
大米蛋白粉多组分含量近红外光谱快速检测
2021-07-29 04:05:14关婷予黄咏梅周新奇
中国粮油学报 2021年6期
关婷予 黄咏梅 林 敏 周新奇
(中国计量大学计量测试工程学院1,杭州 310018)(杭州谱育科技发展有限公司2,杭州 311305)
中国是世界上稻谷产量最大的国家,大米蛋白粉是大米的深加工产物。大米蛋白具有极高的营养价值[1],并且其氨基酸组成接近于 WHO/FAO 推荐的营养模式[2],与其他植物蛋白及乳清蛋白相比具有低敏性,可以免于过敏实验[3]。随着加工工艺的发展,改性大米蛋白被人们认可,逐渐发展成为婴幼儿食品、运动营养剂的重要原料[4],并作为添加剂开发应用于食品工业[5]。
大米蛋白粉为加工产品,不同提取工艺及提取精度会影响大米蛋白粉品质,蛋白质、脂肪与水分的含量是衡量品质优劣的重要指标。传统化学方法成分测定过程复杂且检测时间长,处理过程对样品具有破坏性,不能满足现代质量检测的需求,急需快速无损的检测方法。近红外光谱技术是一种无损检测技术,具有检测速度快的优点,已用于粮食作物[6]、食品成分含量分析中[7]。邱燕燕等[8]利用近红外光谱技术结合偏最小二乘(PLS)快速检测豆浆中蛋白质、脂肪和可溶性固形物含量;Joe等[9]应用近红外光谱技术建立小麦中的水分、淀粉、蛋白质等的定量分析模型。大米蛋白粉中蛋白质、脂肪和水分由含氢基团构成,近红外光谱主要反映了含氢基团倍频和组合频的吸收信息,因此可通过近红外光谱结合化学计量学方法对其含量进行检测。近红外光谱建模方法大多采用PLS[10],是光谱数据处理软件中的常用方法。但当待测样品的光谱数据与理化值存在非线性关系时,PLS预测精度不高[11],需要探索新的化学计量学方法提高预测精度。本研究利用近红外光谱技术结合自适应极限学习机(ELM)模型预测大米蛋白粉中蛋白质、脂肪和水分的含量,为大米蛋白粉中含量快速测定提供新方法,可实现加工厂家对加工原料中成分含量的快速分析。
1 材料与方法
1.1 样品采集与处理
大米蛋白粉样品采自福建省漳州市、安徽省滁州市、陕西西安、河南郑州及湖北武汉等不同地区,采集不同存放时间、样品各成分含量分布范围较大的244份大米蛋白粉。将样品密封存放于干燥、阴凉处并尽快进行近红外光谱分析。
1.2 近红外光谱采集
采集光谱所用仪器为杭州聚光科技有限公司生产的SupNIR-2720近红外多功能采集仪,仪器采用全息数字式光栅和高灵敏度铟镓砷检测器相结合,采集范围1 000~1 800 nm,采样波长间隔1 nm,一个样品800个光谱数据,光谱分辨率为10.9 nm,旋转扫描次数30次,取平均作为测量光谱。实验温度(25±1) ℃,且避免阳光直射。采集光谱前仪器预热30 min,倾倒大米蛋白粉使其自然填满样品盘,防止装样松紧度对测量光谱产生影响,并将样品上表面刮平。仪器通过性能测试后,以白板作为参比,计算样品吸光度,最终得到244份原始光谱数据。
1.3 理化值测定
光谱测量后将样品分为3份,按国家标准分别测量蛋白质、脂肪和水分含量。蛋白质按照GB 5009.5—2016 《食品安全国家标准 食品中蛋白质的测定》中凯氏定氮法测量氮含量;脂肪按GB 5009.6—2016《食品安全国家标准 食品中脂肪的测定》索氏提取法开展实验;水分按照国家标准GB 5009.3—2016《食品安全国家标准 食品中水分的测定》恒重法计算水分含量。最终得到表1大米蛋白粉中各成分含量。

