
基于BERT-LEAM模型的食品安全法规问题多标签分类
2021-07-28 12:44郑丽敏乔振铎田立军
农业机械学报 2021年7期
郑丽敏 乔振铎 田立军 杨 璐
(1.中国农业大学信息与电气工程学院, 北京 100083; 2.食品质量与安全北京实验室, 北京 100083)
0 引言
近年来,食品安全问题频发,为了更好地维护消费者合法权益,人们越来越重视食品安全法规问题[1],因此,研究开发食品安全法规自动问答系统具有重要应用价值。然而,食品安全法规问题涉及管理对象、法规内容、法规约束以及法规管理项目等,内容丰富且复杂[2-3],所以,法规问题的有效分类成为实现法规问答系统的关键[4]。
在传统的分类方法中,每个样本示例只属于一个类别标记,即单标记学习[5]。文献[6]提出TextCNN模型,将卷积神经网络(Convolutional neural network, CNN)加入到自然语言处理任务中。随后,深度学习[7-12]的方法被广泛应用于单标签文本分类任务中,取得了非常好的效果。但国内外关于多标签文本分类问题尚处于研究阶段[13]。
在问答系统的问题分类中,文献[14-15]为深度学习在农业领域的文本分类提供了可行性的依据,但多为单标签分类,且对食品安全法规领域的研究与应用尚显不足。针对食品安全法规的相关问题,不同角度的分类往往涉及多个层次,每个层次同时包含多个类别。文献[16]提出LEAM网络模型,将文本分类的标签转换为语义标签向量,从而使分类任务转换为向量匹配任务。受该模型的启发,根据食品安全法规问题特点引入BERT[17]预训练模型,该模型以大量语料为基础,采用自监督学习方法,可以得到较好的特征表示。针对具体问题,使用BERT特征可以明确地表达该问题的词嵌入特征,因此,BERT可作为一个供其它方法迁移学习的模型,即特征提取模式。
针对目前单标签文本分类方法存在的局限性,为了直观反映食品安全法规问题的多义性,本文提出一种基于BERT-LEAM的多标签文本分类方法。首先,采用多角度、分层次的多标签标注方法将单个问题文本赋予多个标签;其次,引入BERT迁移学习模型表示上下文特征信息,通过Attention机制学习标签与文本的依赖关系,进行Word embedding的聚合,将标签应用到文本分类过程中;最后,将常用方法与本文方法进行比较,得到验证结果。以期实现食品安全法规问题的多标签分类,为设计准确、高效的问答系统奠定基础。
1 数据与方法
1.1 数据获取
为了准确有效地分析用户对于食品安全法规的需求[18],本文筛选出如表1所示业内公认的规模较大、可信度较高的5个公共法律咨询服务网站以及常用的公共问答社区——“百度知道”。利用爬虫技术爬取网站中有关食品安全法规的问答数据,共计7 936条。具体数据信息分布情况如表1所示。

表1 数据来源
1.2 数据预处理
本文直接爬取上述网站的食品安全法规相关问题数据,其中包含一部分重复问题数据,且具有与文本中心思想无关的标点、乱码、语气词和特殊符号,为方便运算,上述实验数据仍需进行清洗。此外,问题样本数据中仍包含食品安全相关名词的简称,如“QS(企业食品生产许可)”,与文本语义相关,为突出此类文本特征,仍需进行标准化操作,将其替换为汉语全称。数据清洗和标准化具体操作为:①去除无关数字、字母、特殊符号。②去除标点及语气词。③替换名词简称。④去除重复问题数据。经过预处理后,最终得到实验数据为7 782条。
