
一种构建情感标签均衡语料库的主动学习算法
2021-07-16 08:02时雪峰任福继
计算机应用与软件 2021年7期
时雪峰 康 鑫 廖 萍 任福继
1(南通大学机械工程学院 江苏 南通 226019) 2(德岛大学工学部 德岛县 德岛市 770-8506)
0 引 言
情感分析对于了解大量社交网络消息中所隐藏的思想具有重要作用,并且越来越多地为解决现实世界中的问题提供帮助,如舆论分析[1]、股票趋势预测[2-3]和产品评论[4-5]等。正确理解社交网络消息中隐藏的情感信息,有助于分析相关领域的未来趋势,并为下一次决策提供宝贵的建议。
与正、负两极的情感判别不同,多情感分类研究的重点是对人类的多种情感进行识别[6-7]。不同的研究领域对人类情感的分类也是不同的,如Ekman[8]认为人类的基本情感有六种,分别是愤怒、厌恶、恐惧、幸福、悲伤和惊奇,用于心理学研究;而Ren等[9]则认为人类的情感状态可以细化分为八种,分别是愤怒、欢乐、悲伤、焦虑、讨厌、期望、惊讶和爱。每一种分类方法,都对相关领域的研究起到了重要的推动作用。
在有监督的情感分类任务中,情感语料库是必不可少的。情感语料库的标注是一件耗费时间长、人工成本高的工作。主动学习(Active Learning)算法自动获取可能性较高的样本,缓解语料库不足的压力。相比于人工专家的筛选,主动学习算法抽取的样本在情感分布上并不均匀,主要是由原始语料中的情感分布倾向性严重造成的。这使得主动学习算法很难根据现实世界的原始语料来构建具有均衡情感标签的训练集,并限制了训练好的情感分类器对低频情感标签的识别,如焦虑和惊奇。现有主动学习算法的研究重点都集中在提高文本情感的预测准确性上,而没有考虑到语料库中情感分布的均衡性。针对该问题,本文提出一种基于Kullback-Leibler散度构建情感分布均衡的文本语料库方法。
1 相关工作
