
基于Q-learning的离散时间多智能体系统一致性
2021-07-31 12:41朱志斌王付永尹艳辉刘忠信陈增强
控制理论与应用 2021年7期
朱志斌,王付永,尹艳辉,刘忠信,陈增强
(南开大学人工智能学院,天津 300350;天津市智能机器人技术重点实验室,天津 300350)
1 引言
近年来,随着计算机技术和网络技术的不断发展,有关多智能体系统协同控制方面的研究越来越多.多智能体系统具有单个智能体无法比拟的优势,可以完成单个智能体无法完成的任务,因而具有更广泛的应用,例如:无人飞行器编队控制、卫星姿态控制和移动多机器人等[1–5].
多智能体系统(multi-agent systems,MASs)的一致性是复杂动力学系统中一个具有理论和实践意义的重要问题.现有的一致性问题主要分为两类:无领导者多智能体系统的一致性和领导–跟随多智能体系统的一致性.对于无领导者的多智能体系统,当所有智能体的状态收敛至同一值时,则系统达到一致;对于领导–跟随的多智能体系统,当系统中所有跟随者的状态趋于领导者的状态,则系统达到一致.基于多智能体系统的一致性和协同控制方面的研究[6],文献[7]利用动态输出反馈的控制方法研究了在固定和切换拓扑下多智能体系统的一致性,并提出了相应的一致性算法.为了解决线性异构多智能体系统在切换拓扑下的一致性问题,文献[8]设计了一种分布式分级控制协议.对于二阶非线性多智能体系统的一致性问题,文献[9]推导出固定网络拓扑在部分间歇通信的情况下达到一致的充分条件.假设系统同时存在网络时延与状态时延,文献[10]研究了一类二阶马尔可夫切换多智能体系统的一致性问题.然而,上述研究均是在模型参数已知的条件下,而面对现实中复杂的物理系统,绝对精确的数学模型是难以得到的.所以,为了避免建模难度大或者模型未知的问题,设计一种基于数据的分布式控制律则更为有效.
强化学习作为机器学习的一种方法[11–12],以环境反馈作为输入并通过不断的试错来寻找最优的行为策略.不同于监督学习,智能体并不知道如何做出正确的行为策略,但可以通过强化学习的方法对行为策略进行评估,并根据有效反馈信息对行为策略进行改善.同时,强化学习的奖励函数对系统信息的需求更少,也更容易设计,因此,强化学习适合解决复杂的控制问题.在有关强化学习的基础数学研究取得突破之后,对强化学习的研究也越来越多[13–14].
强化学习还可以解决最优控制问题,例如带有约束的最优控制[15–16]、带有时延的最优控制[17–18]、最优跟踪控制[19–20]、最优一致性控制[21]等.作为强化学习中一种重要的方法,Q-leaning是一种无模型的学习方法.目前,已经有很多关于Q-learning的研究,例如:跟踪控制[22]、零和博弈[23]、鲁棒控制[24]等.
经过上述讨论可知,在系统模型已知的前提下,文献[7–10]可以很好地解决多智能体系统的一致性问题,但是当系统模型未知时,解决这一问题将变得困难.为了避免复杂的机理建模,本文提出一种Q-learning方法解决离散时间多智能体系统的一致性问题,主要贡献如下:
1) 将Q-learning方法从单智能体拓展应用到多智能体系统中,解决了离散时间多智能体系统模型未知时的一致性控制问题;
2) 对于多智能体强化学习,本文在文献[26]的基础上对值函数的结构进行了优化改进,提出了一种新的关于误差的值函数.
本文结构安排如下:第2部分将给出基础代数图理论和问题描述;第3部分将给出的Q-learning一致性算法,并对所提算法进行了收敛性和稳定性分析;第4部分将通过计算机仿真验证所提算法的有效性;最后,第5部分将对全文工作进行总结和展望.