预处理完成,获得有效数据,将其分为2部分,一部分作为BERT向量嵌入模型的输入数据,无需进行分词处理,另一部分用于验证BERT特征表示模型效果,需要采用分词操作。本文选用BERT预训练模型作为文本分类模型的向量嵌入层,它是基于字符级别的文本特征表示方法,所以该实验无需对数据集进行分词。为了验证BERT模型的特征表示效果,选取了MIKOLOV等[19]在2013年提出的预训练词向量工具Word2Vec作为对比方法。Word2Vec是基于词级别的向量嵌入模型,为了确保对照实验的效果最优,对数据集进行了分词处理,将分词之后得到的文本作为对照实验的数据集。为了保证分词结果的准确率,避免食品安全相关名词被切分,在分词过程中加载了食品安全法规词典,该词典由法规名称、部门名称、法规关键词等名词构成。
1.3 数据分析及问题分类
对食品安全法律法规相关问题进行分析,分析示例如图1所示,其虚线框中为用户提出的问题:“我在超市购买到过期饮品维权的话适用食品法96条还是适用消费者保护法55条”。
依照实际应用对法规问题从8个角度进行层次划分,每个问题进行双层次标签标注,标签层次类别划分结果如表2所示。
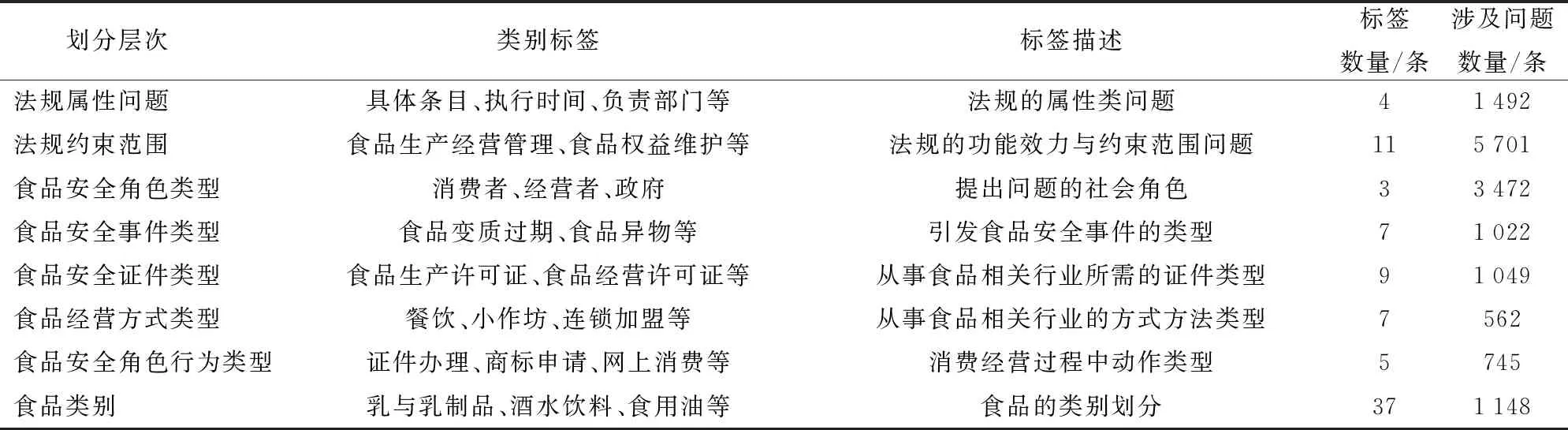
表2 问题层次类别划分
1.4 BERT-LEAM多标签分类模型
本文提出的模型主要由BERT文本特征表示层和LEAM标签语义嵌入网络层两部分组成。将多个标签与文本的组合转换为单个标签加该文本的形式,通过BERT嵌入层转换为向量文本表示后,利用LEAM网络模型计算获得文本的最终概率分布,如图2所示。
1.4.1BERT模型
BERT模型主要利用双向Transformer结构捕捉语句中的双向关系,记忆当前字的前、后字。Transformer是一种基于自我注意力机制的网络,其编码器结构如图3所示。
编码器的关键部分为自注意力机制(Attention),主要通过同一个句子中的词与词之间的关联程度,调整权重系数矩阵来获取词的特征,公式为
(1)
式中Q、K、V——字向量矩阵
dk——embedding维度
多头注意力机制通过多个不同的线性变换对Q、K、V进行投影,最后将不同的Attention结果进行拼接,计算公式为
MutiHead(Q,K,V)=Contact(head1,head2,…,headn)W0
(2)
其中
(3)
式中 MutiHead——多头注意力机制
Contact——投影
W——权重矩阵
因此Transformer模型可以得到不同空间下的位置信息。
Transformer模型缺乏传统神经网络获取整个句子序列的能力,因此,BERT模型在数据预处理前加入位置编码,与输入的向量数据求和得到每个字的相对位置。除了位置嵌入特征外,BERT模型对于输入的文本还有WordPiece嵌入和分割嵌入2个嵌入特征。此外,BERT与传统模型不同点在于,预训练任务中,随机遮盖或替换一句话中的字词,计算被遮盖处的损失函数,此种操作便于捕捉词语级别的表征。实验选用了Google官方提供的12层Transformer的BERT模型,并选取BERT模型的1到12层输出特征,设置问题文本最大长度为100,当问题内容相对较少时,在长度不足的位置补0。
1.4.2LEAM网络模型
传统文本分类流程中,直接将Word的embedding嵌入转变为定长的向量表示,而LEAM模型在每个步骤均使用标签信息(图2)。如图2中流程f0所示,模型学习了Label的embedding对Word的embedding影响,利用Label与Word之间的相关性进行embedding的聚合计算,计算公式为
G=(CTV)∅
(4)
式中G——聚合计算结果
K——Label的类别数
L——Word长度
∅——同位元素对应相乘
C——Label-embedding矩阵
V——Word-embedding矩阵
kl=‖ck‖‖vl‖
(5)
ck——第c个标签向量嵌入
vl——第l个单词向量嵌入
