
基于Django印刷体维吾尔文识别系统的设计与实现
2021-07-26 02:34:34熊黎剑吾守尔斯拉木许苗苗
郑州大学学报(理学版) 2021年3期
熊黎剑,吾守尔·斯拉木,许苗苗
(1.新疆大学 信息科学与工程学院 新疆 乌鲁木齐 830046;2.新疆多语种信息技术实验室 新疆 乌鲁木齐 830046;3.新疆多语种信息技术研究中心 新疆 乌鲁木齐 830046)
0 引言
随着信息化社会的不断推进,光学字符识别(optical character recognition,OCR)技术在各领域开花结果。印刷体文字识别在数字化办公、文献管理等方面均有良好的应用前景。相比于已成熟化的印刷体中、英文识别,印刷体维吾尔文识别还有研究空间[1]。维吾尔文多使用于我国新疆地区,包含32个字母,其中8个元音字母,24个辅音字母,词序是主语-谓语-宾语[2]。有一些维文字母的主体部分相同,仅依靠上下点的标记来区别不同字符[3]。同时,当字母出现在词前、词中、词末以及独立出现时,对应的写法也不同,切分不当会导致单词的改变,所以本文从整词识别入手。已有研究方法多以传统方法为主,如基于统计和结构的方法[4]、模板匹配法[5]等。这些方法往往需要较多的人工干预,包括手工设计特征和人工建立标准的匹配库等,因此效率不高。
近些年以来,国内相关的维文OCR系统是西安电子科技大学卢朝阳教授团队开发的维吾尔文识别软件。它的设计核心是:单词切分成字符再结合人工选取的特征(如方向线素特征和梯度特征),再用欧氏距离分类器[6-8],最终得到候选结果。2019年,该实验室又利用“翻字典”原理设计了从字符到单词的两级级联分类器[9],完成了维文单词的识别。以上方法均是手工选取特征结合分类器进行识别,在特征选择方面具有一定的局限性。
本文选用经改进的卷积循环神经网络(convolutional recurrent neural network,CRNN)和连接时序分类器(connectionist temporal classification,CTC)作为文字识别的核心算法,Django作为构建前后端的框架,搭建了完整的维文整词识别系统。
1 算法原理
1.1 卷积循环网络
用于文字识别领域的卷积循环神经网络(CRNN)是由Shi等提出的[10]。它由深层卷积网络(deep convolutional neural network,DCNN)加循环网络(recurrent neural network,RNN)构成。随着计算机视觉领域研究的持续火热,DCNN经常被用于图像特征提取,同时,它也在目标检测[11-12]、情感分析[13]、图像处理[14]等方面表现优异,但是文字的检测与识别不同于一般的目标检测任务,基于特征(人工设计或CNN得到)及分类的方法往往忽视了文本隐含上下文关联的特点。RNN能处理序列信息,在原有的CRNN中,RNN部分是双向长短期记忆网络(bi-directioanl long short-term memory,BiLSTM),但其结构复杂,训练收敛速度慢。本文将BiLSTM替换为更为简洁的双向门控循环神经单元网络(bi-directioanl gated recurrent unit,BiGRU)[15]。实验证明,改进后的CRNN网络比原有网络收敛的速度更快,同时,在测试精度方面也有略微提升。
1.2 门控循环神经单元网络(GRU)
GRU是在RNN和LSTM的基础上一步步演变而来的,LSTM网络解决了RNN在训练时容易出现梯度爆炸和梯度消失的问题,而相比LSTM更为复杂的3门结构——输入门、忘记门和输出门,GRU将其简化为2门结构——更新门和重置门,这样简洁的结构减少了网络训练收敛时间,具有更高的计算效率,提高了模型精度。GRU内部结构如图1所示。

图1 GRU结构图
GRU的前向传播计算公式[15]为

重置门用来控制需要保留多少之前的信息,被忘记的历史信息越多,其值越小;更新门主要决定被添加到当前状态信息中的历史信息量,经过Sigmoid函数激活,取值为0~1;这两个门共同决定了隐藏状态的输出。
本文采用正向GRU和反向GRU结合成双向GRU(BiGRU),并用双层堆叠形式进行序列建模,其中隐藏层单元数为256。如图2所示。

