
基于EfficientDet的高效目标检测算法研究
2021-08-02 11:42王慧勇
合肥工业大学学报(自然科学版) 2021年7期
王慧勇, 殷 明
(合肥工业大学 数学学院,安徽 合肥 230601)
0 引 言
计算机视觉领域包含如下几个基本的视觉任务:图像分类、目标检测、语义分割和实例分割等。图像分类识别给定图像中对象的语义类别;目标检测不仅可以识别对象类别,还可以通过边界框预测每个对象的位置;语义分割则是逐个像素的分类器,以便为每个像素分配特定的类别标签,不能区分相同类别的多个对象;实例分割识别不同的对象,并为每个对象分配一个单独的像素级分类标签。其中,目标检测负责在数字图像中检测特定类(例如人、动物或汽车)目标。目标检测作为计算机视觉的基本问题之一,是许多其他计算机视觉任务的基础,如实例分割、图像字幕、目标跟踪等。从应用角度来看,目标检测可以分为通用目标检测和特定场景下的目标检测2个研究主题。通用目标检测需要识别不同类型的目标来模拟人类的视觉和认知;特定场景下的目标检测应用在特定的应用场景下,如行人检测、人脸检测、文本检测等。
普遍认为,目标检测的发展大致经历了2个阶段:传统的目标检测阶段和基于深度学习的检测阶段。传统的目标检测算法大多是基于手工特征构建的。由于当时缺乏有效的图像表示,只能设计复杂的特征表示和各种加速技术来充分利用有限的计算资源。
与传统检测算法使用的基于手工设计的特征描述相比,深度卷积神经网络从原始像素到高级语义信息生成分层的特征表示形式,这些特征表示形式是从训练数据中自动获取的。深度卷积神经网络可以使用更大的数据集获得更好的特征表示,而传统方法的学习能力是固定的,并且在更多数据可用时无法提高,如文献[1]利用深度神经网络有效实现了分类任务。
当前,基于深度学习的对象检测框架主要可以分为双阶段检测算法和单阶段检测算法2个系列。双阶段算法代表性的有r-cnn[2]、faster r-cnn[3]、mask r-cnn[4]等;单阶段算法代表性的包括yolo[5]、ssd[6]、focal loss[7]、yolov3[8]等,最新的高效算法有EfficientDet[9]等。目标检测可以应用到自动驾驶、机器人视觉、视频监控、无人机场景分析等领域,因此具有学术价值和商业价值,现阶段仍是计算机视觉领域热门研究方向之一。
现阶段高性能的目标检测算法均基于深度神经网络。深度神经网络本质是一个参数量很多的非线性函数。算法优化不断更新所有参数,使得度量预测值和真实值距离的损失函数尽量小,优化的范围是特定数据集,优化目标就将训练数据的平均误差最小化。
梯度下降算法是机器学习中使用非常广泛的优化算法,但是其各种变体都多少存在不足。如随机梯度下降每次只使用一个样本更新参数,优化的波动性比较大;Adagrad[10]需要计算梯度序列平方和做分式的分母,学习率会不断衰减到一个非常小的值;Adam[11]虽然目前很流行,但在很多领域不适用;AMSGrad[12]做到了低测试损失,但是没有带来训练精度的提高。
