
基于语料库的俄语双译本《诗经·国风》词汇翻译特点对比研究
2021-07-27 02:08杨蕊
科技资讯 2021年7期
杨蕊

摘 要:语料库利用统计学方法,统计分析大量真实生活语料,并通过筛选分析数据得出结论,具有传统方法无可比拟的高效性、客观性和真实性。该文以苏联时期施图金及当代俄罗斯阿布拉缅科的2个俄译版《诗经·国风》为研究对象,对其词汇层面的翻译特点进行对比研究。该文是将语料库与文学翻译结合的常识性探索,对语料库语言学、翻译学等有借鉴意义。
关键词:语料库 诗经 翻译 施图金 阿布拉缅科
中图分类号:H059 文献标识码:A文章编号:1672-3791(2021)03(a)-0001-04
comparative study of lexical translation features in two Russian versions of The book of songs guofeng
on the basis of corpus
YANG Rui
(Harbin University of Science and Technology, Harbin, Heilongjiang Province, 150080 China)
Abstrac:Corpus uses statistical methods to analyze a large number of real life date, and draws conclusions through screening and analyzing data, which has incomparable efficiency, objectivity and authenticity of traditional methods. This paper makes a comparative study of the lexical features of two Russian versions of The book of songs·Guofeng, by Shtukin in the Soviet Union and by Abramenko in Contemporary Russia. This paper is a common sense exploration of the combination of corpus and literary translation, which can be used for reference in corpus linguistics and translation studies.
Key words: corpus; The book of songs; translation; Shtukin; Abramenko
基于语料库的研究方法是语料库语言学的重要分支,具有传统方法无可比拟的特性。随着翻译学研究内容的不断深化和语料库技术的日臻完善, 语料库研究与传统译学、描写性译学等领域不断融合, 兼备了理论依据和实证工具, 成为当前翻译学研究的新范式[1]。
《诗经》作为收录内容时间跨度长达5世纪的中国先秦时期诗集,不仅是中国古代最早的诗歌总集,更是中国古代早期社会面貌的真实写照,开创了古代中国关注社会、关注民生的现实主义文学传统。中国典籍是中国文化的核心,以《诗经》为代表的儒家经典体现了中国文化最基本的价值理念和民族文化特色。其在域外的翻译和传播,可以说是中国典籍走出去的一个代表和缩影[2]。
该文基于语料库方法对苏联时期及当代俄罗斯时期的2个俄译版《诗经》词汇翻译特点进行对比分析。1957年,苏联科学院东方学研究所中国文学研究室研究员施图金完成了俄文全译本《诗经》,第一版由苏联科学出版社于1957年出版[3]。当代俄罗斯时期的《诗经》译本为俄罗斯科学院远东研究所学者阿布拉缅科的俄语全译本。
1 《诗经 国风》语料库的建立
分别建立施图金和阿布拉缅科两个版本译本的单语语料库,使用WordSmith 4.0软件对建立完成的单语语料库分别进行词汇层面和句子层面的统计分析,以得出二者翻译风格特点、词汇难度等信息。采用WordSmith系列软件进行相关信息分析,在前期建立语料库时只需准备纯净的txt格式文本,通常采用Unicode编码方式保存文本,进行语料分析时直接导入WordSmith软件即可。
