
基于ALBERT-CRNN的弹幕文本情感分析
2021-07-26 02:34温超东孙瑜敏
郑州大学学报(理学版) 2021年3期
曾 诚,温超东,孙瑜敏,潘 列,何 鹏
(1.湖北大学 计算机与信息工程学院 湖北 武汉 430062;2.湖北省软件工程工程技术研究中心 湖北 武汉 430062;3.智慧政务与人工智能应用湖北省工程研究中心 湖北 武汉 430062)
0 引言
随着数字媒体技术的快速发展,弹幕成为人们表达观点的一个重要途径,深受年轻用户的欢迎,并在哔哩哔哩、爱奇艺和腾讯视频等多个视频平台逐渐流行。弹幕评论在发送后直接同步显示在视频播放过程中,并在屏幕上从右到左如子弹般缓缓飞过,故网友称之为弹幕。相比普通文本,弹幕文本有着其独特的风格,不仅包含较多的网络词语和字符表情,且存在大量“同词不同义”的情况,给情感分析带来较大挑战。如“喜欢”这个词,在“我很喜欢up主的风格”这个句子中表示一种正向的情感,但在“男主总是喜欢搬弄是非”这个句子中表示一种倾向,不带任何感情色彩。传统的弹幕文本情感分析方法大多利用情感词典来判断弹幕文本的情感极性。文献[1]采用情感词典对弹幕文本中的词汇进行情感分析,得到词汇的情感强度并将其累加,从而得出弹幕文本整体的情感极性。文献[2]针对弹幕文本口语化的特点,建立了网络弹幕常用词词典,能够更好地识别弹幕文本中出现的网络词汇,并通过该词典计算弹幕文本的情感值,最终利用情感值对弹幕文本进行分类。近年来,随着深度学习的发展,越来越多的研究者将深度学习应用在弹幕文本分析任务中。文献[3]提出一种基于注意力机制的长短期记忆网络情感分析模型,用于帮助用户准确地获取弹幕文本中所包含的情感信息。文献[4]使用双通道卷积神经网络对文本进行情感分析,其中一个通道为字向量,另一个通道为词向量,解决了单通道卷积神经网络视角单一以及不能充分学习到文本特征信息的问题。文献[5]则提出一种基于奇异值分解算法的卷积神经网络模型,使用奇异值分解的方法代替传统卷积神经网络模型中的池化层进行特征提取和降维,有效提升了弹幕文本情感分析的效果。
虽然以上研究取得了不错的效果,但是由于弹幕文本中存在着大量“同词不同义”的情况,以上方法在进行特征提取时无法区分句子中同一个词在不同上下文语境中的不同含义,且在训练过程中不能兼顾文本中的局部特征信息和上下文语义关联,导致其分类准确率相对较低。因此,本文结合ALBERT预训练语言模型和卷积循环神经网络(CRNN)方法来分析弹幕文本的情感极性,提出一种弹幕文本情感分析模型ALBERT-CRNN。利用ALBERT预训练语言模型获取弹幕文本的动态特征表示,充分利用了句子中词的上下文信息,使得句子中同一个词在不同上下文语境中具有不同的词向量表达;使用CRNN对特征进行训练,充分考虑了文本中的局部特征信息和上下文语义关联,进一步提高了模型在弹幕文本情感分析任务中的准确率。
1 相关工作
深度学习技术在情感分析中应用的前提是解决词映射问题,即将文本转化为机器可以识别的数字,常用的方法是针对文本训练词向量。Mikolov等[6-7]提出Word2Vec模型,其本质为一种神经网络概率语言模型,包括CBOW和Skip-Gram两种模型,但通过该模型训练出的词向量为静态词向量,舍弃了文本中大量词语的位置信息,不能表示出文本的完整语义。Devlin等[8]在ELMo[9]和GPT[10]的基础上提出了BERT预训练语言模型,该模型通过使用双向Transformer[11]编码器对语料库进行训练得到文本的双向编码表示,且训练出的词向量为动态词向量,使得句子中同一个词在不同上下文语境中具有不同的词向量表达。
