
基于Attention_DenseCNN的水稻问答系统问句分类
2021-07-28 12:44王郝日钦吴华瑞刘志超许童羽
农业机械学报 2021年7期
王郝日钦 吴华瑞 冯 帅 刘志超 许童羽
(1.沈阳农业大学信息与电气工程学院, 沈阳 110866; 2.内蒙古民族大学计算机科学与技术学院, 通辽 028043;3.国家农业信息化工程技术研究中心, 北京 100097; 4.北京农业信息技术研究中心, 北京 100097)
0 引言
“中国农技推广APP”是一个提供专家指导、农技问答的综合性专业服务平台,用户每天在水稻问答模块中提问千余条,目前主要利用人工筛选特征和浅层学习模型对水稻提问数据进行分类管理。由于水稻提问数据的高维性和稀疏性,其分类效果并不理想,如何使用自然语言处理[1]技术自动、快速地挖掘水稻问句的特征,并用于水稻问句分类,是当前需要解决的重要难题。问答系统一般包括用户问句分类[2]、问句语义分析[3]和答案抽取[4]3部分。问句分类是问答系统的关键模块,其分类准确性对问答系统至关重要,因此,对水稻问句进行自动分类是实现水稻智能问答系统[5]的关键,也是实现人工智能[6]的必然需求。
近年来,国内外研究人员使用机器学习[7-8]与深度学习[9-13]模型进行文本分类,并取得了良好的效果。卷积神经网络在图像分类领域取得了显著的效果,研究人员将卷积神经网络模型进行优化和改进,使用词向量转换工具将高维的文本数据转换为低维稠密的词向量,并输入卷积神经网络,提升了分类效果。文献[14]提出用于文本分类的单层卷积神经网络模型,将文本当作固定长度的图像输入到模型中,提高了文本分类效果,但并未考虑文本信息中的序列信息所带来的影响。文献[15]运用循环神经网络模型(Recurrent neural network,RNN)针对文本中的序列信息提升了文本分类效果,但RNN无法解决长时依赖以及梯度消失问题。为此,研究人员对RNN模型进行了优化及改进,提出了长短期记忆网络(LSTM)和门控循环单元神经网络模型(GRU),并用来解决文本分类问题。文献[16]提出Densenet网络模型,在卷积层之间采用了密集的连接,缓解了梯度消失问题,加强了特征传播,在文本分类任务上表现出良好的性能。在机器学习中,常用的文本分类方法有K-means算法[17]、朴素贝叶斯模型[18]和支持向量机模型[19]。在农业领域,由于缺少大规模可用的数据集,相关研究仍处于起步阶段。现有研究[20-23]为深度学习在农业文本数据分类提供了参考及可行性依据。然而,农业文本分类大部分采用固定宽度的卷积核来提取文本特征,未考虑关键词在农业文本分类中的重要性,在多类别水稻问答问句数据集上分类的验证也鲜有涉及。
针对水稻问答问句稀疏性强、噪声大、数据量大的特点,本文提出一种基于注意力机制的密集连接卷积模型文本分类方法。在CNN上下游卷积块之间建立了一条稠密的捷径,每个卷积块采用不同宽度的卷积核来提取文本特征,引入农业词典对文本数据进行分词和词向量转换,然后输入到建立的混合神经网络模型中,从而使网络可以自动提取水稻文本特征,并进行分类,针对一些重要参数进行优化和改进,以实现水稻问句的自动分类。
1 文本预处理及模型构建
1.1 语料库构建
本文数据为从“中国农技推广”APP问答社区中导出的水稻提问数据,使用Python中的正则表达式对所获得的文本数据进行清洗和过滤,去除掉无用信息,对水稻提问数据进行人工标注,获得水稻病虫害、草害药害、高产增产、储存保鲜、栽培管理、其他共6个类别12 000条提问数据。水稻提问文本数据样例如表1所示。

表1 水稻提问文本数据
1.2 数据预处理
首先对文本数据的常用标点符号进行去除,清洗和过滤无用信息。然后加载农业专用停用词表,去除文本中的常用停用词、中英文特殊字符等影响特征提取的噪声。采用Python的JIEBA分词工具包对文本数据进行分词,由于农业文本数据具有较多的农业专用词汇,为了提高分词的准确度,选择搜狗农业词汇大全[24]作为分词字典。预处理前后文本数据如表2所示。

