
基于BERT与XGBoost的航天科技开源情报分类
2021-07-26 02:34刘秀磊孔凡芃谌彤童刘旭红
郑州大学学报(理学版) 2021年3期
刘秀磊,孔凡芃,谌彤童,刘旭红
(1.北京信息科技大学 网络文化与数字传播北京市重点实验室 北京 100192;2.北京信息科技大学 数据与科学情报分析实验室 北京 100192;3.北京跟踪与通信技术研究所 北京 100192)
0 引言
航天科技开源情报[1]的分类问题是航天情报工作开展的第一步。如何利用机器学习的新技术来提升航天科技开源情报的分类效果,是当前航天情报学领域迫切需要解决的问题。
早期航天科技开源情报的分类研究主要集中于传统的机器学习方法,如文献[2]结合贝叶斯算法与web技术研发了一套服务器-客户端模式的航天文本分类系统。文献[3]研究了基于SVM的航天情报分类方法,并提出多分类流程以应对不同类别数据的分类操作。然而这些方法大都需要人工特征工程,且文本表示无法准确反映文本间的关系,不能保障较高的分类准确性。深度学习的广泛发展与应用,使得文本分类的效果得到显著提升。文献[4]提出基于Attention机制的TextRCNN-A文本分类算法,能够捕捉上下文内容信息,也可以更好地消除单词歧义。可见,在航天科技开源情报分类的研究中,能否准确捕捉到上下文语义信息对于提高相关文本分类的准确率具有一定影响。
传统的文本向量表示方法主要是词袋模型,如One-Hot直接映射表示方式[5]、基于词频的TF-IDF模型[6]等,但这些模型并未考虑词与词之间的关联性,且向量长度较大,易造成矩阵稀疏问题。后来出现了基于神经网络的文本向量化模型,如文献[7]提出的word2Vec模型,可用来表示词与词之间的关系。文献[8]提出的Glove模型可以利用全局统计信息,进行矩阵分解来获取词向量,但上述模型在表达多义词方面存在较大缺陷。由此,文献[9]提出Elmo模型,在获得预先训练的词向量后,根据实际上下文数据对向量表示进行动态调整,能够学到语法和语义等复杂的词汇用法。文献[10]提出了用Encoder-Decoder和Attention机制的Transformer模型,最大的优点是能够高效并行化。文献[11]提出了基于Transformer的双向编码器模型(bidirectional encoder representations from transformers,BERT),具有优秀的表达词句能力,该模型既提供了简单的接口来处理下游的自然语言处理任务,又可以作为预训练语言模型进行文档向量的研究,具有较强的迁移性。
通过对航天科技开源情报文本数据的分析发现,相关情报的文本内容较长,且含有大量的领域性专有名词,相关特点制约了航天科技开源情报分类的准确率,而现有的应用于航天科技开源情报分类任务中的模型不能很好地关注相关专有名词并提取情报的内容特征。基于此,本文提出基于BERT与极端梯度提升模型(extreme gradient boosting, XGBoost)[12]的融合模型用于航天科技开源情报的分类研究。利用BERT模型提取航天科技开源情报的关键特征,同时结合使用分类效果较好的XGBoost模型对BERT提取到的关键特征进行分类,从而提升分类准确率。