为了更好地获取连续的Word之间的空间信息,模型引入卷积和ReLU激活函数,如图2所示。用Gl-r:l+r衡量中心在l、长度为2r+1的Label-Phrase的相关性,第l个Phrase和k个Label的相似度向量计算公式为
ul=ReLU(Gl-r:l+rW1+b1)
(W1∈R2r+1,b1∈Rk)
(6)
式中Gl-r:l+r——以第l个词为中心词的片段
W1、b1——需要学习的参数
ul——相似度向量
R——标签与单词的共享向量空间
利用max_pooling得到最大相关系数,即ml=max_pooling(ul)。其中ml是长度为L的向量m中第l个元素。在获得向量m的基础上,经过softmax函数后得到Attention的系数,如图2中的系数β。文本最终表示z通过基于标签的Attention score加权词嵌入得到,公式为
(7)
式中βl——第l个元素的Attention系数
针对本文中所研究的多标签分类问题,模型将其拆解为M个单标记问题。训练目标公式为
(8)
式中CE(ynm,f2(znm))——2个概率向量的交叉熵
N——类别数M——标签数
ynm——类别标签的概率表示
znm——类别标签的文本特征表示
为了标签起到增加类别判断权重的作用,即相同类别的文本表示之间的距离小于不同类别的文本表示之间的距离。模型引入一个标签的正则化项,公式为
(9)
1.5 对比模型
(1)BERT-softmax模型:对BERT模型进行Fine-Tune,通过softmax激活函数计算标签与样本的差距,并输出分类结果。
(2)TextCNN模型:文献[6]提出TextCNN模型,将CNN在图像领域中取得的成就应用到自然语言处理NLP任务中,与传统机器学习方法相比,神经网络会自己构建、选择特征并分类,是端到端的训练,可以达到一种联动的效果,实现全局优化。
(3)VDCNN模型:文献[20]提出的非常深度卷积神经网络模型(Very deep convolution neural network, VDCNN),利用小尺度的卷积核池化操作,包含了29个卷积层,可以从简单到复杂地提取文本特征。
(4)Self-Attention模型:文献 [21]提出Self-Attention模型,自身进行Attention操作,改进了CNN模型只能捕捉局部文本特征,RNN模型难以并行化,且两者缺乏对全局特征的理解等缺点。Self-Attention模型中每个词与文本中所有词均进行Attention计算,可以捕获长距离依赖关系。
(5)CapsuleNet模型:文献[22]提出了CapsuleNet胶囊网络,该网络引入动态路由,保留了文本特征的位置信息,解决了卷积神经网络在识别实验对象子结构特点的缺陷,从而保证句子语义不变。
(6)LEAM模型:参数较少,收敛速度快,其学习过程只涉及一系列的基本代数运算,因此,模型可解释性较强,有效保证准确率的同时还降低了时间成本。
以上述模型为基础,实验对比Word2Vec与BERT 2种向量嵌入层的文本分类结果。
1.6 评价指标
采用F1值和汉明损失[23](Hamming loss)作为性能评价指标。由于数据集中每个标签之间的数据量不均衡,因此,将计算得出的F1值取加权平均值F1-W。计算公式为
(10)
(11)
(12)
式中P——精确率R——召回率
S——样本数H——汉明损失值
Yi——真实标签集合
△——异或运算符
F1值作为精确率(P)与召回率(R)的加权平均值,当出现精确率与准确率其中一个值为1而另一个值为0时这种极端情况时,F1值可以很好地避免这种情况对实验结果的影响。F1-W值作为加权平均值,值越大多标签分类效果越好。而H是衡量样本中误分标签平均数量的指标,H值越小,说明误分标签数量越少,分类模型的效果越好。
2 问题分类实验与结果分析
2.1 实验设计
2.1.1数据集划分
