
碳中和背景下基于BP神经网络的电费成本管理
2021-07-21 12:14邓君令中国电信集团广东分公司财务共享服务中心广东广州510081
商业会计 2021年12期
邓君令(中国电信集团广东分公司财务共享服务中心 广东广州 510081)
一、引言
2020年9月22日,国家主席习近平在第七十五届联合国大会一般性辩论上发表重要讲话:“中国将提高国家自主贡献力度,采取更加有力的政策和措施,二氧化碳排放力争于2030年前达到峰值,争取在2060年前实现碳中和。”“碳中和”是指国家、企业、产品、活动或个人在一定时间内直接或间接产生的二氧化碳或温室气体排放总量,通过植树造林、节能减排等形式,以抵消自身产生的二氧化碳或温室气体排放量,实现正负抵消,达到相对“零排放”。对企业,国家通过制定一系列政策,引导企业采取措施,从而控制并逐步减少生产运营等活动中所产生的碳排放。中央经济工作会议确定的2021年八项重点工作第八项就是节能减排,减污降碳等碳中和工作。
随着强制性节能增效政策推出,实现能耗限额标准全覆盖,高耗能行业大中型企业合规性压力增大,如电信运营商,根据近年各运营商公开年报,中国移动2019年度营业成本为6 327.68亿元,其中网络运营及支撑成本为1 758.10亿元,而动力水电取暖费用为328.37亿元;中国电信营业成本3 466.64亿元,其中网络运营成本1 097.99亿元,而能耗成本为138.18亿元;中国联通营业成本2 141.33亿元,而网络运营及支撑成本为432.36亿元;仅移动和电信两家,动力能耗成本总额就高达466.55亿元,分别占其网络运营及支撑成本的18.68%和12.58%。随着5G智能+的发展,营业成本中能耗成本增长趋势明显,加上管理费用、销售费用中办公、营业厅用电费费用,企业的电费总量居高不下,成本费用压降趋势依然严峻。
一方面是国家政策,另一方面实现企业为股东创造更多的价值,将更多地取决于对成本的精耕细作,实现成本的精细化管理,而能耗成本更是重点成本管控目标之一。基于人工智能数据分析技术日渐成熟,有利于管理会计成本管理方法提升,通过绘制企业财务数据之间、财务数据与非财务数据之间的勾稽关系,建立学习模型、机器自动学习,由输入特征值数据推导出输出目标成本科目预测值,研究影响成本的主要因素,提前有针对性地控制各项输入特征值科目预算,对成本费用进行合理控制,实现精细化成本管控。对已发生成本异常,通过预测模型发现预测值与实际值数据偏离原因,加强管理,防止年度成本费用偏离预算目标。