另外,数据集包含数据的广泛性直接影响算法在现实中的表现。现实中任意特定的数据集是有限的,因此需要扩充数据集,使得模型泛化性更好。数据增强算法主要分为基于基本图像处理技术和基于深度学习的数据增强算法。前者主要包括几何变换,如平移、翻转等,后者一般是通过建模转化为一个离散搜索问题,包括Population Based Augmentation[13]、Fast AutoAugment[14]等,接着使用搜索算法来寻找最佳策略,这种方案一般需要大量的计算资源。
本文在以上模型基础上作出改进,使得模型优化速度快,精度提高,同时泛化性更好。
1 相关工作
1.1 传统目标检测算法
传统目标检测方法流程大体是首先进行区域选择,然后进行特征提取,最后进行分类。
(1) 区域选择。最初使用滑动窗口方法遍历,这样可以包含目标所有可能出现的位置。缺点是冗余窗口太多,效率比较低下。
(2) 特征提取。由于目标的姿态、光照强弱不同等外部因素,很难设计一个通用的特征。此阶段常用的特征有SIFT[15]、HOG[16]等。
(3) 分类。使用分类器把提取的特征分类,主要有支持向量机等算法。
传统算法提取特征基本是针对某一类对象专门设计的人工选定特征,不能很好地表达其他类别的目标,现阶段不能满足对性能和速度的要求。
1.2 基于深度学习的目标检测算法
目前高性能目标检测算法是基于深度学习的,基本可以分为单阶段检测和双个阶段检测2个类别。单阶段检测算法在一个步骤内完成分类和定位任务。双阶段目标检测算法首先产生候选区域,然后对候选区域进行分类回归得到类别和感兴趣类别物体的具体位置。近几年很多网络设计技巧使得单阶段检测方法可以达到类似双阶段算法的准确率。
1.2.1 单阶段目标检测算法
单阶段检测算法在一个步骤内产生位置坐标和类别概率。具有代表性的有yolo、ssd、focal loss、yolov3,最新的EfficientDet等。
yolo采用一个卷积网络来实现检测,训练和预测都做到了端到端。主要贡献是算法比较简洁且速度快,做到实时检测;不足是每个单元格仅仅预测2个边界框,而且属于一个类别,对于小物体检测效果欠佳。ssd结合yolo中的回归思想和faster r-cnn中的anchor box机制,取整个特征提取过程中不同分辨率的特征图均做预测,作了6个尺度的预测,损失也是每个尺度损失之和,从而提高算法的检测精度;不足是需要人工设置默认检测框的初始尺度和长宽比,另外在小目标上的表现有待提高。
focal loss针对训练过程中正负样本不均衡问题,在交叉熵损失函数基础上进行修改。减少易分类样本的损失,重点关注难训练的样本,在一定程度上克服了单阶段检测器对于正负样本不平衡时难以训练的问题。
yolov3使用3种不同尺度的特征图来预测边界框,并且结合残差结构提出更健壮的特性提取器。利用多尺度特征进行对象检测,yolov3检测效率高,检测流程简单,背景误检率低。但是相比于RCNN系列,识别物体位置精准性差,召回率低。
EfficientDet设计加权双向特征金字塔网络BiFPN优化多尺度特征融合问题,采用复合系数一致地缩放骨干网络、BiFPN网络、分类/检测框网络和分辨率。在与精度相当的算法相比较时,参数量小1/4~1/8,浮点计算量小1/9.7~1/28,GPU下加速1.4~3.2倍,CPU下加速3.4~8.1倍;与当时最好的SOTA方法比较,EfficientDet-d7模型规模明显更小;在相同硬件条件下GPU计算延迟更小,CPU计算延迟更小,做到了在大范围约束条件下同时满足高精度和高效率。
