条纹的方向,取值范围为0到360度;相位偏移(φ)取值范围为±180°;长宽比(γ)为空间纵横比例,用于表示Gabor函数形状的椭圆率,当γ=1时为正圆形。
语音信号是一维信号,本文首先对语音信号进行方向场估计和脊线频率估计,生成一个带有特定方向和频率分布的正弦平面波。Gabor滤波器可以很好地增强代表谐波成分的脊线附近区域,由此可以获取语音样本信号的短时特征。
1.3 LTSV滤波
LTSV(Long-Term Signal Variability)滤波使用一个较长时的语音分析窗口来分析语音信号和噪声信号的非平稳性变化特点,因此在非平稳噪声的环境下,与短时特征相比,算法具有更好的分辨力和更高的准确率[20]。算法首先对音频文件进行短时处理,然后使用一个长时分析窗口利用熵的测量进一步处理。算法的基本原理如下:首先,对语音信号进行分帧加窗,采用短时傅里叶变换(Sort-Time Fourier Transform,STFT),将信号由时域变换到频域,计算语音的短时谱为SX(n,ωk),具体公式如下所示:

其中,X(n,ωk)表示第n帧语音在频率为ωk时的STFT系数,Nω为语音帧长,Nsh表示帧偏移量。接着计算每个频率点的熵,公式如下所示:

熵的计算范围是包括当前帧在内的前R帧对应频率点的短时谱值,实现了语音的长时分析。计算K个频率点的熵的方差,就可以获得长时滤波的特征值Lx(m)。
2 基于深度神经网络和多特征融合的算法框架
2.1 深度神经网络
深度神经网络是在浅层神经网络的基础上发展起来的,它克服了浅层神经网络表示能力有限、易产生局部最优等问题,具有较好的非线性模拟性能和泛化能力。通常情况下,DNN的低层网络主要用于提取高层特征,而高层网络用于分类问题。本文利用深度神经网络强大的非线性学习能力和预测能力,解决传统语音端点检测对噪声估计难、端点检测准确率低的问题。DNN由输入层、多个全连接的隐含层和输出层构成。采用DNN进行语音端点检测时,输入层用于接收语音的特征信号,隐含层对这些特征信号进行处理分析、计算,建立特征与分类间的关系,输出层给出DNN分类的后验概率。
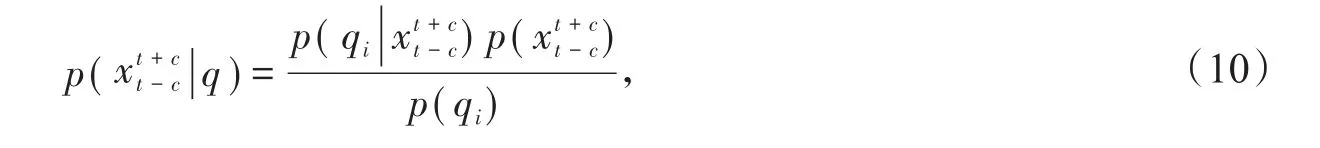
其中,p(qi)是qi状态的先验概率,可以通过模型训练得到[16]212。
本文以多特征融合的语音信号作为输入信号,通过事先训练好的DNN网络模型,计算每一帧语音信号属于语音或者非语音的概率。具体来说,采用典型的音频数据集DARPA RATS[21]中的训练集用于DNN模型的训练,从而得到一个训练好的DNN模型。对于新的测试样本,将使用该训练好的DNN模型进行测试。
2.2 算法整体框架
基于深度神经网络和多特征融合的语音端点检测算法的整体流程如图1所示。首先加载音频文件,然后采样生成语音源文件;进而采用GT滤波算法提取音频源文件的耳蜗特征,采用Gabor滤波算法提取短时特征,采用LTSV滤波算法提取长时变化特征。由于不同算法得到的语音信号特征值的范围不同,因此,首先将这三种特征信号进行归一化处理,融合后作为深度神经网络的输入信号。通过网络模型计算每一帧语音信号属于语音/非语音的概率,由于网络输出的语音概率准确率较高,文中采用简单的阈值进行判断,若计算得到的语音概率如果大于0.5,则判断为语音信号,取值为1,否则取值为0。最后通过一定窗长的中值滤波算法去掉孤立的跳变点,完成语音信号的端点检测。
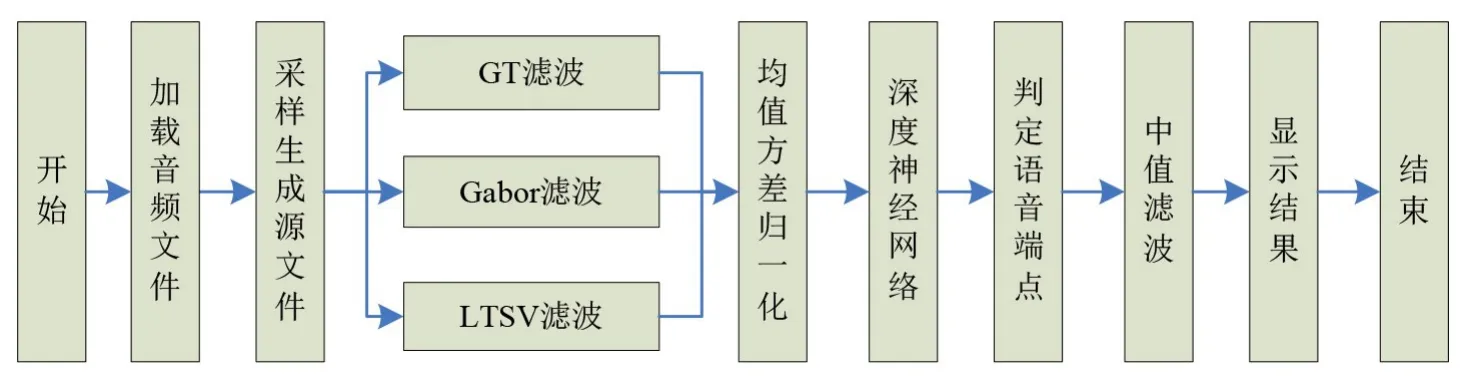
图1 算法流程图
3 仿真结果及分析
3.1 理想环境下的语音端点检测
为了验证算法的有效性,首先对理想环境下采集的音频文件进行仿真实验,检测处理结果如图2所示。图2中用到的音频文件是在安静的实验室环境下采集得到,其中包含三段语音信号。图2(a)是采用GT滤波处理后的数值颜色化输出结果,获取的是语音信号的耳蜗滤波后的特征;图2(b)是采用Gabor滤波处理后的数值颜色化输出结果,获取的是语音样本信号的短时特征;图2(c)是采用LTSV滤波后的数值颜色化输出结果,获取的是语音信号的长时变化特征。从这三个仿真结果可以看出:(1)音频文件经过这些算法处理后,得到的特征数据的语音区域明显区别于非语音区域,有利于后面的检测;(2)三种特征检测处理后的数据值范围区别较大,因此在进行特征融合前,必须对数据进行归一化处理后才可以送到DNN网络的输入端。图2(d)是采用DNN和多特征融合的语音端点检测出的三段语音信号。

图2 理想语音信号检测处理结果
为了便于观察每种滤波算法的输出结果与语音端点检测结果的差异,将最后语音端点检测结果叠加到滤波处理后的结果上,用方框表示。仿真结果如图3所示,为了清晰显示语音端点的位置,图3(a)和图3(b)中,语音区域设置值为10,非语音区域设置值为0,下面的仿真实验也是如此设置。