实验选取上述食品安全法规问题数据为研究对象,采用如图1所示的分析方法,对经过预处理的所有数据依次进行层次和类别分析,并依据分析结果赋予问题文本单个或多个标签,层次分析后的数据作为粗粒度多标签数据集,类别分析后的数据作为细粒度多标签数据集。2类数据集标签情况见表3,其中粗粒度多标签为表2中的划分层次,细粒度多标签为表2中的类别标签。

表3 数据集标签信息
表4为以上2种数据集中不同数量标签的问题分布情况。本实验中,2种数据集均将多标签视为标签组合类,采用StratifiedKFold[24]分层采样方法对相同标签组合下的数据进行训练集与测试集划分,确保划分结果中各标签组合类之间的比例与原始数据集相同。训练集与测试集的划分比例为4∶1,训练过程中在训练集中随机抽取10%进行验证。

表4 2种数据集的问题分布情况
2.1.2参数设置
为防止模型过拟合,设定全连接层单元丢弃比例为0.5。伴随训练轮次增加,梯度下降无法收敛至全局最优点,因此,设定学习率衰减系数为0.9,学习率衰减步长为1 000,即每间隔1 000次训练,学习率乘以衰减系数为新的学习率。
实验选用Top_K_Categorical_Accuracy[25]性能评估函数作为训练时评价模型准确率的参数,即测试文本的真实值标签在所有类别标签预测准确率中排前k名。为保证训练模型的最优化,实验测试了选取不同k时,测试准确率产生的变化,结果见表5。由表5可知,当k=5时,分类效果最佳。分类模型训练可以离线完成,因此,模型应更加关注结果的准确率。
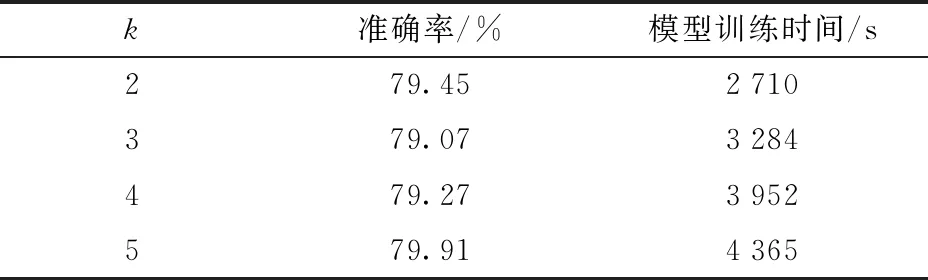
表5 k值的确定
选用Adam[26]算法进行模型的优化,该优化算法是对随机梯度下降算法的扩展,计算效率高,占用内存少,适合解决例如文本分类这种特征较为稀疏的问题。
2.2 结果分析
本文所有实验均在主频为2.9 GHz的i5-9400F处理器和显卡为NVIDIA GeForce GTX1660 super的计算机上进行,采用的神经网络模型使用版本为2.2.4的Keras进行搭建。实验以2.1.1节所述的粗、细粒度多标签数据集为基础,选取1.5节所述的模型与本文模型进行对比。细粒度标签数据集实验结果如图4和表6所示。

表6 细粒度多标签H
由图4和表6可知,BERT-LEAM模型F1-W值为79.81%,H为0.288 9,分类对比效果表明,BERT作为向量嵌入层进行文本特征表示的方法明显优于Word2Vec,尤其对LEAM模型分类效果的提升更为显著。与BERT对接的其他网络相比,LEAM模型将BERT的F1-W值提高了4.89个百分点,H减小了0.343 4,其优势更为明显。与直接对BERT进行Fine-Tune的方法相比,其他对接分类网络的方法均提升了分类效果。
实验方法首先将多标签问题转换成单标签多分类问题,标签数量较多,导致样本数据极不均衡,从而导致实验结果F1-W与H效果较差,实验选取粗粒度多标签数据集进行了对比,来验证BERT-LEAM模型方法的鲁棒性,实验结果如图5和表7所示。
由图5和表7可知,BERT-LEAM模型F1-W值为93.35%,H为0.122 6,对粗粒度多标签数据集的分类效果也明显优于其他模型。实验结果表明,无论是基于粗粒度多标签数据集还是细粒度多标签数据集,本文采用的BERT-LEAM模型均获得了分类的最优效果。
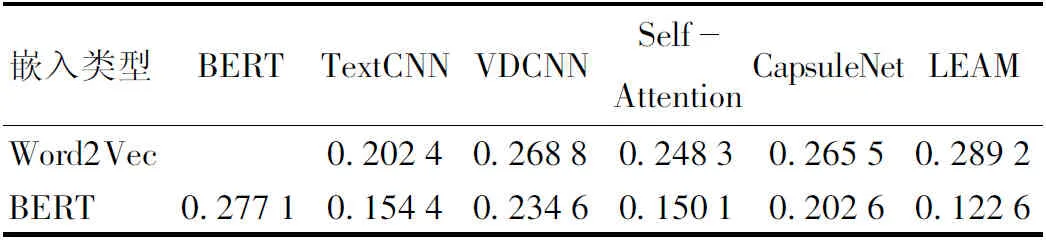
表7 粗粒度多标签H
由于分类模型的训练可以离线进行,实验对比了5种采用不同嵌入类型的模型在1 556条粗标签测试数据上的响应时间,对比结果如表8所示。

表8 模型测试响应时间
