
求解高斯过程方程组预测煤元素含量研究
2021-08-03 08:25刘福国
热力发电 2021年7期
刘福国,刘 科
(国网山东省电力公司电力科学研究院,山东 济南 250003)
煤的元素组成是电厂能量转换过程效率分析的基本数据,常用于确定锅炉燃烧空气量、排烟烟气量以及烟气成分等,帮助运行人员控制合理的炉膛送风量,降低排烟热损失和风机电耗[1-3]。因此,煤质实时测量在电力生产上受到较多关注[4-5]。目前,电厂化学实验室每天定时进行入炉煤工业分析,并在厂内实时数据库中更新分析数据;但煤的元素成分检测较为复杂,需要特殊的仪器和资质较高的化学分析人员,普通的电厂化学实验室通常不能进行元素含量检测,而基于瞬发伽马中子活化分析(prompt gamma neutron activation analysis,PGNAA)技术的在线测量系统成本较高,且需要特殊安装位置,因此还未得到广泛应用[6-7]。目前,煤元素成分的检测通常在较高级别的实验室内进行,因而滞后性较大。
根据煤的工业分析预测元素含量,再通过电厂实时数据库提供给运行人员,用于锅炉调整和控制,这是一种高性价比的煤质监测方法。这种采用易于测量的煤质参数预测难以测量煤质参数的方法,在以前的文献有较多研究[8-10];但工业分析和元素分析包含多种成分,一些元素含量较低且受随机因素影响较大,全部元素成分预测存在较大困难;另外,元素含量预测还要保证组成的完整性,即所有元素含量之和等于100%。采用回归分析或神经网络等对元素含量进行直接建模,难以保证元素组成的完整性,因此,现有文献通常只给出C、H和O等主要元素成分的预测关联式[11-13]。
本文的主要目标是,根据煤的工业分析数据预测元素分析的全部成分。为此,首先寻找多种成分或成分组合量之间的关联式,而不是对某种元素含量进行直接建模;所得的成分关联方程与全成分完整性方程一起组成方程组,解得煤的各种元素成分,从而保证全成分的完整性;为提高元素含量的预测精度,将关联方程的残差作为随机过程,采用高斯过程对残差进行建模,这种考虑残差的解方程法能够较为准确地预测煤的全元素成分。
1 煤样检测及样本数据
煤样采制按ISO 18283—2006(E)标准进行,水分、挥发分和灰分等工业分析的检测分别按照ISO 589:2008、ISO 562:2010和ISO 1171:2010标准进行;发热量的测定和计算遵守ISO 1928:2009标准;煤元素成分的检测根据ISO 17247:2013标准进行。
本研究共收集或检测了287个煤样数据,每个样本包括工业分析、元素分析和发热量等数据,这些成分均以干燥无灰基表示,发热量是干燥无灰基高位发热量。其中175个样本从公开文献中收集[14-16],考虑收集的样本数据分布,补充检测了112个样本煤,这些煤样来自火力发电厂入炉煤实际采样,在实验室中按照上述ISO标准对各种成分和发热量进行检测。表1给出了所有样本数据的参数区间,这些样本覆盖了无烟煤、贫煤、烟煤和褐煤等各种发电用煤。
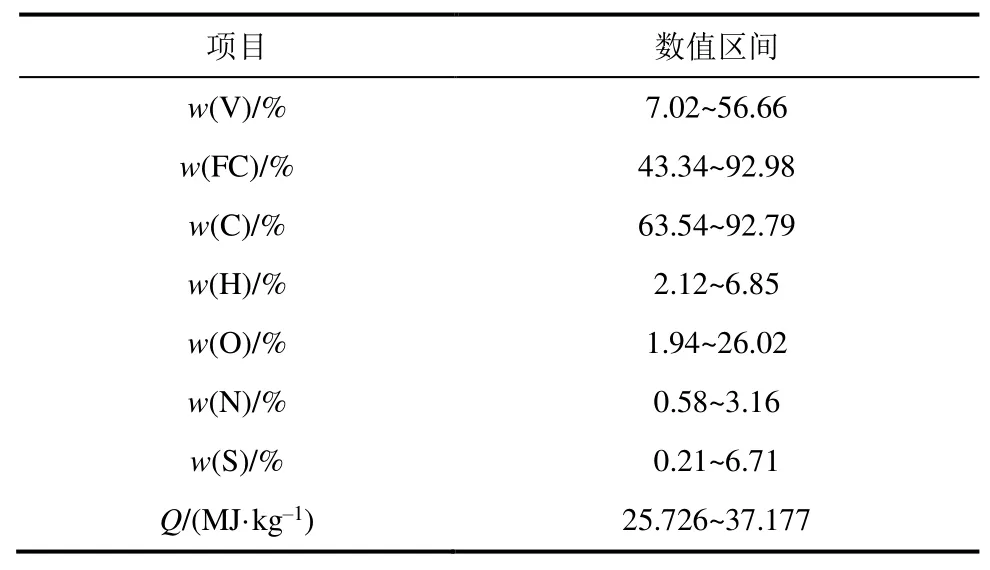
表1 样本参数区间Tab.1 Parameters intervals of the test sample
模型输入变量采用干燥无灰基成分,能够避免煤运输和储存过程中,灰分和水分变化带来的误差;采用干燥无灰基高位发热量,测定时不需要已知氢元素含量。
2 各种成分之间的关联方程式
根据样本煤的工业分析、元素分析和发热量,对各种成分之间的相关性进行了大量研究,得到4个质量较高的关联方程如下:

式中,w(C)、w(H)、w(O)、w(N)、w(S)分别表示煤的干燥无灰基碳、氢、氧、氮、硫的质量分数,Q为煤的干燥无灰基高位发热量,εi(i=1,2,3,4)为预测残差。
图1 给出了式(1)—式(4)所表示的方程及样本数据点分布。从图1可以看出,样本数据点都分布在方程所表示的直线附近。
以往研究表明,煤的氢元素或氧元素含量与碳元素含量之间有明显相关关系[17-18]。式(1)和图1a)给出了氢氧2种元素含量之和与碳元素含量之间的关系,研究表明,这种相关性更高,相关系数R=0.968。

图1 煤的各种成分之间的关系Fig.1 Relationship between various components of the coal

式(2)和图1b)反映了挥发分的组成规律。挥发分V通常由氢元素、氧元素、一部分碳元素和少量硫元素组成。假设固定碳FC中没有氢元素和氧元素,全部是由碳元素组成,则挥发分V中的碳元素等于元素分析碳C含量减去固定碳FC,即等于[w(C)–w(FC)]。式(2)左侧是氢元素、氧元素以及[w(C)–w(FC)]之和,它们与挥发分含量w(V)成正比,相关系数R=0.981。
式(3)和图1c)表明,[100–w(C)–w(N)]与C含量之间有很好的线性关系,相关系数R=0.997,主要是因为煤中氮元素含量普遍较低,一般在1%~2%。因此,式(3)反映了煤中氮元素含量特性。
式(4)将发热量Q表示成各种元素含量的函数,现存文献中有较多类似的研究[19-20]。式(4)右侧的元素含量组合项作为发热量预测值。以样本煤发热量实际值为横坐标,预测值作为纵坐标,绘成图1d)。图中粗实线上的点表示实际值和预测值相等,可以看出,大部分样本点分布在粗实线附近,表明预测值和实际值较为接近。
各种元素含量除应满足式(1)—式(4)外,还应保证元素成分的完整性,即全部成分之和等于100,即