表1 大米蛋白粉主要成分含量统计值
由表1可知,大米蛋白粉样品中蛋白质、脂肪和水分的含量分布较广,所选样品有一定的差异和代表性,符合近红外光谱建模要求。
1.4 近红外光谱模型的建立
1.4.1 光谱数据预处理
为了消除光谱采集过程中不可避免的噪声,减少外界因素的影响以及简化数据分析中的计算,在建模分析前,先对数据进行预处理[12,13]。分别采用二阶导数(2ndDer)、去除趋势(Detrend)、标准正态变量校正(SNV)和小波变换(WT),选择大米蛋白粉的预处理方法。
1.4.2 极限学习机建模
极限学习机(ELM)是一种单隐含层前馈神经网络[14],因其学习速度快,泛化性较好而应用于定量预测[15]或定性分类[16]中。将预处理后的光谱数据及样品理化值作为输入,模型输出为大米蛋白粉中蛋白质、脂肪和水分的预测含量,ELM模型如图1所示。其中x1,x2,…,xm为m个样品的光谱数据,h为隐含层节点,p为隐含层节点数,ωij为连接输入层与隐含层的权重,bij为隐含层偏置;βij为需要训练的输出层权重,y1,y2,…ym为ELM模型预测的成分含量。人工调节p值后,通过权重βij及光谱数据xm可得成分预测含量ym。
1.4.3 自适应极限学习机
经典ELM模型初始参数输入层权重(ω)和隐含层偏置(b)是随机确定的,预测效果不稳定,因此先将ω和b进行自适应寻优,提高ELM的稳定性。另外ELM的隐含层节点数p决定了模型的精度及过拟合程度,隐含层节点数可选范围较广,且人工试验方法无法直观判断出精度最高、过拟合最小的节点数,因此需要对其进行自适应寻优。本研究提出的自适应ELM优化过程如图2所示。
初始化参数ω和b采用粒子群算法(PSO)[17]进行优化。PSO寻优时有多个粒子且信息互通,更易找到全局最优解。将ω和b作为PSO的粒子,随着迭代次数的增加向着训练集均方根误差(RMSEC)减小的方向调整。
隐含层节点数p采用线性加权评价法确定。首先确定评价预测模型优劣的指标为预测精度及过拟合程度,接着根据指标的重要程度分配权重m,将不同隐含层节点数下ELM的输出线性加权求和,最后根据线性加权求和结果,自适应的选取最优隐含层节点数。

图1 极限学习机网络模型
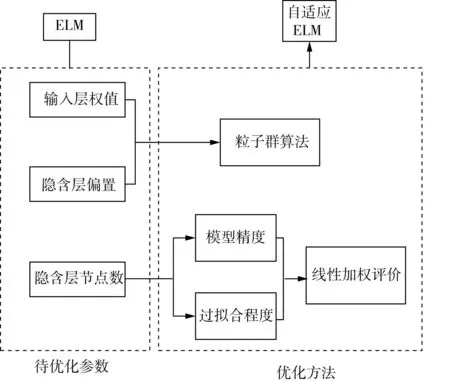
图2 自适应ELM优化过程示意图
1.4.4 模型评价
将大米蛋白粉样品按照2∶1的比例分为训练集和预测集,训练集用来建立模型,预测集用来检验模型的预测能力。模型精度由预测集均方根误差(RMSEP)及预测集决定系数(R2)[18]决定,过拟合程度由RMSEC与RMSEP之差的绝对值判断。RMSEP表示预测值与实际值的差异,越接近于0越好,R2表示预测值与实际值的相关程度,越接近于1越好。
2 结果与分析
2.1 原始光谱
采用光谱仪对大米蛋白粉进行扫描测量,为了防止偶然误差,由同一实验员操作两次取平均作为测量光谱,大米蛋白粉的原始光谱曲线如图3所示。

图3 大米蛋白粉原始光谱
近红外光谱主要反映了有机物分子中C—H、O—H、N—H键基频振动的倍频和组合频信息。大米蛋白粉样品中蛋白质、脂肪和水分各成分含量不同,吸光度也不同,因此峰值高低与大米蛋白粉中的成分含量相关。大米蛋白粉在1 193、1 505、1 730 nm附近有三个吸收峰,蛋白质中N—H的伸缩振动一级倍频在1 500 nm左右、脂肪中C-H振动的一级倍频、二级倍频分别在1 730、1 193 nm附近,水在1 730 nm及1 193 nm附近有的组合频吸收[19]。不同成分的吸收峰有重叠,仅通过光谱曲线无法判断各成分含量,因此需结合数据分析方法,建立光谱数据与成分含量的非线性关系模型。
2.2 光谱数据预处理方法
通过马氏距离剔除4个异常样品。剩余的240组数据分别采用不同预处理方法的结果如表2所示。

表2 不同预处理方法对大米蛋白粉各成分含量预测模型的影响
由表2可知, WT预处理方法效果最好。图4a为任意选取的3个样品的原始光谱,图4b为利用小波变换系数进行重构的光谱曲线,由图可知,WT可较好的还原原始光谱数据,小波系数重构光谱数据与原始光谱数据的均方根误差为1.46×10-4。WT将800个原始光谱数据用52个小波系数代替,消除冗余的光谱数据,大大简化了后续建模的复杂度,提高检测的快速性。


图4 大米蛋白粉光谱数据图及预处理
2.3 样品集划分及数据特征
大米蛋白粉成分中的蛋白质含量较高,脂肪和水分的含量较低。利用光谱-理化值共生距离(SPXY)算法将样品按2∶1比例划分为训练集和预测集,各成分含量的最大、最小值和标准差如表3所示。利用SPXY划分训练集和预测集使样品具有较大的差异性,提高建模的稳定性。

