
基于改进Elman神经网络的制糖企业原糖需求预测模型
2021-07-30 10:34:08李洋莹陈智军张子豪
计算机应用 2021年7期
李洋莹,陈智军,张子豪,游 兰
(湖北大学计算机与信息工程学院,武汉 430062)
0 引言
制糖业是多类行业的基础工业,在我国的国民经济中具有不可或缺的地位[1]。制糖原材料的供需平衡直接影响着企业生产效率,通过人工智能方法针对原材料供需规律建模,是实现企业高效生产的有效方法,也是制造型企业智能化转型的重要信息化指标之一。
需求量预测是一种定量预测,较为常用的预测手段为时间序列预测法。时间序列预测法由数学家Yule 在1927 年提出,自回归模型(Auto-Regressive Model,AR)可用来预测未来市场变化规律[2-3],随后自回归移动平均模型(Auto-Regressive Moving Average Model,ARMA)和 .动 .均模型(Moving Average model,MA)的提出则揭开了国内外学者研究时间序列的序幕[4]。时间序列预测旨在通过研究对象本身所具有的数据变化规律,在时间基础上拟合出数据的规律性,在解决线性时间序列的拟合问题上有着出色表现。但现实中多为非线性复杂问题,相较于传统的时间序列预测方法[5-7],引入神经网络可以更好地解决非线性时间序列的拟合问题。武乃虎等[8]采用时间序列和神经网络改进模型,解决了风速和风电功率之间存在的非线性关系对预测精度的影响;Wang 等[9]提出了基于长短期记忆的顺序神经网络预测模型,可用于预测给定页面深度处的广告将在用户屏幕上显示特定停留时间的概率。
目前,国内外需求量预测相关研究已积累了一些成果,但较少考虑行业特点对需求量预测的影响,准确性有待提高;同时,食品加工业中原材料采购主要以周为周期,而现有研究多以月和年为预测时间长度,导致现有方法难以满足预测的时效性要求。针对上述问题,本文基于制糖企业原材料供需错位与时间特征因素的关系分析,充分考虑了以周为单位的原糖采购量预测的时效性要求,在多时间粒度下提出一种时间特征关联的使用改进布谷鸟搜索(Modified Cuckoo Search,MCS)算法优化的Elman神经网络需求量预测模型TMCS-ENN(Temporal feature-correlated MCS-Elman Neural Network)。
本文主要工作如下:
1)提出了自适应学习速率公式优化Elman 神经网络(Elman Neural Network,ENN)学习速率。在神经网络迭代过程中,不断将当前误差与上一次误差对比,自适应地调整学习速率逼近最优解,提升了ENN 的收敛速度,并增强了其局部搜索能力。
2)通过对历史大量数据的特征分析,并结合制糖企业原材料购买的时间相关性与滞后性规律,将历史数据进行基于周粒度的短时数据切片设计,并以节假日作为重要特征因子优化ENN 的模型预测,提高了模型预测精度。在多时间粒度下进行对比实验,并在短时预测的精细时间粒度下满足了制糖企业对于原材料购买的时效性要求。