2 问题描述
2.1 代数图论
令G=(V,E,A)表示一个有向加权图.其中:V={v1,v2,···,vN}表示具有N个节点的集合,E ⊆V ×V表示边集,节点下标集合为I={1,2,···,N}.定义矩阵A=[aij]是图G的非负邻接矩阵,矩阵元素aij≥0表示节点vi和vj之间的连接权重.当节点vi可以收到来自节点vj的信息传递时,则aij≥0;否则aij=0,本文所讨论的图中,aii=0,∀i,j ∈I.如果aij=aji,则称图G是无向的,显然无向图对应的加权邻接矩阵A=[aij]是对称的.节点vi的邻居下标集合为Ni={j|vj ∈V(vj,vi)∈E}且邻居的个数表示为|Ni|.定义度矩阵为D=diag{di,i=1,2,···,N},为矩阵A的第i行元素的和,节点vi的入度和出度分别定义为.若图G中每个节点的入度都等于出度,则称图G是平衡图.定义图G的Laplace矩阵为L=D −A.对于图中的节点vi和vj,存在有序下标集合{k1,k2,···,kl},若,则称节点vi和vj之间存在一条有向连接路径.如果对于图中任意的两个节点vi和vj之间存在至少一条有向连接路径,则称图G是强连通的.
2.2 问题描述
假设多智能体系统由N个智能体组成,且智能体间的通信网络拓扑是固定、无向和连通的.给出下面的离散时间系统的一致性算法:
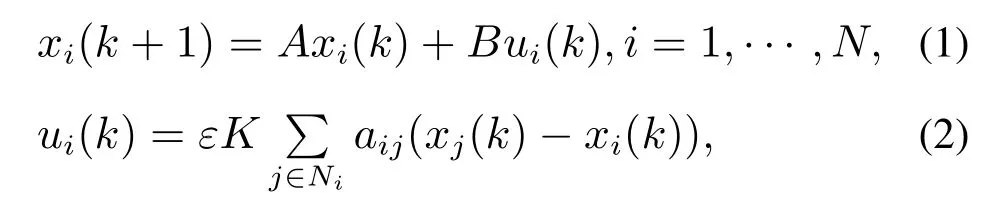
其 中:A ∈Rn×n,B ∈Rn×m和K ∈Rm×n,xi(k)∈Rn是智能体i在k=1,2,3,···时刻的状态,ui(k)∈Rm是其控制律,ε ∈(0,1/Δ)是系统的控制参数,Δ=为网络节点的最大出度.
假设1假设本文中的系统模型是确定且未知的.
控制律(2)可以用每个智能体自身信息和其邻居智能体的信息求得,那么每个智能体和其邻居智能体的局部误差定义如下:
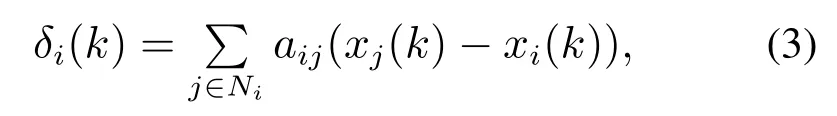
根据式(3)可以得到全局误差向量
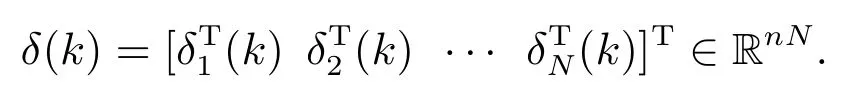
本文目标是求解最优控制律(2),使得当k →∞时,‖δ(k)‖→0,所有智能体的状态达到一致,即

各个智能体的最终状态满足[6]
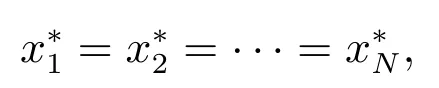
同时使后面第2.3节中的目标函数式(4)最小.