1.2.2 双阶段目标检测算法
双阶段目标检测算法分2个阶段处理检测问题。第1个阶段是产生候选区域,产生可能包含目标的初始边界框,为后续目标定位服务。第2个阶段对初始边界框分类和位置修正。具有代表性的算法有r-cnn、faster r-cnn、mask r-cnn等。
r-cnn首先使用区域生成算法生成2 000个候选区域,之后使用预训练好的AlexNet网络进行特征提取,对每个类别分别训练一个SVM分类器来判断上面提取到的候选区域的特征是否属于该类。它首次把卷积神经网络成功用于目标检测任务,缺点是训练分为多个步骤,比较繁琐,训练和测试比较耗时,训练占存储空间。
faster r-cnn提出了区域建议网络,实现了快速生成候选区域,同时增加分支可以完成目标检测和语义分割。它提高了检测精度和速度,真正实现端到端,不足是无法达到实时检测,对每个候选区域分类的计算量偏大。
mask r-cnn为faster r-cnn添加并行的掩模分支做到同时实例分割、定位和分类。主干网络使用特征金字塔网络提取特征,由于加入了掩模分支,带来损失值改变,间接增强了主干网络的效果。
2 本文工作
最新的EfficientDet算法通过改进FPN[17]多尺度融合方法并提出根据参数一致的缩放模型,结果非常吸引人。在资源限制条件下,其效率始终比现有技术高出一个数量级。该算法包括参数量不同的EfficientDet-d0到EfficientDet-d7,模型体积逐渐变大,精度逐渐提高,速度逐渐变慢。EfficientDet-d0和yolov性能相似,浮点计算量(floating point operation,FLOPs)是其1/28。对比focal loss和mask-rcnn,EfficientDet-d1实现了接近的性能,但参数量和FLOPs分别是它们的1/8和1/25。EfficientDet-d7取得了目前单尺度单模型最好的效果,同时参数量和FLOPs分别是先前最好方案的1/4和1/9。
本文在EfficientDet基础上做出改进,使得检测效果更加好,效率更高。受限于实验环境,本文主要研究其中参数量和浮点计算量最小的EfficientDet-d0。
2.1 结合AdamW和AdaMod优化器加速收敛
梯度下降法简单来说就是一种寻找目标函数最小化的方法。具体是沿着目标函数J(θ),参数θ∈Rd,梯度相反方向-θJ(θ)来更新参数到达目标函数的(局部)极小值点,包括全量梯度下降(batch gradient descent, BGD)、随机梯度下降(stochastic gradient descent, SGD)、小批量梯度下降(mini-batch gradient descent)、基于动量(Momentum)SGD[18]、Adagrad、Adam,AMSGrad、AdamW[19]和AdaMod[20]等。