3)提出了改进布谷鸟搜索(MCS)算法优化ENN 的权值和阈值。引入自适应的寄生失败概率和自适应的步长控制量公式,使得算法在更新过程中充分利用鸟巢位置信息,加强局部搜索,改善了算法的收敛速度和解的质量。
4)TMCS-ENN 可以较好地为原糖需求量购买提供精准预测,而且该方法可以迁移到其他时间相关的需求预测场景进行预测,能为企业原材料需求预测提供重要的参考。
1 面向原糖预测的Elman神经网络
1.1 研究思路
制糖原材料需求量预测的研究是一个典型的时间序列预测问题。对于制糖企业,在日常的生产活动中制糖原材料的需求量通常受到购买价格、产品销量以及采购时间等多方条件限制,使其具有较为鲜明的非线性特点。针对非线性问题,传统时间序列预测模型具有一定局限性,导致最终结果往往不佳[10-11]。神经网络的出现弥补了传统时序预测模型的不足,因此,本文选择神经网络作为原糖需求量预测的基础模型。
一般的静态神经网络的输出仅依赖于当前输入,不具备记忆性,因此对解决具有时序依赖关系的时间序列预测问题,效果往往不够理想。为使系统具有记忆性,达到适应时变的目的,Elman 神经网络(ENN)[12-13]具有内部反馈与前馈相连的结构特点,从而具备记忆特性[14-15]。图1 展示了ENN 的模型结构。ENN 将承接层作为隐含层中增加的一步演示算子,通过收集与存储隐含层的输出值,解决了神经网络不具有动态记忆功能的问题。
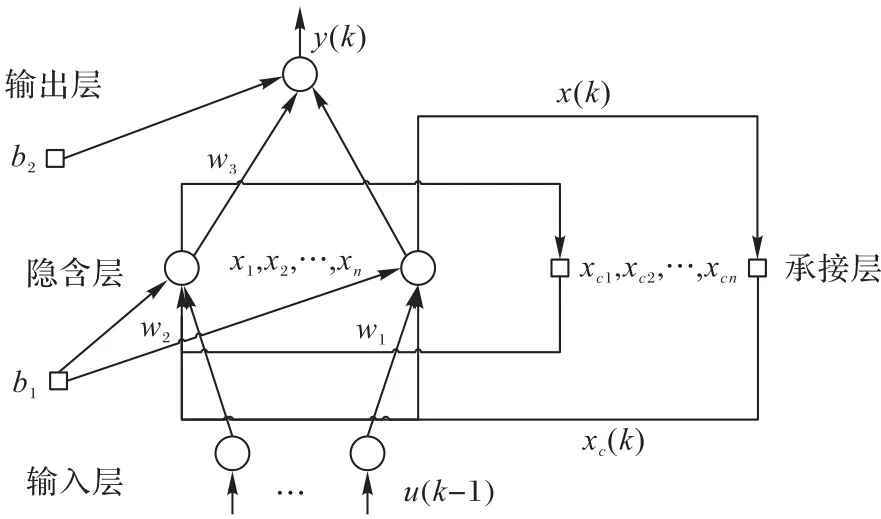
图1 Elman神经网络结构Fig.1 Structure of Elman neural network
人类的某些特殊活动会对整个社会以及各个行业产生一定的影响[16],如受我国传统习俗影响,节假日会造成制糖原材料需求量的波动,某些传统节日如元宵节、中秋节,对糖消耗量较大,日不均匀系数会受到较大的影响。根据调研制糖企业业务流程以及对基础数据的分析,制糖企业的采购频率具有一定规律,一般分为周采购、半月采购、月采购。图2展示了部分采购量变化趋势:从图2(a)中可以看到,1 月因春节与元宵节,原糖采购远超其他月份;在图2(b)展示的每半月购买数据中,也体现出了类似的趋势;图2(c)展示了第31 周至第44周的原糖购买量,其中,第40 周为国庆节假日,对于原糖的购买量也远超过近邻几周。可见制糖原材料采购量的增长和节假日具有一定的关联性,这些波动具有一定的规律性和相对稳定性,因此可依据其变化规律进行预测。本文采取与制糖原材料需求量预测关联最大的节假日因素进行需求量预测。

图2 原糖采购量与采购周期的关系Fig.2 Relationship between raw sugar procurement volume and procurement cycle
1.2 自适应网络学习速率优化ENN
数据源维度决定了ENN 输入层的节点个数,研究对象则决定其输出层节点个数。通过对企业原糖相关历史数据的分析,数据源可被划分为以下四类:原糖采购量、原糖消耗量、成品糖销售量以及时间特征,研究对象则为原糖需求量的预测值。因此,针对原糖需求预测问题,本文中ENN 的输入层节点数和输出层金额点数分别为4和1。