表2 预处理前后文本数据
1.3 数据向量化
由于神经网络不能识别自然语言文字,因此,本文采用 Word2vec[25]中SKIP-Gram[26]模型将分词结果转换为词向量。模型训练窗口设置为 5,词向量维度设置为100,训练并行数设置为2,迭代次数设置为25。Word2vec训练得到每个词的词向量储存到字典中,将水稻提问数据中的每个词转换成对应的词向量,例如“稻瘟病”的词向量如图1所示。由于每个问句的长度不是完全一致,将提问数据长度设置为100,长度不足100的,在后面用0补齐,保证每一条提问数据向量长度一致,才能输入到神经网络中。文本预处理流程如图2所示。
1.4 基于注意力机制的密集连接卷积神经网络
本文提出的基于注意力机制的密集连接卷积模型(Attention_DenseCNN),包括密集连接的卷积,注意力机制和Softmax分类层,模型结构如图3所示。首先将水稻问题文本数据预处理向量化之后输入到密集连接卷积网络层进行特征自动提取,密集连接CNN包含多个卷积块,每个卷积块都包含卷积、批次标准化(Batch normalization)和激活函数ReLU,卷积块流程如图4所示。为了更进一步选取特征,将提取的特征输入到注意力机制层进行权重重置及特征选择,最后将提取的特征向量输入到分类层。
1.4.1密集连接的CNN
针对水稻提问文本数据特征的稀疏性,通过卷积块之间的密集连接加强文本特征的传输,通过特征的不断重复学习,增强文本特征在各卷积块之间的流动,使得模型能够自动提取和学习文本特征。密集连接的CNN允许网络的每一层直接连接到之前的所有层,以实现特征的重复使用,这种连接有助于提高水稻问句特征的整体利用率。同时将网络的每一层设计的非常狭窄,即只学习很少的特征映射来减少冗余。本文采用密集连接的CNN来提取问句的高层语义特征。每一层连接到通道维度中的上一层,并作为下一层的输入,每个层都会接收其前面所有层输出作为其额外的输入,传统的卷积神经网络模型都是采取固定的卷积核尺寸来提取特征,为了提取可变长度的文本特征,本文在每个卷积块都采用不同宽度的卷积核提取特征,卷积块包含卷积层、批量标准化和ReLU激活函数。卷积层主要提取水稻问句向量矩阵的特征。批量标准化可以防止梯度消失,提升学习收敛速度,缩短模型训练时间。ReLU激活函数用来将输入的数据做非线性映射。每个卷积块可以形式化为
Xl=f(Wl,[X1,X2,…,Xl-1])(Wl∈R(l-1)k2w)
(1)
式中f——复合函数,包括卷积、Batch normalization和ReLU 3个步骤
l——卷积块层数Xl——第l层特征
Wl——第l层的权重矩阵
k——卷积核个数w——窗口尺寸
比如已经得到X1和X2,分别进行卷积操作得到2个m×k的矩阵,然后进行相加得到X3。除了输入,由于注意力机制的需要,所有特征图的尺寸都设置成m×k。这种结构就可以使得上游卷积块的词或者短语可以被后续结构使用,得到大尺度的特征。
1.4.2注意力机制层
针对水稻提问文本数据长度较短,词汇量较少,文本稀疏性等特点,本文使用注意机制来有效地利用通过密集连接卷积神经网络得到的特征进行分类。在注意力机制层,利用注意力机制来强化关键词特征在水稻提问数据中的权重,解决了文本特征稀疏性导致的关键词权重较低的问题,注意力机制为每个特征向量分配不同的权重,以反映它们在问题中的作用。权重越大,语义越重要,并将影响整个问题的最终分类。该部分包含滤波器集合和尺度权重重置两步操作。连接起来之后经过MLP得到各部分的权重αi。具体计算公式为
(2)
(3)
(4)
MLP——多层感知器函数
αi——用于输入分类器的权重向量
1.4.3Softmax分类层
在输出层,以注意力机制层的输出作为输入,并使用Softmax计算每种分类的概率,再将概率归一化到(0,1),最后以最大概率输出水稻提问文本数据对应的具体类别。
1.5 模型训练
本文使用随机梯度下降(SGD)对模型参数进行优化。随机梯度下降算法是每次训练一个样本和类别标签对参数进行更新,其更新公式为
(5)
式中J(φ)——目标函数
φ——参数η——学习速率
x(i)——样本y(i)——类别标签
本文使用交叉熵损失函数来评判当前训练得到的概率分布与真实分布的差异性,如果该类别和样本的类别相同就是1,否则是0,交叉熵损失函数公式为
(6)
式中M——类别数量c——类别
y——指示变量,取0或1
p——对于观测样本属于类别c的预测概率
2 试验及结果分析
2.1 硬件、软件环境和评价指标
试验软件环境为Python 3.6.2和TensorFlow 1.13.1,服务器硬件环境为:显卡NVIDIA Corporation Device 1e04 (rev a1),GPU:NVIDIA GeForce RTX 2080Ti。使用Keras神经网络框架构建网络。从建立的水稻问答语料库中提取出水稻提问数据作为试验数据,将水稻提问文本数据进行人工标注。分为病虫害、草害药害、高产增产、储存保鲜、栽培管理、其他6个类别,共计12 000条提问数据,问题类别数据具体分布见表3。将12 000条提问数据随机打乱顺序后,按照9∶1的比例划分为训练集和测试集,训练集共10 800条,测试集1 200条,训练集用于模型训练及调整神经网络参数,测试集用来验证模型效果及反馈时间。本文以精确率P、召回率R和F1值作为评价指标。