3 残差预测
式(1)—式(5)组成方程组,忽略方程中的预测残差εi(i=1,2,3,4),并将w(FC)、w(V)、Q作为已知数,可解得C、H、O、N、S等元素含量。但忽略残差会导致元素含量的预测误差增大。为提高元素含量预测准确性,先采用高斯过程对残差εi进行回归建模,根据所建模型对残差εi进行预测,在考虑残差εi的情况下,求解式(1)—式(5)组成的方程组,得到各种元素含量。
3.1 残差高斯过程模型
用y表示式(1)—式(4)中的某种残差ε1、ε2、ε3和ε4。对应每一个样本,残差y作为一个随机变量,样本的w(FC)、w(V)、Q组成3维实向量x,作为残差随机变量y索引,则随机变量y的集合{y(x),x∈R3}就是一个随机过程,其中x为
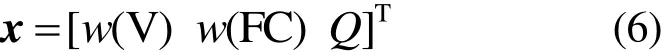
利用样本煤数据,残差随机变量y的观测值根据式(1)—式(4)计算得到,y的观测值包含了各种成分含量的观测噪声ε,不包含观测噪声的部分用高斯过程f表示,则
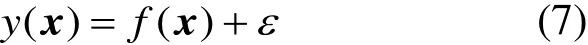
高斯过程f是一种随机过程,其中任意有限个随机变量组成多元高斯分布,f由均值函数m和协方差函数k确定,定义为:

式(8)表示索引位置x处的随机变量f的数学期望等于均值函数m(x)的值;式(9)中fi和fj分别为索引位置xi和xj对应的随机变量,这2个随机变量的协方差cov(fi,fj)等于协方差函数k(xi,xj)的值;式(10)表示函数f分布符合均值函数为m、协方差函数为k的高斯过程。
根据高斯过程定义,任意n个随机变量f=[f1,f2, …,fn]T服从多元高斯分布,即

式中,μ为均值向量,K为协方差矩阵。
μ中第i个变量fi的均值μi根据函数m(x)计算:

协方差矩阵K的第i行和第j列的元素是随机变量fi和fj的协方差,利用协方差函数k(xi,xj)计算:

式(7)中,假设y的观测噪声是独立同分布的高斯噪声,即

根据式(7)和式(15),若认为每一个f(x)与它自己有一个额外的协方差,则该协方差的大小与噪声ε的方差相同,因此,可得到包含观测噪声的函数y(x)符合如下高斯过程:

式中,δii′是克罗内克函数,且仅i=i′时,δii′=1。
3.2 均值函数和协方差函数
均值函数m(x)通常表示为显式基函数h(x)的线性组合,即

式中,h(x)为基函数向量,β为系数向量。
基函数h(x)可选为常数、线性或纯二次方等型式,当选用线性基函数时,对于上述残差高斯过程,式(17)中的h(x)和β分别为:
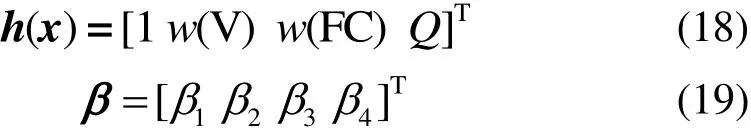
协方差函数k(xi,xj)又叫核函数,是高斯过程的核心,最常用的核函数为径向基核函数,其基本形式如下:

式中σ和l为核函数的超参数。k(xi,xj)是2个维度fi和fj之间的协方差cov(fi,fj),根据式(20),它与索引变量xi和xj之间的距离有关,当xi和xj之间的距离很小时,协方差的值几乎等于1,随着xi和xj之间的距离增加,协方差的值减小。因此,索引变量xi和xj之间的距离越小,它们所对应的随机变量fi和fj之间的协方差就越大,fi和fj之间的线性相关性越强,其中一个随机变量由另一个决定的程度越大。这是高斯过程回归的关键所在。
残差高斯过程的协方差函数k(xi,xj)也可选用参数为5/2的ARD matern核函数:
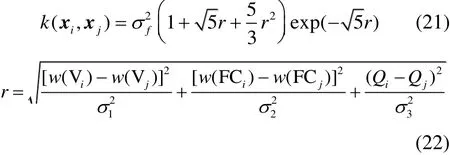
3.3 训练高斯过程
对于式(16)所示的残差高斯过程,它作为贝叶斯推断的先验。先验给出了均值函数m和协方差函数k的信息,见式(17)和式(21),但这些函数信息依然是模糊的,因为虽然函数形式已经确定,但其中β和σf等是未知参数。
高斯过程训练就是利用观测数据对均值函数和协方差函数的先验信息进行更新,确定其中的未知参数,这些参数分布在式(17)、式(21)和式(22)中,它们和式(16)中的高斯噪声方差一起组成超参数θ={σn,β1,β2,β3,β4,σf,σ1,σ2,σ3}。若已知n组观测数据D={(xi,yi)},根据高斯分布可得到给定超参数下观测数据的概率logp(y|x,θ),即
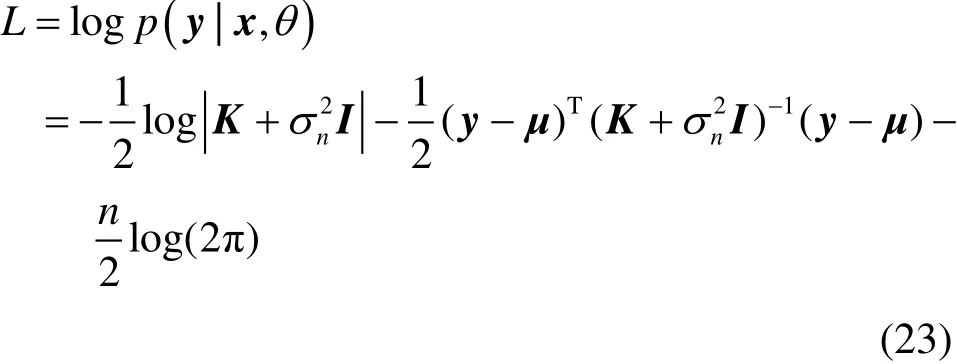
式中,I为单位矩阵,μ和K分别根据式(12)—式(14)、利用n组观测数据得到。
根据最大似然原理,对数边际似然函数L取得最大时的超参数值作为求解结果。采用共轭梯度算法确定上述最优化问题的超参数值。
3.4 利用高斯过程预测残差
残差高斯过程的超参数确定后,根据给定的索引变量x*的值,可预测x*所对应的残差值f*。
在给定n个观测数据D={(xi,yi);i=1,2,…,n}的情况下,输入x*所对应的函数y*的条件概率分布为:

其中

式中μ*根据均值函数m(x)计算,μ*=m(x*);k*表示索引输入x*和n个观测点之间的协方差向量,它由n个协方差函数k(xi,x*)值组成。
式(24)—(26)表明,高斯过程预测虽然利用了训练得到的超参数,但预测计算更多是根据观测数据D来进行,因此,高斯过程是非参数模型;利用式(26)计算预测值y*的方差σ2[y*],从而可得到y*的置信区间,因此,高斯过程可以给出概率型预测结果。
3.5 残差预测结果
对于式(1)—式(4)中的每一种残差ε1、ε2、ε3和ε4,各建立一个高斯过程。利用表1中287个样本数据,分别根据式(1)—式(4)得到相应残差的观测数据,用于训练和预测。
均值函数的基函数分别选用常数、线性或纯二次方函数,协方差函数分别选用径向基核函数、参数为3/2的Matern核函数以及参数为5/2的ARD Matern核函数,进行对比训练和预测。研究表明,线性基函数和参数为5/2的ARD Matern核函数有较好的预测精度。
287个样本的w(V)、w(FC)和Q分别作为残差高斯过程的输入,对式(1)—式(4)中的残差ε1、ε2、ε3和ε4进行预测,预测值和实际值的对比如图2所示。
图2 中黑实线上的点表示残差的预测值等于实际值。从图2可以看出,残差预测值和实际值的样本点都分布在黑实线附近,表明高斯过程对残差预测的准确性较好,残差的预测精度可用平均相对误差δMAPE来表示。

图2 残差预测值和实际值Fig.2 The predicted values and actual values of the residual error
4 元素含量预测
在忽略残差ε1、ε2、ε3和ε4的情况下,求解式(1)—式(5)组成的方程组,得到煤元素含量分析关联式如下:

由于式(27)—式(31)忽略了残差,势必导致各种元素含量预测误差增大。
为提高元素含量预测精度,首先通过上述残差高斯过程回归模型计算式(1)—式(4)中的残差ε1、ε2、ε3和ε4,将这些残差值代入式(1)—式(4),求解它们和式(5)组成的方程组,得到煤元素成分含量。
在忽略残差和考虑残差的情况下,对287个样本的元素含量进行预测计算,并分别计算均方根误差δRMSE[2]和平均相对误差δMAPE[11],结果见表2。