在ENN 中,学习速率的大小会直接影响收敛速度,学习速率过大、过小或者保持恒定都会影响最终预测结果的精准性。为此,本文提出了自适应改变学习速率的方法来提高模型的收敛速度。其基本原理为:在模型的迭代过程中,将当前误差与上一时刻误差进行比较,若二者相对接近,则说明此时已经接近最优解,考虑增大学习速率以提高收敛速度;若二者相差较大,则表明当前解已偏离最优解,考虑减小学习速率,并结束当前操作。自适应网络学习速率如下所示:

其中:η(t)和η(t+1)分别表示当前迭代过程和下一次迭代过程的模型学习速率;Et和Et+1分别表示当前误差和迭代下一次的误差;a、b均为正小数,对学习速率进行限制。本文中a、b取值均为0.05。
根据式(1),本文实验中设置网络的学习训练次数、目标精度以及误差精度分别为5 000、0.1和0.000 1时,TMCS-ENN效果最佳。
1.3 TMCS-ENN设计
时间序列预测实质为一种非线性的、约束繁杂并且可能存在多局部极值的最优化问题。制糖企业原材料需求量预测具有十分典型且复杂的非线性特点,原糖需求量受诸多因素影响,使用传统算法很难在有限的时间和空间内做出准确有效的应答。布谷鸟搜索(Cuckoo Search,CS)算法作为一种新兴的元启发式算法,具有参数少、易实现、效果好等众多优点,能够快速、高效地解决非线性的复杂问题,该算法的研究基于布谷鸟的巢寄生行为与莱维飞行机制[17],通过采用莱维飞行更新解,避免频繁陷入局部最优解,使算法的全局搜索能力更强,在此过程中需对部分解进行丢弃并更新。
考虑到节假日对于原糖需求量有直接显著的影响,本文采用了时间特征关联的使用MCS算法优化的Elman神经网络需求量预测模型TMCS-ENN,其流程如图3 所示,其中的时间特征优化、神经网络权值和阈值的初始化以及MCS 算法是TMCS-ENN预测模型的主要改进。

图3 TMCS-ENN预测模型的流程Fig.3 Flowchart of TMCS-ENN prediction model
1.4 改进布谷鸟搜索(MCS)算法
CS 算法具有易实现、参数少、效果好等众多特点,常用于解决具有非线性特点的优化问题[18]。由于CS 算法具有收敛速度慢和全局搜索仍然不彻底的现象,为改善其性能,通常需要采取一定方式对该算法进行改进。因此,本文从自适应的寄生失败概率和自适应的步长控制量两方面对CS 算法进行优化,得到MCS算法。
1.4.1 自适应的寄生失败概率优化
寄生失败的概率用Pa表示,在标准的CS 算法中Pa保持不变,但在CS算法中,无论较优鸟巢解还是较差鸟巢解,在迭代过程中均会以概率Pa出现寄生失败现象。寄生失败概率Pa越大,则较优鸟巢解越容易被新的鸟巢解所替换,导致算法很难收敛至最优解;Pa越小,则较差鸟巢解越可能被保留,从而使得收敛变慢。
针对上述问题,CS 算法的迭代过程中,前期应通过一个较大概率接受新解,从而提高收敛速度;在后期应使用较小的概率去保留较优解。为实现这样的迭代效果,本文提出一种自适应的寄生失败概率Pa,如式(2)所示:

其中:Pmin和Pmax分别表示最小寄生失败概率以及最大寄生失败概率;t和T分别表示当前迭代次数与最大迭代次数;m是一个取值大于0 的非线性因子,其作用为控制寄生失败概率的减小速率。分析式(2)可知,当m取值小于1,可以实现Pa在初期较大,而后期急速变小的效果。因此,本文Pmax和Pmin分别取0.5 和0.1,m和迭代次数取值分别为0.5 和500。Pa随迭代次数的变化曲线如图4 所示。可以看出,在迭代优化的早期过程中,寄生失败概率维持在一个较大取值范围内缓慢降低,而在后期则迅速变小,从而实现了寄生失败概率Pa的自适应效果。

图4 Pa随迭代次数变化曲线Fig.4 Variation curve of Pa with iterations
1.4.2 自适应的步长控制量优化
莱维飞行的路径是一种随机行走,其行走步长服从重尾分布,因此CS 算法在全局空间上表现出了较强的随机跳跃性,使其全局寻优能力较强;但由于其长步与短步分别以低频率和高频率交替出现,使用CS算法在全局空间中搜索鸟巢附近位置时极有可能搜索不彻底,忽略某些解。并且随着迭代的不断增加,长步长的出现可能会导致较优鸟巢位置被跳过,并使其附近的局部信息无法利用,使得算法很难在最优解处收敛,造成算法的收敛精度不高。
针对上述现象,本文提出一种自适应步长控制量,可有效控制CS算法的迭代步长,避免优秀位置解被跳过从而导致算算法收敛精度低的问题。
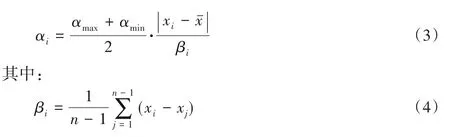
式中:xi为当前鸟巢位置解;αi为xi的下一个步长;αmax和αmin分别表示最大步长与最小步长,在本文中取值分别为1.5 和0.5;xˉ表示当前所有鸟巢位置解的平均值;βi表示当前鸟巢位置解与其他鸟巢位置解的平均差值。由式(3)可知,αi与当前鸟巢位置解和平均鸟巢位置解的差值的平均值成正比,因此可以自适应地对步长进行调整。这种自适应步长控制方法可以更好地利用局部信息,减少了原先算法由于跳跃性所导致的缺陷,提高了算法在全局空间中找到全局最优的可能性。
若对ENN 的阈值和权值进行随机初始化,往往会使得网络陷入局部最优,并降低收敛速度。为此,本文使用MCS 算法对模型进行优化。由于每个鸟巢都可能是ENN 的最优阈值与最优权值,使用均方根误差作为适应度函数计算ENN 的最优权值与最优阈值。MCS 算法会不停地进行迭代运算,一直达到收敛条件(达到迭代次数或满足最小均根方误差),MCS 优化Elman 神经网络(MCS-ENN)的流程如图5 所示。ENN 相关参数在1.2 节已给出,MCS 算法的自适应寄生失败概率和自适应步长控制量分别初始化为0.5和1.5,根据实验数据量将鸟巢数n、迭代次数T和精度e分别设置为75、500和0.000 1。
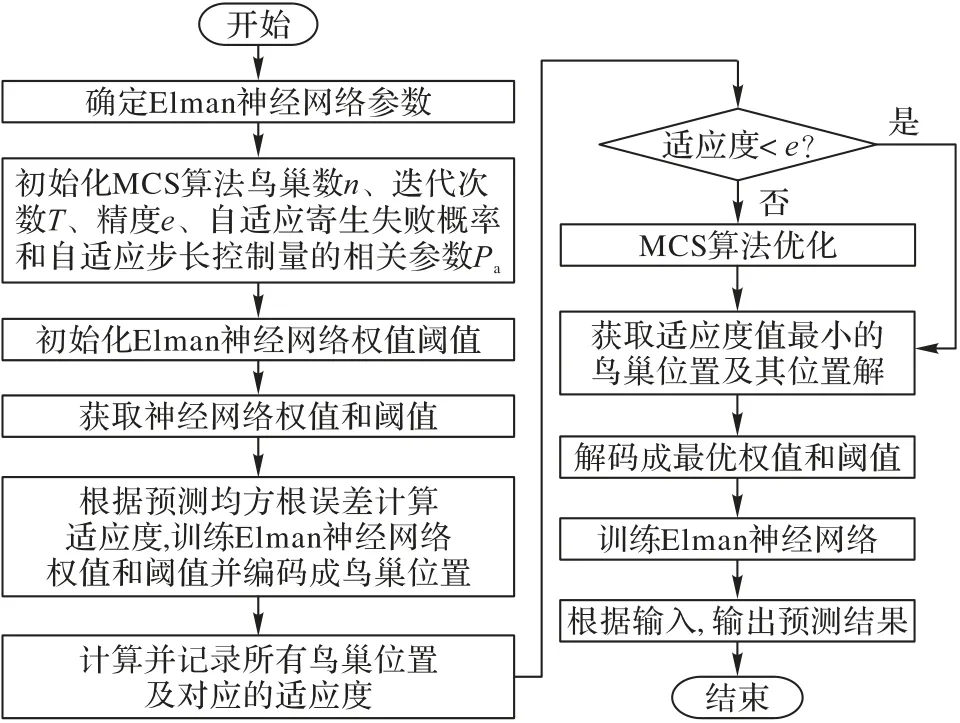
图5 MCS-ENN流程Fig.5 Flowchart of MCS-ENN
1.5 利用时间特征优化ENN