全量梯度下降优点在于每次更新都会朝着正确的方向进行,最后能够保证收敛于极值点;其缺点是每次学习时间过长,并且不能投入新数据实时更新模型。随机梯度下降每次随机选择一个样本更新模型参数,每次的训练速度快,但是准确度下降,优化方向有波动。小批量梯度下降每次随机选择n个训练样本,降低了收敛波动性使得收敛更稳定,可以使用矩阵运算进行高效计算,但是选择一个合理的学习速率很难。
基于动量的SGD可以加速优化损失函数并减小震荡,不足是盲目地沿着坡下降,不具备将要上坡时就知道需要减速这类先验知识;Adagrad对每个参数自适应不同的学习速率、低频特征作较大更新,高频特征作较小更新,但是需要计算梯度序列平方和做分式的分母,学习率不断衰减到一个非常小的值;Adam对每一个参数都计算自适应的学习率,更新规则中还引入了历史梯度指数衰减平均值。虽然Adam算法目前成为主流的优化算法,不过在计算机视觉的对象识别、自然语言处理中的机器翻译等很多领域里的最佳成果仍是使用基于动量的SGD得到的;AMSGrad指出使用历史梯度平方的指数移动平均是Adam泛化能力差的原因之一,于是更新规则使用历史梯度平方最大值,实验表明比Adam收敛得快,但最终的训练精确度和训练损失与之表现一致。
AdamW观察到L2正则化对于Adam并非有效甚至不利于优化损失函数,Adam泛化能力没有基于动量的SGD强,其中一个因素是权重衰减。实验表明,分离出权重衰减项提高了Adam的泛化性能。
具体地,对于标准的SGD,权重衰减Weight Decay等同于L2正则化。本文提出了一个简单但是很少有人注意的事实,即现行的所有深度学习框架在处理权重衰减的时候均采用了L2正则的方法,但实际上,L2正则在自适应梯度方法中,如Adam,与权重衰减并不等价。
例如基于动量的SGD优化算法,即
vt=γvt-1+ηgt,
θt+1=θt-vt
(1)
其中:η为学习率;θ为权重参数;gt=θJ(θ),J(θ)为目标函数。网络权重θt更新后乘以衰减率wt,衰减率wt略微小于1,即
θt+1=wtθt
(2)
权重衰减也可以理解为二范数正则化,它取决于添加到损失函数的权重衰减率wt,即
(3)
因此,AdamW从梯度更新中分离出权重衰减项,具体是在参数更新后添加权重衰减项实现。基于动量的SGD结合权重衰减更新如下:
vt=γvt-1+ηgt,
θt+1=θt-vt-ηwtθt
(4)
其中,第2个等式中ηwtθt为解耦后的权重衰减。
类似地,Adam结合权重衰减更新方式如下:
mt=β1mt-1+(1-β1)gt,
(5)
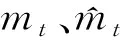
实验表明,分离出权重衰减项提高了Adam的泛化性能,使其在图像分类任务上性能得到提高。另外,它使学习率和权重衰减的选择没有联系,这使得更好的超参数优化成为可能。
AdamW在图像分类数据集上通过实验验证,带解耦权重衰减的Adam优化算法的泛化性能始终优于带L2正则化的Adam。本文认为这样的结果必须在更广泛的任务中进行验证,尤其是正则化比较重要的任务中。因为带解耦权重衰减的Adam没有在目标检测数据集上进行实验验证其有效性,EfficientDet使用的是基于动量的SGD优化器,所以模型训练效率不高。本文为了提高收敛效率,使用AdamW作为优化算法的一部分,加快网络收敛速度。