根据不同研究的需求,文本情感一般可以分为三个粒度:单词的情感标记,句子的情感分类,文档的情感分析[10]。单词情感标记主要是从文档中找到情感单词并预测这些单词的情感[11-12]。对文档的情感分析着重于文章中情感因素的识别,以及通过各种机器学习方法对文档中情感的进一步预测[13]。句子的情感分类取决于对中、短文本中单词情感的分析,并为文档情感分析提供丰富的信息。文献[14-16]提出一个句子可能同时具有多个情感状态,这表明了句子情感分类是多情感分类问题。对此,文中讨论了针对中、短社交网络文本情感分类而训练的多情感分类器。
Ren等[9]基于对单词、主题和情感标签的概率依赖性假设,采用分层贝叶斯网络生成潜在主题和情感标签,以预测文档中复杂的人类情感。通过分析情感标签和主题的分布,他们发现了不同语义主题的情感变化情况。Liu等[17]采用大规模包含内在情感信息的现实世界知识来感知文本情感。这一方法有较强的鲁棒性,可以根据对现实世界知识的理解,来预测文本中隐藏语义的情感。由于以前的主动学习方法无法获得最具信息性和代表性的样本,因此,Reyes等[18]基于基本分类器的预测和已预测标签集的不一致性,提出一种新的样本选择策略。通过与其他几个选择策略在多个数据集上的实验对比,结果表明该方法具有明显的优势。Kang等[19]提出包含互补性、信息性、代表性和多样性四个标准的主动学习方法,用于评估候选样本。他们将通过文献[19]中方法选择的样本补充到训练集中,并将选择的样本补充到训练集中以逐步改善监督的情感分类结果。以上这些工作的重点都集中在提高对候选样本的预测准确性上,而对已并入候选样本的训练集中情感标签分布的均衡性关注很少,且在样本筛选过程中,也很少通过主动学习的方法去抑制训练集中标签不均衡的现象。
2 均衡情感分布的主动学习算法
本文提出的主动学习方法是一个包含信息性、代表性、多样性和互补性四个评价策略的样本选择算法。
2.1 主动学习算法
在主动学习算法中,本文构造了一组逻辑回归分类器φk,其中每个分类器对应一种情感类别。在监督学习的基础上,分类器对每条文本x进行情感预测,并给出情感类别k的预测概率yk∈[0,1]。
yk=φk(x)
(1)
本文主动学习算法从大量未标注数据中逐步选择最具信息性和代表性的文本样本,并将其添加到现有的训练集,然后通过对其学习来更新情感概率预测器φk。