图2 系统框架图
1.3 连接时序分类器
连接时序分类器是一种用于解决不等长序列的输出问题(序列对齐问题)的算法,最早由Graves 提出,之后他又将CTC成功应用于语音识别方面[16]。训练时无须切分语料,也不需要中间语音的表示,在测试集上错误率低至17.7%。该解码算法能有效解决输入、输出序列不等长的问题。
数学模型上,CTC层也叫转录层,是根据上一层(RNN层)输出长度为T的预测序列{x1,x2,…,xT},去寻找具有最高概率的标签序列。
(1)
(2)
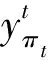
维吾尔文识别的一个CTC实例。

由上述实例可以看出,CTC对齐前的输入序列长度为26,CTC对齐后的输出序列长度为5,可见CTC有效地解决了序列对齐问题。
2 识别系统的设计与实现
2.1 系统框架
本文采用开源的Django设计系统,遵循M(model)T(templete)V(view)模式。用户在浏览器端发送请求,通过urls.py发给view处理,view再调用对应的templete和model进行处理。其中view负责业务逻辑,templete(主要是HTML文件)负责页面展示,model负责数据库对象和业务对象。这种松耦合和相互独立的特性,易于开发和维护。系统流程如图3所示。

图3 系统框架图
2.2 系统功能与展示
后台输入命令启动服务,然后在浏览器页面输入网址,开启Web服务。
1)上传功能。选择一张本地图像,点击提交,图像会自动上传到后台splite数据库。


图4 系统展示图
3 实验与结果
3.1 实验数据
1)训练数据(合成数据)
利用JAVA语言编写脚本,合成了含32个维文字母(8个元音,24个辅音)在内的约10万张图片数据(JPG格式),以及对应的标签数据(TXT格式)。同时,为了使训练样本更具代表性,本文对32个维文字母作了数据均衡处理。部分训练图片如图5所示。

图5 部分训练数据
2)测试数据(真实数据)
从天山网(维文版)(http:∥uy.ts.cn/)中的不同栏目进行收集并制作成测试图片和标签。总数约1 500张,部分测试数据图片如图6所示。

图6 部分测试数据
3.2 实验设置
为了验证系统的有效性,本文设置了对比实验。采用约10万张图片作为训练数据,分别在CRNN和改进的CRNN(BiGRU)上训练,并将训练得到的模型文件分别在测试集上进行测试。实验中的PC机主要配置为:Nvidia独立显卡(1060Ti 6G内存)等。所依赖的软件及环境为:Pycharm(社区版)编译工具、Ubuntu18.04操作系统、Python3.6.2编程语言、Pytorch1.2.0等。
1)实验中精度的定义为A=(nt/ns)·100%,其中:nt代表正确识别样本数;ns代表样本总数;A代表识别精度。
2)实验中识别速度的定义为v=1/(to-ti),其中:to代表获得字符串时刻;ti代表输入图片时刻;v代表识别速度。
3.3 实验结果
本实验对两种方法均进行了充分训练,当损失趋于收敛后,保留最终模型文件,其中CRNN(BiGRU)收敛速度更快。在测试集上,CRNN的精度为94.1%,CRNN(BiGRU)的精度为95.7%,平均速度为12.5 fps,表现出较好性能。究其原因,循环层由BiGRU替换,简化了模型结构,加快了模型训练收敛速度,提高了计算效率。此外,训练数据均衡也使得识别率较为稳定。
4 结语
针对传统维文识别方法特征表示不足和基于切分的识别方法易出错等问题,本文从整词识别入手,采用卷积神经网络自动提取文字的深层次抽象特征,并对循环层进行改进,用BiGRU替换原有的BiLSTM,改善了识别性能。引入连接时序分类器,很好地解决了维文字符难切分以及不等长输入输出问题。测试识别精度达到95.7%,平均速度达到12.5 fps。最后,利用Django框架,设计了一个端到端的维文整词识别系统。因此,该系统具有一定的实际应用价值。然而,现有系统只能识别纯维文(不含数字、字符),从实际应用的角度来看,后续工作可将常用的符号和数字纳入识别系统,进一步完善该系统。
猜你喜欢
书香两岸(2020年3期)2020-06-29 12:33:45
现代装饰(2020年6期)2020-06-22 08:43:14
计算机工程与应用(2018年19期)2018-10-16 05:50:10
电子测试(2018年1期)2018-04-18 11:52:35
学苑创造·B版(2017年3期)2017-05-03 16:04:17
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电测与仪表(2014年15期)2014-04-04 12:05:20
宠物世界·猫迷(2014年1期)2014-02-19 01:14:16
民族古籍研究(2012年0期)2012-10-27 08:20:41