增大BERT预训练模型的规模能提升下游任务的效果,但受计算资源的限制,所需的训练时间较长,且进一步提升模型的规模将导致显存或内存不足。为此,Lan等[12]提出ALBERT模型,该模型是基于BERT模型的一种轻量级预训练语言模型,采用双向Transformer获取文本的特征表示,且大大减少了模型中的参数,并在多项自然语言处理(NLP)任务中取得了最佳效果。为准确判断弹幕文本的情感倾向,特征分类算法的选择也尤为重要。Kim[13]提出文本卷积神经网络模型(TextCNN),使用不同尺寸的卷积核对文本局部特征进行训练,实现了句子级别的分类任务,并取得了较好的分类效果。Socher等[14]将循环神经网络(RNN)应用到NLP任务中,在进行文本特征训练时能够较好地利用上下文信息。然而,传统RNN存在梯度爆炸和消失问题,处理长序列文本的效果并不理想。Hochreiter等[15]提出长短期记忆网络(LSTM),解决了传统RNN的梯度爆炸和消失问题。之后,Dey等[16]提出了门控循环单元(GRU),在保持LSTM效果的同时使得模型结构更加简单。
卷积神经网络(CNN)虽然能够高效地利用文本的局部特征信息,但无法获取上下文信息;双向门控循环单元(BiGRU)虽然能够有效地获取文本的上下文信息,但由于自身循环递归的特性,网络结构复杂度较高,时间代价较大。文献[17]结合CNN和BiGRU的网络结构优势,提出基于注意力机制的CRNN文本分类算法,既能利用CNN训练局部特征的优势,又能利用BiGRU获取上下文语义信息的优势,提升了文本分类的准确率。然而,由于其在提取文本特征时采用的是传统的Word2Vec模型,导致其舍弃了大量词语的位置信息,无法表示出文本的完整语义。综合以上研究,本文将ALBERT预训练语言模型与CRNN相结合,提出了一种基于ALBERT-CRNN的弹幕文本情感分析模型,并通过与其他模型的对比实验证明了其在弹幕文本情感分析中的有效性。
2 基于ALBERT-CRNN的弹幕文本情感分析模型
本文提出的ALBERT-CRNN弹幕文本情感分析方法主要包括以下步骤。1)对弹幕文本数据进行清洗和预处理,筛选出具有情感极性的弹幕文本数据,并打上相应的标签。2)使用ALBERT预训练语言模型获取弹幕文本的动态特征表示。3)使用结合CNN与BiGRU的神经网络模型CRNN对文本特征进行训练,获取每条弹幕文本的深层语义特征。4)利用Softmax函数对文本深层语义特征进行分类,最终得出每条弹幕文本的情感极性。
2.1 ALBERT预训练语言模型
2.1.1ALBERT模型结构 ALBERT预训练语言模型采用双向Transformer获取文本的特征表示,其模型结构如图1所示。其中,E1,E2,…,EN表示序列中的每一个字符,经过多层双向Transformer编码器的训练,最终得到文本的特征向量表示T1,T2,…,TN。Transformer的模型结构为Encoder-Decoder[18-19],ALBERT采用的是其Encoder部分,该部分由多个相同的基本层组成。其中,每个基本层包含两个子网络层:第一个为多头自注意力机制层;第二个为普通前馈网络层。

图1 ALBERT模型结构
2.1.2ALBERT模型对BERT模型的改进 为减少BERT模型的参数和增强模型的语义理解能力,ALBERT模型在BERT模型的基础上主要进行了两点改进。首先,ALBERT模型通过嵌入层参数因式分解和跨层参数共享方法有效减少了BERT模型中的参数,大大降低了训练时的内存花销,并有效提升了模型的训练速度。其次,为弥补Yang等[20]提出的BERT模型中NSP任务存在的缺点,ALBERT模型通过使用SOP任务代替BERT模型中的NSP任务,提升了多句子输入的下游任务的效果。