二、相关研究
根据财政部发布的《管理会计应用指引第300号——成本管理》,企业成本管理是指在营运过程中实施成本预测、成本决策、成本计划、成本控制、成本核算、成本分析和成本考核等管理活动,分事前、事中、事后管理等。事前主要是对未来成本水平及其趋势进行预测与规划;事中主要是对营运过程中发生的成本进行监督和控制,事后是在成本发生之后进行的核算、分析和考核。传统的成本管理管控方法更多解决可以线性描述的成本费用关系,计算非线性的成本费用关系能力有限,限制了成本预测、控制、分析的范围,目前主要有目标成本法、标准成本法、变动成本法、作业成本法等。
人工神经网络虽然是20世纪40年代出现,但财会领域真正开始尝试却是80年代,如1987年美国执业会计师协会首次将人工智能引入会计智能审计领域,发布了“人工智能与专家系统简介”。目前,人工智能技术也逐步完善,从单层感知网络到BP神经网络、卷积神经网络理论研究和技术积累已非常丰富,并出现了非常成熟的神经网络学习模型工具,为会计师学习和应用提供了便利,也便于管理会计专家专业知识的累积和固化,为其他新进管理会计人员提供指引,总体提高成本管理工作的效率和精准性。最初的人工智能神经网络,具有模型清晰、结构简单、计算量小等优点,但也存在不足,例如无法处理非线性问题,即使计算单元的作用函数不用,阀函数用其他较复杂的非线性函数,仍然只能解决线性可分问题,不能实现某些基本功能,从而限制了它的应用。随着技术的发展,具有函数逼近、模式识别、分类、数据压缩的BP神经网络被David Runelhart、Geoffrey Hinton、Ronald W-llians、DavidParker等人提出,创造性地解决了多层神经网络隐含层连接权学习问题,并发布完整的数学推导过程。作为一种全新的误差反向传播算法训练的多层前馈神经网络,其突出优点是具有很强的非线性映射能力与柔性的网络结构。网络中间层、各层神经元数和网络学习率等参数可以根据具体情况任意设置,灵活性大,网络推广能力强。
三、基于BP神经网络学习的电费成本管理原理
每个企业相当一个神经网络,如图1所示,财务和非财务数据类似于神经元,每个神经元互相连接,互相依存,一个神经元的波动,会引起其他神经元的联动,如在国家碳中和目标背景下,国家对高能耗产业政策的调整,必定会影响相关企业,如对电力消耗大的电信运营商企业,耗能高的设备更新为更节能环保设备,对应固定资产、电费成本费用数据联动变化,通过分析影响电费成本费用的因素,如设备资产功率、产品存货量、服务完成次数、用户收入完成目标等,输入特征值变量描绘输出电费成本目标变量值,通过机器学习,建立电费成本预测分析模型,实现电费成本管理的事前成本预测、事中成本控制、事后成本分析等功能。