式中,Pi为预测值,Mi为测量值,n为样本个数。
从表2可以看出,采用解方程法预测各种元素含量的均方根误差δRMSE在0.24~2.55之间;当考虑残差时,C、H、O和N元素含量的平均相对误差δMAPE在1.46%~16.48%之间,S元素含量的δMAPE预测误差较大。考虑残差后各种元素的预测误差都明显降低,C元素的δMAPE从2.38%降低到1.46%,H元素的δMAPE从9.57%降低到6.34%,O元素的δMAPE从24.28%降低到16.48%。

表2 忽略残差、考虑残差及与有关文献的预测精度Tab.2 The prediction errors when ignoring and considering the residual errors and the ones in related literatures
文献[2]根据煤的工业分析,采用多元回归分析(MR)、主成分回归(PCR)、偏最小二乘法(PLS)以及反向传播神经网络(BP-ANN)等多种方法预测C、H和O等3种元素含量,并对这些方法进行了对比研究,结果表明,BP-ANN预测精度最高。表2给出了BP-ANN的预测误差,本文解方程法的预测精度高于BP-ANN法,尤其是考虑残差的解方程法,C元素含量的δRMSE比BP-ANN法明显降低。
Yi Lan[12]发现,采用二次回归模型预测煤O元素含量的误差很大,因此,根据挥发分含量,将煤分成无烟煤、烟煤、次烟煤和褐煤等4个子区间,利用不同的二次函数进行建模,以降低O含量的预测误差。在整个区间内,与Yi Lan的模型相比,虽然考虑残差的解方程法的O含量预测误差δMAPE有一定增加,但C和H含量的δMAPE均有所降低,且Yi Lan的分段函数预测模型需要进行区间判断,使用不方便。
为避免直接回归模型带来的全成分完整性的矛盾,文献[2]和文献[12]都只给出C、H和O等3种主要元素成分的关联式,降低了模型的实用价值,因为燃烧分析通常依赖于煤的全成分数据。
以元素含量实际值为横坐标,以考虑残差的解方程法的预测值为纵坐标,绘成图3。图中黑实线上的点表示预测值等于实际值。对于C、H、O和N等元素,样本点分布在黑实线附近,预测准确性较高,而S元素的样本点较为分散,含硫量高的煤预测误差较大,这也和表2的数据相吻合。