1 基于BERT-XGBoost的航天科技开源情报分类
1.1 BERT-XGBoost融合模型整体结构
本文提出的基于BERT-XGBoost融合模型的航天科技开源情报分类方法主要由两部分组成:一部分是基于BERT的航天科技开源情报特征提取;另一部分是基于XGBoost的航天科技开源情报特征分类,将情报数据进行向量化后作为BERT模型的输入,BERT模型的输出为给定长度的航天科技开源情报特征向量。
在融合模型的整体结构中,使用航天科技开源情报文本内容以及对应的分类标签训练出BERT分类模型,并使用梯度下降的策略不断调整模型,以得到分类准确率较高的模型。由于原BERT模型最后输出层的结果为相关文本的类别,所以在此模型的基础上,将模型最后的输出层改为线性输出,模型中其他层的参数不变,以此输出提取的特征向量。
当BERT模型作为编码器将航天科技开源情报映射成特征向量后,将特征向量与对应的文本分类标签一同输入至XGBoost模型中进行后续训练。由于XGBoost模型是一种决策树[13]集成算法,输入的特征向量会被构建成树,当初始树构建成功后,新的树会去修正模型中已有的树的误差,当模型分类结果中没有更多提升时,停止树的构建。所有树的叶子结点分数总和对应于评估划分类别的得分,选取得分最高的类别确定为最终划分类别。
利用XGBoost模型对BERT提取出的特征向量进行分类,能够使融合模型更充分地学习数据与标签之间的真实联系,以达到更加高效的分类效果。
1.2 基于BERT的航天科技开源情报特征提取
航天科技开源情报中存在较多专有名词,对航天科技开源情报的分类具有较大影响,由于Multi-Head Self-Attention机制可以精准地关注到文本中的关键信息,有利于捕捉到相关情报中的专有名词,所以本文利用内含Multi-Head Self-Attention机制的BERT模型对航天科技开源情报进行特征提取,从而实现更为精准的文本分类。模型特征提取结构如图1所示。输入一条航天科技开源情报数据到BERT模型中,经过模型的计算后输出对应的文本特征向量,作为后续融合模型中XGBoost模型的输入。

图1 模型特征提取结构图

Multi-Head Attention机制在Attention基础上,重复多次线性变换与点积计算的过程来实现Multi-Head,这样做可以让模型在不同表示的子空间里学习到更多上下文相关信息,从而可以更全面地捕捉到文本中的关键信息。以“美国陆军加速研发激光武器”为例,进行Attention的可视化,验证Multi-Head关注上下文信息的能力,结果如图2、3所示。

图2 One head可视化结果
图2、3中不同颜色块代表不同Attention头的结果,同一种颜色的程度越深,Attention值越大,线条两端的字符依赖关系也越强。从图2 one head的结果可以看出“激”这个字只能学习到和“激”的依赖关系,而图3 two head的结果中“激”可以同时学到“激”、“光”的依赖关系,从而验证出Multi-Head可以从不同的表示子空间里学习相关信息。

图3 Two head可视化结果