中国节假日因其特有的文化传统对于人的行为具有一定的导向作用,例如,中秋节时月饼的销量会达到一年中的峰值。由于各个节假日活动对食品有不同的要求,而糖作为基础食品材料,需求量受到节假日因素影响在一定范围内有规律地波动。可见,制糖原材料的需求量与时间序列存在相互依赖关系,若预测时仍按照平时生活方式进行预测,将会与真实值产生较大误差,降低预测精度。本文针对节假日原材料需求量变化的特点,对模型进行改进。
针对制糖原材料的时间高度敏感性,本文首先对数据分别按照“月”“半月”和“周”的时间粒度对数据进行切片,同时,以“0”“1”标签的形式标识每条数据中是否包含节假日因素,如春节、元宵节等,“1”表示划分的时间片内包含节假日因素,“0”则相反。将改进数据的节假日特征作为预测模型的影响因子,作为输入变量对模型进行优化。
在MCS 算法优化的ENN 中加入节假日时间特征后,预测模型更加符合制糖企业的真实情况。通过对时间特征进行分析,提取节假日因素,加入节假日因素的TMCS-ENN的具体算法如算法1所示。
算法1 加入节假日因素的TMCS-ENN。

2 实验设计与分析
2.1 原始数据
本文研究的制糖原材料数据来源于某真实制糖企业,实验选取了制糖企业近5年共60个月的历史数据。本次实验数据集的主要结构描述如表1~3。

表2 原材料消耗数据集描述Tab.2 Description of raw material consumption data set

表3 成品糖销售数据集描述Tab.3 Description of sugar sales data set
2.2 数据预处理
对于原材料需求量预测模型,首先需要对模型的输入输出、训练样本进行确定,也就是样本数据的确定。真实而完整的数据有助于提高预测原材料需求量的精准度,然而用于预测原材料需求量的数据大多来源于单机系统、地磅称重数据以及相关单据,因此需要对数据进行预处理,这是原材料需求量预测必不可少的环节[19]。
2.2.1 数据清洗与时间切片
制糖原材料数据因其来源可能出现数据异常、空缺、不一致等问题,会严重影响数据分析的准确性,所以需要通过对原数据进行清洗从而得到更加精准的预测结果。原始数据中的字段不能完全应用于预测模型,为降低计算量,本文对数据进行预处理时剔除了与预测无关的属性。
空值数据可能会对模型预测结果产生一定的影响,因此,对该类数据进行处理十分必要。在进行预测时,若空值数据不影响预测结果,就不予考虑;若空值数据是关键数据,则不能忽略。本文针对这样的关键性数据会根据时间选取该数据前后半个月的数据求平均值,以对该空缺数据进行填充。
由于数据本身的复杂性,不能直接体现其具有的时间特征因素。本文选择以周、半月、月的时间粒度分别对现有数据进行时间切片,以周粒度为例,一条数据包括一周内的原材料购买量与实际消耗量等,切片后的数据从第1周开始生成对应ID。此外,每条数据以“0”表示不具有节假日,“1”表示具有节假日,作为数据的时间特征以及预测模型的影响因子之一参与模型优化,经过数据清洗与时间切片后的样例如表4所示。
表4 巴西原糖数据时间切片样例Tab.4 Worked-example of Brazil raw sugar data after time slicing