由表8可知,无论分类网络选择何种嵌入类型,与其他3种模型对比,Self-Attention模型和LEAM模型响应时间均较低,其中Self-Attention模型主要计算为自身进行Attention,结构相对简单,LEAM模型的参数较少,收敛速度快,时间较短的同时仍能保证分类准确率。但是,综合细、粗粒度多标签数据集上的表现,BERT-LEAM模型的分类效果更好。响应时间较长的TextCNN模型、VDCNN模型和CapsuleNet模型3种模型中,一维卷积层的TextCNN模型响应时间明显优于VDCNN模型和CapsuleNet模型,VDCNN模型为深层的卷积神经网络,卷积层数较多,因此,测试响应时间最长。CapsuleNet模型网络神经元输出由标量变为矢量,保留了子结构的位置特征,模型计算量较为复杂,因此测试响应时间相对较长。
除分类网络不同以外,预训练模型的选取也会影响模型的测试响应时间。实验选用BERT向量嵌入模型,该模型为动态向量表征方法,能够根据文本上下文语义特征生成句向量,输出向量为768维,且计算参数较多,分类模型的响应时间相对较长。对照实验选用Word2Vec预训练向量工具,该工具为固态向量表征方法,当分类模型在训练或测试过程中,加载预训练完成的词向量,且该嵌入层输出向量为300维,计算量较小,因此时间成本较少。但是,综合两种嵌入模型在细、粗粒度多标签数据集上的分类表现,BERT模型明显优于Word2Vec模型。与Word2Vec模型相比,BERT在LEAM分类网络上将F1-W值分别提高了10.43、6.99个百分点,在Self-Attention分类网络上将F1-W值提高了8.19、4.82个百分点。因Word2Vec为固态向量表征模式,无法解决一词多义问题,导致分类效果较差,而BERT模型动态生成句向量,可有效规避词语多义性对分类效果的影响。
实验分析了细粒度多标签分类效果相对于粗粒度多标签分类效果降低的原因,统计了测试集中不同量级标签的分布情况,共计83种细粒度标签类别,样本数量大于100的标签为9种,数量处于50~100之间的标签有7种,数量在10~50之间的标签有23种,包括50%以上的细粒度多标签样本数量在10个以下,其中大部分为食品类别标签,该类别标签所含样本数量和特征较少,导致实验结果不均衡,进而造成测试结果的F1值在50%以下。另一个重要原因是,细粒度多标签分类的类别明显多于粗粒度分类,从而使得细粒度分类中每一类的样本数相对较少,进而导致细粒度标签数据集样本分布不均,分类效果较差。
3 结论
(1)提出了针对食品安全法规问题的多标签标注方法,并应用到文本分类任务中,有效实现了食品安全法规问题多角度、多层次的信息挖掘,切实改善了传统单标签问题分类数据特征单一、信息表达不完整的问题。
(2)提出了基于BERT-LEAM模型的多标签分类方法,该方法能够满足问答系统的实际需求,可有效对食品安全相关问题进行自动分类。基于BERT-LEAM模型的分类方法在细粒度标签数据集和粗粒度标签数据集上F1-W值分别达到了79.81%和93.35%,无论数据量还是数据特征,其分类效果均优于其他分类模型,有效实现了食品安全相关问题的多标签文本分类。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
理财·市场版(2020年7期)2020-08-06
理财·市场版(2019年10期)2019-09-10
软件导刊(2018年2期)2018-03-10
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
科技资讯(2017年7期)2017-05-06
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