由此可见,Multi-Head Self-Attention机制可以有效地关注航天科技开源情报中的专有名词,有利于模型的特征提取,为后续利用XGBoost模型进行特征分类做好准备。
1.3 基于XGBoost的航天科技开源情报特征分类
XGBoost模型可以基于特征粒度上并行,相较于softmax分类器及线性分类器来说,XGBoost模型可以更加充分地利用数据特征拟合数据。因此利用XGBoost模型对BERT提取出的特征向量进行分类。XGBoost使用梯度上升框架,核心是最小化第k棵树的残差。XGBoost使用二阶泰勒展开公式来求解目标函数,展开后公式为

XGBoost模型涉及诸多参数,参数的调节对于模型的训练至关重要,其主要参数如表1所示。Booster参数选择gbtree,该参数值表示采用树的结构来运行数据,符合本文提取的特征分类;由于航天科技开源情报文本类别共有5个,所以类别数量参数Num_class取值为5;Max_depth表示树的深度,一般取值在5到10之间,本文取值为8;多分类问题决定Objective的参数值选择multi:softmax;其他参数按照一般要求设置。

表1 XGBoost模型主要参数
由于BERT模型对航天科技开源情报提取出的特征向量较为复杂,为了能够更好地考虑这些复杂特征对相关文本分类效果的影响,选取XGBoost模型对BERT提取出的特征向量进行分类。
将航天科技开源情报进行向量化,表示为x,用于训练BERT模型,最终输出特征向量Outputvec;将原始分类标签y与BERT输出的特征向量共同组成XGBoost模型的输入Inputx;通过XGBoost模型输出最终的分类结果。具体公式为Outputvec=BERT(x),Inputx=(Outputvec,y),Outputfinal=XGBoost(Inputx)。
融合模型训练过程的伪代码如下。
算法1BERT 与XGBoost融合模型应用于航天科技开源情报分类训练过程。
Input dataoriginal:航天科技开源情报原始文本;modelpre:预训练模型BERT-Base,Chinese;
Output Test set error rate: Testerror; modelBERT: the BERT model after training;
modelXGBoost: the XGBoost model after training;
1)model=Load(modelpre);∥加载中文预训练模型
2)data,label=DataProcessing(dataoriginal); ∥数据预处理
3)datainput=DataVectorization(modelpre,data); ∥文本数据处理成BERT模型输入数据
4)datatrain, datadev, datatest=SplitData(datainput); ∥划分数据集
5)modelBERT=Train(model,datatrain,datadev)
6)features=OutputFeature(datatrain,modelBERT); ∥BERT分类输出训练集特征向量