另外,AdaMod发现网络早期训练阶段存在的极大学习率会妨碍性能并导致不收敛,于是在Adam基础上加入新的超参数描述记忆,这种长期记忆解决了自适应学习率的异常过大数值,并且不需要warmup模式,对初始超参数不敏感,训练曲线更平滑。
AdaMod保持了自适应学习率自身的指数长期平均值,并在整个训练过程中用该值修剪任何过高的适应率,从而提高了优化器的收敛性,无需进行预热,并且降低了对学习率的敏感性。记忆的程度由一个新的参数β3控制。该种长期记忆和从中的裁剪(限制大小)解决了许多自适应优化器(Adam)的主要问题,即缺乏长期记忆可能会导致不收敛,优化器由于自适应学习率而达到局部最优。
具体来说,在Adam中添加新参数β3操作如下:
st=β3st-1+(1-β3)ηt
(6)
其中:ηt为Adam在第t步计算得到的学习率;st为当前步骤平滑值。新参数β3就是记忆长短的度量。当β3=0.9时,记忆平均范围为10个周期;当β3=0.999时,记忆平均范围为1 000个周期。根据β3得到平滑值st和之前s0,s1,…,st-1的关系:
st=(1-β3)[st-1+β3st-2+
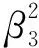
(7)
显然,当β3=0时,AdaMod完全等价于Adam。
计算出当前平滑值st后,在它和当前Adam计算得到的学习率ηt中选出一个最小值,即
(8)
从而有效避免了学习率过大的情况。该项操作可以看作是逐个控制学习率的大小,从而使输出受到当前平滑值的限制。
实验表明,AdaMod不需要warmup模式。同时实验例证了SGDM和Adam的训练结果均依赖于初始学习率的选择,AdaMod即使学习率相差2个数量级,也能收敛于同一结果,说明对学习率超参数不敏感。通过长期记忆和从中裁剪在整个训练过程中提高了稳定性,通常在最终结果上优于Adam,训练曲线更平滑。然而它也有局限性,尽管AdaMod胜过Adam,但是在更长的训练周期下,基于动量的SGD优化算法仍然可以胜过AdaMod。
考虑到AdamW实验验证的带解耦权重衰减的Adam优化算法的泛化性能始终好于带L2正则化的Adam,同时结合AdaMod不需要warmup、对初始学习率不敏感和训练曲线更平滑的优点及较长训练周期下不如基于动量的SGD。本文采取训练前期使用AdaMod训练,后期使用AdamW优化器训练的优化方案,具体见实验部分。
2.2 使用mixup数据增强方案
深度学习在计算机视觉任务许多方面都表现出良好的性能,然而严重依赖大量数据增加可靠性同时避免过拟合。许多应用领域无法利用大量数据,如医学图像分析。数据增强技术可以提高训练数据集的大小和质量,从而可以使用它们构建更好的深度学习模型。具体通过数据增强实现数据更复杂的表征,从而减小验证集和训练集以及最终测试集的差距,使网络更好地学习迁移数据集上的数据分布。
数据增强算法主要分为基于基本图像处理技术和基于深度学习2类。基于基本图像处理的数据增强主要包括几何变换、翻转、色彩空间、裁剪、旋转、平移、噪声、色彩空间转换等;此外基本增强还包括基于滤波器核的图像增强、随机擦除增强、混合图像等。基于深度学习的数据增强算法主要包括特征空间增强,基于生成式对抗网络(generative adversarial networks,GAN)的数据增强、神经风格转换等。