与文献[19]中主动学习模型不同的是,本文对信息性、代表性和多样性三个选择准则进行重新排序;同时,算法在互补性准则中加入抑制情感分布偏向化的机制,这使本研究可以直接控制最终输出样本的情感标签平衡属性,并对互补性标准赋予更多权重。此外,本文重新设计了互补性标准,并通过评估临时训练集的情感分布与理想的均匀情感分布之间的Kullback-Leibler散度,以明确的方式评估更多原始样本的情感标签平衡特性。以下是各标准的详细推导过程。
(1) 利用式(1)对样本进行情感类别{1,2,…,K}上的概率预测,信息性准则i(x)通过评估预测概率的最大交叉熵值,完成样本考察。
(2)
式中:yk表示情感类别k的预测概率。如算法1中所示,通过最大化该准则,本文可以根据候选样本的情感预测概率,为其找出至少一种具有较大信息性的情感类别。
算法1通过主动学习构建标签平衡情感语料库
输入:训练集X,未标注数据集U,选择标准参数λ。
1.信息性标准对全体数据进行筛选:I={i(x)|∀x∈U};
2.按比例抽取样本:UI=argpartition(I,λI|U|);
3.代表性标准对样本集UI进行筛选:R={r(x)|∀x∈UI};
4.按比例抽取样本:UR=argpartition(R,λRλI|U|);
5.多样性标准对样本集UR进行筛选:D={d(x)|∀x∈UR};
6.按比例抽取样本:UD=argpartition(D,λDλRλI|U|};
7.Fori=0→λC,执行:
8.抽取散度值最小的样本:x=argmin({c(x)|∀x∈UD});
9.获取x的情感标签e;
10.添加(x,e)到训练集X,
11.输出样本x;
12.从未标注集U中删除x;
13.完成情感标签平衡 。
(2) 代表性标准通过以下方法评估每个文本样本与未标注数据中其他文本样本的平均相似性:
(3)
式中:U表示所有未标注样本的集合;两个样本x和x′之间欧几里得距离值的相反数表示它们的语义相似程度。距离值的相反数越大,则说明样本间的距离越小。通过像算法1中那样最大化该准则,本研究可以在未标注数据集中找到在语义上最具代表性的候选样本。