2.2.2 数据转换与数据归并
针对制糖原材料预测,若直接使用原始数据作为预测模型的训练样本,预测结果的误差往往偏大,也会产生饱和的现象。因此对于历史数据,首先要对输入变量进行归一化处理,避免没有经过处理的数据影响到预测效果。本文将制糖企业原材料的数据样本使用2.2.1 节中归一化方式处理至[0,1]范围。
数据归并是在已有的数据特征中,根据任务目标需求寻找有用的特征,在不失真的条件下尽量精简数据。对于原材料采购数据,相同对象因为所处环节不同可能会出现属性值各不相同的现象,需要通过归并解决数据冗余和不一致的问题。
2.3 预测模型评价指标
为了验证模型的效果和性能,本文采取均方根误差(Root Mean Squared Error,RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)以及预测精度(Forecasting Precision,FP)这三种指标进行评价。具体指标计算公式如下:

2.4 结果分析
本节实验共分四组:首先验证CS 算法对于ENN 的优化(记作CS-ENN);其次,通过MCS 算法和CS 算法的对比实验,验证MCS 算法是否较CS 算法有更好的优化效果;接着,验证加速时间特征因素后的TMCS 算法的优越性;最后,在不同时间粒度下对比TMCS-ENN和MCS-ENN的预测效果。
本文实验选取的原材料预测样本为某制糖企业2013年1月到2017 年12 月近5 年的巴西原糖采购的历史数据。为保证预测的准确性和可比性,四组实验都采用巴西原糖作为原材料预测未来10 个时间节点的情况。对周时间粒度实验,共有165 周巴西原糖数据,其中前155 周数据作为训练样本,最后10 周(2017 年前10 周)数据作为测试样本,对网络进行训练和预测;TMCS-ENN加入了节假日因素,输入层个数设为4。对于按月预测,选取数据量共120 个月数据,其中前110 个月作为训练样本,后10 个月为预测样本;对半月预测,选取数据量共120 个半月数据,其中前110 个半月作为训练样本,后10个半月为预测样本。
2.4.1 权值优化对预测模型的影响
本组实验比较CS算法优化权值、阈值的ENN与采取随机权值阈值的ENN 模型预测精度。在周时间粒度下进行实验,预测结果和百分比误差如图6 所示。由实验可得,CS-ENN 的均方根误差(RMSE)为0.102,平均绝对百分比误差(MAPE)为8.72%,预测精度为91.28%;ENN 的三项指标则分别为0.173、12.15%以及87.85%。由图6 可知,巴西原糖需求量在第6 周(春节)和第8 周(元宵节)明显增高,并且CS-ENN 模型预测结果更好,其预测精度比ENN 高3.43 个百分点,误差明显减小,可见,由CS 算法优化的ENN 在一定程度上能够提高预测精度。
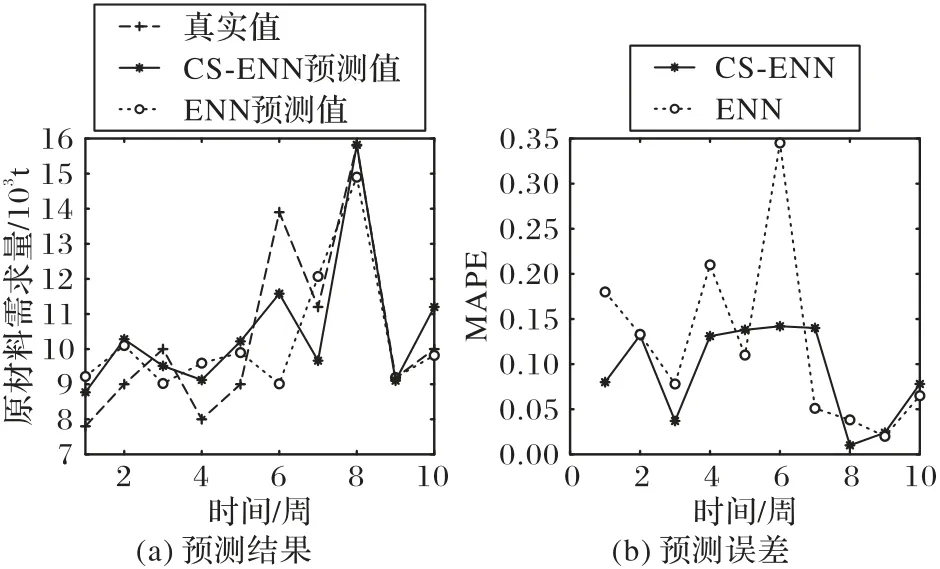
图6 CS-ENN和ENN的预测结果及误差比较Fig.6 Comparison of CS-ENN and ENN in prediction results and errors