2.3 值函数的定义
对于每个智能体定义一个如下所示的目标函数:
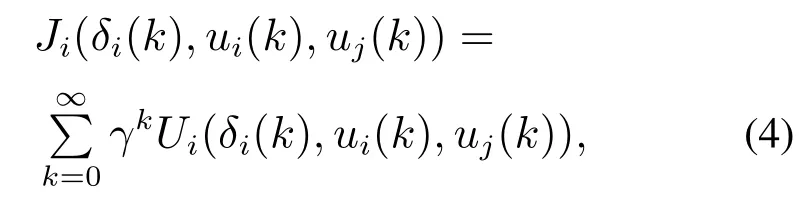
上式中的效用函数Ui(δi(k),ui(k),uj(k))定义如下:
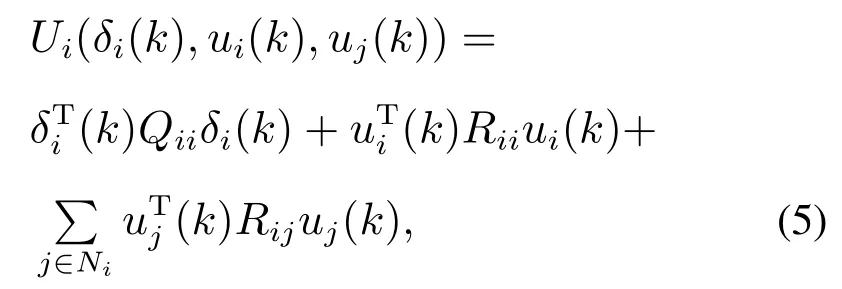
其中:Qii >0∈Rn×n,而Rii >0∈Rm×m,Rij >0∈Rm×m均为正定对称矩阵,0<γ≤1为折扣因子.
对每个智能体及其邻居智能体给定控制律(ui(l),uj(l)),每个智能体的值函数定义如下

注1目标函数(4)用来评价智能体i的性能,智能体i的值函数(6)可以收集局部信息.
定义1(容许控制[25]) 如果控制律ui(k),∀i ∈I不仅可以使系统稳定,还可以保证目标函数有界,则称其为容许控制.
在满足容许控制律的条件下,值函数可以改写成贝尔曼方程的形式