1.1 语料的准备
对两个版本《诗经·国风》译本进行整理,另存为Unicode编码方式后生成生语料库,仅保留原文中的标点及必要的换行符,注意文件名称尽量使用英文字母。
1.2 语料的分析
WordSmith软件是语料库语言学中的常用软件,支持英文及其他小语种文本的分析和检索,主要包括3个板块——Concord(词汇检索工具)、Keyword(关键词表工具)、Wordlist(词频列表工具)。
1.2.1 词频分析
使用WordSmith 4.0软件中的Wordlist功能对双译本《诗经 国风》部分分别进行词频分析,将整理好的清洁语料库文本导入得到词频列表。对显示的结果进行词性还原(Lemmatization)所得表格中的数据实际上是经过词性还原(Lemmatization)后的结果,对于未经标注的小语种生语料库,词频列表工具的结果需要进行手动词性还原。节选前30个高频词汇进行分析,两个版本译本中的前3个高频词均为В、Не和Я,说明两段译文采取的翻译格式大体相同。阿布拉缅科版的前30个高频词中实词有11个,施图金版中有13个。两个版本译文的在高频词汇的应用上都以简单易懂的词汇为主,没有过多的长难词汇,这在一定程度上说明两个版本的译本词汇难度都不大,但在信息承载量上略有區别。
1.2.2 类符形符比
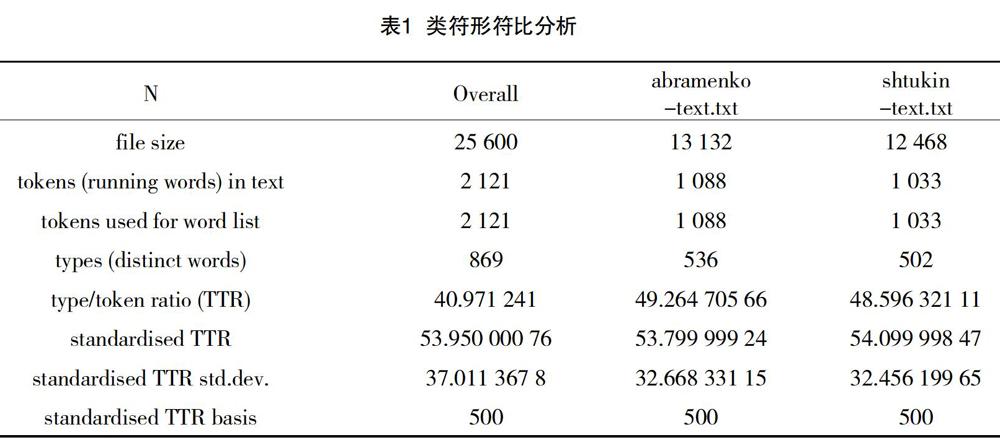
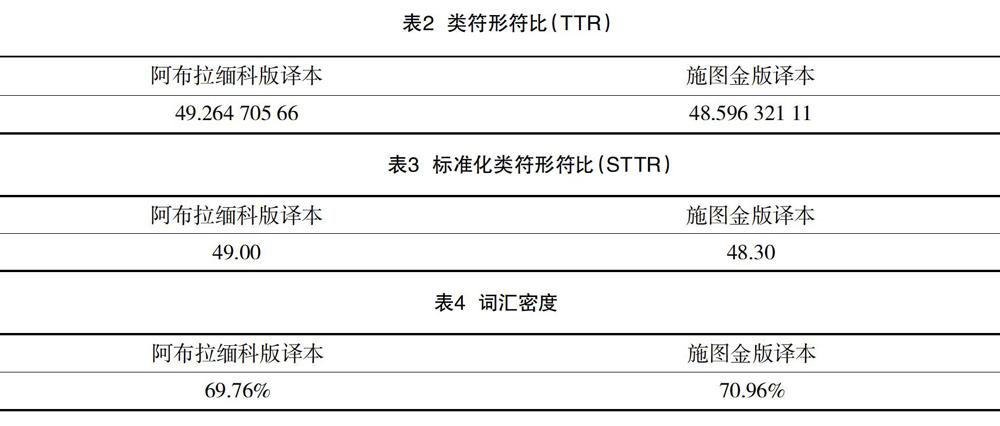
在上一节所得到的Wordlist列表界面,点击下方的statistic按键,可以看到该语料库的详细数据。表1中Overall竖列为两个语料库的总数据,abramenko-text.txt和shtukin-text.txt分别为两个译本的数据。token数(即形符)阿布拉缅科版为1 088个,施图金版为1 033个;type数(即类符)阿布拉缅科版为536个,施图金版为502个,由此可以得出类符形符比(TTR)见表2。
类符形符比是指语料库中类符(type)与形符(token)之间的比例,在一定程度上能够体现语料的用词变化性,但当较长的语料文本出现时,类符形符比已经不能全面、直接地衡量词汇的变化程度了[4]。为准确地反映一篇语料的语言复杂程度,还需要对类符形符比进行标准化处理,也就是标准化类符形符比(standard TTR)。标准化类符形符比是指在每个单位容量的语料中去计算类符形符比,再对结果进行平均所得到的类符形符比。由于该文研究的对象语料库词汇容量均大于1 000,所以该文取1 000个词汇为标准化类符形符比的单位容量,进行标准化处理后的类符形符比见表3。
(1)词汇密度。
词汇密度是指一个样本中有实际意义的词语占总词数的百分比。语料库语言学中句子中的词汇大致分为两大类,即起到维持结构作用的语法类词语和确定句子主要意思的实义词。语法类词汇主要是一些代词、连词和一部分副词;实义词主要是名词、动词、形容词以及大部分的副词。在语料库语言学中,词汇密度指的是实词占总词数的比例。一般而言,词汇密度与文本的信息量以及文本的难易度有关,词汇密度越大,文本的信息量就越大,文本的难度系数就相对越高[5]。对词性还原(Lemmatization)后的Wordlist列表进行筛选,在Excel表格中分别统计出两个版本译本的实词数,带入词汇密度计算公式,即词汇密度=实词数/总词数×100%,得到词汇密度如表4所示。
(2)平均词长。
平均词长是指一个语料库中词汇长度的平均值,能够反映一个语料文本的词汇难度。平均词长越长,在一定程度上可以说明语料文本中的长词越多;反之则说明语料文本中长词越少。WordSmith的Wordlist功能可以统计出文本中各个长度词汇的数量,并计算出平均词长。表5为WordSmith得出的两个俄译本平均词长及各个长度的单词数量。由于各个语料文本的容量可能不同,所以直接统计出来的各长度单词数量不具有可比性,此时需要转换成百分数占比方可进行比较。
2 基于语料库的《诗经》词汇翻译特点分析
