
基于深度神经网络的新闻舆情分析系统研究与实现
2021-08-03 08:26王庆娟
台州学院学报 2021年3期
周 雁,王庆娟,庞 桐
(北京理工大学珠海学院 计算机学院,广东 珠海 519000)
0 引言
舆情是“舆论情况”的简称,是指在一定的社会空间内,围绕中介性社会事件的发生、发展和变化,作为主体的民众对作为客体的社会管理者、企业、个人及其他各类组织及其政治、社会、道德等方面的取向产生和持有的社会态度[1-4]。它是较多群众关于社会中各种现象、问题所表达的信念、态度、意见和情绪等表现的总和[5-7]。
舆情是社会事件的发生与变化,新闻是网络舆情的重中之重。随着互联网在全球范围的极速发展,人们获取讯息的主要方式渐渐转变为经由网络媒体获取。网络上的新闻种类繁多,信息量巨大,当网络出现重大舆情,特别是负面舆情时,若不能及时了解、有效引导,很容易形成舆论危机,严重时甚至影响公共安全。
随着大数据和人工智能的飞速发展以及机器学习中神经网络的突破,使得舆情分析监测系统的架构发生了根本性的转变[8-13]。以往的舆情信息解析系统大多以规则为主导,容易导致规则数量庞大、逻辑复杂,难以维护与升级;应用神经网络技术后,一般以神经网络模型为主、规则为辅,舆情分析系统的准确率与速度因此得到巨大提升。本文即是运用此思路,参考文献[9,14-22]中相关观点,构建了一个新闻舆情分析系统。通过将系统各模块松耦合,把解析模块独立出系统,使系统结构更清晰和灵活;研究利用神经网络代替规则作为分析工具,使用微量规则修正模型结果,以提高准确率。以此来对新闻进行过滤、筛选与分析,去除无用信息的干扰,从巨量数据中取出重要的信息,实现对网络新闻舆情的分析和监测,以便提前做出预警及必要准备。
1 系统设计
新闻舆情分析系统采用微服务架构,由四部分组成:Web服务、新闻搜集服务、新闻分析预测服务和数据存储服务,四个服务对应四个技术模块,如图1所示。
新闻搜集模块利用Scrapy框架以及Blocking Scheduler库构建新闻爬虫,全天候多进程定时爬取新闻。新闻分析预测模块利用TensorFlow框架搭建CNN模型实现两个多分类任务,分别用于新闻类型和情感的预测。数据存储模块是存放数据的后方阵地,由Mysql、MongoDB和ElasticSearch构成。Mysql负责存储原始数据与滤重表,滤重操作在这里进行;MongoDB存储分析后的数据;ElasticSearch作为搜索引擎单独部署。Web服务模块是连接系统各部分的枢纽,基于Tornado构建web服务,以连通另外三个模块。通过Web模块的连通作用,搜集的新闻先后历经滤重、关键词提取、分析得出预测结果等步骤后,存入相应数据库,并且与前端作数据交互,其详细流程图如图2所示。