7)training the XGBoost model modelXGBoostwith features;
8)set the maximum number of iterations epochs;
9)set the initial bert error rate besterror;
10)initial epoch=0;
11)repeat
12)Train(datatrain, datadev, modelBERT); ∥训练BERT模型
13)features=OutputFeature(datatest,modelBERT); ∥BERT输出测试集特征向量
14)result=Prediction(features,modelXGBoost); ∥XGBoost输出分类结果
15)testerror=ComputError(result); ∥计算测试集错误率
16)if testerror<=berterrorthen
17)besterror← testerror;
18)Save(modelBERT);
19)features=OutputFeature(datatrain,modelBERT);
20)training the XGBoost model modelXGBoostwith features;
21)Save(modelXGBoost);
22)end if
23)Save(testerror);
24)until(epoch>epochs)。
2 实验分析
2.1 实验数据
本文实验数据是某平台所提供的公开科工资讯文本,来源于各大国防科技网站,总数据量为61 027条,主要类别为航天工业、船舶工业、兵器工业、航空工业与电子工业。本文借鉴文献[15]中文本预处理的方法,对航天科技开源情报数据中的无效信息进行清理,并将处理后的文本内容用于后续分类任务中。
经统计,航天科技开源情报各类别数据的数量差距较大,故在此基础上,设计数据均衡与非均衡两组实验作为对比。航天工业、船舶工业、兵器工业、航空工业与电子工业在均衡情况下的数据量均为4 053条,在非均衡情况下的数据量分别为13 454条、15 804条、4 053条、20 846条、6 870条,5个类别的均衡数据总量为20 265条,非均衡数据总量为61 027条。实验数据均按照约8∶1∶1的比例进行训练集、验证集与测试集的划分。
2.2 实验过程
本文在模型的训练过程中,依据BERT提取特征向量长度的不同设计了对比实验,根据数据集中不同类别的数据量差距较大的特点,设计了数据集均衡与非均衡情况下的对比实验,最后设计了融合模型与其他部分主流语言模型在相同数据集上的对比实验,以探究融合模型的分类效果。
2.2.1融合模型训练 本文融合模型中BERT模块用的是“BERT-Base,Chinese”模型,网络结构一共12层,隐藏层有768个神经单元,采用12头模式,共有110 M参数。模型训练过程中使用2.1节中提及的非均衡数据集。模型设置参数随机失活率为0.1、模型Epoch为3、学习率为5e-5。将提取到的特征向量输入到XGBoost模型中,以得到正确的分类结果。BERT训练损失和准确率及XGBoost训练错误率如图4、5所示。