(3) 多样性标准通过以下方法评估未标注样本与训练集中样本之间的最小欧几里得距离:
(4)
式中:x∈X表示训练集文本,X为训练集合。通过最大化算法1中所示的多样性标准,本研究可以找到与训练集文本在语义上截然不同的候选样本。
(4) 本文提出的新的互补性准则是通过构造一组临时训练集X∪{x},来抑制属于高频次情感标签的样本被选入训练集。每个临时训练集X∪{x}都是将原始样本x∈U并入现有训练集X。通过以下方法评估临时训练集的情感分布p′与理想的均衡情感分布u~unif{1,K}之间的Kullback-Leibler散度,并寻找出最小的Kullback-Leibler散度值c(x),即表示完成情感标签最平衡的新训练集的构建。
(5)
(6)
式中:ek(x)是关于考察样本x情感标签k的预测概率。
(7)
对于新训练集中的样本x∈U,根据实际的情感标注规则和观察到的情感类别k的概率,给定情感标签1.0或0.0。对于未标注数据集中的样本x′∈U,其情感类别为k的概率由逻辑回归情感分类器的预测结果ek(x′)=φk(x)给出。
2.2 平衡情感分布的过程示例
图1为基于互补性准则的情感标签均衡化的样本选择过程。如图1(a)所示,从当前训练集情感标签分布的情况得知,算法需要寻找的情感类别为“难过”和“讨厌”;图1(b)显示,算法在侦测到训练集所缺乏的情感类别后,根据选择准则,抽取出预测概率较高的“悲伤”样本;算法从未标注数据中选择能够使临时训练集X∪{x}具有更均衡的情感分布的样本,完成平衡训练集情感标签的任务,如图1(c)所示。
(a)

(b)
(c)图1 主动学习算法平衡数据集情感分布过程
在算法1中,参数λI、λR和λD分别是基于信息性、代表性和多样性标准选择样本的百分率。固定选择比例有助于选择标准在面对不同规模的未标注数据集时,保持同样的样本选择能力。参数λC(其中C表示互补性准则)对应文中主动学习算法最终选择样本的规模。另外,本文使用固定数字作为输出样本的规模,方便不同规模的未标注数据集在文本情感分类学习过程中的实验对比。
