
中考体育成绩预测方法研究
2021-07-14 07:58吴春连
中文信息 2021年5期
吴春连
(万达信息股份有限公司,上海 200041)
引言
在《体育总局教育部关于印发深化体教融合 促进青少年健康发展意见的通知》发布后,各省市积极响应政策,同时广大家长、学生对加强体育运动的响应效果也逐步凸显,并加强了被纳入中考的体育项目的学习,以期在中考中获得良好的表现。本文采用历年学生的体育成绩数据训练了几种拟合模型,从而对学生中考体育成绩进行预测。
一、拟合模型介绍
首先给出中考体育成绩预测问题的形式化定义。假设有n个学生,每个学生都有自己日常的体育数据,用m维向量x来记录,向量中的每一个维度都表示具体的某一种体育特征,包括身高、体重、BMI、肺活量等等;学生对应的中考成绩用y表示,其中y可以为学生的中考体育总成绩或者具体某一项考试的成绩。所有n个学生的数据可以表示为{(x1,y1),(x2,y2),…,(xn,yn)}
本项目的目标是学习一个拟合函数f,在给定一个学生u的日常体育特征Xu时,预测他的中考体育成绩,即uyˆ=f(Xu),并期望uyˆu尽可能接近于他的真实成绩yu。
下面介绍本文研究的一些经典的机器学习方法、其建模形式、适用问题以及需要设定的参数等情况。
1.最近邻模型
K-近邻模型属于比较简单的一种模型,经常被用于作为机器学习的基准方法。即在训练集中,根据输入特征,找到与目标对象最接近的K个邻居,将他们输出值的平均值作为目标对象的预测值。K-近邻模型没有具体的学习参数,主要依靠训练集的数据,来推测新样本的情况。该模型的优点是结构简单,训练成本较低。其中,需要确定的参数主要包括选择合适的距离函数,以及确定最优的K值。该模型适用于训练数据较为丰富,且数据存在局部性模式的情况。该模型也存在一些缺陷,例如,模型的预测速度受训练数据的总量、K值的大小、距离函数的复杂程度影响较大。而且如果数据中存在较多噪声,有些数据点附近训练数据样本较少等情况,则拟合效果较差。
2.线性拟合模型
线性拟合模型是最简单的一种拟合模型。该模型假设输入特征x和预测的目标y存在线性关系。输出的预测值可以用输入的特征进行加权估计得到。公式为=wx+b,其中,是预测值,w是权值向量,b是偏置,x是自变量向量。在定义完预测模型之后,需要根据训练样本,估计模型中的参数w和b。预测模型的目标是最小化预测值和真实值之间的偏差,因此,可以定义损失函数为
其中,n表示训练样本数量。如果将的估计函数代入到该公式中,就可得到损失函数L(w,b)=最小化该损失函数,就可得到模型的参数。对于最小化该损失函数,可以有两种方法,包括最小二乘法和梯度下降法。最小二乘法是根据求导,使得导数为0的方式,获得极值,最终得到参数的解析解梯度下降法是使用迭代的方式,首先对预测模型求导,然后得出迭代公式,根据如下的公式对权重和偏置进行不断迭代,即可得到参数其中,和分别表示损失函数对于权值和偏置的导数,α是学习速率,需要设定为小于1的值。线性拟合模型的优点是假设输入和输出是线性关系,模型较为简单,模型过拟合的风险较小,所需要的训练数据也较少。模型需要确定的参数是权值向量和偏置。该模型适用于输入和输出存在明显线性关系的场景。同时,也存在模型较为简单,难以建模复杂非线性依赖的缺陷等。
3.多项式拟合模型
为了解决线性模型难以建模复杂依赖的问题,可以向线性模型中加入特征的幂次项。具体操作是,根据原始特征向量x,分别求出其2次、3次等指数结果。然后拟合公式=p0+p1X1+p2X2+…+pqXq。