2.2 CNN层
CNN是一种前馈神经网络,由卷积层和池化层组成。在卷积层中,通过与文本特征表示矩阵S进行卷积得到新的特征ci,其计算公式为
ci=f(w⊗Si:i+m-1+b),
(1)
其中:i表示第i个特征值;m表示卷积计算中滑动窗口的大小;Si:i+m-1表示矩阵S中第i行至第i+m-1行的文本特征矩阵;w为卷积核;⊗表示卷积计算;f为非线性激活函数;b为偏置值。将滑动窗口应用于各局部文本特征矩阵S1:m,S2:m+1,…,Sn-m+1:n,最终得到特征向量C,
C=(c1,c2,…,cn-m+1)。
(2)
另外,分别采用尺寸为3、4、5的卷积核对特征图进行卷积,对每个卷积核重复上述过程,得到各自的特征向量。在池化层中,通过最大池化方法保留权重最大的特征值,并舍弃其他特征值,计算公式为
pj=max(cj),
(3)
其中:pj表示特征图中第j个池化区域内最大的特征值。
2.3 BiGRU层
GRU是LSTM模型的一个变体,其模型结构如图2所示。LSTM模型包含三个门计算,即输入门、输出门和遗忘门。GRU模型在LSTM模型的基础上进行了简化,只由zt和rt两个门控单元组成。其中:zt表示更新门,用于控制前一时刻的状态信息被带入到当前状态中的程度;rt表示重置门,用于控制忽略前一时刻的状态信息的程度。

图2 GRU模型结构
基于以上GRU的模型结构,可以得出GRU的前向传播计算公式为
zt=σ(Wzxxt+Wzhht-1+bz),
(4)
rt=σ(Wrxxt+Wrhht-1+br),
(5)
(6)
(7)
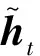
2.4 ALBERT-CRNN模型
ALBERT-CRNN模型结构如图3所示,主要由以下6个部分组成:输入层、ALBERT层、CRNN层(包含CNN层和BiGRU层)、全连接层、Softmax层和输出层。该模型的工作流程如下。

图3 ALBERT-CRNN模型结构
步骤1 利用输入层将弹幕文本数据输入到模型的ALBERT层中,输入的弹幕文本数据X=(X1,X2,…,XN),其中Xi表示该条弹幕文本中的第i个词。
步骤2 在ALBERT层对输入的文本数据进行序列化,将文本数据X中的每个词转化为其在字典中所对应的编号。序列化后的文本数据E=(E1,E2,…,EN),其中Ei表示文本中第i个词的序列化字符。利用多层双向Transformer编码器对序列化后的弹幕文本进行训练,得到弹幕文本的动态特征表示。文本特征表示T=(T1,T2,…,TN),其中Ti表示文本中第i个词的特征向量。在使用Transformer编码器获取弹幕文本特征时,计算当前句子中每个词与其他词之间的相互关系,然后利用这些相互关系去调整每个词的权重,从而获得句子中每个词的新的表达。通过此方式训练出的文本特征表示T充分利用了句子中词的上下文信息,使得句子中同一个词在不同上下文语境中具有不同的词向量表达,较好地区分了同一个词在不同上下文语境中的不同含义。
步骤3 将文本特征表示T输入到CNN层中, 分别采用尺寸为3、4、5的卷积核对文本特征进行训练,经池化层降维后分别得到三个文本向量Fc1、Fc2和Fc3,将三者进行叠加得到向量Fc。为保证池化后的三个文本向量能够相互叠加,在池化层采用全填充的方式使得池化后的三个文本向量形状相同。
步骤4 将CNN层的输出Fc分别传给BiGRU层的前向GRU层和后向GRU层,经过多个GRU隐藏单元的训练,最终得到两个文本向量表示,分别记作Fg0和Fg1。