基于语料库的方法建立在统计学方法和语言学方法的基础上,用真实的语料库统计数据,反映各个方面的语言学特性,从而能够更加科学、客观地比较不同译本的语言翻译特点。
2.1 类符形符比对比
该小节基于前文得出的标准化类符形符比,在词汇变化和丰富度上对两个版本俄译本进行比较。
从表6中的数据可以看到在语料样本容量相差不多的情况下(差值不超过6%),阿布拉缅科版译本的sTTR值要略高于施图金版译本,这说明阿布拉缅科版译本在词汇丰富度和变化上要比施图金版译本更高,而施图金版译本则更加简洁。例如:《国风·召南》中的《江有汜》篇,阿布拉缅科版类符数为40个,而施图金版形符数仅31个。施图金译本变化的语言较阿布拉缅科版稍少一些,他在翻译的时候会表达自己的理解;阿布拉缅科则更加注重精确还原原文。这一点上也符合了施图金的导师阿列克谢耶夫对该版译本的评价—— 语言简单明了,便于读者理解内容,以及阿布拉缅科在翻译中国古代经典作品过程中对原文的精准把控[6]。
2.2 词汇密度对比
基于词汇密度对两译本进行信息承载量和文本理解难易程度方面的分析对比。在表4词汇密度中,阿布拉缅科版的词汇密度为69.76%,而施图金版为70.96%。二者相差的原因在于阿布拉缅科尽可能地忠实于原文,同时在此基础上保留了俄文中诗体的工整和韵律,赋予读者对诗歌充分想象和理解的空间;而施图金在翻译的过程中挖掘了诗歌深层的含义,补充了一些诗歌中省略的内容,但总体上还是比较贴近原文所要表达的含义,因此二者词汇密度虽有差距但相差不大。
2.3 平均词长对比
基于平均词长数据比较分析译本词汇复杂程度方面的特点。根据上一章的数据,阿布拉缅科版译本平均词长为4.659个字母,施图金版为4.609个字母,二者平均词长相差并不大,且均未超过5个字母,整体词汇难度相对简单。这主要是因为《诗经》记录的内容均为周代民歌,反映的主题多为平民百姓的日常生活,词汇大都平实朴素,说明两个译本均在大体上较为忠实于原著,只是施图金版在一些句子的翻译中稍微加入了自己的理解。由于6个字母及以下的词语多为一些常见词汇和简单词汇,该节只选取7个字母长度以上的词汇频率对两个版本的长词使用情况进行分析比较,结果如表7所示。
从表7中可以看出阿布拉缅科版的长词频率为21.33%,施图金版为20.03%,阿布拉缅科版译本略微高于施图金版。对数据进行卡方检验,带入拟合度公式,得到卡方值为0.503 1,拟合概率约在0.5~0.4之间,表明两个版本译本在长词使用情况方面有一定的相似性,阅读难度大体相类似。
通過类符形符比、词汇密度和平均词长总结阿布拉缅科和施图金译本词汇层面的翻译特点——前者注重原文,力求用俄语原汁原味地表达《诗经》的本意;后者版本则在不过多变更原文的基础上加入了自身对《诗经》所要表达的主旨的理解。两个版本译本词汇运用难度上大致相仿,长难词汇的运用量有一定相似性,且均无过多的高难度词汇,对读者理解有帮助。
参考文献
[1] 许明武,赵春龙.国内语料库翻译学研究的名与实[J].上海翻译,2018(4):3-9,94.
[2] 刘永亮.理雅各《诗经》翻译出版对中国典籍走出去之启示[J].中国出版,2016(13):63-65.
[3] 王文霞.基于语料库的《诗经·国风》英译文本中显化现象研究[J].海外英语,2019(17):230-231,243.
[4] 王姗姗.《诗经》与其注疏文献的句子对齐研究[D].南京农业大学,2018.
[5] 王汝蕙.基于语料库的翻译共性研究——以《生死疲劳》英译本为例[J].中国现代文学研究丛刊,2020(9):181-193.
[6] 魏海玉.基于语料库的《中国日报》和《纽约时报》体育报道文体对比研究[D].黑龙江大学,2018.
猜你喜欢
意林彩版(2022年4期)2022-05-03
意林彩版(2022年2期)2022-05-03
知识文库(2019年22期)2019-11-11
师道·教研(2017年11期)2017-12-10
商场现代化(2016年22期)2016-10-18
学苑创造·A版(2016年9期)2016-10-10
考试周刊(2016年77期)2016-10-09
改革与开放(2010年6期)2010-06-04
祝您健康(1989年1期)1989-12-30