基于深度学习的数据增强一般建模为一个离散搜索问题,需要创建一个数据增强策略的搜索空间,该搜索空间中的一个策略包含许多子策略,为每个小批量(mini-batch)中的每张图像随机选择一个子策略。每个子策略由2个操作组成,每个操作都是类似平移、旋转或剪切的图像处理函数,以及应用这些函数的概率和幅度(magnitude)。一般地,此类方法需要消耗大量的计算资源,如Population Based Augmentation、Fast AutoAugment等。对于普通用户而言在计算资源这一方面难以满足。
相反地,基本图像处理技术的数据增强方法实现简单,增加的计算量很少。考虑到大部分数据增强没有考虑不同样本不同类之间的关联,同时mixup[21]现阶段使用在目标检测任务上比较少。现有目标检测算法往往是在特定公开数据集上进行训练和评估,这些都属于高质量的图像,实际场景中,目标通常会受光照强度、遮挡等因素影响。为了增加实际复杂场景下的检测精度,本文采用混合图像里面表现较好的mixup,属于混合图像。
文献[21]提出了一种和数据本身无关的线性插值方案,即
(9)

图1 两图混合示例
3 仿真实验与分析
3.1 评价指标
Positive和Negative代表模型的判断结果,True和False评价模型的判断结果是否正确。真正例(true positive, TP):被判定为正样本,事实上也是正样本;假正例(false positive, FP):被判定为正样本,但事实上是负样本;真负例(true negative, TN):被判定为负样本,事实上也是负样本;假负例(false negative, FN):被判定为负样本,但事实上是正样本。以识别大雁和飞机分类系统举例,假定系统目的是识别飞机,TP就是飞机的图片被正确识别为飞机,FN就是飞机的图片系统错误地分类成大雁。
精确率Precision为:
(10)
精确率就是所有被识别出来的飞机中,真正的飞机所占的比例。
召回率Recall为:
(11)
召回率就是被正确识别出来的飞机个数与测试集中所有真实飞机的个数的比值。
准确率Accuracy为:
(12)
下面介绍矩形框交并比(intersection-over-union, IoU)。二维平面上2个矩形框记做A和B,S代表面积。IoU的定义为2个矩形框面积的交集和并集的比值,即
(13)
交并比范围为0~1。
对于目标检测来说,当预测框与真实框的IoU值大于某个阈值时,该预测框才被认定为真样例,反之就是假样例。本文先固定IoU阈值为0.5。
检测网络输出预测框的类别、置信度得分、检测框(预测框)的大小和位置。设置不同的置信度阈值,会得到不同数量的检测框。阈值高,得到检测框数量少;阈值低,得到检测框数量多。
下面首先选定某一个需要检测的类别,定义精确率Precision和召回率Recall。
(1) 计算精确率Precision。固定好IoU阈值,设置预测框置信度阈值会得到一组检测框,数量为TP+FP。根据IoU阈值划分检测框,大于IoU阈值的检测框划分为TP;否则划分为FP。根据公式在类别内计算精确率Precision。