2.3 多情感分类算法
与一般主动学习算法相同的是,本文构建基于逻辑回归分类器φk的情感分类算法,用于考察所选数据的合理性。
在分类前,算法过滤掉低频词特征和暂停词特征,并通过观察到的每个单词特征统计量表示微博文本,记作x。通过对训练集进行5倍交叉验证,确定逻辑回归分类器的超参数(包括l1和l2惩罚项、正则化强度、每个分类器φk的类权重)。
在情感分类算法中,本文采用准确率(Precision,P)、召回率(Recall,R)和F1值来评估分类结果,公式如下:
(8)
(9)
(10)
式中:TP表示真正例;FP表示假正例;FN表示假反例。
3 实 验
3.1 数据预处理
(1) 降噪。为了减少下文研究中主动学习算法的工作量,本节对原始微博数据的预处理进行说明。由于本文的研究对象为中文短文本微博数据,其中很多为不规范用语,大量的噪声不仅增加后续研究的工作量,还容易影响抽取样本的质量。
通过构建噪声语料库,本文从原始语料中萃取到纯粹的人为短文本信息。构建的噪声语料库主要成分包含以下7个方面,如表1所示。
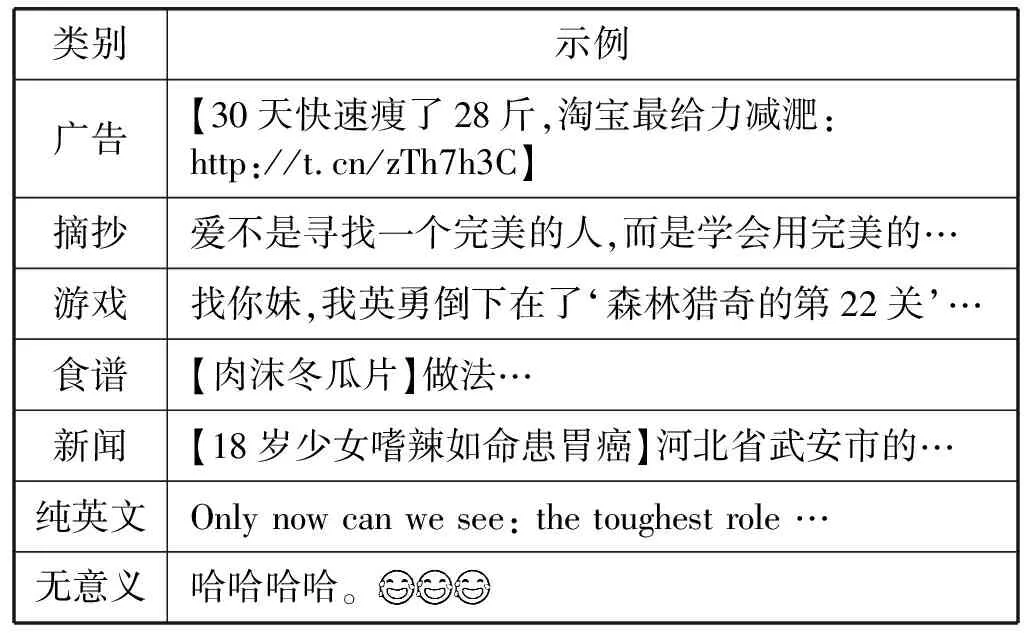
表1 噪声语料库的文本类别
基于逻辑回归分类器的预处理算法通过对噪声语料库的学习,为原始语料库中的文本进行打分评价。当文本得分超过0.5时,表明该文本有极大的可能属于噪声语料,故将其过滤。
(2) 标签数据集构建。本研究中,首先由人工专家标注情感分布相对均匀的小规模语料库,然后由主动学习算法在保证其情感分布均匀的基础上,逐步扩大其规模,最后完成情感语料库的扩充。
为了验证本文方法在小规模数据集上的有效性,人工专家标注的语料库分为训练集、验证集和测试集,其分别包含文本864、1 005和1 592条,且每条文本均已由人工专家标注有一个或多个从情感标签库(愤怒、欢乐、悲伤、焦虑、讨厌、期望、惊讶、爱和中立)中挑选的情感标签。为使主动学习模型从开始就学习到一个相对公正的情感分类器,本文训练集、验证集和测试集中每类情感标签的规模分别约为100、100和184条。