表3 水稻问题类别分布
2.2 参数设置
通过Word2vec转换的词向量维度设置为100,问句最大长度设置为100,神经网络的输入就是(100×100)维的向量矩阵,模型训练次数设置为50轮,每批次输入64条,学习速率设置为0.01。
由1.4节可知,密集连接的卷积神经网络拥有多个卷积块,通过一组试验来测试在不同数量卷积块下模型的分类效果,设置卷积块个数分别为3、4、5、6,精确率分别为94.3%、94.7%、95.0%、94.6%,可知当卷积块个数为5时,模型分类效果最佳。
卷积模型在提取文本特征时,卷积核的长度与文本向量的维度相同为100,在不同卷积块中采用不同的卷积核宽度来提取可变的文本特征。通过一组试验来研究不同宽度的卷积核对问句分类精确率的影响。如表4所示,在5个卷积块中,卷积核宽度分别为2、3、4、5、6时,模型的分类精确率最高。

表4 不同卷积核宽度下模型分类效果
通过一组试验来研究卷积滑动窗的步长对Attention_DenseCNN模型影响。设置步幅分别为1、2、3、4。除了步幅,其他参数都保持不变。本文所提出的模型在卷积步幅分别为1、2、3、4时的问句分类精确率分别为95.0%、95.6%、94.2%、92.7%。在步幅增大过程中,Attention_DenseCNN对于数据集的分类精确率会在步幅为2时达到95.6%。相比于步幅为1时精确率提高了0.6个百分点,这是由于卷积滑动窗口在步幅为2时能更好地提取文本特征,表达文本信息。而在步幅为3和4时,精确率开始下降,分别为94.2%和92.7%。这是由于步幅过大,在提取特征时会丢失更多的语义信息。
2.3 问句分类模型分类结果与评价
首先使用密集连接卷积神经网络(DenseCNN)、基于文本的卷积神经网络(TextCNN)[15]、长短期记忆网络(LSTM)[27]、门控循环单元网络(BiGRU)[28]、基于注意力机制的长短期记忆网络(Attention-LSTM)[29]5种神经网络模型对水稻问句数据进行试验。表5展示了不同深度学习模型在精确率、召回率和F1值的比较。从表5可以看出,在基本的对比试验中,TextCNN与3个循环神经网络的F1值相似,证明了卷积神经网络在水稻问题分类中有很好的性能。DenseCNN获得了最高的F1值和精确率,这是由于通过密集连接的卷积块可以加强特征的传递和提取,减少特征损失,有利于最后的分类效果。基于注意力机制的LSTM相比于LSTM有更好的精确率、召回率和F1值,但略低于DenseCNN,这说明了注意力机制在训练过程中通过权重重置,可以更好地表达特征信息。

表5 5种神经网络模型效果对比
将注意力机制与上文提到的4种神经网络模型相结合,得到Attention_DenseCNN模型、Attention-TextCNN模型[30]、Attention-LSTM模型[29]、Attention-BiGRU[31]模型,进行水稻问题分类试验。表6展示了不同深度学习模型在精确率、召回率和F1值的比较。通过比较每种模型的F1值及精确率,可以发现在水稻问句文本数据集下,DenseCNN模型在训练效果上优于TextCNN模型,这是由于在DenseCNN模型中是通过密集连接的5个卷积块来提取特征。相比于传统的卷积神经网络模型在特征传递时只是将上一层的输出作为本层的输入,DenseCNN在传递特征时不仅接收上一层的输出,还将接收之前所有层的输出作为额外输入,可以有效减少文本特征的丢失。通过密集连接的CNN,文本特征可以更好地传递和表达,最终提高文本分类效果。从表6可以看出,Attention_DenseCNN模型的精确率、召回率和F1值最高。其精确率为95.6%,召回率为94.3%,F1值为94.9%。F1值比Attention-TextCNN提高2.8个百分点。将加入注意力机制后的4种模型与未加入前的模型进行对比分析,可以发现,精确率分别提升了0.9、1.9、1、0.7个百分点,F1值分别提升了1、1.9、1.5、1.3个百分点。这说明注意力机制能使模型在训练过程高度关注目标的特征信息,从而更好地识别特定目标的类别,验证了注意力机制在问句分类任务中的有效性。