(2) 计算召回率Recall。因为TP+FN是所有的人工标注值(已知的检测框的数量),根据公式计算即可。召回率也是在特定的类别中计算的。
(3) Precision-Recall曲线。设置不同的预测框置信度阈值会得到一组精确率Precision和召回率Recall,以召回率Recall为横轴,以精确率Precision为纵轴得到的曲线就是Precision-Recall曲线。需要注意的是对于检测系统来说,每个需要检测的类别都会得到一条Precision-Recall曲线。
某个类别的平均精度(average precision,AP)就是该类别Precision-Recall曲线下面的面积。假定最开始选定的IoU阈值为0.50,记作AP50,最开始选定的IoU阈值为0.75,记作AP75,现在比较通用的计算方法为AP根据10个IoU阈值(0.50、0.55、0.60、0.65、0.70、0.75、0.80、0.85、0.90、0.95)计算出对应AP取均值就是最终这个类别的AP值。
特定数据集下的均值平均精度(mean average precision, mAP)是目标检测系统中需要检测此数据集包含的各个类别获得的AP的平均值。则AP50得到mAP50,AP75得到mAP75,或者10个IoU阈值计算出的AP得到mAP。
3.2 实验数据集
在目标检测方面,过去10 a中已经发布了许多著名的数据集和基准测试,包括MS COCO检测挑战赛数据集[22]、PASCAL VOC挑战赛数据集[23-24](VOC2007、VOC2012)等通用目标检测数据集。
PASCAL VOC挑战赛是早期计算机视觉界最重要的比赛之一。PASCAL VOC中包含多种任务,包括图像分类、目标检测、语义分割和动作检测。2种版本的PASCAL VOC主要用于对象检测,即VOC07和VOC12,前者由5×103训练图像加上12×103标注的物体组成,后者由11×103训练图像加上27×103标注的物体组成。这2个数据集中标注了生活中常见的20类对象。
MS-COCO是目前最具挑战性的目标检测数据集。如MS-COCO-17包含来自80个类别的164×103图像和897×103带注释的对象。MS-COCO包含更多的小对象(面积小于图像的1%)和比VOC和ILSVRC更密集的定位对象。与VOC相比,MS-COCO最大的进步是除了边框标注外,每个对象都进一步使用实例分割进行标记,以帮助精确定位。
3.3 实验配置
受限于计算资源,本文使用VOC07+12数据集,在VOC2007和VOC2012的train+val集(16 551张)上训练,在VOC2007的test集(4 952张)上测试。只在EfficientDet-d0上作实验验证,基础网络是efficientnet[25]提出的efficientnet-b0。
本文具体训练策略如下:因为AdaMod无需预热,所以训练前期使用AdaMod训练200个epoch;后期用AdamW优化器训练了60个epoch;260个epoch后加入mixup图像增强训练至480个epoch后,不再采用mixup作收敛训练至500个epoch,此时损失趋于稳定,并且在达到600个epoch并没有大的提升。