(3) 分词。本文采用清华大学推出的一套中文词法分析工具包THULAC(THU Lexical Analyzer for Chinese)对所构建的标签数据集进行分词处理,去除多余的空格、英文字符和其他特殊字符。同时,将文本“@”、“http”和阿拉伯数字形式的字符串转为基本语言单元,分别为
3.2 模型参数选择
本文使用验证集和3个未标注数据集来确定参数λI、λR和λD的值,并使用6个未标注数据集来确定算法1中参数λC的值。
表2显示了每个选择参数的候选值。其中:前三个参数的候选值是用于指定选择准则选择样本的百分率;最后一个参数的候选值则指定最终输出样本量的规模。根据不同组别的参数值而更新的训练集,比较其在情感分类实验结果的准确率、召回率和F1值,本研究发现参数λI、λR、λD的最佳取值分别为0.2、0.5、0.5,且λC为40。
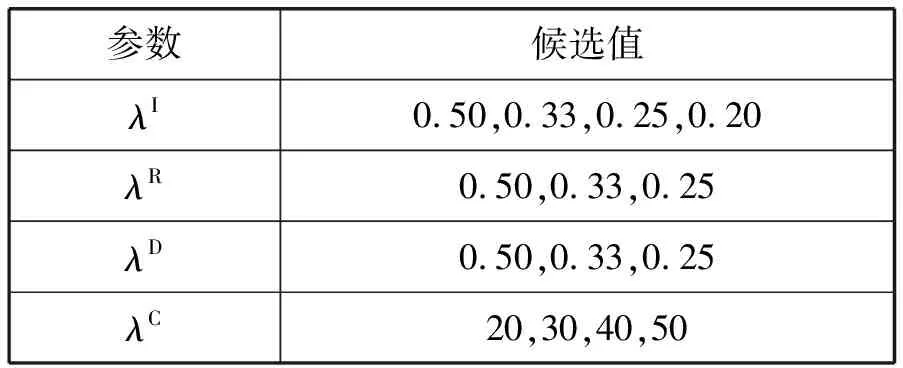
表2 主动学习算法中选择准则参数候选值
3.3 实验结果与分析
为了验证本文算法在情感平衡上的有效性,本文做了多组实验。对比了本文算法和文献[19]中方法的情感分类性能,还比较了没有情感分布均衡措施的主动学习方法。在主动学习实验中,对于每个未标注数据集U,本文首先将其与已有训练集X一起输入算法1,以获取更新的训练集;然后,基于每个训练集,训练所构建的情感分类器(式(1)),并分别使用这些学习到的分类器在测试集上进行情感分类实验并评估结果;最后,逐步统计分类结果。结果表明:随着训练集中样本数量的增加,文本情感分类的结果也随之改进,如图2所示。
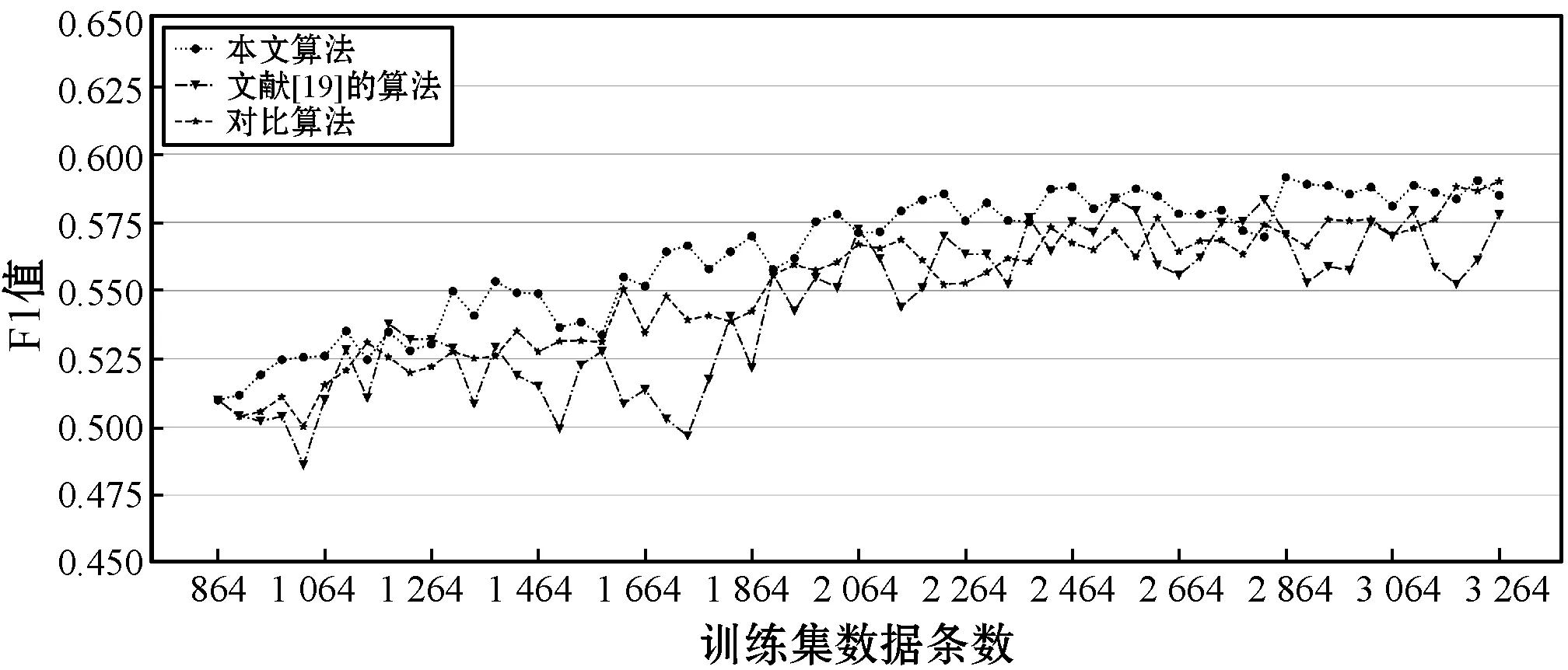
(a) F1值的变化趋势
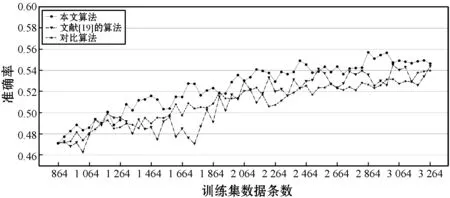
(b) 准确率的变化趋势

(c) 召回率的变化趋势图2 情感分类结果随着训练数据增加的变化趋势