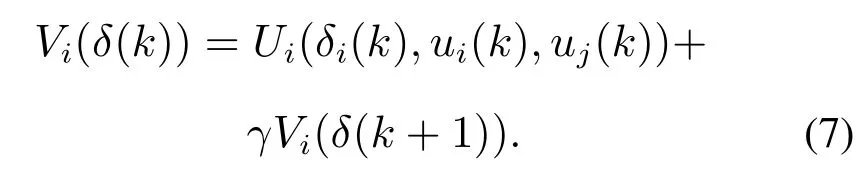
引理1(二次型值函数) 在满足容许控制律的条件下,智能体i的值函数式(6)可以改写为如下二次型的形式
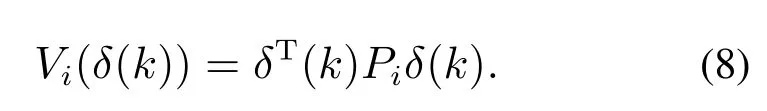
证此引理的证明可以通过以下步骤完成:
步骤1根据式(3),智能体i和邻居智能体的局部误差动力学方程为
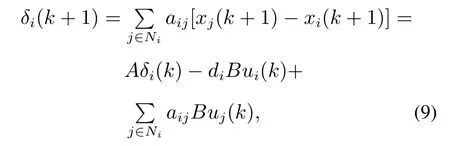
根据式(9)可得
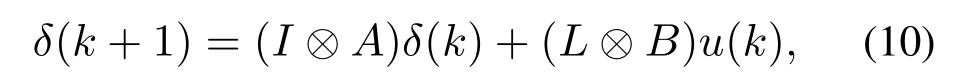

将式(11)代入式(10),得到

步骤2定义两个块对角矩阵
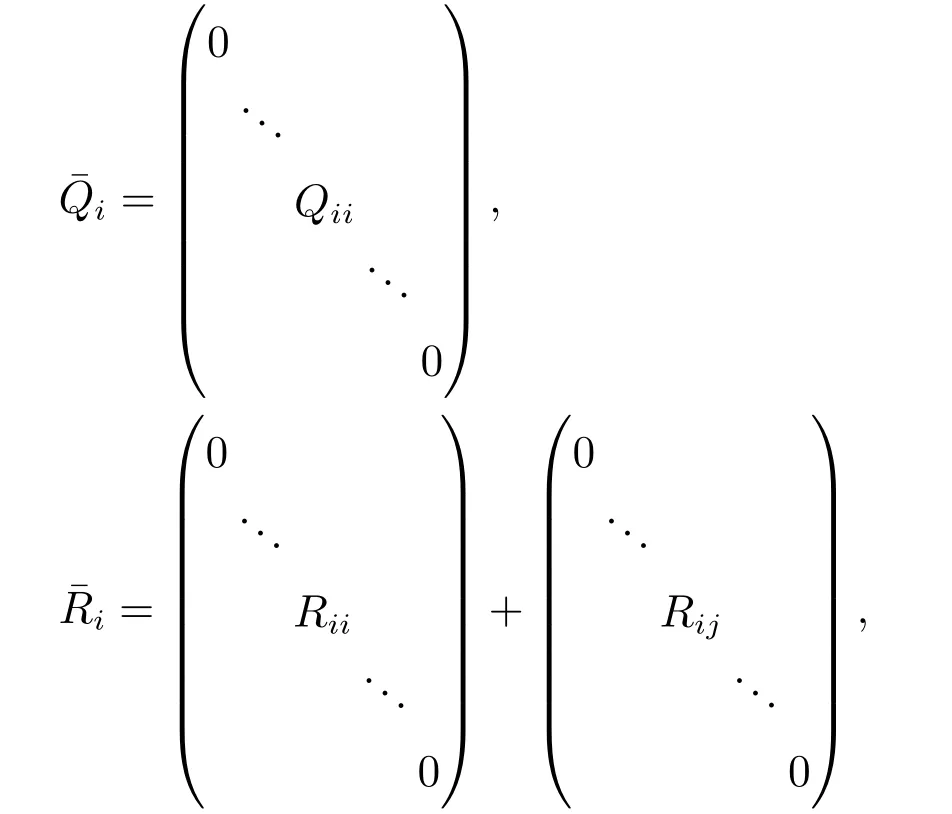
步骤3根据式(11)–(12),式(6)可以改写为
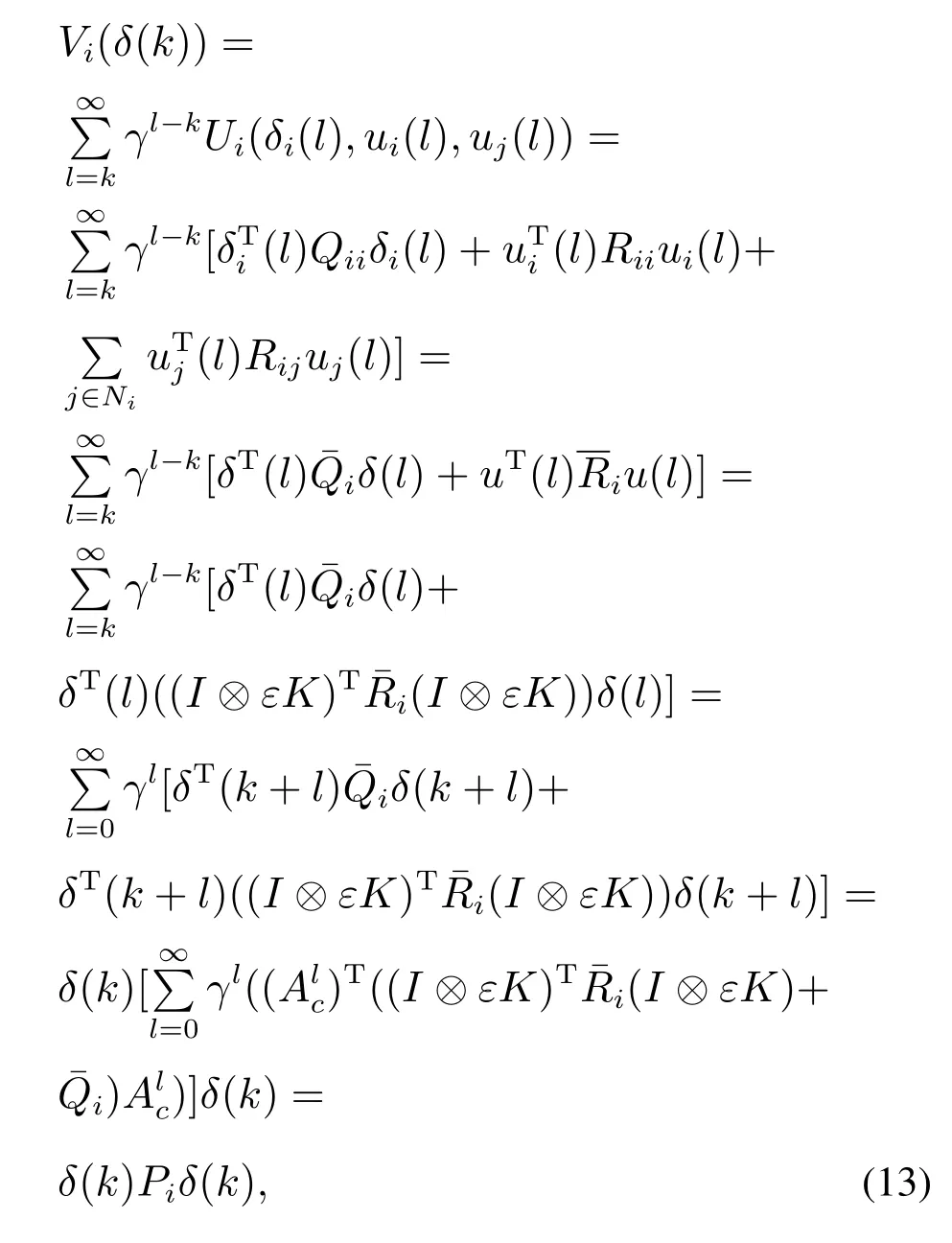