图3 元素含量的预测值和实际值Fig.3 The predicted and actual values of elemental composition
通常采用落入[–kσ,+kσ]区间内的样本相对数量来评价预测不确定性,σ取为根据式(32)计算的均方根误差。对于正态分布,当k=1.96时,上述区间的置信概率为95%,这意味着95%的样本落入区间[–1.96σ, +1.96σ]。图4给出了各个样本的C、H、O、N和S的实际值、预测值以及置信概率为95%的区域,为便于观察,每个图中的样本按实际元素含量进行从大到小排序。从图4可以看出:1)绝大多数样本点都落入95%的置信区域内;2)C、H和O含量预测值能很好反映实际值的变化(图4a)—图4c)),不同样本煤的N和S含量较稳定,只有少量样本的N和S含量较高(图4d)、图4e));3)对于C、H、O和N等元素含量,95%的置信区域宽度较小,这表明这4种元素含量预测精度较高,这与表2的数据相吻合;4)与S含量相比,煤的N含量更少,且更为稳定(图4d)、图4e)),这是N含量比S含量预测精度高的主要原因;5)图4e)表明,对于S含量过高或过低的煤,预测值偏离实际值较多。
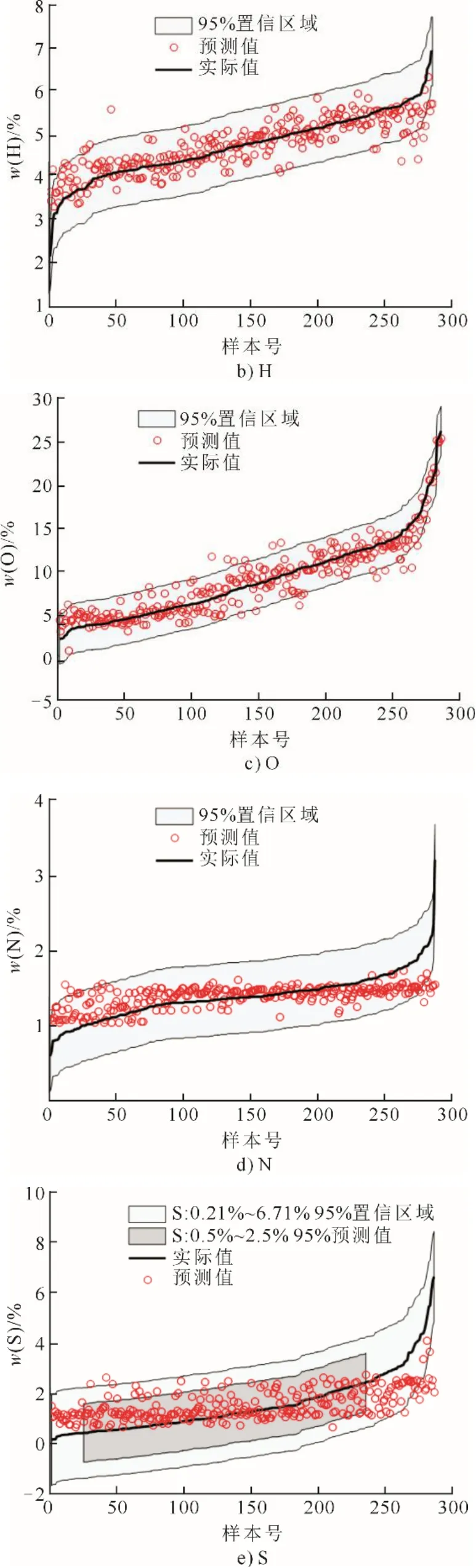
图4 元素含量预测置信区域及样本点分布Fig.4 The confidence regions of elemental composition prediction and the sample point distributions

因此,基于残差高斯过程的解方程法能够较为准确地预测煤的C、H、O和N元素含量,对于高硫煤,S含量的预测误差较大。但S含量通常在5%以下,其预测误差对煤的总体性能尤其是燃烧计算参数的影响较小。尽管如此,对于高硫煤,在使用预测模型时仍应多加关注。
图4 e)表明,对于常见的S质量分数区间,S元素的预测误差明显减小。当S质量分数在0.5%~2.5%范围内,95%置信区域明显减小,这表明S质量分数预测精度提高,这也被均方根误差δRMSE所证实:当S质量分数在0.21%~6.71%范围内,δRMSE值为0.92,当S质量分数在0.5%~ 2.5%范围内,δRMSE值为0.59。
5 结 论
1)采用回归分析或神经网络等对元素含量进行直接建模,通常难以保证组成的完整性。而通过求解煤成分关联方程与全成分完整性方程组成的方程组,预测元素含量,能够保证全成分的完整性。
2)煤成分关联方程的残差可采用高斯过程预测。这种考虑残差的解方程法能够较为准确地预测煤的全元素成分,其δRMSE和δMAPE均小于忽略残差的解方程法。
3)采用考虑残差的解方程法预测C、H、O和N元素含量的δMAPE分别为1.46%,6.34%,16.48%和12.86%。
4)S含量的预测较为困难,对于高硫煤,预测误差较大;对于常见的S含量范围,预测误差明显减小,δRMSE从0.92降低到0.59。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
北京大学学报(自然科学版)(2022年1期)2022-02-21
北京航空航天大学学报(2020年10期)2020-11-14
舰船电子工程(2020年3期)2020-06-11
北京航空航天大学学报(2019年9期)2019-10-26
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
考试周刊(2016年54期)2016-07-18
电影故事(2015年16期)2015-07-14
现代电子技术(2015年10期)2015-05-29