随着算法1迭代次数的增加,训练集的规模逐渐增大。实验结果中不断提高的微平均准确率、召回率和F1值证明,情感分类模型的学习能力逐渐增强。具体来说,在主动学习算法迭代60次后,分类实验结果的P、R和F1值的微平均分别提高了7.53%、7.36%和7.51%。结果表明,本文方法可有效地从未标注数据集中找到合适的样本,进而显著提高多标签文本情感分类模型的学习能力。
下面通过比较本文方法与对照实验的文本情感分类结果(其主动学习算法仅由前三个准则组成,即信息性、代表性和多样性)来检验所提出的互补性标准的有效性。对照实验中选择的参数与本文方法相同,不同之处在于参数λD被λC取代,以保证样本选择的规模与算法1相同。
如图2所示,根据本文方法得出的P、R和F1值的微平均始终高于对照实验。两种方法之间的平均差距为:准确率1.55%,召回率0.94%,F1值1.30%。表明本文所提出的互补性准则能够以有效的方式对样本选择的优先级进行重新排序,从而更轻松地找到高质量样本并将其添加到训练集中。当对文献[19]算法的实验结果进行比较时发现,准确率、召回率和F1值的微平均增量分别为1.55%、2.49%和1.97%。虽然其结果也有提高,但是根据本研究提出的方法而抽取的样本更可靠。
最后,本文探索了本文方法、对比算法、文献[19]算法产生的情感标签的分布,以进一步分析三种算法对训练集情感标签平衡性的影响。通过本文算法或对比算法选择越来越多的样本,且将其并入训练集,不断扩大训练集中情感标签的规模。
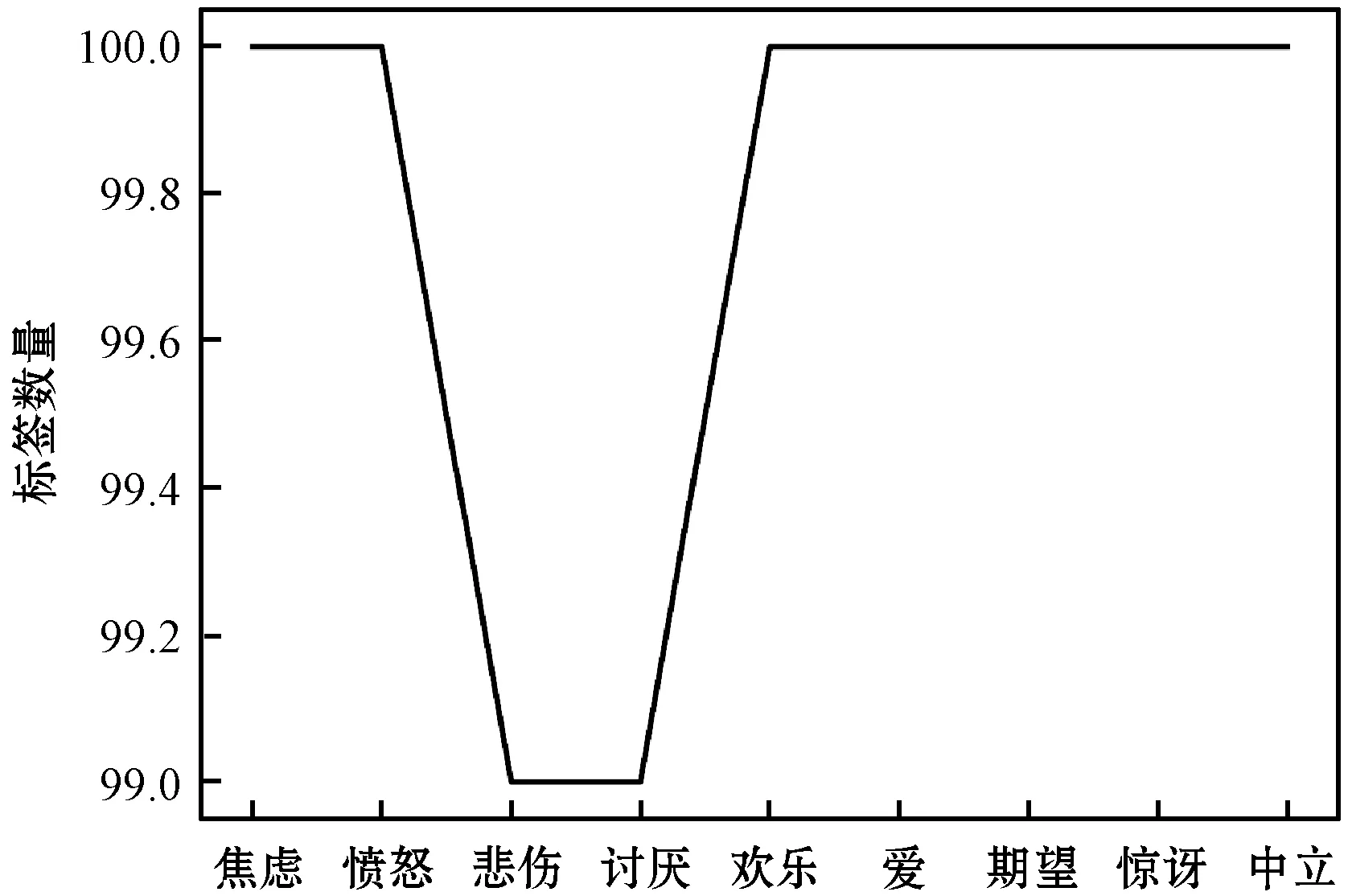
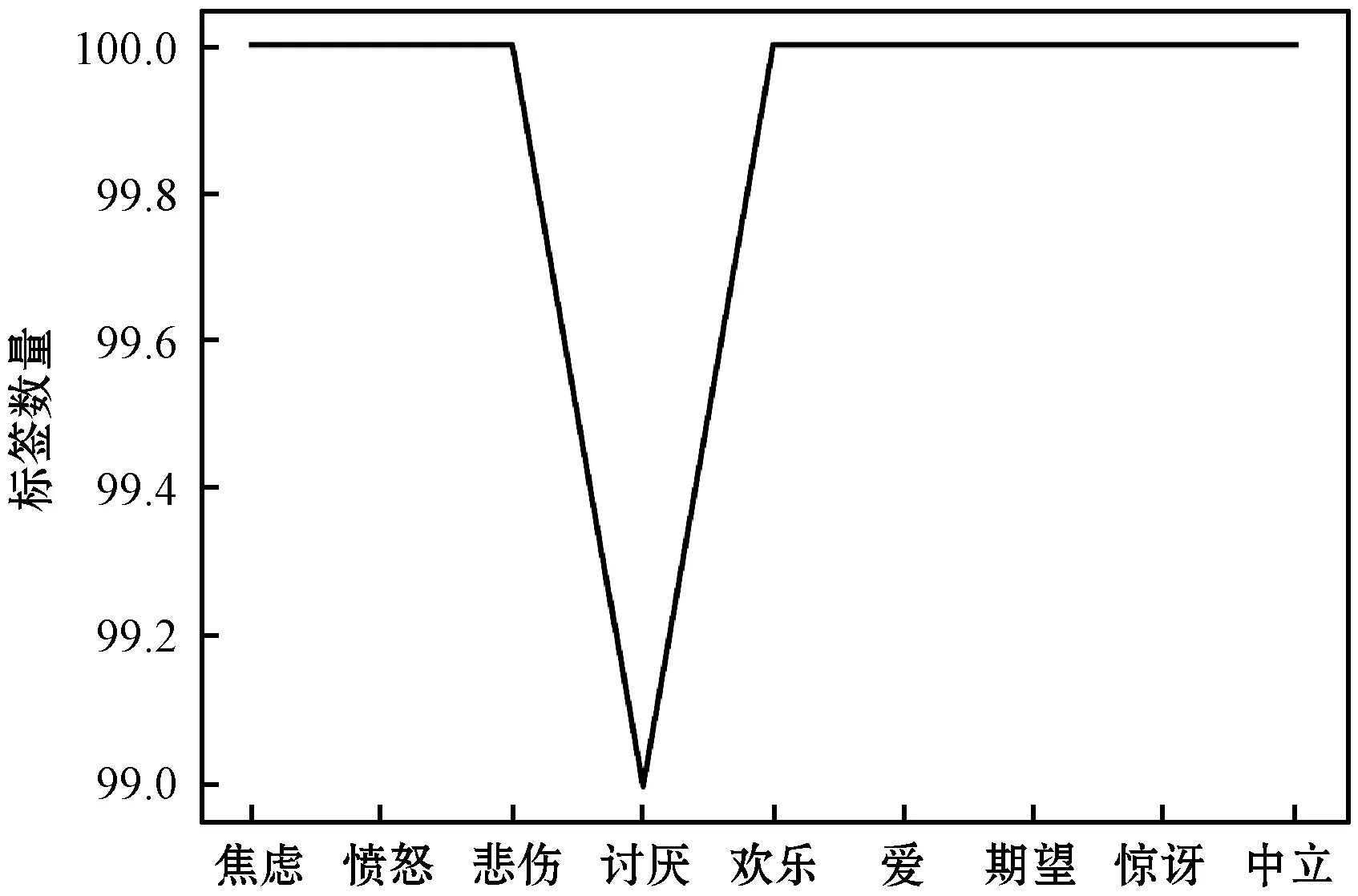
图3(a)、图3(b)和图3(c)分别为基于本文算法、对比算法和文献[19]算法而逐步更新的训练集中情感标签分布情况,其中数字为情感标签数量的衡量刻度。算法在迭代过程中,构建了一系列训练集。这些训练集具有比对比算法构建的训练集更为均衡的情感标签分布。具体而言,未标注数据集中频次最高的中立情感标签在选择过程中受到了很大的限制。同时,在通过本文方法获得的训练集中,其他情感标签的增长速度比对比实验中的增长快得多,并且这种增长在情感标签“焦虑”、“欢乐”、“讨厌”和“期望”上尤其明显。与本文方法相比,在基于文献[19]算法更新的训练集中,“无情感”标签极化现象严重。其余八种情感类别的标签数量变化趋势相似,但增长速度缓慢,与本文方法差距明显。