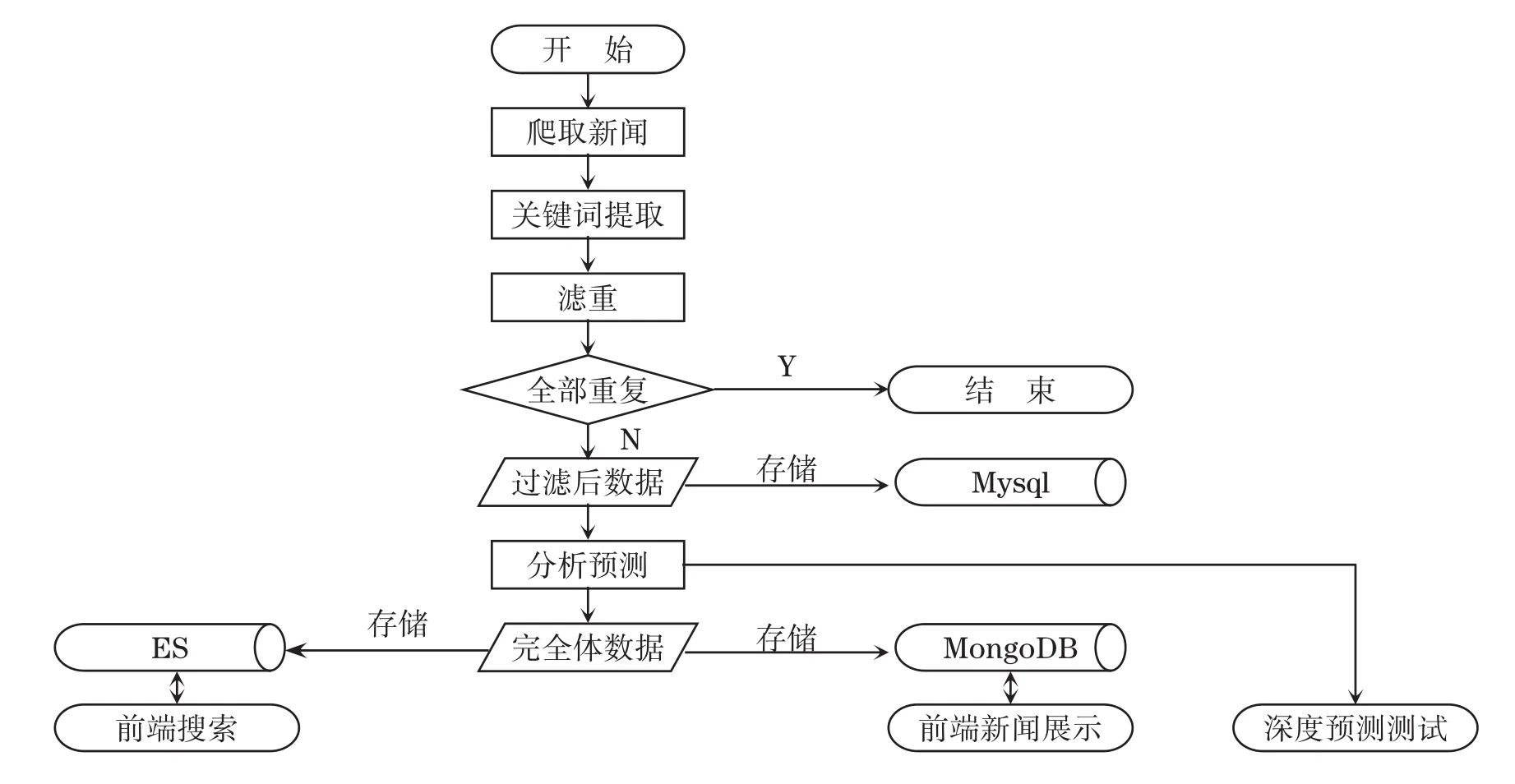
图2 系统流程图
2 关键技术简介与实现
2.1 服务器部署
系统采取微服务架构,其主要优点在于:
1)系统中的各个微服务被独立部署,不同服务之间通过http或rpc(Remote Procedure Call,远程过程调用)轻量级通信。
2)微服务之间松耦合,每个微服务只需关注本模块内的功能逻辑以及上下游的数据传输,且每个微服务都是一种相对独立的业务。
3)微服务更新迭代非常方便、快速,开发人员易于理解与管理。
4)可以按需定制资源利用,横向扩展十分方便。比如,新闻分析服务和新闻搜集服务所需的CPU存在较大差异,可以给前者分配更多的CPU,给后者分配较少的CPU,使资源利用最大化。
部署系统的微服务架构,使用的是云服务技术的革新者Docker。Docker是一个开源的应用容器引擎,它使得部署中最耗时的环境配置环节几乎可被忽略,为开发带来了巨大的便利。利用Docker,将应用或服务打包到一个虚拟化、可移植的微型Linux(或Windows)容器中。容器实际上是一个进程,之间不存在接口,在容器内的操作不会对宿主机造成任何影响,类似虚拟机。如果要进行通信,只需映射外部端口和内部暴露端口即可。Docker的工作过程类似做汉堡,构建镜像时的每一次命令都将添加一层镜像层(可以理解为添加面包片、芝士或肉)。基于镜像,便可启动容器。
2.2 数据集获取及关键词提取
数据集来自搜狗新闻的开源数据。使用Scrapy框架构建爬虫模块,从搜狗新闻的网页上爬取新闻,并对每条新闻提取标题、内容文本、更新日期、来源等结构性数据,进行编号后存入数据库。本文共搜集了约15万条新闻,提取其结构性数据作为原始数据集,训练集与测试集比例为9:1。
新闻数据集搜集完毕后,使用TF-IDF算法进行关键词提取,为后续处理作准备。
TF-IDF指的是词频-逆文本频率。词频是文本中某词出现的频率,一般来说,一个词在文中现的频率越高则越重要,但仅以词频考量词的重要度是不科学的。因为存在很多介词、代词等,它们出现的频率很高,但意义不大,不能用来表示文本的特征。因此引入逆文本频率(IDF)概念,其反映了一个词在所有文本中出现的频率。如果IDF低,即代表这个词在很多文本中出现,唯一性低;IDF高,即代表这个词在很少文本中出现,唯一性高。用变量FID表示IDF,词x的逆文本频率计算公式如下:

其中,N代表语料库中文本的总数,N(x)代表语料库中包含词x的文本总数。
综合考虑TF和IDF,用变量FT-ID表示TF-IDF,词x的词频-逆文本频率计算公式如下:

其中,FT(x)代表词x在当前文本中的词频。
基于TF-IDF,建立词库后,便可以开始抽取关键词了。本文利用Python的jieba库进行TF-IDF关键词提取。为了屏蔽不需要的词,还需自定义一份停用词列表供切词器加载。
2.3 Simhash滤重
提取关键词后,将输出新闻列表交给系统后端处理。为了避免对相同的新闻作重复的保存、分析等操作,必须对新闻列表进行滤重。新闻的滤重属于长文本滤重,综合考虑可行性和空间消耗等因素,对比Simhash、Bitmap和布隆过滤器等算法后,选择Simhash作为滤重算法。
Simhash算法由Manku G S等[23]提出,用于解决亿万级别的网页去重任务。其原理是将文本切词后得到的词的权重,经过Hash计算出二进制Hash值,然后加权求累加和,降维得到一个输出序列即为Simhash值;计算两个文本Simhash值间的汉明距离,如果小于某个阈值,即认为两个文本为类似文本。算法示意图如图3所示。
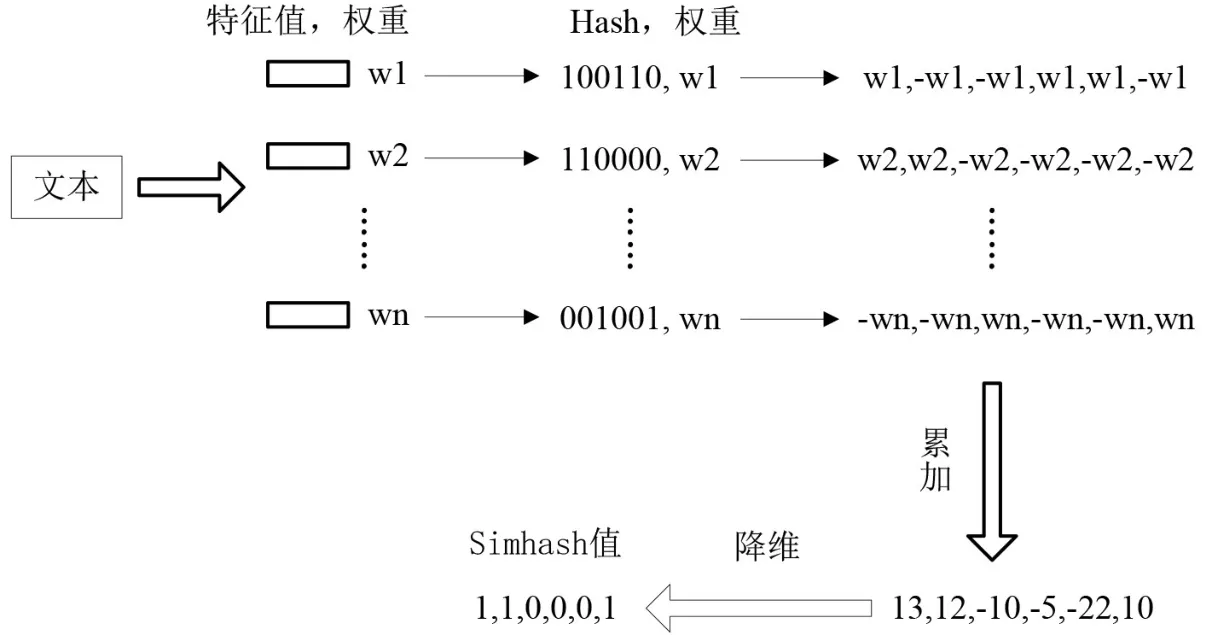
图3 Simhash算法过程
本文将滤重阈值设为3。首先在数据库中建立一张存放Simhash值的表,每次有新的新闻文本需滤重时,将其Simhash值与表中的Simhash值计算汉明距离,即进行异或运算,当距离小于等于3则判定此文本为重复新闻。
2.4 深度神经网络分析预测
滤重之后,使用深度神经网络对新闻进行分析预测。通过对新闻进行分析,预测出新闻的内容类型及情感倾向。本文将新闻类型分为6类:金融、科技、社会、时政、体育和游戏,情感倾向分为3种:正面、中性、负面。因此,新闻的分析预测本质上是两个多分类任务。
深度神经网络的基础结构由多个层组成,以学习具有多个抽象层次的数据特征,使得计算机能通过相对简单的概念来学习复杂的概念。本文的深度神经网络使用的是Tensorflow框架及CNN模型。CNN模型包含输入层、卷积层、池化层、全连接层、Dropout层及激活层,每一层完成不同的操作。
输入层用于训练语料的输入。语料在输入模型之前,需要进行清洗与优化。首先需要确保分类标签的准确性;其次是要去除其中的噪声,如剔除“了”“的”“你”“我”“他”等无用词,避免其影响模型的分析效果,使预测产生误差。输入层后加入Embedding层,避免语料中由于存在相同字词导致的向量距离较近而影响训练效果。卷积层是为了筛选特征,根据卷积核得到想要的特征形状。池化层是为了减少学习的特征数和数据量,突出特征。连接层使所有的特征整合在一起计算出一个值,这个值就是分类的结果。此操作可以消除特征位置对结果的影响,避免结果受到时序的干扰。Dropout层作用是将部分神经元舍弃,防止模型掌握了太多的特征而出现过拟合的情况。CNN的卷积层和全连接层都有激活函数,为模型加入非线性的影响因子,使得模型效果更好。文中的激活函数使用Softmax,它可以将全连接层的输出归一化,很好地计算出各分类的概率得分。