表3 训练集和预测集样品成分含量的分布特征/g/100 g
2.4 自适应ELM模型
2.4.1 初始参数ω和b的优化
预处理后的光谱数据及理化值作为ELM模型输入,将粒子群算法迭代200次后的ω和b作为ELM的初始参数。图5为经典ELM与PSO优化的ELM分别运行10次的结果图。由图5可知,对ELM的ω和b进行改进,可提高预测的稳定性及精度。

图5 ELM与PSO-ELM蛋白质含量预测结果比较
2.4.2 隐含层节点数的自适应选择
ELM隐含层节点数的最优个数一般不会超过60个[20],合适的隐含层节点数应使预测模型的精度尽可能高,并且过拟合程度尽可能小。因此评价指标为RMSEP及|RMSEP-RMSEC| 2个指标。由于目的是检测大米蛋白粉各成分含量,预测精度更重要,因此根据指标重要性赋予RMSEP的权重为0.6,|RMSEP-RMSEC|的权重为0.4。通过线性加权求和计算各个隐含层节点数p的得分Q。由于各指标均为极小型指标[21],所以Q越小说明该隐含层节点数越好,得到蛋白质、脂肪和水分ELM模型的最优隐含层节点数分别为24、18、14个。
2.5 模型检验
为了验证模型的预测能力,使用未参与建模的预测集样品对大米蛋白粉中蛋白质、脂肪、水分含量进行检测,结果如表4所示,预测集样品的预测值与实际值如图6所示。

表4 预测集样品检验结果



图6 大米蛋白粉中各成分含量预测结果图
分析表4及图6发现,模型的决定系数R2均接近于1,RMSEP比较接近于0。大米蛋白粉中蛋白质含量最大值为86 g/100 g,脂肪和水分最高仅有11 g/100 g及7 g/100 g,对于不同含量,预测集样品的预测值与实际值差异很小,说明近红外光谱技术结合自适应ELM建模方法可以对未知大米蛋白粉样品进行预测。
2.6 讨论
大米蛋白粉中蛋白质、脂肪和水分的预测效果不同,外部检验决定系数分别为0.990 5、0.964 3、0.957 4。从训练集的标准差来看蛋白质标准差为2.61,脂肪和水分的为1.39和1.03。蛋白质含量大小分布较广,模型效果更好,说明样品理化值大小的分布会影响模型的预测效果。
ELM是由前馈神经网络演化而来,相比于线性PLS模型,其学习能力有所提升,可实现对多组分含量的预测。但ELM需要人工调参,且结果不稳定,本文提出自适应ELM自动寻找最优参数,将自适应ELM与经典ELM、PLS建模方法进行比较,如表5所示。

表5 三种建模方法比较
由表5可知,自适应ELM与PLS模型相比,大米蛋白粉中蛋白质、脂肪及含水量预测集R2更大,RMSEP分别降低了40%、28%、30%,预测精度有了较大提高。相比于经典ELM模型,经过优化的自适应ELM提高了模型的稳定性及预测精度,可实现大米蛋白粉中蛋白质、脂肪和水分的自动检测。
3 结论
本研究利用近红外光谱技术结合自适应ELM建模方法预测大米蛋白粉中蛋白质、脂肪和水分的含量。对采集的244份大米蛋白粉原始光谱数据进行小波变换预处理,数据压缩比为93.5%。为了提高预测模型的精度,采用自适应ELM建模,ELM是单隐含层前馈神经网络,将ELM的初始化参数用PSO进行优化,并利用线性加权评价方法自适应确定隐含层节点数,建立稳定性更高的自适应ELM模型。蛋白质、脂肪、水分模型的决定系数分别为0.990 5、0.960 7、0.957 4;预测均方根误差为0.330 8、0.376 6、0.192 2,结果表明自适应ELM定量分析方法与PLS相比预测精度有较大提高,说明近红外光谱技术结合自适应ELM能够有效预测大米蛋白粉中各成分含量。该研究为大米蛋白粉中各成分含量的无损快速检测提供一种新方法。
猜你喜欢
科普童话·百科探秘(2023年5期)2023-06-19 04:18:30
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
农村百事通(2021年31期)2021-12-13 03:02:33
中老年保健(2021年3期)2021-08-22 06:51:08
农村百事通(2021年11期)2021-01-17 07:33:01
特别健康(2018年9期)2018-09-26 05:45:42
饮食保健(2016年21期)2016-12-10 05:28:39
中国光学(2015年5期)2015-12-09 09:00:28
高中生学习·高三版(2014年3期)2014-04-29 06:12:54
食品工业科技(2014年23期)2014-03-11 18:18:54