步骤5 将Fg0和Fg1进行叠加得到向量Fg,Fg的维度为2h,其中h为GRU隐藏单元个数。通过全连接层对Fg进行两次全连接,全连接层的输出维度为s,s表示情感标签的个数。
步骤6 使用Softmax函数对全连接层的输出结果进行归一化,得到弹幕文本情感极性的概率分布矩阵L,对L按行取最大值的索引,最终得到弹幕文本的情感极性。
上述流程中的步骤3和步骤4充分利用了CNN训练局部特征的优势以及BiGRU获取上下文语义信息的优势,从而能够充分考虑文本中的局部特征信息和上下文语义关联,进一步提升了模型的效果。
3 实验部分与结果分析
3.1 实验环境与数据
实验环境如下:操作系统为Ubuntu16.04,CPU是Intel®Xeon®Gold 5218,GPU为NVIDIA Tesla V100,内存为48 GB,使用Python3.6进行算法编程,并使用Tensorflow1.12.0作为深度学习框架。利用网络爬虫技术分别从哔哩哔哩、爱奇艺和腾讯视频三个视频网站上爬取弹幕文本数据,形成不同的弹幕文本数据集。对弹幕数据进行清洗,剔除掉不具有情感倾向的弹幕,并将具有情感倾向的弹幕分为负向和正向情感弹幕。数据清洗完成后,哔哩哔哩弹幕数据集共包含5 037个负向情感样本和5 109个正向情感样本,爱奇艺弹幕数据集共包含5 014个负向情感样本和5 115个正向情感样本,腾讯视频弹幕数据集共包含5 024个负向情感样本和5 218个正向情感样本。对以上数据进行预处理,并按照7∶3的比例划分为训练集和测试集。
3.2 评价指标
为评价模型的分类效果,采用混淆矩阵对分类结果进行统计。使用TP表示实际为正样本且预测为正样本,FP表示实际为负样本但预测为正样本,TN表示实际为负样本且预测为负样本,FN表示实际为正样本但预测为负样本。根据混淆矩阵统计的结果,采用准确率(Acc)、精确率(P)、召回率(R)以及精确率与召回率的调和平均值(F1)对模型效果进行评价,计算公式为
(8)
(9)
(10)
(11)
3.3 实验参数
实验参数主要包括ALBERT模型和CRNN模型的参数。其中ALBERT采用Google发布的预训练模型ALBERT-Base,其模型参数如下:嵌入层尺寸为128,隐藏层尺寸为768,隐藏层的层数为12,注意力头的个数为12,并且使用ReLU作为模型的激活函数。另外,在模型训练的过程中对该预训练模型进行微调,以更加适用于本文的情感分析任务。CRNN模型参数如下:CNN中的卷积核尺寸分别为3、4、5,且每种尺寸卷积核的个数均为128,另外在池化层采用最大池化的方法对特征进行降维,且池化尺寸为4。BiGRU中的GRU隐藏单元个数为128,模型的层数为1,采用ReLU作为激活函数,并在训练阶段将Dropout的比例设置为0.5。ALBERT-CRNN模型训练参数如下:设置批次大小为64,迭代轮数为30,由于弹幕文本一般较短,设置最大序列长度为30,采用交叉熵损失函数,选取Adam作为模型的优化器,并将学习率设置为5×10-5。
3.4 对比实验设置
为验证ALBERT-CRNN弹幕文本情感分析模型的有效性,将ALBERT-CRNN模型与SVM、CNN、BiGRU、CRNN以及ALBERT模型进行对比,在哔哩哔哩、爱奇艺和腾讯视频三个视频平台的弹幕文本数据集上分别进行实验。其中SVM、CNN、BiGRU和CRNN模型均基于Word2Vec模型构建词向量;ALBERT和ALBERT-CRNN模型则采用Google发布的中文预训练模型ALBERT-Base来进行文本特征表示,并将此预训练模型在本文数据集下进行微调。