图3 理想环境下的语音端点检测结果
3.2 噪声环境下的语音端点检测
为了验证文中提出的语音端点检测算法的鲁棒性,分别在三种自然背景噪声的干扰下采集三个音频文件来进行仿真实验。
第一个音频文件是在开着电风扇的实验室环境下采集得到的,其中包含三段语音信号,语音端点检测结果如图4所示。三段语音信号均被检测到,但是由于电风扇产生的噪音信号的干扰,检测到的语音信号的起止点略有偏差。
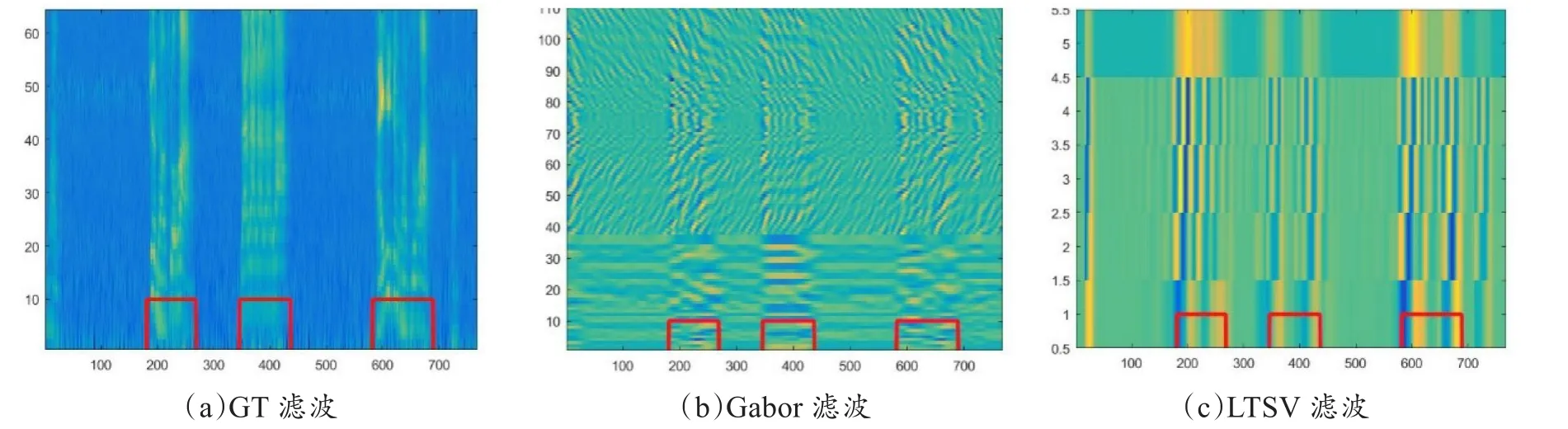
图4 开着电风扇的实验室环境下语音端点检测结果
第二个音频文件是在公园里采集得到,语音端点检测结果如图5所示。前面一段没有人讲话,但是有自然环境下的背景噪音;后半部分有人一直在讲话,由于说话人换气等因素的影响,造成说话声音有间隔,最后被识别为几段语音。

图5 公园环境下的语音端点检测结果
第三个音频文件是在建筑工地施工环境下采集得到的,语音端点检测结果如图6所示。这段在相对恶劣语音环境下的语音信号与公园采集得到的语音信号有点相似。前面一段没有人讲话,只有工地里面的各种噪声;后面是有人讲话的语音信号。用文中算法虽然检测到了语音信号,但是由于受到施工工地榔头敲打、砸东西等强噪声的影响,前面的噪声部分被误检出了语音信号。

图6 建筑工地施工环境下的语音端点检测结果
根据前面的仿真结果可以看到,本文提出的算法可在自然环境噪音背景下完成语音端点检测,即使在较为恶劣的环境下,仍然可以检测到语音信号。结果说明,结合DNN和多种特征融合的算法在语音端点检测方面具有较高的准确性和鲁棒性。
4 结语
针对自然语言背景环境复杂、当前单一语音端点检测算法检测准确率较低及鲁棒性较差的问题,本文提出了一种基于深度神经网络和多特征融合的语音端点检测算法。该算法针对语音信号的特点,分别提取了耳蜗特征、短时特征以及长时变化特征,对语音信号分析较为全面,使算法具有较强的鲁棒性。深度神经网络在语音信号增强及识别中取得了较好的效果,我们将以上三种特征融合后作为深度神经网络的输入信号,经过处理后得到的语音信号的概率准确性较高,进一步提高了算法端点检测的准确性。但当前论文研究主要停留在实验室环境下,计算较为复杂,后续工作考虑将算法进一步简化并应用到实际场景中,以期为自然语言背景下语音端点检测技术的研究提供较高的参考价值和应用价值。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
语数外学习·高中版中旬(2020年8期)2020-09-10
中学生数理化·教与学(2019年8期)2019-09-18
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
电子制作(2018年16期)2018-09-26
电子制作(2018年1期)2018-04-04
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
火控雷达技术(2016年3期)2016-02-06
火控雷达技术(2016年2期)2016-02-06