2.4.2 MCS算法对预测模型的影响
本组实验比较在MCS 算法优化下使用自适应寄生失败概率和自适应步长控制量的ENN 预测模型与CS-ENN 预测模型的预测精度。在周时间粒度下进行实验,预测结果和百分比误差如图7 所示。实验结果表明,MCS-ENN 的均方根误差(RMSE)为0.067,平均绝对百分比误差(MAPE)为6.11%,预测精度为93.89%;而CS-ENN 对应各项指标分别为0.096、9.38%和90.62%。MCS-ENN 的预测精度较CS-ENN 提高了3.27 个百分点,误差明显减小,说明MCS 算法对于模型的优化效果更为明显,能够提高预测模型的精准度。
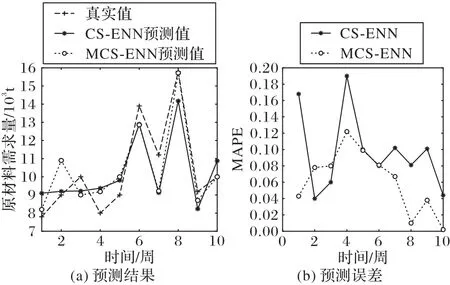
图7 MCS-ENN和CS-ENN的预测结果及误差比较Fig.7 Comparison of MCS-ENN and CS-ENN in prediction results and errors
2.4.3 时间特征对预测模型的影响
本组实验比较加入节假日时间特征后对MCS-ENN 的影响。以周为时间粒度进行实验,预测结果和百分比误差如图8 所示。实验结果表明,加入节假日特征的TMCS-ENN 的均方根误差(RMSE)为0.058,平均绝对百分比误差(MAPE)为5.36%,预测精度为94.64%;而未考虑该特征的MCS-ENN 的对应各项指标分别为0.092、6.73%和93.27%。加入时间特征可以使得预测模型精度提高1.37 个百分点。图8 中第6 周(春节)需求量明显提高,这是因为该节点具有节假日的时间特征,而在加入节假日因素后预测误差明显变小,再次说明加入时间特征对预测模型有优化作用,能够提高预测模型的预测精度。
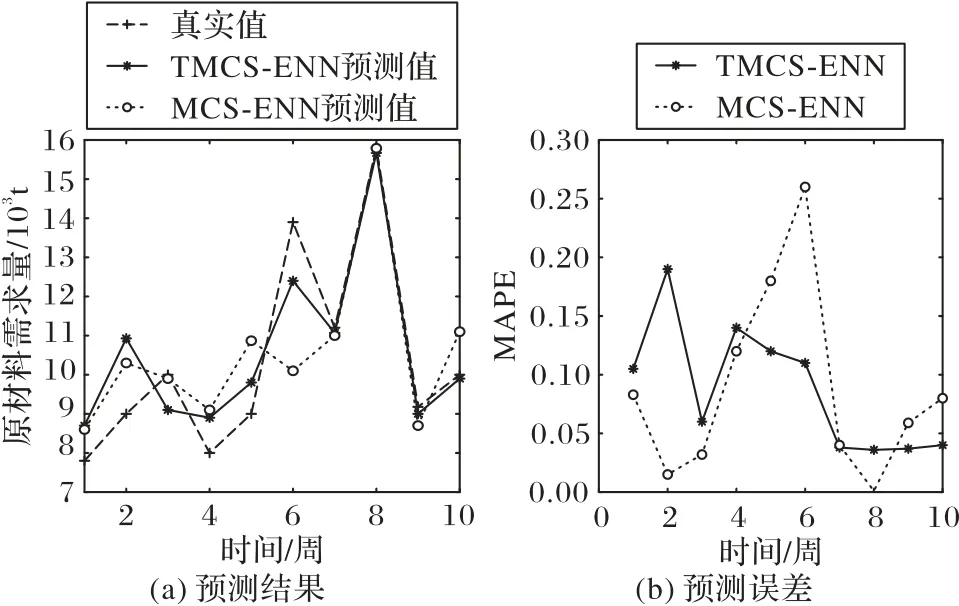
图8 TMCS-ENN和MCS-ENN的预测结果及误差比较Fig.8 Comparison of TMCS-ENN and MCS-ENN in prediction results and errors
2.4.4 时间粒度对预测模型的影响
为进一步探究不同时间粒度下,TMCS-ENN 预测模型的表现情况,本组实验将时间粒度划分为月、半月以及周分别进行实验。其中,MCS-ENN 输入层个数为3,隐含层个数为5。实验得到预测结果和百分比误差如图9所示。
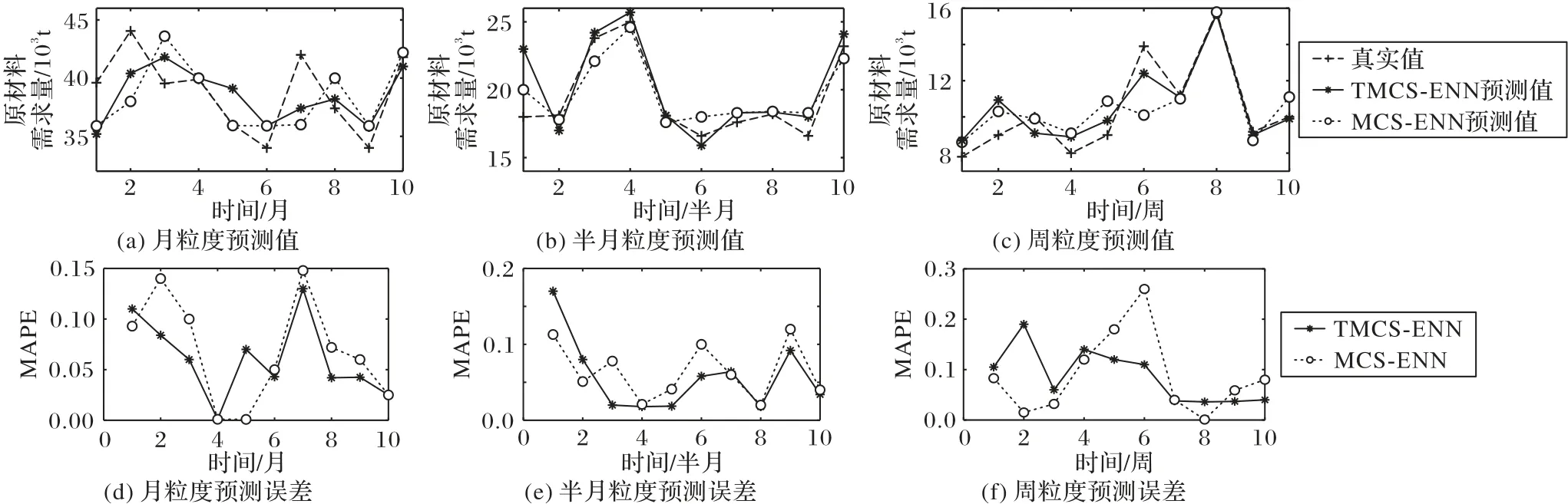
图9 不同时间粒度TMCS-ENN和MCS-ENN的预测结果及误差比较Fig.9 Comparison of TMCS-ENN and MCS-ENN in prediction results and errors under different time granularity