神经网络学习模型是通过数学建模的方式模拟神经细胞接受其他神经细胞的信号,产生反应电脉冲输出的过程,人通过学习积累经验最终知道何种反应输出是正确的,类似成本线性函数y=wx+b,变动成本加固定成本求解目标成本的过程,已知历史数据x和目标成本y取值,通过机器学习求解权重系数w和偏执b,求解过程如下:(1)设定w的起始值,设定损失函数(描述w如何变动的函数,如每次w增加0.001,损失函数则为wi=wi-1+0.001,不断测试w值,直到满足函数等式关系)(b的计算过程类似);(2)得到权重系数w和偏执b后,如果已知任意x代入函数y=wx+b,可以算出目标成本y。
具体到不同的学习模型,输入特征值不止一个变量,可能是矩阵[x1,x2,x3…,xn]T和权重系数也是矩阵[w1,w2,w3…,wn]T,甚至是多层矩阵,输入特征值变量与输出目标值变量的关系也不会是简单的y=wx+b线性关系,如通信基站,虽然核定功率乘以使用时长可以得出类似线性的成本增长曲线,如果加上同时连接的用户的数量,或是用户数据流量大小,电费成本的变动与功率、时长、流量的关系就是非线性的,更倾向为非线性的关系。构造满足非线性关系的函数关系及损失函数满足学习训练要求,通过历史数据求解权重系数W矩阵和偏执b,完成网络模型建设后就可以开始成本预测、控制、分析等用途。
(一)企业数据神经网络学习模型
企业财务类指标如资产、负债、权益、收入利润、成本费用,非财务类指标如客户、行业政策、竞争环境、运营支撑、人力资源存在线性或非线性的关系,梳理出特征值变量与输出值目标变量的映射表,搭建神经网络学习模型如图2所示。
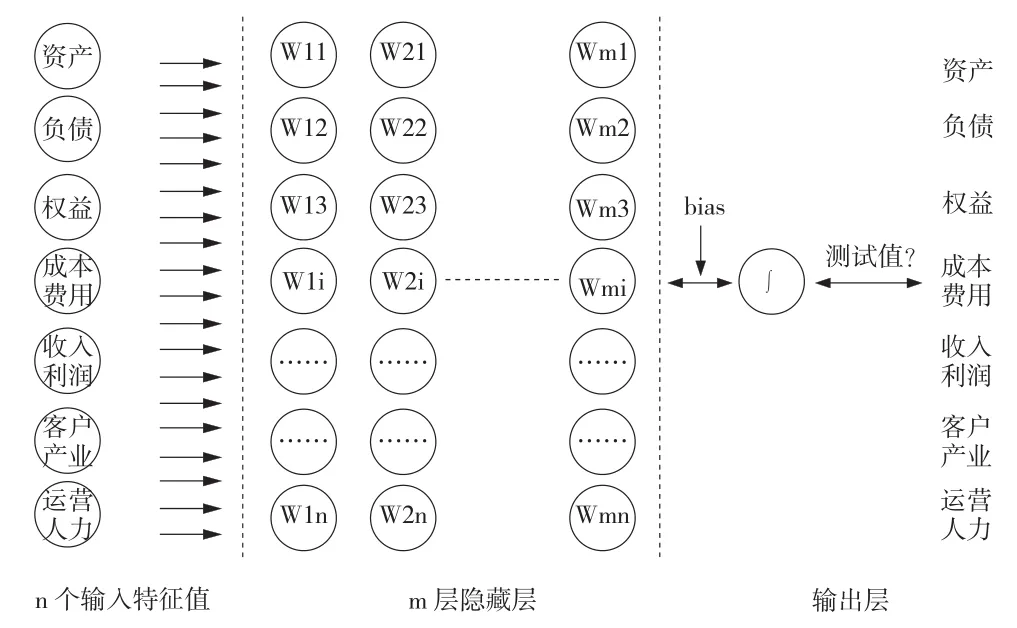
图2 企业数据神经网络学习模型
(二)基于BP神经网络的电费成本管理预测、控制、分析流程
基于BP神经网络的电费成本预测、控制、分析流程如下页图3所示。具体流程步骤描述如下:

图3 基于BP神经网络电费成本预测、控制、分析流程图