优化器用来更新和计算影响模型训练和模型输出的网络参数,使其逼近或达到最优值。以上为训练过程,模型训练完毕后,可输入待分析的新闻语料进行分析预测。
预测和训练流程基本一致,但无需损失函数计算和优化器的步骤。需要注意的是确保定义好预测文本Embedding的长度和词表的统一。
2.5 数据库技术
系统使用了Mysql和MongoDB两种数据库及1个全文检索引擎Elasticsearch。Mysql的作用主要是进行Simhash滤重和存储原始数据。Mysql中建了两张表:news表和simhash表。news表存放爬虫爬取的未加工数据,包括新闻的编号、标题、内容文本、更新日期、来源等具体信息。simhash表除了上述信息外,还存储了八列新闻文本的Simhash序列码,用于新闻滤重时计算新闻文本之间的汉明距离。MongoDB是一种文档型数据库,其拥有非常完善的权限机制。文中Mongo数据库用来存储新闻解析后的完全体数据,并同步到Elasticsearch中。MongoDB全文检索在数据量大时性能急剧下降,本文选用ElasticSearch来实现后台搜索。Elasticsearch存储的数据和Mongo是同步的,但没有Mongo自生成的_id。因此Elasticsearch不需要设计数据库,只需建立索引和文档类型即可。Elasticsearch提供RESTful的接口,系统通过http方式与ElasticSearch通信。
3 系统前端与系统应用
3.1 系统前端简介
系统前端设计简洁,共设计了三个页面:主页、深度预测页面以及搜索页面。页面使用Bootstrap、Layui和Datatables的组件搭建,使用JavaScript编写前端逻辑。由于技术比较简单,在此不做详细阐述。主页承载Datatables组件,自动从Mongo数据库获取最近50条新闻及其分析预测结果进行展示,负面情感的新闻会标红警示。深度预测页面是提供用户测试文本内容类型和情感倾向的一个页面。用户可以输入一段文本进行类型和情感的深度分析预测。后台搜索页面是基于Elasticsearch搭建的搜索服务,可以对用户输入的内容进行新闻搜索。
3.2 主页展示
主页展示新闻数据,获取50条最新的新闻并展示,界面如图4所示。在初始化表格的时候,前端给后端发送一串参数,包括:当前页面展示数据条数、当前页面页数等,后端根据参数的值,返回前端需要的数据集。