其中
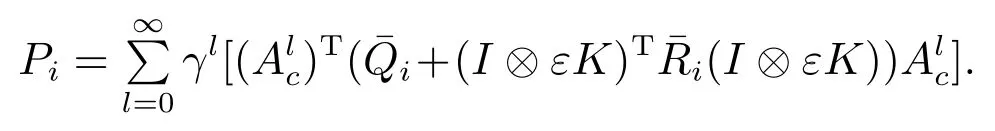
证毕.
基于贝尔曼最优性原则,智能体i的最优值函数满足离散时间的Hamilton-Jacobi-Bellman(HJB)方程

定义2(纳什均衡解[25]) 如果包含N个控制律的控制序列是N个智能体博弈的全局纳什均衡解,那么满足
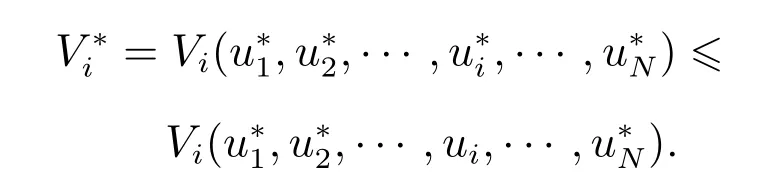
根据定义2,智能体i的耦合离散时间HJB方程为

3 基于Q-learning的多智能体系统的一致性算法
对于模型未知的多智能体系统,已有的基于模型的算法是无效的.尽管可以通过系统信息建立模型,但是实际系统中的不确定因素导致难以建立准确的系统模型.由于Q-learning算法不需要构建系统模型,可以利用多智能体系统产生的数据在线实时更新控制律,故本文采用此方法解决多智能体系统一致性问题.