表6 不同模型下问句分类效果对比
图5和图6分别展示了8种神经网络模型的F1值趋势。Attention_DenseCNN的收敛时间明显提前,并且每个模型在训练过程中不会出现大的振荡。另外,Attention_DenseCNN在前20个轮次大致可以收敛,在随后的训练中F1值保持最高。
表7展示了使用Attention_DenseCNN模型对水稻提问文本数据,在草害药害、高产增产、病虫害、储存保鲜、栽培管理、其他共6个类别分类的精确率、召回率及F1值。Attention_DenseCNN模型分类平均精确率达到了95.6%,召回率达到了94.3%,F1值达到了94.9%,体现了良好的分类效果。本文提出模型在病虫害类别中精确率和F1值明显高于其他5个类别,达到了99.1%和99%,这是由于深度学习模型需要大量的数据支撑,病虫害作为水稻种植过程中经常遇到的问题,其文本数据占到整体文本数据的1/3,因此分类精确率及F1值最高,而在储存保鲜类别中精确率及F1值最低,说明数据量过小,会影响模型的分类效果。
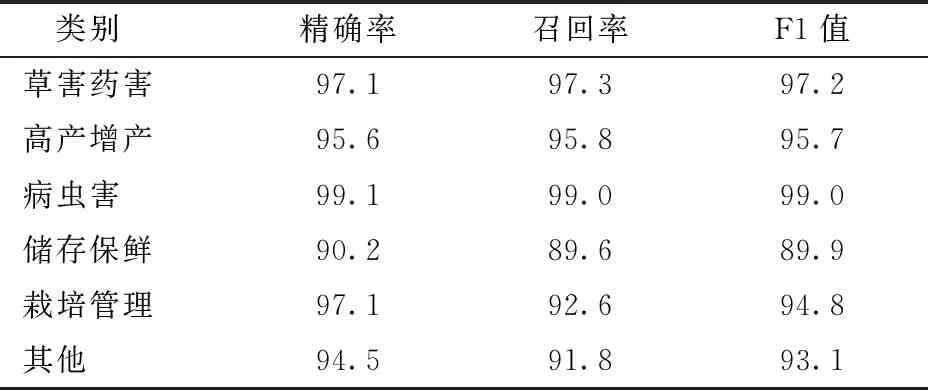
表7 Attention_DenseCNN模型分类结果
表8展示了基于注意力机制的4种神经网络模型在1 200条测试集上的响应时间和精确率,达到了对水稻问句快速分类的要求,Attention-TextCNN的响应时间最短,这是由于Attention-TextCNN模型结构简单,训练层数和模型参数较少。本文提出的Attention_DenseCNN模型在5 s可以完成对测试集1 200条水稻问句进行精准分类,精确率达到了最高(94.7%),在响应时间相差不大的情况下,本文提出的模型在精确率方面具有更好的效果。

表8 4种网络模型的响应时间和精确率
3 结论
(1)采用Word2vec和农业词汇专业词典对文本进行向量化,有效解决了水稻问句文本的稀疏性和高维性。使用基于注意力机制的密集连接卷积神经网络构建水稻问答系统问句自动分类模型,可以快速、准确地实现水稻问句在6个类别上的自动分类,避免了浅层学习模型耗时、分类效果不佳的问题,模型精确率达到95.6%,F1值达到94.9%,与其他7类文本分类模型相比优势明显。
(2)使用注意力机制对文本关键词特征进行权重重置,强化了关键词在水稻问句中的作用,切实解决了水稻问句特征不足的问题,提出的Attention_DenseCNN相比DenseCNN,水稻问句文本分类精确率和F1值均提高了1.9个百分点。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
小雪花·成长指南(2022年1期)2022-04-09
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
北京航空航天大学学报(2017年12期)2017-04-23
第二课堂(课外活动版)(2016年2期)2016-10-21