1.编制特征值输入变量和输出电费成本目标映射关系表。不同的企业、不同成本的影响因素各异,以电信企业为列,营销服务中心、营业厅的数量、规模影响销售费用中的电费费用;办公场地的数量、规模影响管理费用中的电费,对某一公司来说,电费一般如无大的结构变化,基本每期变动较小,在预测时可以参考历史数据变化趋势算出,重点是主营业务成本中电费成本的预测、监控、分析,分析企业影响输出目标电费成本的资产、负债、收入、成本等科目因素或非财务数据因素,编制特征值输入变量与输出电费成本目标变量映射关系表(见表1)。
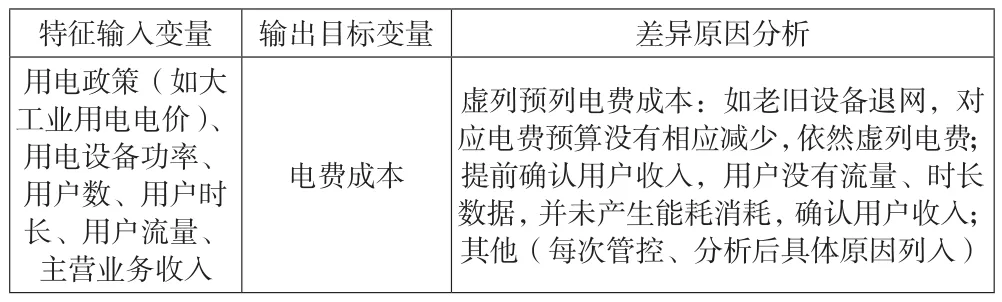
表1 特征值输入变量和输出目标变量映射关系表
以电信企业电费成本为输出变量,特征值输入变量为国家电费政策(如电价、大工业用电、直购电和普通工商用电优惠电价)、主营业务用电设备功率输出(设备固定资产原值*设备功率/设备单价)、用户数(不同用户规模对通信设备用电耗能)、用户时长、用户流量、主营业务收入。在业务未发生大的转型前提下,特征值输入变量和输出电费成本应该有稳定的线性或非线性关系:如特征变量主营业务收入增长满足预算考核目标,但对应的电费并未见增长,说明可能年底存在提前预列收入;或特征变量固定资产发生变化,如程控交换机退网,电费应该也会发生变化,如果电费维持稳定,预测值与实际值不符,可能部分地市公司预列电费成本,维持电费成本预算的增量,为其后续数据业务出租(程控机房退网后改造为IDC出租机房)预留电费成本。
2.特征值输入变量和输出电费成本历史数据清洗归一化、分组。
(1)清洗的目的是保持各变量可比性,方便神经网络训练学习的快速收敛和防止某一个变量权值过重,影响整体预测效果。选取历史年度财报及非财务历史数据,对数据进行清洗,清洗主要是对各变量进行单位统一和量级统一,单位的统一如用户数单位是户、时长数是分钟、流量是比特,而输出电费是元,具体可以参考《关于印发〈2015年电信业务不变单价表〉的通知》 (工运行函[2017]187号)。清洗完后需要采用公式(1)进行归一化,用公式(2)对输出目标变量进行归一化使得所有输入特征变量和输出目标值为(0,1)之间。

说明:x*i、y*i为归一化后输入特征值变量和输出特征值变量,xi、yi为归一化前的输入特征值变量和输出特征值变量,xmin、xman、ymin、yman为归一化前的最小、最大值。
(2)归一化后,对数据进行随机分组,分为训练集和测试集,训练集和测试集选取的比例可以为9∶1,具体可以根据数据的多少酌情决定;如果历史数据少,可以采用留一法选取测试集,也就是只选取一组变量为测试集,其他都为训练集。