图4 融合模型-BERT模块训练损失和准确率
由图4可知,BERT模型在迭代超过5 400轮后,训练集和验证集上的损失与准确率数据波动幅度变小,逐渐趋于稳定,验证集的准确率基本保持不变,说明模型训练拟合效果已达最优。由图5可知,XGBoost在训练之初,模型的训练错误率就比较低,推测可能是BERT较为精准地提取出了航天科技开源情报的特征,使得XGBoost模型在后续分类时能够取得较好效果。
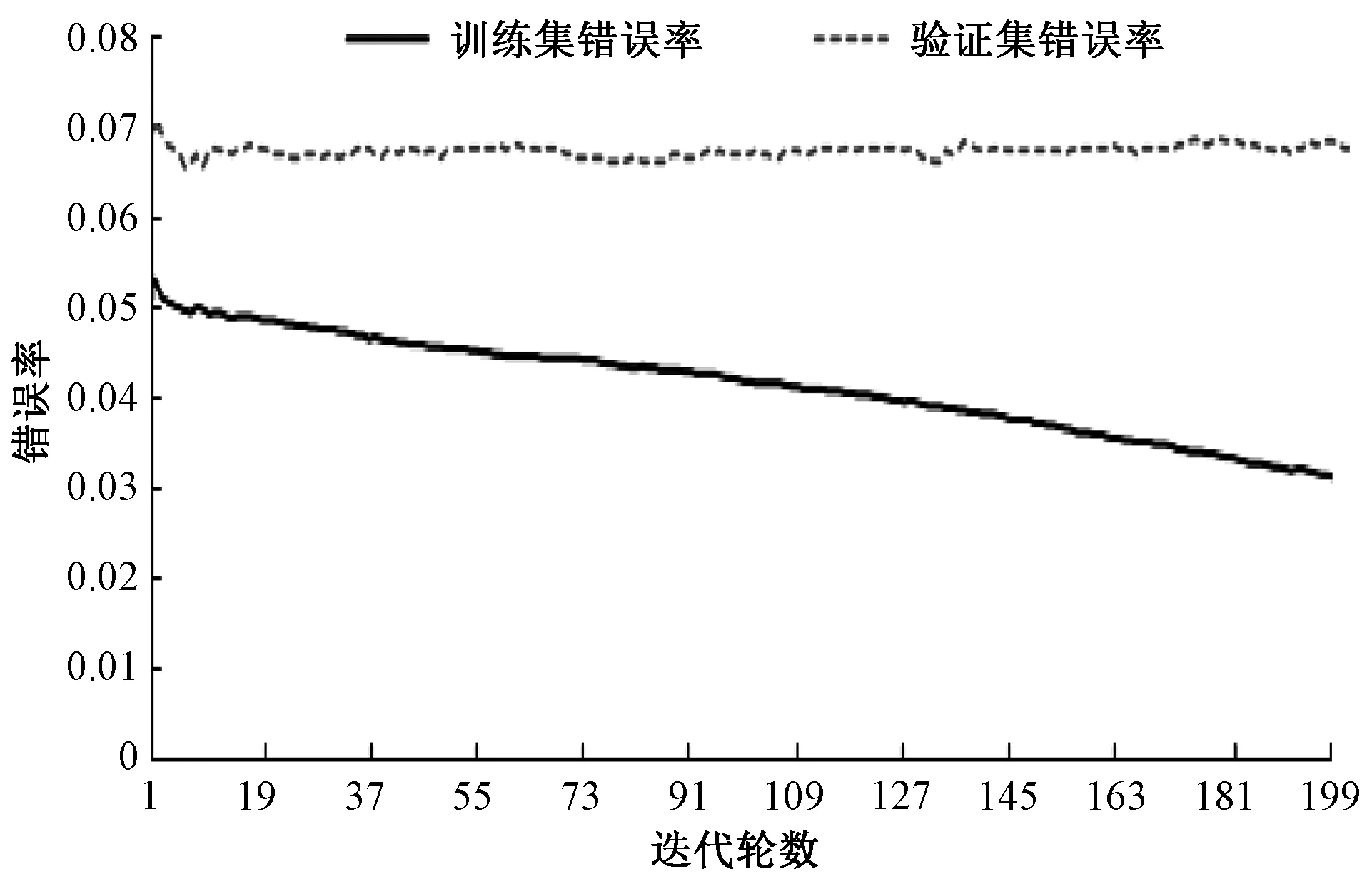
图5 融合模型-XGBoost模块训练错误率
融合模型最后在测试集上的准确率为90.01%,相较于相同参数下单独使用BERT模型进行分类的准确率提高了1.5%,说明融合了BERT与XGBoost的模型有利于提升航天科技开源情报的分类准确率。
由于融合模型中BERT模块提取的文本特征向量长度不同,信息量也不同,由此会导致模型分类准确率不同,因此设计对比实验,探究模型分类准确率随文本特征向量长度的变化情况,实验结果如图6所示。

图6 不同长度文本特征向量的模型分类准确率
由图6可知,随着提取的文本特征向量长度的增加,模型的分类结果表现出先升后降的波动变化,当提取的文本特征向量长度为110左右时,模型分类准确率最高达到90.02%。当提取的文本特征向量长度大于120时,考虑可能是由于文本特征向量过长导致模型提取的特征达到饱和,从而影响模型的分类效果,导致模型的分类准确率呈现波动降低态势。
2.2.2均衡与非均衡数据集对比 本文设计数据集均衡与非均衡情况下的F1值对比实验,来探究数据集对航天科技开源情报分类的影响。由于在实验2.2.1中得到结论,当BERT模块提取的特征向量长度为110时模型分类准确率最好,所以为了较全面的做对比,本文挑选大于110维及小于110维的特征向量长度进行实验,设置模型提取的最大文本特征向量长度分别为100维、110维和128维。融合模型在数据集均衡与非均衡情况下的测试集准确率如图7所示。融合模型在非均衡数据集下的准确率优于均衡情况,考虑到非均衡情况下的数据量多于均衡情况,推测可能是由于非均衡数据量较多使得模型的学习效果更好,由此分类准确率更高。同时本文采用了可以评价模型性能的F1值进行对比,结果如表2所示。当类别为“兵器工业”、“电子工业”时,均衡数据集下的F1值高于非均衡情况,考虑到这两个类别下的数据量相对最少,非均衡情况下其他类别的数据可能对这两个类别的数据分类产生干扰;当类别为“航空工业”、“船舶工业”时,非均衡数据情况下的F1值高于均衡情况,可能是因为这两个类别的数据量相对较多,使得非均衡情况下模型训练更为充分,学习到的特征更多,所以F1值更高。
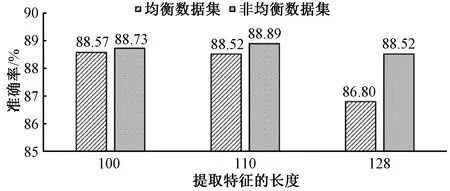
图7 融合模型在不同类型数据集下的分类准确率
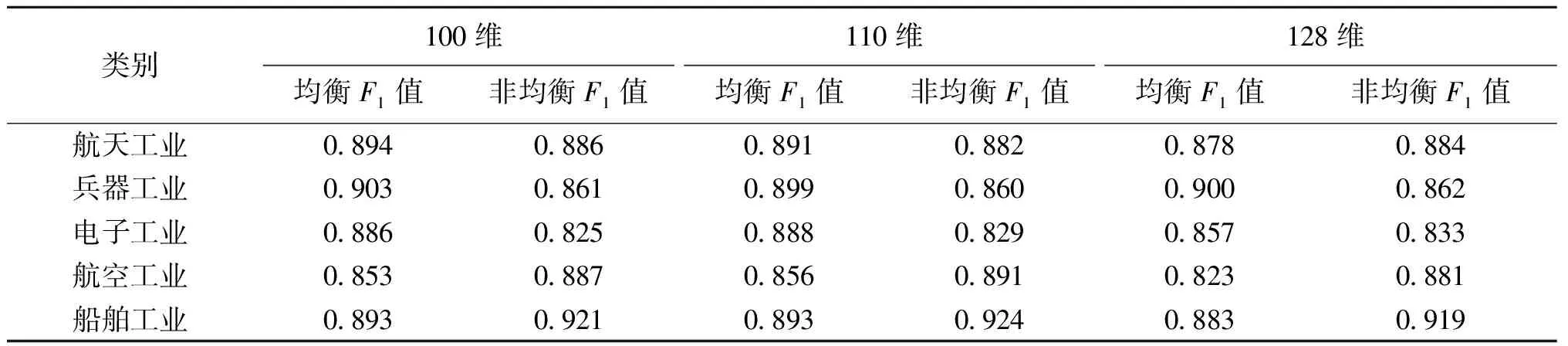
表2 数据集均衡与非均衡情况下 F1值对比
综合融合模型在测试集上的准确率结果以及在各类别上的F1值分析发现,模型在均衡数据集以及非均衡数据集上的F1值差距并不明显,但是在测试集上的准确率非均衡数据集结果均高于均衡数据集,因此非均衡数据集更有利于模型学习航天科技开源情报文本的特征。