其中,p0,p1,…,pq是需要学习的参数。在定义完预测公式之后,与线性模型类似,可以定义如下的损失函数,最小化该损失函数,即可得到其中的参数{p0,p1,…,pq}L=
需要注意的是该模型虽然有指数项,但是只需要根据原始特征求出来x1,x2,…,xn的值,就可以把多项式拟合问题,转化为线性拟合的问题。该模型的优势在于可以建模输入和输出的非线性关系。需要确定的参数包括各项权值。该模型相比于线性模型参数更多,需要的训练数据也更多,可能存在更大的过拟合风险。
4.支持向量回归(Support Vector Regression,SVR)模型
线性模型较为简单;而多项式模型也只是加入了指数项,提升了其建模非线性关系的能力,但是局限性也比较大。SVR模型通过引入核函数,进一步提升了模型拟合复杂关系的能力。SVR模型是支持向量机模型的变种。支持向量机(support vector machine,SVM)是针对分类任务提出的模型。SVR模型思想与其类似,是寻找一些支持向量,确保预测值相对于真实值不会偏离到支持向量划定的界限之外。SVR的推导过程是从线性模型开始的,然后引入了核函数提升其建模非线性关系的能力。首先定义线性拟合函数=wx+b,SVR的思想是只要真实值和预测值偏差不太大即算预测正确,设ε为拟合精度控制参数,期望-ε<y<+ε。
考虑到SVM中的线性不可分的情况,引入松弛变量和,得出SVR的优化问题引入拉格朗日乘子,经过对偶和求解,得出预测函数其中,α,为拉格朗日乘子,即为待求参数。然后引入核函数,得到预测公式其中,K(Xu,Xi)是核函数,表示对象u和i相似的程度。核函数可以使用非线性核增加模型建模非线性关系的能力。核函数有很多种选择,下面介绍几种常用的核函数:
● 线性核函数是使用内积的形式,计算出两个特征向量的相似程度,公式为K(x,z)=XTZ,其中,X和Z分别表示一个向量,XT表示向量X的转置。
● 多项式核函数使用多项式的形式,计算两个特征向量之间的关联性K(x,z)=(axTz+c)d,其中,a和d是两个可以设置的超参数。
● 高斯核使用高斯函数来计算两个特征向量之间的相似性。

SVR模型是针对非线性关系建模的一种有效的模型。需要求的参数包括拉格朗日乘子,核函数的选择,以及核函数中的超参数等。SVR模型需要根据数据分布的特点选择合适的核函数。
二、训练数据分析
训练数据分类两类,一类是预测的目标数据,包括中考体育总成绩,以及学生中考体育专项成绩,另一类是输入特征包括学生在初三年级的体质健康测试成绩和日常体育成绩。
1.数据分布分析
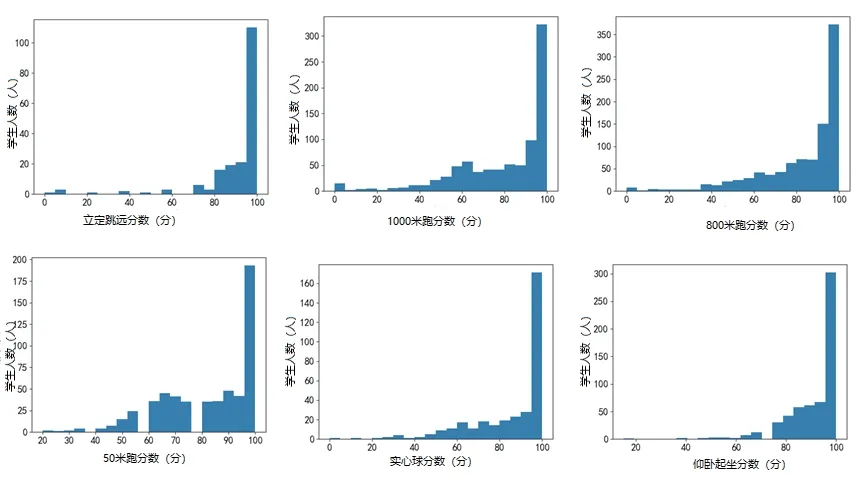
本文分析的预测目标数据分别为体育总分、1000米、800米、50米、实心球、仰卧起坐、立定跳远,各项数据的平均分分别为27.72、78.08、81.49、82.21、84.61、92.07和89.65,标准差分别为3.05、23.31、20.36、18.05、19.50、11.31、18.18。总分都是接近30分,差别不大,其他各专项数据分布如下图:
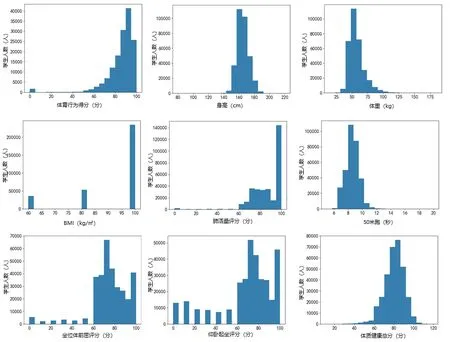
输入特征数据为体育行为数据和体质健康数据,包括学生体育行为成绩、身高、体重、BMI、肺活量、50米跑、坐位体前屈、仰卧起坐、体质健康总分。各项平均分分别为85.11、164.86、57.00、92.27、86.61、8.56、74.04、68.30、80.34。各项标准差分布为13.77、7.52、12.23、13.53、14.64、0.92、17.58、25.79、9.99。各项数据分布直方图如下:
由上述分布情况可以看出,身高、体重、50米跑、体质健康总分都是比较符合高斯分布的。而且每个项目的数据分布、数据范围都不同,需要进行归一化处理,才能作为模型的输入,否则可能降低预测的准确性。
2.数据相关性分析
本文还分析了输入特征与预测目标之间的关联性。只有强关联性的特征,才会对预测任务有帮助。本文采用了皮尔森相关系数来衡量各个特征与预测目标之间的相关性强弱。分析结果表明中考1000米成绩与体重、BMI、50米跑、体质健康总分的相关性较大,实心球和体质健康总分以及50米跑成绩相关性较大,仰卧起坐与50米跑和体质健康总分相关性较大,立定跳远和仰卧起坐以及体质健康总分的相关性较大。
三、模型超参设置和预测结果分析
1.模型超参设置
本文通过实验寻求各拟合模型的最佳超参。对于K近邻拟合方法,当K值为10时获得了该方法的最好效果;对于线性拟合模型,设置梯度下降的学习速率为0.01;对于多项式拟合模型最终指数的值设置为2时获得了最好的预测效果;对于SVR模型需要确定的超参数包括核函数类型的选择以及核函数中的超参数设置。本文测试了线性核、多项式核、径向基核,其中径向基核获得了最好的预测效果。
2.预测结果分析
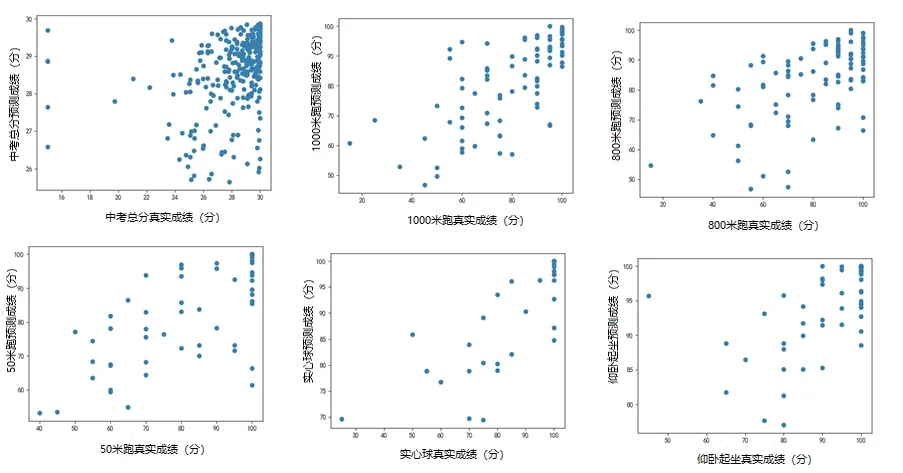
为了训练所设计的模型,并验证其预测效果,将中考体育成绩、体质健康和体育行为的历史数据分为两部分,随机选择其中90%的数据作为训练集,剩余10%的数据作为测试集。预测的目标包括中考体育总成绩和体育专项成绩。为了比较不同模型的预测精度,本项目使用MAE指标来评价各个模型。在模型训练好之后,使用模型在测试集上进行预测,并根据计算公式得到MAE的值。其中,m是测试样本的个数;X(i)为真实值,这里每个要预测的Xt都是一个预测样本的真实值;为模型预测的结果;|·|表示求绝对值。MAE的值越小,说明预测模型的预测效果越好。实验表明,K近邻、线性模型、多项式模型、SVR模型预测中考总成绩的MAE值分别为1.62、1.41、1.40和1.32。由此可知,SVR模型获得了最好的预测效果。本文还对各体育专项进行了预测实验,结果表明,SVR模型在1000米,800米,50米、实心球和坐位体前屈项目上获得了较好的预测效果。以下散点图展示了中考体育总成绩及各专项成绩的真实值与预测值之间的相关性。
四、结语
在本文研究的所有的预测模型中使用了径向基核函数的SVR模型获得了最好的预测效果。预测结果和真实值具有明显的正相关性,说明本文设计的预测模型是十分有效的。从而可以为学生选择中考体育项目提供一定的数据参考,为体育总成绩的预估提供依据。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
新高考·高一数学(2022年3期)2022-04-28
中学生数理化·七年级数学人教版(2021年12期)2021-12-31
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
中学生数理化·七年级数学人教版(2017年10期)2017-04-23
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
常熟理工学院学报(2011年4期)2011-03-20