超参数设置如下:前180个epoch学习率为0.001,后面的为1×10-4,权重衰减5×10-6,动量参数为0.9。损失函数选用focal loss,使用Pytorch1.3.0框架。
3.4 实验结果分析
训练260个批次后模型在VOC07测试集上mAP为57.7%,500个epoch mAP达到71.7%,此时损失趋于稳定,并且在之后达到600个epoch并没有大的提升。IOU阈值为0.5时mAP和各类AP见表1所列。
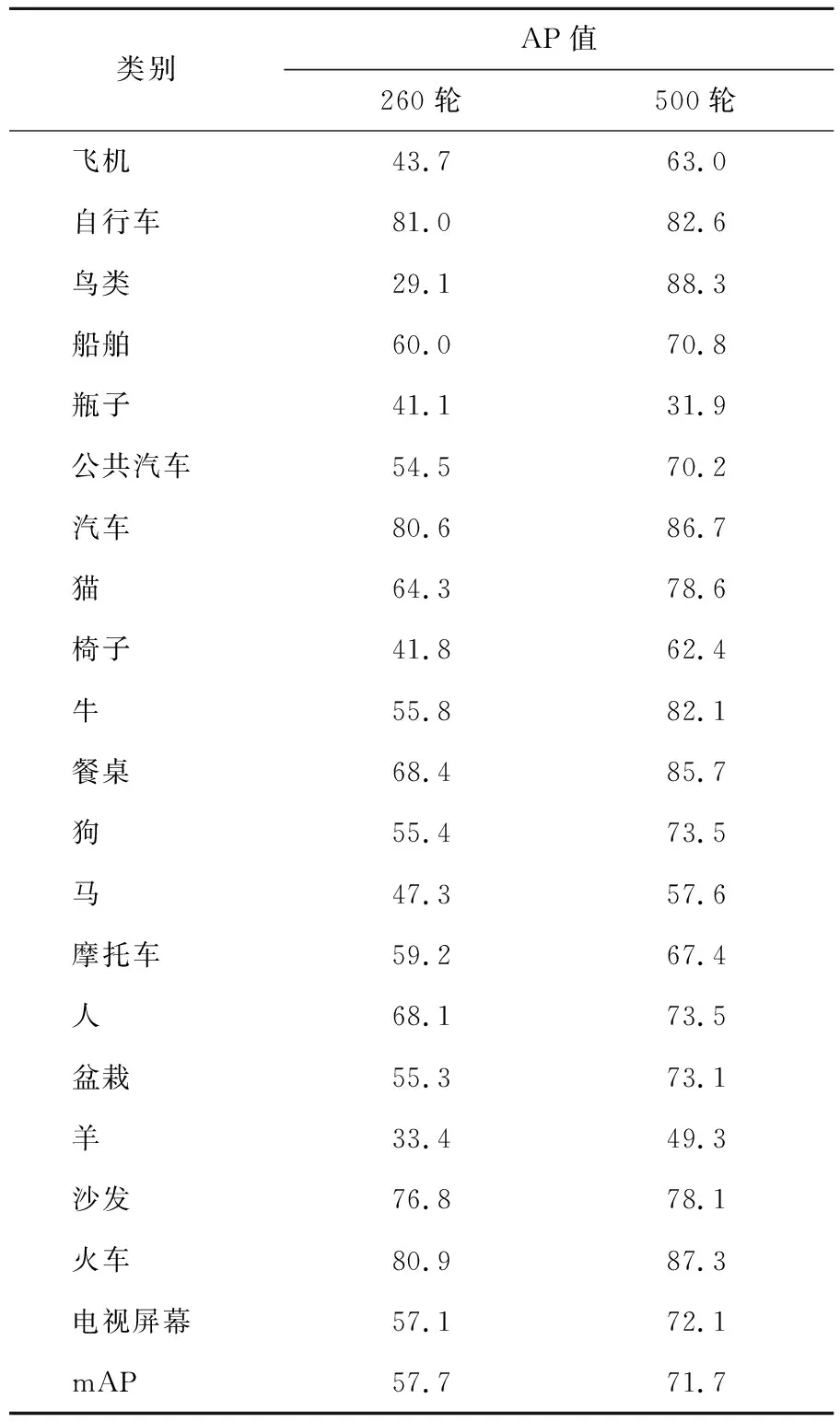
表1 epoch 260、epoch 500的AP和mAP结果 单位:%
检测速度方面,VOC07测试集共有4 952张图片,单个NVIDIA GeForce GTX 1070检测所有图像需要182.3 s,每张图片平均检测用时0.036 s,平均每秒检测图片数目(frames per second,FPS)为27.2,基本达到实时检测的效果。
综合FPS、模型参数量和模型浮点运算次数, faster rcnn和r-fcn[26]的参数量、浮点运算量很大,同时做不到实时检测。yolo、ssd、yolov2[27]虽然做到了实时检测,但是参数量和浮点运算量依然比较大。tiny-yolo做到了较小的参数量和浮点运算量,但是均值平均精度mAP比较差。pelee[28]和dsod-small[29]综合3个方面比较好。本文使用的EfficientDet-d0参数量只有3.9 M,是最少的。
综合来说EfficientDet-d0是目前较小检测算法里面综合性能较好的,见表2所列。表2中其他算法选定图像输入大小、基础网络后得到的FPS、参数量、浮点运算量和mAP分别来源于对应文献的计算结果和Tiny-DSOD[30]总结。
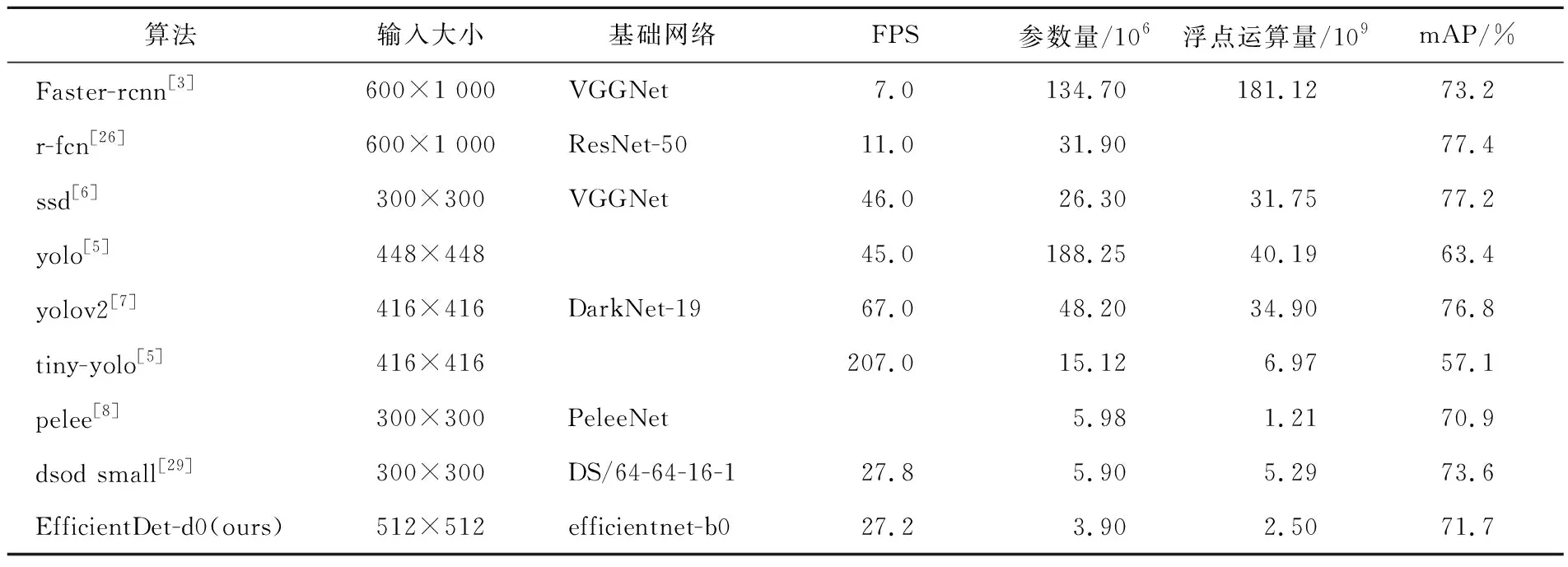
表2 不同检测算法FPS、模型参数量、浮点计算量和PASCAL VOC2007测试集mAP对比
4 结 论
本文首先分析传统的和基于深度学习的具有代表性的目标检测算法各自优势;接着概括梯度下降法各种变体优化算法对应的优缺点,根据以上总结选择结合使用AdaMod和AdamW优化器作为本文的神经网络优化策略;此外考虑到深度神经网络性能表现和数据集有较大联系,本文罗列并分析现阶段主流的数据增强方法并结合实际分析其可行性,选择使用基本图像处理技术中混合图像做数据增强;最后通过VOC07+12数据集上的实验结果,验证本文应用的优化策略和数据增强方案有利于网络收敛得更快更好,并且泛化性能得到提高,做到了速度、精度和泛化性能兼备。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
少儿画王(3-6岁)(2020年4期)2020-09-13
智能计算机与应用(2020年4期)2020-08-31
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
东方教育(2018年20期)2018-08-22