3.搭建训练BP神经网络学习模型。现有通用的神经网络学习工具有Google发布的TensorFlow和MathWorks的Matlab神经网络学习工具。选取工具后编程,完成神经网络模型的搭建,输入归一化后训练集的特征值变量和输出变量,设置神经网络隐藏层层数、训练次数、可接受的目标误差、学习率,可以选取系统默认损失函数或是自己构建损失函数,启动训练,直到输出误差在允许的范围内,训练结束,调用测试集特征变量,通过已训练神经网络预测目标值,由于第一步对测试集和训练集进行归一化,测试集调用神经网络预测的目标值为(0,1)之间的数值,可以用公式(3)进行反归一化,用公式(4)计算预测值与实际值的决定系数R2,R2越接近1,说明学习效果越好。
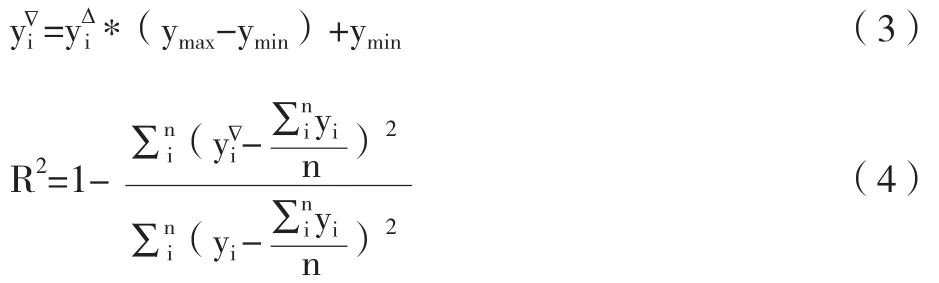
4.事前电费成本预测、成本决策。获得成熟的神经网络学习模型后,代入目标年度特征值输入变量值,获得预测电费成本输出,如果预测值与目标值有差异,说明输入特征值变量的值可能不适宜,如对年度用户收入有较高的增长预期(用户采购产品服务增加,如时长、流量的增加),而电费成本目标依然保持与上年趋同或是下降,则需要调整目标电费成本目标,或是调低收入增长预期;或是固定资产(用电设备)发生变化,如高耗能的程控交换机退网,用耗能较小的计算机软交换技术替代,实现收入增长的同时,电费成本实现压降。
5.事中电费成本监督、成本控制。如设定年度电费成本目标,在期间不断用训练好的神经网络模型输入特征值输入变量值,获得的期间电费成本预测值与实际电费成本进行比较,如有差异,分析发现原因:如部分直购电或是协议用电约定付费在年中或是年终,可能会导致实际月度或季度电费成本预测值与实际值之间的差异,可以通过预列成本解决,或是业务爆发式增长导致电费成本增加,需要适当调整电费成本预算目标。
6.事后成本分析、成本考核。收集特征值输入变量年度实际数据依次替代特征值输入变量预算数据,查看输出电费成本差异比例,发现电费成本偏离预算目标的原因,依据成本考核方法进行奖惩,提升电费成本管理手段。
四、基于BP神经网络的电费成本模型训练与测试结果
选取上页表1特征值输入变量和输出目标变量映射关系表,训练电费成本管理网络模型,选取某省分公司用户规模、资产规模、收入规模都比较类似的7个地市分公司近5年财务年报数据构建数据集,共生成35条数据,对数据进行清洗,随机排列后,随机选择31条数据(35x90%)作为训练集,4条数据(35x10%)为测试集,实验环境选择MATLAB R2017a,最后测试出目标值与预测值之间的误差率,同时计算决定系数R2作为判断预测学习效果依据。