3.5 实验结果及分析
不同模型在三个弹幕文本数据集上的精确率、召回率和F1值结果如表1所示。可以看出,相比SVM、CNN、BiGRU、CRNN和ALBERT模型,ALBERT-CRNN模型在哔哩哔哩数据集上的F1值分别提高了8.5、5.5、5.6、4.9和0.6个百分点,在爱奇艺数据集上的F1值分别提高了8.1、5.0、5.5、3.8和0.7个百分点,在腾讯视频数据集上的F1值分别提高了8.1、5.9、5.7、5.0和1.9个百分点。由此可以得出,相比其他基于Word2Vec构建词向量的模型,ABERT和ALBERT-CRNN模型在弹幕文本情感分析中有着明显的优势,证明了由预训练语言模型获取的文本特征能够充分利用句子中词的上下文信息,较好地区分了句子中同一个词在不同上下文语境中的不同含义,从而使得弹幕文本情感分析的效果得到了提升。另外,ALBERT-CRNN模型相比ALBERT模型在弹幕文本情感分析中具有更优的表现,证明了CRNN模型能够充分考虑文本中的局部特征信息和上下文语义关联,进一步提升了模型的性能。

表1 不同模型在三个数据集上的精确率、召回率和F1值结果
图4给出了不同模型在三个弹幕文本数据集上的准确率对比。可以发现,相比SVM、CNN、BiGRU、CRNN和ALBERT模型,ALBERT-CRNN模型在弹幕文本情感分析中具有更佳的效果,在三个数据集上的准确率分别达到94.3%、93.5%和94.8%,再次证明了ALBERT-CRNN模型在弹幕文本情感分析任务中的有效性。
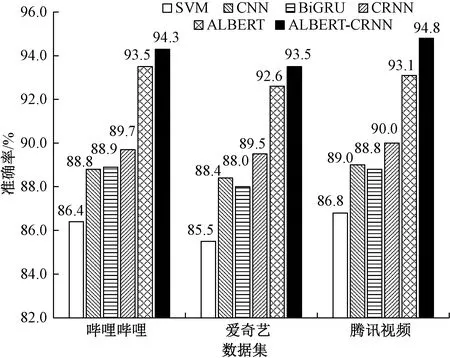
图4 不同模型在三个数据集上的准确率对比
利用ALBERT-CRNN模型对单个弹幕文本进行预测,展示了模型真实的运用功能。为方便了解输出结果的含义,将预测值大于0.5的定义为正向情感,其余的定义为负向情感。单个样例分析结果如表2所示,可以看出,ALBERT-CRNN模型对随机选取的单个弹幕文本的预测结果都是正确的,能够成功应用于弹幕文本情感分析中。

表2 单个样例分析结果
4 结语
本文提出一种结合ALBERT与CRNN的弹幕文本情感分析模型ALBERT-CRNN。通过ALBERT预训练语言模型获取弹幕文本的动态特征表示,解决了传统弹幕情感分析方法无法区分句子中同一个词在不同上下文语境中含义不同的问题;使用结合CNN与BiGRU的神经网络CRNN对特征进行训练,充分利用了文本中的局部特征信息和上下文语义关联。在哔哩哔哩、爱奇艺和腾讯视频三个视频平台的弹幕文本数据集上进行对比实验,证明了ALBERT-CRNN模型在弹幕文本情感分析任务中的有效性。由于ALBERT模型在使用过程中的参数量仍然较大,导致训练所花费的时间较长。在下一步研究工作中,将对ALBERT模型进行压缩,在模型精度不受较大损失的情况下尽可能降低模型的复杂度,从而提高模型的训练效率。
猜你喜欢
计算机与网络(2022年8期)2022-07-05
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
大众投资指南(2021年35期)2021-02-16
综艺报(2020年6期)2020-01-21
证券市场红周刊(2019年45期)2019-11-30
学生天地·小学中高年级(2018年8期)2018-10-11
青春美文CUTE(2017年1期)2017-11-14
传奇故事(上旬)(2017年6期)2017-06-17
高中生学习·高三版(2016年9期)2016-05-14