(a) 本文算法
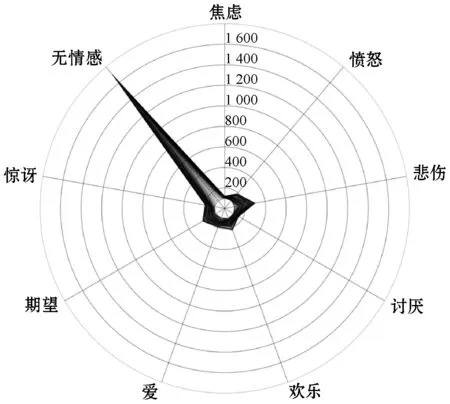
(b) 对比算法
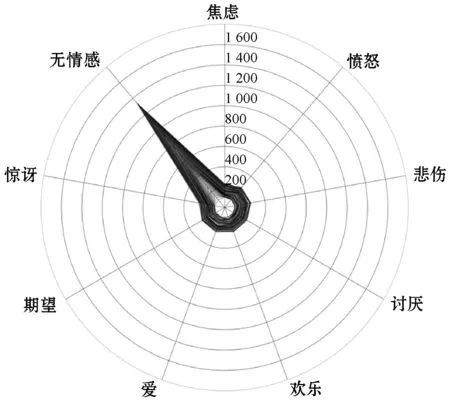
(c) 文献[19]算法图3 通过主动学习算法所获取的训练集中各类情感 标签的分布情况
以上结果表明,在未标注数据集情感分布具有高度偏向的情况下,文中所提的互补性准则可有效地选择具有标签平衡特性的未标注样本,这从本质上抑制了训练集中高频次情感标签的增长,并促进了低频次标签的选择。
4 结 语
本文提出一种平衡情感分布的主动学习互补性准则,从可能存在情感分布高度偏向的未标注数据集中选择样本以扩充训练集,并在训练集样本数量不断增长的情况下,保持情感标签分布的平衡。实验结果表明:所提出的基于Kullback-Leibler散度互补性准则可以有效地平衡构建训练集的标签分布,限制了潜在的属于高频情感的样本选择,并发现潜在的属于稀少情感的样本,一定程度上平衡了训练集的情感分布。同时,随着训练数据的增长,文本情感分类结果也得到了稳步提高。虽然所构建的训练集情感标签还不能达到完全平衡,但是为情感标签平衡语料库的建立提供了新的思路,且部分解决了标签不平衡的问题。下一步的工作将进一步优化模型,以期抽取到使训练集情感标签更均衡的样本,从而提高模型在平衡情感标签方面的性能。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
外语学刊(2021年1期)2021-11-04
计算机系统应用(2021年2期)2021-02-23
师道·教研(2017年11期)2017-12-10
软件导刊(2017年4期)2017-06-20
对外经贸(2016年8期)2016-12-13
商(2016年32期)2016-11-24
改革与开放(2010年6期)2010-06-04