3.1 Q-learning算法
基于贝尔曼方程的离散时间Q函数定义如下:
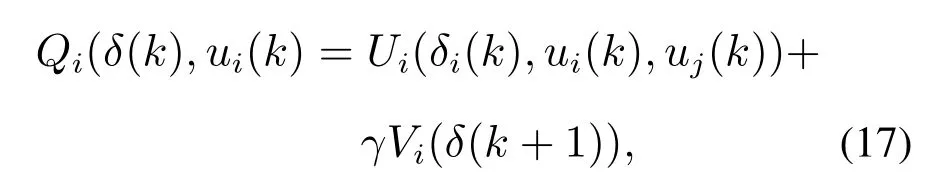
其中Q函数由智能体i及其邻居智能体的状态信息和控制律构成.根据式(17),可以得到
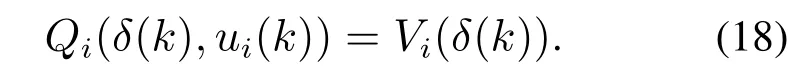
构造Q函数的二次型的形式
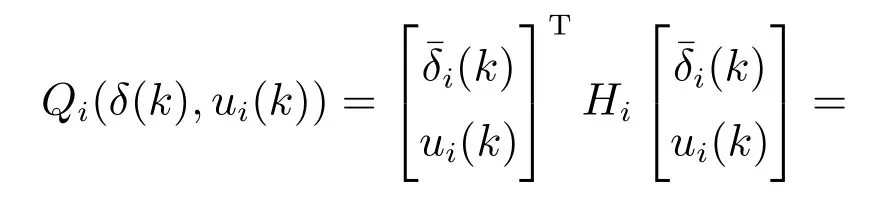

由式(21)(23)可知,在策略评估和策略迭代时不需要任何系统模型信息.矩阵Hi可以通过最小二乘法实时迭代求解[26].将策略迭代直接应用到所提Q-learning算法中,给出如下算法:
步骤1初始化:对于每个智能体i,给定初始容许控制律u0i(k),∀i=1,2,···,N;r=0,r表示迭代次数,总的迭代次数为R;
步骤2策略评估:根据式(23)迭代求解每个智能体i的第r+1次矩阵Hi
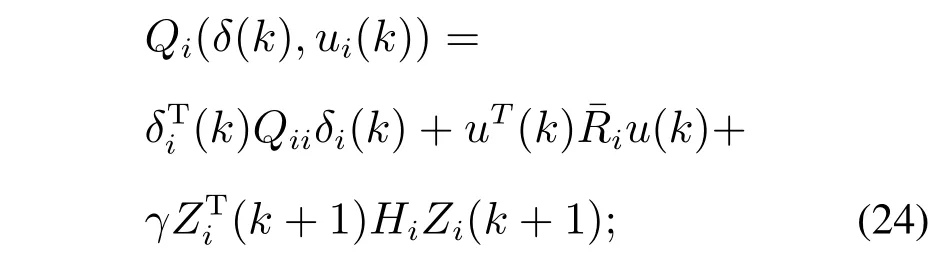
步骤3策略迭代:利用求得的矩阵Hi更新第r+1迭代控制律

步骤4若r=R,停止迭代;否则,r=r+1并返回步骤2.
注2为了确保数据训练过程中对状态空间有更充分的探索,策略迭代算法一般需要一定的激励条件ξ,ξ是会随着迭代次数的增加而逐渐衰减至0的.
3.2 算法的收敛性分析
为了保证系统稳定,下面对所提的算法进行收敛性分析.
假设2假设智能体之间的通信网络拓扑图G是固定、无向且连通的.
引理2[27]对i ∈I和∀r ∈N值函数和控制律分别通过式(24)–(25)进行更新.如果智能体i给定的初始控制律是容许的,那么迭代控制律也是容许的,则不仅可以使系统(1)稳定,还可以保证目标函数(4)有界.