为进一步验证实验可信度,本文共对5 年历史数据汇总的数据进行了5 次预测,并对最终结果取均值后得到对比结果如表5所示。表5较为直观地展现出了在不同时间粒度下,TMCS-ENN 预测模型与MCS-ENN 预测模型各项评价指标的对比。由表5 可以看出,通过加入时间特征,模型预测精度相较未加入时间特征的MCS-ENN 模型的预测精度在月粒度下提高了1.02 个百分点;在半月粒度下提高了0.82 个百分点;在周粒度下提高了1.44 个百分点。对于同一模型,时间粒度划分越细,则预测精度及其余各项评价指标越好。实验数据表明,加入时间特征可进一步提高模型预测精度,有利于指导企业生产。

表5 不同时间粒度下的TMCS-ENN和MCS-ENN的评价指标对比Tab.5 Comparison of evaluation metrics of TMCS-ENN and MCS-ENN under different time granularity
通过以上四组实验对比,从预测精度及误差可以看出,CS-ENN 在任何情况下的预测精度均高于ENN;MCS-ENN 的预测精度相较于CS-ENN 预测的精度有进一步提高,表明本文对于CS算法的改进可以提高原材料需求量的预测精度;在进一步考虑到时间特征后,TMCS-ENN 预测模型的预测精度明显提高,且时间粒度越细致精度越高。可以看出,利用本文提出的TMCS-ENN预测模型将有助于制糖企业科学合理地进行制糖原材料购买。
3 结语
原糖需求的精准预测有利于提高制糖企业的生产效率。现有原材料预测研究大多采用传统回归、线性规划等算法模型,忽略了时间因素影响及行业特点,预测准确性有限;同时,传统方法难以满足原糖需求预测的时效性要求。针对这些问题,本文提出了一种基于改进Elman 神经网络的制糖原材料需求量预测模型。通过提出自适应学习速率公式以及MCS算法优化ENN,有效提高了模型的局部搜索能力,避免了局部最优,并结合企业与现实背景,进行基于周粒度的短时数据切片设计,使用节假日特征因子进一步提高模型预测精度。通过多组多粒度时间片段数据实验,在周时间粒度下的短期需求预测结果较准确,符合短时预测的时效性要求。
TMCS-ENN 预测模型为原材料供需匹配一致性提供了科学可行的解决方案,为企业智能化管理提供了技术支撑;然而,并未考虑到影响需求量的其他因素,如价格税、国内生产总值、温湿度及天气等,将在后续研究中进一步完善。
猜你喜欢
商品与质量(2021年43期)2022-01-18 05:29:02
粉末冶金技术(2021年3期)2021-07-28 06:26:16
南京大学学报(自然科学版)(2021年1期)2021-01-30 14:01:04
中学时代(2019年12期)2019-11-13 01:00:50
中国糖料(2019年4期)2019-10-11 07:13:22
意林(2019年16期)2019-09-04 21:00:12
广西农学报(2016年5期)2017-05-17 18:35:51
系统工程与电子技术(2016年12期)2016-12-24 07:19:14
中国洗涤用品工业(2015年6期)2015-02-28 19:02:34
淮阴工学院学报(2012年3期)2012-06-08 07:08:40