(一)主要数据和参数设定
进行实验之前,对数据进行清洗,其中电价进行量级为每亿瓦单价,对用户数、用户时长、用户流量转化单位为元,固定资产剔除房屋等非电力消耗对象资产,主营业务收入中对出租收入等非电力消耗的收入项进行剔除。其后对训练集输入特征变量数据归一化后获得归一化训练集特征输入变量列表(见表2)。对应训练集输出目标变量见表3。
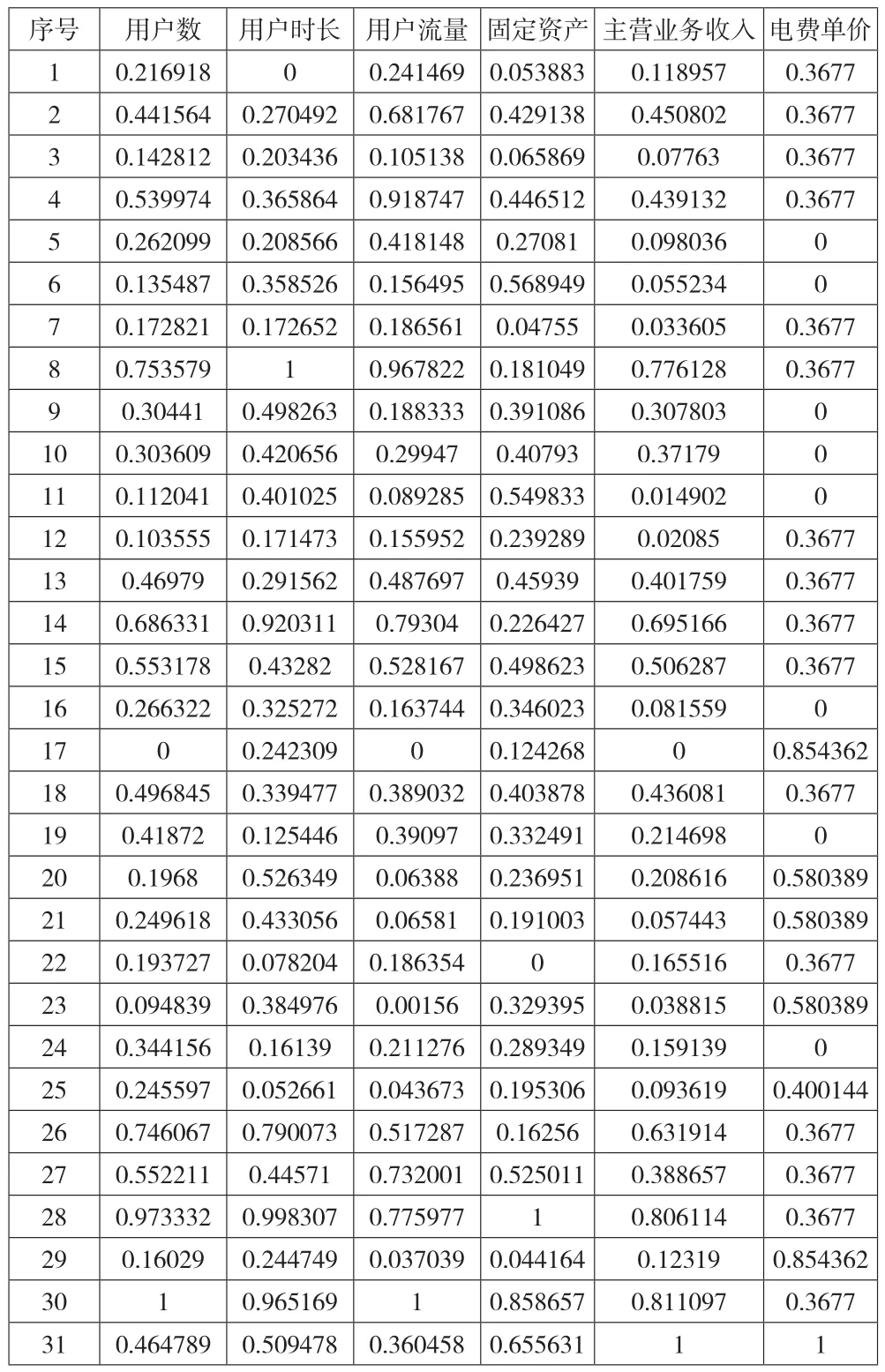
表2 归一化后训练集特征输入变量列表

表3 训练集输出目标变量列表
利用公式(2)对训练输出目标变量归一化后,作为神经网络学习模型的训练集输出目标变量值。
在训练过程中,先设置隐含层数为6,逐步加大隐含层数量,比较训练结果,经过实验验证当隐含层数为9时,效果最好,学习率和可接受误差值设定类似,最后设定学习率为0.01,可接受误差为0.01,训练次数为1 000次。
训练完成后查看训练样本、验证样本、测试样本和全部样本的回归系数R值,R越接近于1越好,如本次实验中相关系数都为0.9以上,可以认为本次训练较为成熟,如果小于0.9,则继续训练,直到回归系数大于0.9趋近1,如下页图4所示。
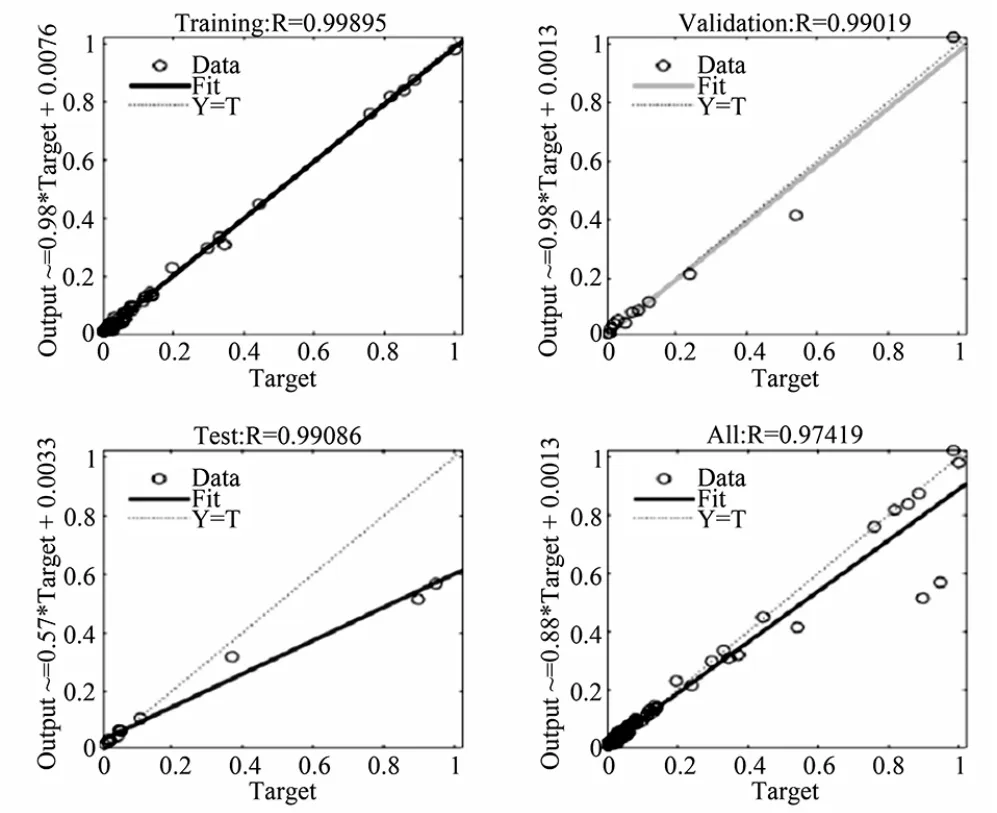
图4 训练样本、验证样本、测试样本和全部样本的回归系数
(二)实验与结果
经过对省公司近5年财务年报数据和非财务数据35组数据31组训练后神经网络,用另外4组数据进行测试验证训练效果,4组数据目标值与预测值如下页表4所示的误差率,最小为0.000317,最大为0.006625847,决定系数R2=0.99714372,非常逼近于1,说明训练效果较为理想。
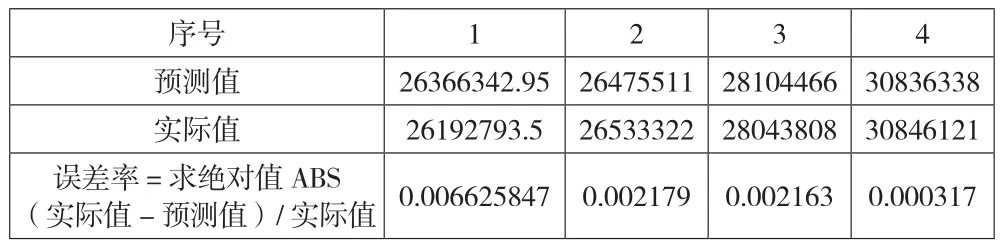
表4 测试机输出目标变量实际值及预测值对比表
实验输出对比结果如图5所示。

图5 实验输出目标变量真实值与预测值对比图
五、总结
实验结果输出预测值与实际值决定系数R2=0.99714372逼近于1,满足设定的误差率,说明建立神经网络学习模型通过对历史数据的学习,可以很好地预测后续账期(月度、季度、年度)电费成本,基于BP神经网络学习的电费成本管理原理有可行性。