引理3对于∀i ∈I和∀r ∈N,给定一个初始容许控制律(2),即,分别通过式(24)–(25)计算和,可以得到函数是单调非递增的,即
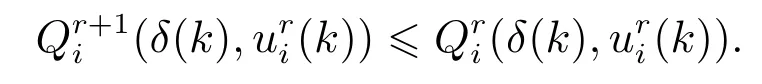
证此引理的证明可以通过以下步骤完成:
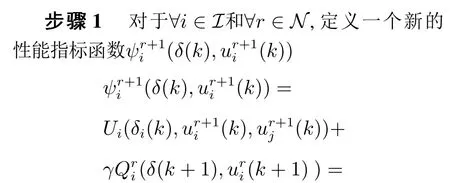




3.3 稳定性分析
定理2在假设1和假设2成立的条件下,系统(1)的每个智能体i的和分别满足耦合离散时间HJB方程(16)和最优控制律(15).智能体i和其邻居的局部误差δi(k)是渐近稳定的,并且当k →∞时,δi(k)→0,此时所有智能体的状态达到一致.
证根据式(21)可以得到
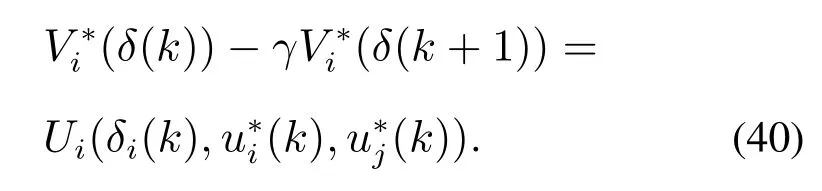
定义Lyapunov函数的差分
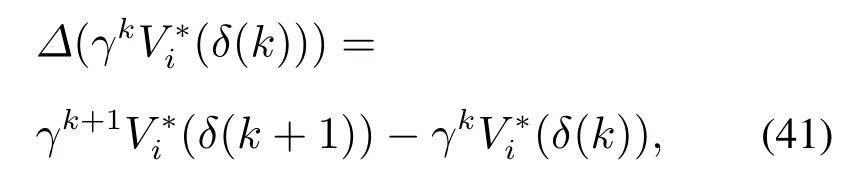
根据式(40),式(41)可改写为
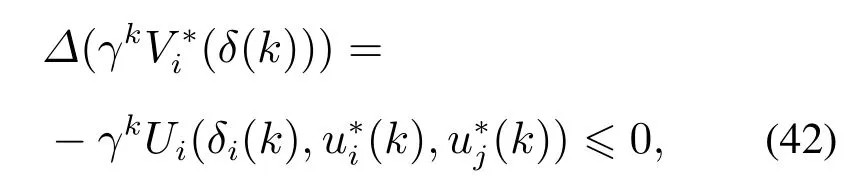
上述式(42)表明智能体i和其邻居的误差δi(k)是渐近稳定的,即当k →∞,δi(k)→0,i=1,2,···,N.最终,所有智能体的状态将趋于一致.
证毕.
4 仿真
本节用MATLAB仿真验证所提算法的有效性.假设多智能体系统的通信网络拓扑如图1所示,该网络是一个固定无向图,且系统模型未知.5个顶点分别代表5个智能体,智能体之间的连接权值均为1.每个智能体的动力学方程满足式(1),令
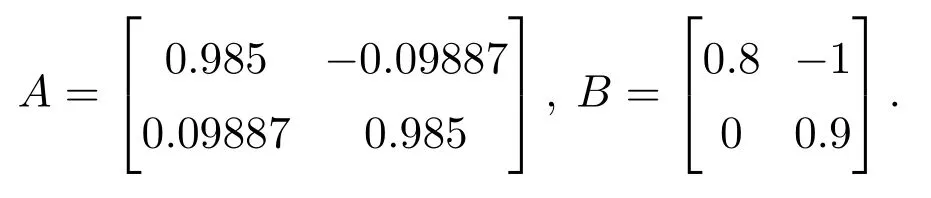

图1 多智能体系统的通信拓扑Fig.1 The communication topology of multi-agent systems

下面的图2给出了多智能体系统的一致性误差动态曲线,可以看出在前1000次的迭代过程中,由于缺少模型信息,5个智能体之间的一致性误差较大;在迭代至1000次至2000次时,随着不断的获取邻居智能体的信息并学习过往积累的数据信息,智能体之间的一致性误差开始减小.迭代至2000次之后,智能体之间的一致性误差逐渐趋于0.