图4 主页界面
表格上方可选择每页显示的条目数,支持翻页和列排序。当单元格数据超过一定长度时,将生成超链接,点击后弹出信息框显示完整的文本内容。新闻内容、关键词、来源这三列内容字数较多时可通过点击显示全部内容实现浏览。
通过查看系统运行日志,可获取系统各部分的执行时间。如图5所示,系统获取50条最新新闻的时间大约为91 ms(其中查询数据库的时间约为87 ms)。
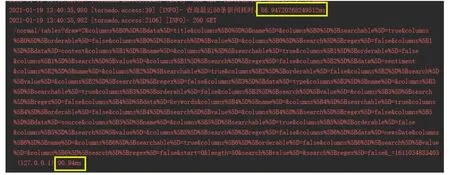
图5 系统运行日志
在新闻的滤重方面,500字的长文本建立Simhash序列码平均速度约为6 ms,万级数据的查询滤重平均速度约为7.5 ms。
3.3 深度预测页面
深度预测页面由两个文本域及对应的按钮组成,分别用于分析文本的情感倾向和新闻的内容类型,如图6所示。经测试,200字文本的分析预测耗时约为5 ms。如果要追求更快的速度,可以使用Tensorflow-serving载入pb格式的模型并使用rpc通信。
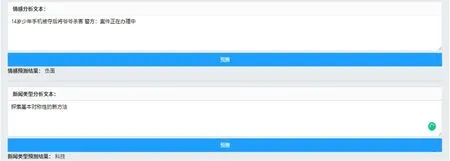
图6 情感分析和新闻类型分析
3.4 搜索页面
搜索页面由搜索文本框、搜索按钮和表格组成,如图7所示。当ElasticSearch中有1万条数据并设置最高返回80条结果时,平均搜索速度为500 ms。

图7 搜索页面
3.5 系统应用
本系统基于某企业实际项目中的舆情分析模块而设计开发。系统搭建完成后,对系统各部分功能进行了测试,均能正常执行,准确无误。后期根据企业使用需要,对系统进行了适当调整,并改写接口,目前已作为核心部分实际应用于该企业监测上市公司动态的项目中。投入应用后,该项目舆情分析模块的预测准确率得到了较大提升,具有良好的现实意义和应用价值。
4 结语
本文基于深度神经网络,研究并设计实现了网络新闻舆情分析预测系统。系统实现了预设功能,投入实际使用后,效果良好。然而系统仍存在一定的不足,如:前端的界面不够丰富和美观;新闻滤重时随着数据的增多,查询速度会逐渐变慢;等等。这些都将在实际应用中根据需要不断改进与升级。
猜你喜欢
黄河之声(2022年10期)2022-09-27
保健医苑(2022年1期)2022-08-30
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
动漫界·幼教365(中班)(2021年4期)2021-05-23
电脑爱好者(2020年17期)2020-09-14
领导决策信息(2017年13期)2017-06-21
领导决策信息(2017年9期)2017-05-04
消费电子(2016年12期)2017-01-19