本文在参考现有成本管理研究的基础上,探索基于BP神经网络学习的电费成本管理方法,与传统目标成本法、标准成本法、变动成本法、作业成本法相比,高耗能企业电费成本存在更多的非线性成本输入输出关系,基于神经网络学习的成本管理方法可以更好地构造非线性的数学模型,提供数据计算的准确性,为高能耗行业提供准确性和全面性的事前预测、决策;事中成本监督、控制;事后分析、考核成本管理,同时借助大数据存储和挖掘技术,能提高电费成本分析的深度和广度。在国家碳中和目标的背景下,为高能耗企业落实国家碳排放目标、精准把控动力能耗成本支出助力。
该研究方法也可以用于其他成本管理,特别是输入特征值变量和输出目标变量之间存在非线性关系,可以作为一种替代成本管理方法,原理与本文论述原理类似,把企业财务数据如资产、负债、权益、收入利润、成本费用及非财务数据如客户、行业政策、竞争环境、运营支撑、人力资源,选择某项目标成本,并由影响其大小的特征值输入变量描述,绘制映射表,通过历史数据学习获得成熟的神经网络学习模型,保存后就可以用于后续的成本管理。
该方法还可以拓展用于审计分析程序,针对审计专项,选取适当的特征值变量和对应的输出目标变量(两者之间可以存在线性的或非线性的关系),绘制映射表,并训练出成熟神经网络学习模型;在审计的风险评估、实质性审计程序或审计结论分析阶段,调用学习模型,预测正确的输出目标变量值,如果目标预测值与实际值存在较大差异,说明可能存在风险,通过分析输入特征值变量与输出目标变量,可以发现潜在隐藏的舞弊风险;而且神经网络模型一旦训练成功,可以保存推广,通过审计专家训练的模型也能用于新进的审计人员,提高审计效率,减少对审计专家经验的要求,在合理降低审计成本的同时提高审计的效率和准确性。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
安徽工业大学学报(自然科学版)(2022年2期)2022-04-16
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
意林·少年版(2020年1期)2020-02-18
新生代(2019年16期)2019-10-18
现代营销·理论(2019年5期)2019-09-10
软件(2017年6期)2017-09-23
课程教育研究·新教师教学(2016年18期)2017-04-12
科学与财富(2016年32期)2017-03-04