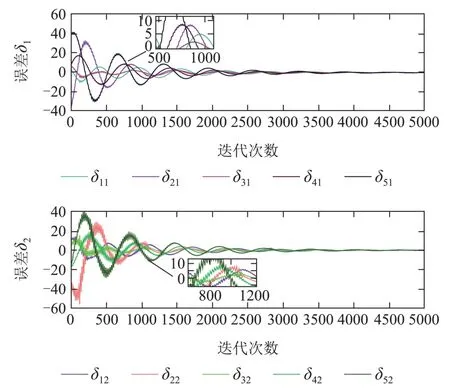
图2 智能体的一致性误差Fig.2 The consensus error of the MASs
下面的图3给出了关于控制律的动态曲线,可以看出在前1200次迭代过程中,由于迭代次数少还无法学习到较好的控制策略,智能体的控制律还不理想.但值得注意的是,因为选取了初始容许控制律,所以控制律的更新始终是有界的.从1500次迭代开始,根据过往积累的数据信息和邻居智能体的信息,智能体开始逐渐学习并优化控制律,但智能体之间的状态误差是非0的,所以智能体的控制律需要不断更新且不为0.
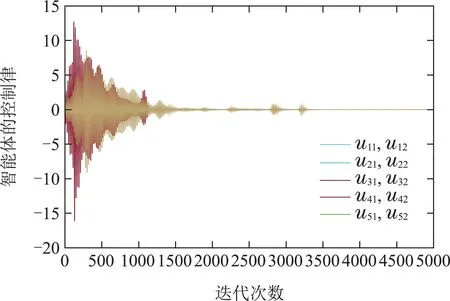
图3 智能体的控制律Fig.3 The controller of the MASs
下面的图4给出了每个智能体状态的动态变化曲线,可以看出在迭代至0~1500次时,由于缺少模型信息,智能体的状态无法达到一致;从1500次开始,经过学习过往积累的数据信息不断更新控制律ui(k),每个智能体的状态开始逐渐趋于一致.图5是智能体状态的三维坐标图.

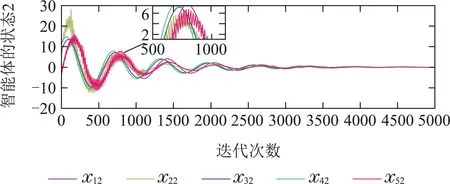
图4 智能体的状态Fig.4 The dynamics of the MASs

图5 智能体状态三维坐标图Fig.5 3-D phase plane plot of the dynamics of the MASs
5 结论
本文研究在系统模型未知的情况下一类离散时间多智能体系统的一致性问题.论文提出了一种Q-learning的方法,这种方法避免了复杂的系统建模与HJB方程求解,利用系统数据进行策略迭代得到理想控制律,实现多智能体系统的状态一致.为了保证系统稳定,论文给出了所提算法的收敛性和稳定性分析.最后,通过MATLAB仿真验证了所提方法的有效性.未来研究工作可以针对如何利用强化学习方法解决一类模型随机的多智能体系统的一致性问题进行研究.
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
教学考试(高考物理)(2021年5期)2021-11-08
历史教学问题(2021年4期)2021-11-05
今日中国·法文版(2020年7期)2020-07-04
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
山东青年(2016年2期)2016-02-28
山东青年(2016年1期)2016-02-28
燕山大学学报(2015年4期)2015-12-25