2.2.3融合模型与部分主流语言模型对比 在本文融合模型提出之前,研究者们针对语言模型做了很多相关研究,如:基于CNN的TextCNN模型;基于BiLSTM的TextRNN模型等。本文在上文研究使用的数据集基础上,为部分主流语言模型设置了相同的基本超参数:随机失活率为0.5;迭代轮数为20;学习率为e-3;最大文本长度为256。同时将部分主流语言模型与本文提出的融合模型在航天科技开源情报分类任务中的表现做了对比,除上述提及参数设置相同外,根据2.2.1节的结论,设置融合模型中BERT模块提取的最大特征长度为110维。
BERT_XGBoost、BERT、TextRCNN、DPCNN、TextRNN、TextCNN、FastText以及Transformer模型在测试集上的准确率结果分别为90.01%、88.50%、88.16%、87.83%、87.27%、85.54%、85.06%、80.57%。可以看出,BERT_XGBoost融合模型在测试集上的准确率相较于其他主流模型更高,同时融合模型的分类准确率比单独使用BERT模型进行分类的结果高1.5%,说明融合模型的分类效果更好,能够在一定程度上提升航天科技开源情报分类的准确率。同时本文对比了各模型在不同类别下的F1值,其结果如表3所示。
从表3可以看出,在5个类别中,BERT_XGBoost融合模型的F1值结果相较于其他任何模型来说都是最高的,说明融合模型在这5个类别上的分类结果更为出色。

表3 各模型在不同类别下的F1值对比
综合融合模型与其他主流语言模型在测试集上的准确率结果对比,以及在各类别上的F1值对比,分析发现,相较于其他主流语言模型,融合模型的准确率更高,在各类别上的F1值也更高,说明融合模型更适合航天科技开源情报文本的分类,并且融合模型能够提升航天科技开源情报文本分类的效果。
3 结语
本文的主要工作是解决航天科技开源情报的分类问题,针对航天科技开源情报文本内容较长且含有大量专有名词的特点,提出BERT-XGBoost融合模型的分类方法,使用BERT模型提取出相关开源情报文本的特征,并利用XGBoost模型对BERT提取的特征进行分类。通过与部分主流语言模型在相同数据集上的准确率对比,验证了融合模型能够有效提升在航天科技开源情报文本分类上的准确率。但本文尚未研究数据集中存在的图片信息对分类效果的影响,且本文所用数据集规模较小,在后续的工作中,将尝试在融合模型的基础上融入图片信息用来丰富句子特征表示,同时研究融合模型在更大规模数据集上的分类性能。
猜你喜欢
体育师友(2022年1期)2022-04-17
保定学院学报(2022年2期)2022-04-07
中学生理科应试(2021年11期)2021-12-09
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
软件和集成电路(2020年8期)2020-11-28
创新作文(1-2年级)(2019年3期)2019-09-03
软件和集成电路(2019年7期)2019-08-30
